1 つ目は、yolov8 の onnx モデルを rknn モデルに変換することです (ここでは yolov8n-seg です。
変換モデルのコードは次のとおりです。これは Python コードです:
if __name__ == '__main__':
platform = 'rkXXXX' #写自己的型号
exp = 'yolov8n_seg'
Width = 640
Height = 640
MODEL_PATH = './onnx_models/yolov8n-seg.onnx'
NEED_BUILD_MODEL = True
# NEED_BUILD_MODEL = False
im_file = './dog_bike_car_640x640.jpg'
# Create RKNN object
rknn = RKNN(verbose=False)
OUT_DIR = "rknn_models"
RKNN_MODEL_PATH = '{}/{}.rknn'.format(OUT_DIR,exp)
if NEED_BUILD_MODEL:
DATASET = './dataset.txt'
rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], target_platform="rkXXXX")
# Load model
print('--> Loading model')
ret = rknn.load_onnx(MODEL_PATH)
if ret != 0:
print('load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=True, dataset=DATASET)
if ret != 0:
print('build model failed.')
exit(ret)
print('done')
# Export rknn model
if not os.path.exists(OUT_DIR):
os.mkdir(OUT_DIR)
print('--> Export RKNN model: {}'.format(RKNN_MODEL_PATH))
ret = rknn.export_rknn(RKNN_MODEL_PATH)
if ret != 0:
print('Export rknn model failed.')
exit(ret)
print('done')
else:
ret = rknn.load_rknn(RKNN_MODEL_PATH)
rknn.release()
正常に実行されると、yolov8n_seg.rknn モデルが取得されます。
以下はcppコードです。
rknn モデルを実行し、ゼロコピーでない場合はこのコードを使用します。
//设置outputs数组保存结果
rknn_output outputs[io_num.n_output]; //长度为2的数组
memset(outputs, 0, sizeof(outputs));
for (int i = 0; i < io_num.n_output; i++) {
outputs[i].want_float = 0;
}
ret = rknn_run(ctx, NULL); //运行rknn模型
//这里不是零copy方法,需要用到rknn_outputs_get函数
ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);
ゼロコピー方式ではこのコードを使用します。
ret = rknn_run(ctx, nullptr);
memcpy(y0, output_mems[0]->virt_addr, output_attrs[0].n_elems * sizeof(char)); //outputs[0]copy到y0
memcpy(y1, output_mems[1]->virt_addr, output_attrs[1].n_elems * sizeof(char));
rknn モデルの演算結果の出力の構造を見てみましょう。
この結果に至った経緯とその意味については、こちらをご覧ください。
出力のサイズは 2 です。ここで、outputs[0] のサイズは 8400*176、8400 はボックスの数、176 には
3 つの部分が含まれ、64 はボックス座標、80 はカテゴリ確率、32 はマスク係数です。
Outputs[1] これは proto_type で、サイズは 32 * 160 * 160 です。
want_float は結果を float として出力するかどうかで、ここではまだ int 出力であることを示す 0 を設定し、後で逆量子化します。
データ部分は buf (void*) に格納され、使用時に (int8_t*) にキャストされます。
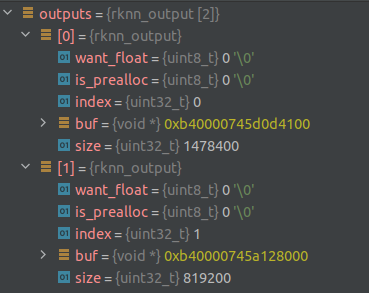
ここで、ターゲット ボックスを取得し、出力をマスクするための後処理を記述する必要があります。
主なアイデアは次のとおりです。
1.逆量子化
rknn モデルの出力は量子化された int8_t 型なので、計算時に float 型に逆量子化する必要があります
。
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++) {
output_attrs[i].index = i;
//rknn_query:查询模型与sdk的相关信息
//output_attrs:存放返回结果的结构体变量
ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr));
dump_tensor_attr(&(output_attrs[i]));
}
ダンプ結果は以下の通りで、モデル出力の型は int8 で、量子化にはアフィン変換、つまり出力 / スケール + zpが使用されていることがわかります。

(出力 - zp) * 逆量子化にはスケールが必要です
//反量化计算
static float deqnt_affine_to_f32(int8_t qnt, int32_t zp, float scale) {
return ((float)qnt - (float)zp) * scale; }
2.ボックス部
8400 * 176、ここで、8400 はボックスの数、176 には 3 つのパーツが含まれ、64 はボックスの座標、80 はカテゴリ確率、32 はマスク係数です。8400 個のボックス パーツは各ボックスの 80 カテゴリ確率を取り出し
、カテゴリ確率値がこのボックスのラベルです。
カテゴリ確率値 > 閾値のとき、有効です。
各 176 ベクトルの最初の 64 データ、各 16 個のグループ、合計 4 つのグループを取得できます。ボックス (l, t, r, b)
。8400 個のアンカーの中心点と (l, t, r, b) を使用して、ボックスの (x0, y0, x1, y1) を取得します。
さらに、各ボックスの 32 次元マスク係数を保存します。
カテゴリ確率がしきい値より大きいかどうかを判断する場合、最初にカテゴリ確率を逆量子化する必要があることに注意してください。
for (int i = 0; i < box_num; i++) {
//遍历8400个box
...
// find label with max score
int label = -1;
float score = -FLT_MAX;
//找到最大score和对应的label
for (int k = 0; k < num_class; k++) //80个类别prob
{
float confidence = deqnt_affine_to_f32(score_ptr[k], zp, scale); //反量化,int转float
if (confidence > score)
{
label = k;
score = confidence;
}
}
float box_prob = sigmoid(score);
if (box_prob >= prob_threshold){
...
softmax(bbox_pred); //对4x16中的每16个一组求softmax,因为作了softmax,就不再需要对每个数据作反量化
...
//anchor中心点
float pb_cx = (grid_strides[i].grid0 + 0.5f) * grid_strides[i].stride;
float pb_cy = (grid_strides[i].grid1 + 0.5f) * grid_strides[i].stride;
float x0 = pb_cx - pred_ltrb[0]; //center_x - l
float y0 = pb_cy - pred_ltrb[1]; //center_y - t
float x1 = pb_cx + pred_ltrb[2]; //center_x + r
float y1 = pb_cy + pred_ltrb[3]; //center_y + b
Object obj;
obj.rect.x = x0;
obj.rect.y = y0;
obj.rect.width = x1 - x0;
obj.rect.height = y1 - y0;
obj.label = label;
obj.prob = box_prob;
obj.mask_feat.resize(32);
std::copy(bbox_ptr + 64 + num_class, bbox_ptr + 64 + num_class + 32, obj.mask_feat.begin());
objects.push_back(obj);
}
}
上記は、ボックスの最初の波をカテゴリ確率のしきい値でフィルタリングし、
次に nms で別の波をフィルタリングすることです。
nms_sorted_bboxes(proposals, picked, nms_threshold); //picked里面保存的是proposals的下标
3.マスク部
マスクは、mask_coeff と proto_type の行列乗算によって取得されます。
Mask_coeffは、上記オブジェクト内の各objのmask_featに格納されます。
上記のmask_featは逆量子化されていないことに注意してください。
Outputs[1] はデータの先頭のポインタですが、
行列の乗算やサイズ変更などの後続の操作を容易にするために、これを cv::Mat に変換する必要があります。
int8 型 Mat の場合、値は自動的に [0,255] に制限され、
当然、mask_feat には負の数が含まれるため、float 型 Mat を使用することに注意してください。
まずnmsで選択したターゲットのmask_coeffをMatに変換します。次に、逆量子化計算を実行します。
//mask_feat里面保存每个目标的mask coeff
cv::Mat mask_feat_qnt(count, 32, CV_32FC1); //float型的Mat, count为nms后目标的个数
for (int i = 0; i < count; i++) {
float* mask_feat_ptr = mask_feat_qnt.ptr<float>(i); //指向第i行的指针
std::memcpy(mask_feat_ptr, proposals[picked[i]].mask_feat.data(), sizeof(float) * proposals[picked[i]].mask_feat.size());
}
//因为mask_feat从outputs[0]中得到,所以用zps[0],scales[0]作反量化
cv::Mat mask_feat = (mask_feat_qnt - out_zps[0]) * out_scales[0];
proto_type を cv::Mat に変換します。proto_type の値も逆量子化されます。
cv::Mat proto = cv::Mat(32, 25600, CV_32FC1, proto_arr);
ターゲットのマスクを取得するには、mask_coeff と proto_type マトリックスを乗算します。
cv::Mat mulResMask = (mask_feat * proto).t(); //(n,32)*(32,25600)=n*25600,必须加转置,不加的话mask会很奇怪
cv::Mat masks = mulResMask.reshape(count, {
160, 160}); //每个目标有一个160*160的mask
std::vector<cv::Mat> maskChannels;
cv::split(masks, maskChannels); //把count个mask分割开,每个目标的mask保存为vector的一个元素
各ターゲットのボックスとマスクを結果オブジェクトに保存します。
std::vector<Object> objects;
objects.resize(count); //保存结果的object
for (int i = 0; i < count; i++)
{
objects[i] = proposals[picked[i]];
// adjust offset to original unpadded
float x0 = (objects[i].rect.x - (wpad / 2)) / scale;
float y0 = (objects[i].rect.y - (hpad / 2)) / scale;
float x1 = (objects[i].rect.x + objects[i].rect.width - (wpad / 2)) / scale;
float y1 = (objects[i].rect.y + objects[i].rect.height - (hpad / 2)) / scale;
// clip
x0 = std::max(std::min(x0, (float)(img_width - 1)), 0.f);
y0 = std::max(std::min(y0, (float)(img_height - 1)), 0.f);
x1 = std::max(std::min(x1, (float)(img_width - 1)), 0.f);
y1 = std::max(std::min(y1, (float)(img_height - 1)), 0.f);
objects[i].rect.x = x0;
objects[i].rect.y = y0;
objects[i].rect.width = x1 - x0;
objects[i].rect.height = y1 - y0;
//计算mask并保存到object
cv::Mat dest, mask;
cv::exp(-maskChannels[i], dest); //每个mat单独计算sigmoid
dest = 1.0 / (1.0 + dest); //160x160的mask
dest = dest(roi); //取rect区域
cv::resize(dest, mask, cv::Size(img_width, img_height), cv::INTER_NEAREST);
//crop
cv::Rect tmp_rect = objects[i].rect;
mask = mask(tmp_rect) > 0.5; //mask阈值设为0.5
objects[i].mask = mask;
}
効果は次のとおりです。

コードの完全バージョンは、github のセマンティックに配置されます。