第5章 CUDAメモリ
「超並列プロセッサ プログラミングの実践」の学習。他の章ではCUDA Cのコラムに焦点を当てています。
CUDA C プログラミングに適したリンク:
- 第 3 章 CUDA の概要 - CUDA C プログラミング ベクトルの追加
- 第4章 CUDAデータ並列実行モデル
- 第5章 CUDAメモリ
- 第 6 章 CUDA パフォーマンスの最適化 (原書へのリンク付き)
- カーネル関数: CUDA プログラミング入門 (1) - スレッドの構成とイメージ操作によるカーネル関数の使用方法を参照
- 拡張: CUDA 畳み込みの計算と最適化 - 1 次元の畳み込みを例にします
スレッドがデータを処理するときは、並列コンピューティングを実行するために、まずホストからデバイスのグローバル メモリにデータをコピーし、次にブロック ID とスレッド ID を使用して処理する必要があるデータの場所を決定する必要があります。カーネルが計算するとき、メモリ (グローバル メモリ) との多くの対話が必要です。この種のメモリは通常、ダイナミック ランダム アクセス メモリ (DRAM)を使用し、アクセスの遅延が特に大きくなる場合があります。そのため、CUDA は大量のメモリを提供します。グローバルメモリへのアクセスを省略し、メモリアクセスの高速化とCUDAカーネルの処理速度の向上を図るメモリアクセス方式。
5.1 メモリアクセス効率の重要性
CGMA (Compute to Global Memory Access) とは、CUDA プログラムが特定の領域のグローバル メモリにアクセスするたびに実行される浮動小数点演算の数を指します。CUDA 比率は、CUDA のカーネル関数のパフォーマンスをより正確に反映できます。

この時のCGMA=1:1=1.0
グローバルメモリの帯域幅が 200GB/s、単精度浮動小数点数が 4 バイトの場合、単精度浮動小数点数の読み取り帯域幅は 200GB/4B = 50 GFLOPS となります。CGMA = 1.0 の場合、単精度浮動小数点数の演算は 50 GFLOPS を超えることはできません。
5.2 CUDAデバイスメモリの種類
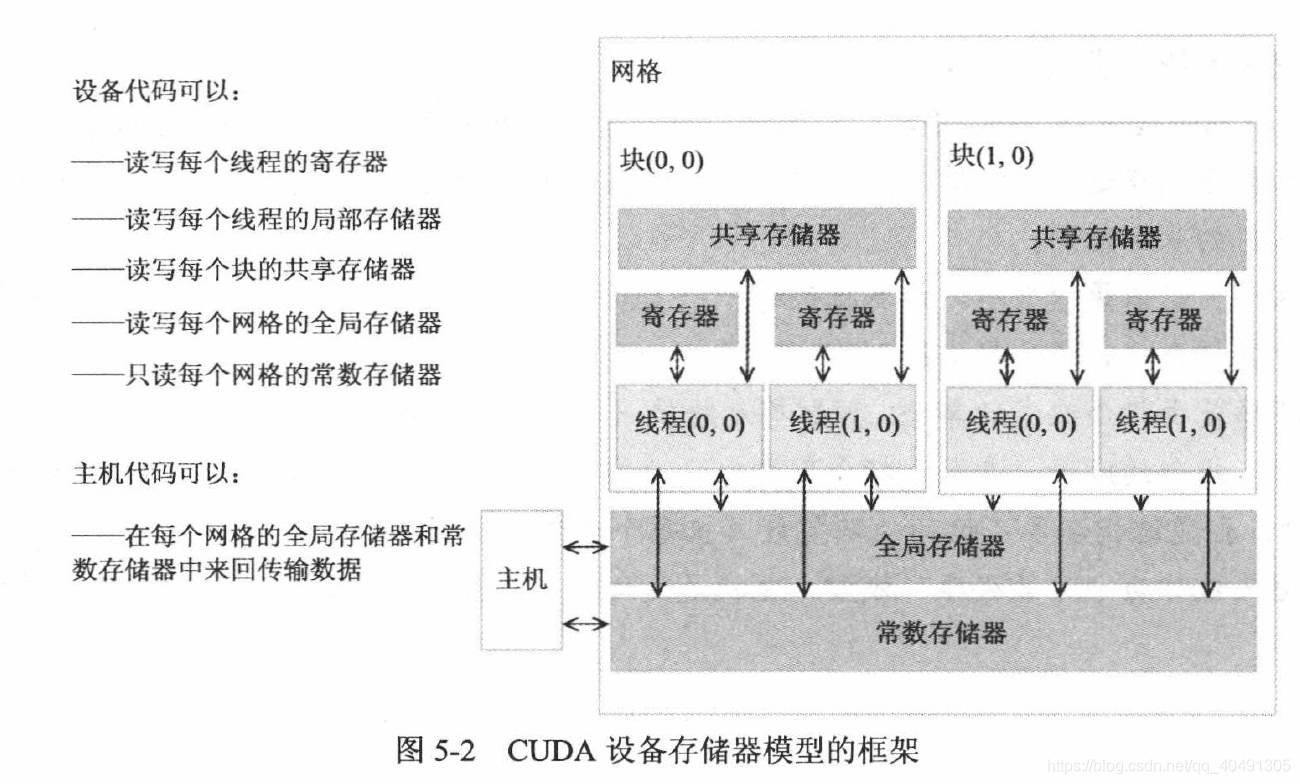

- グローバル メモリ (ホスト インタラクティブ)
- 定数メモリ (読み取り専用)
- レジスタと共有メモリ、つまりオンチップ メモリレジスタには単一のスレッドのみがアクセスでき、共有メモリにはスレッド ブロック内のすべてのスレッドがアクセスできます。
2 つの異なる処理アーキテクチャ
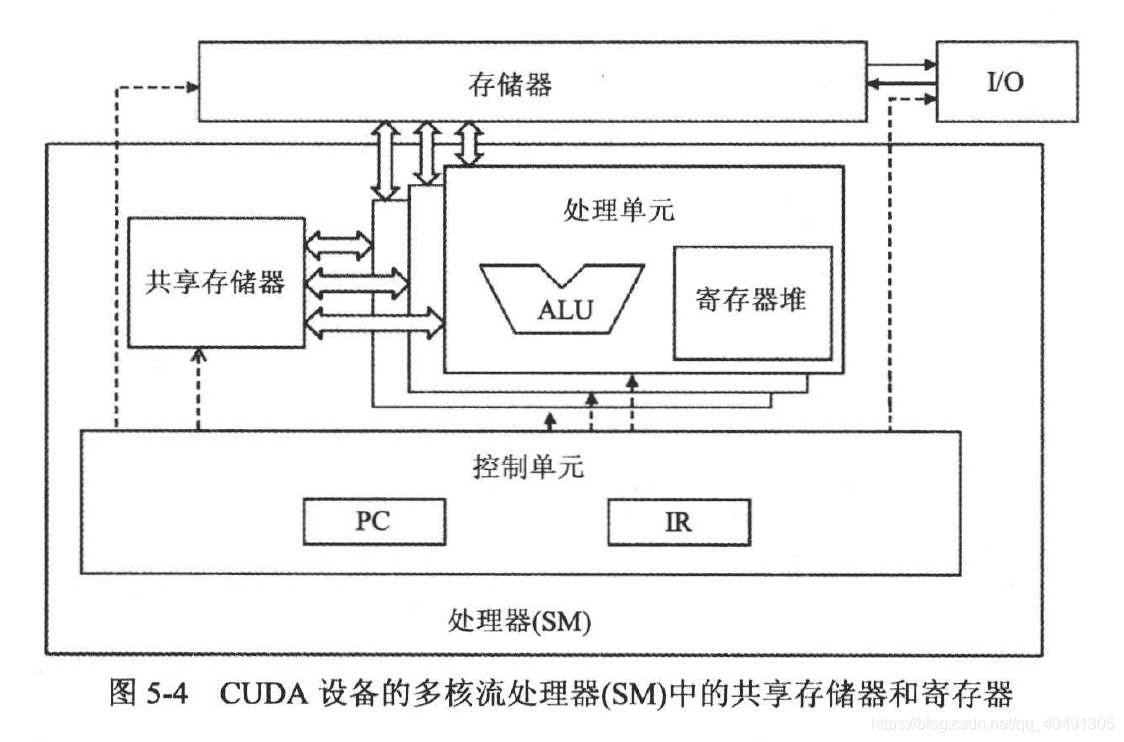
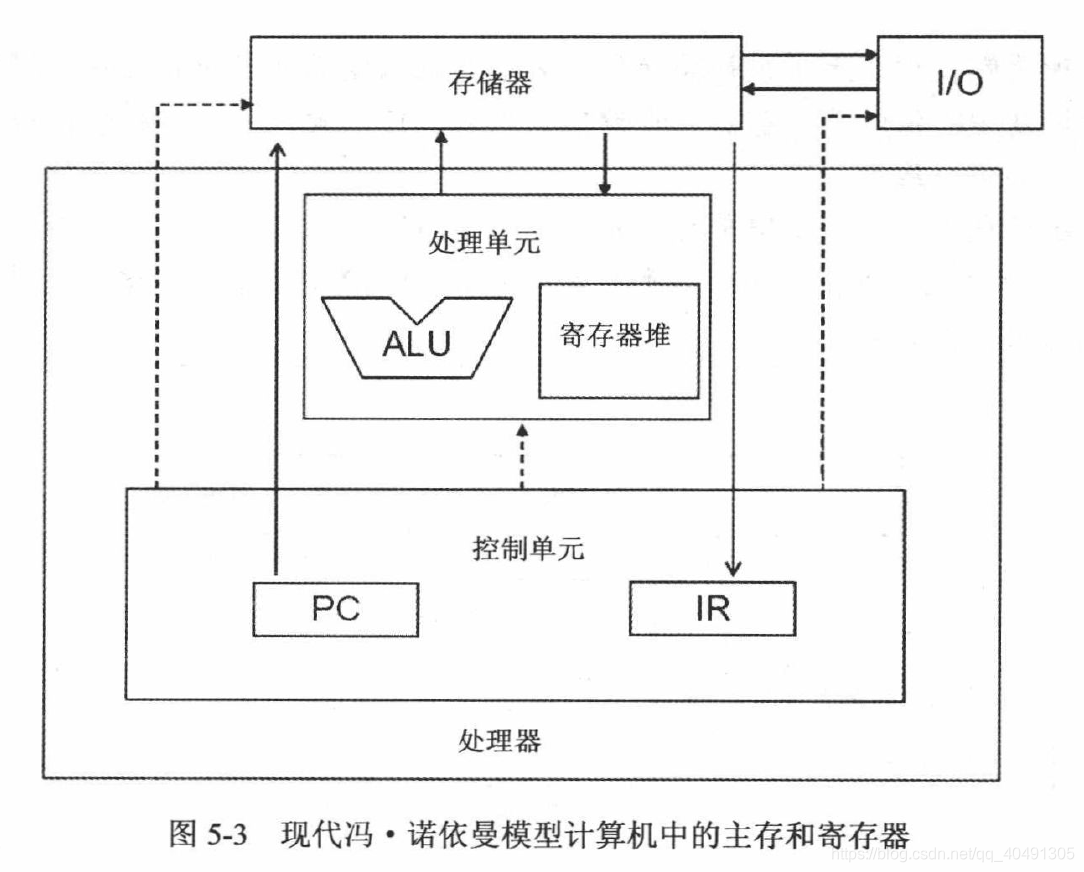
変数が異なれば、スコープを定義する際の宣言方法も異なります。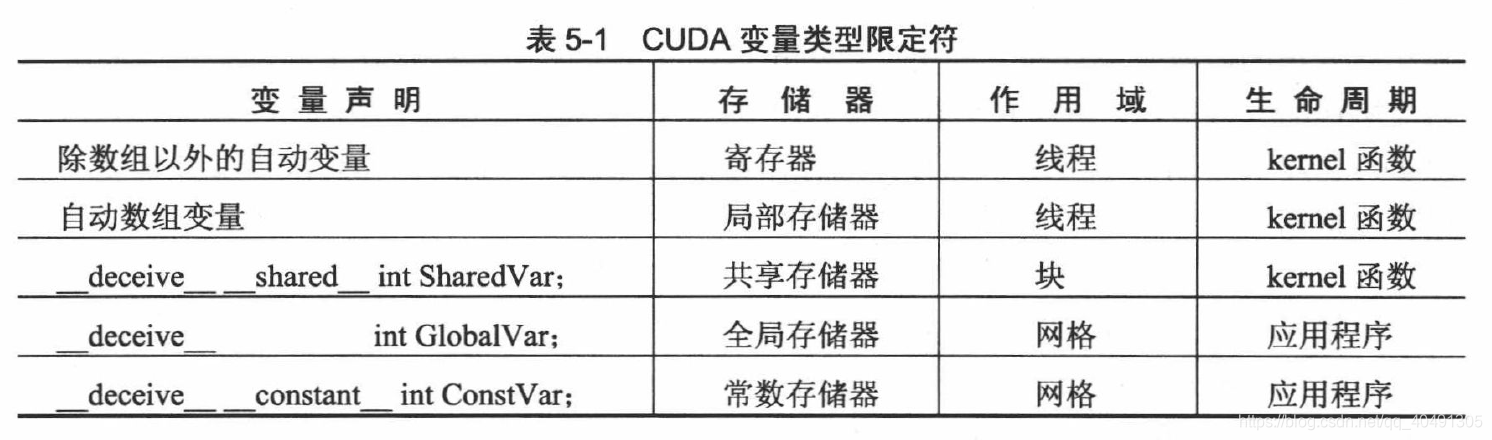
注: 自動配列変数はグローバル メモリに保存されます。
5.3 グローバルメモリトラフィックを削減する戦略
グローバル メモリ アクセスは低速ですが、共有メモリ アクセスは高速です。ブロック アクセスのためにデータをタイルと呼ばれる複数のサブセットに分割し、アクセス (グローバル) の数を減らし、効率を向上させます。
頻繁にアクセスされるグローバル メモリ ポイントをオンチップ メモリに常駐させることで、グローバル メモリへのアクセスを減らすことができますが、常駐しすぎると大量のオンチップ メモリが占有されるため、フェンス同期を使用する必要があります。常駐時間を短縮するための同期用。
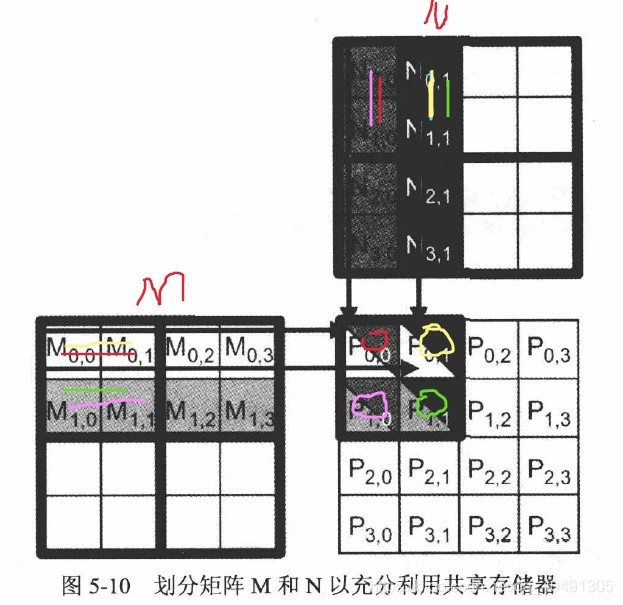
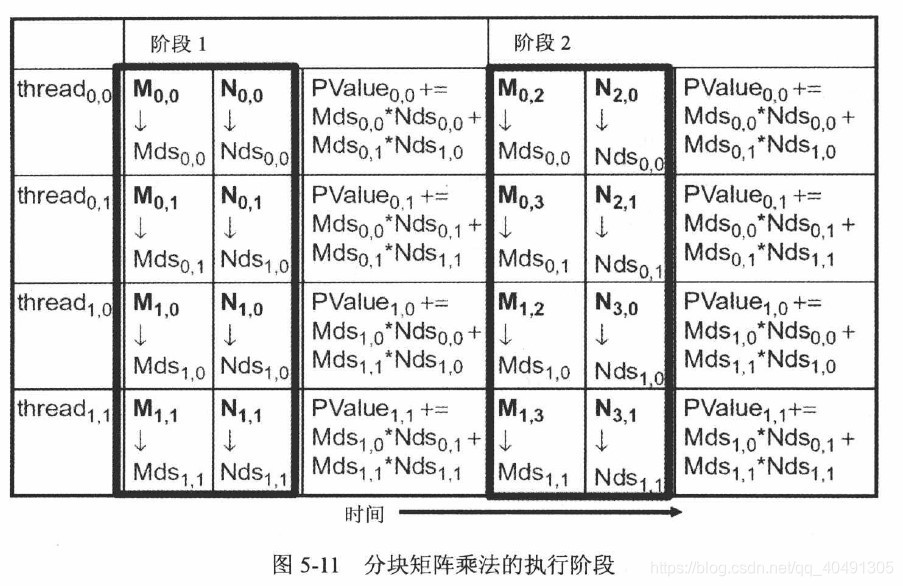
5.4 ブロック行列乗算のカーネル関数
原始行列乗算では、段階的な演算を実行できます。
各ステージごとに、
- 各スレッドはまず必要なブロック データをグローバル メモリから共有メモリに取得し、各スレッドは 2 つの位置 (2*2 単位の行列乗算) を取得します。
- 得られたデータに対して積和演算を行い、この 2*2 ユニットの行列積を求めます。
- 図に示すように、赤色はP 0 , 0 P_{0,0}を表します。P0、0 _ _スレッドの操作、赤い領域の積の合計、 M 0 , 0 M_{0,0}がかかります。M0、0 _ _およびM 0 , 1 M_{0,1}M0、1 _ _データ、N行列の値は紫色に与えられます。他の色についても同様です。同じデータ M または N が 2*2 の範囲内の 2 つのスレッドで同時に使用されるため、2 つのスレッドは別々に値を取得し、同じステージでデータを共有します。
[

5.5 メモリ — 並列処理を制限する要因
各SMに確保できるレジスタや共有メモリは限られており、スレッドブロック単位で確保されます。スレッド ブロック * ブロックごとに必要なレジスタ/メモリの数 > SM の最大容量の場合、各 SM で実行されているスレッド ブロックの数はブロック単位で減ります。メモリ/レジスタに収容できるスレッド数が SM が収容できる最大スレッド数より大きい場合、SM 固有の最大スレッド数が速度制限要因になります。
プログラミング中に取得したハードウェア情報に応じて、共有メモリの使用量が動的に決定されるため、GPU の使用率が向上し、計算が高速化されます。したがって、行列乗算の共有レジスタ宣言が変更されます。
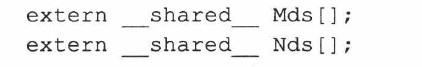
カーネルの起動時に、メモリ サイズも設定できます。
