著者:ルー・ウェイイー(武双)
HA3 (社外オープンソースコード名: Havenask) は、アリババ インテリジェント エンジン チームによって開発された大規模分散検索システムで、アリババの社内検索ビジネスで広く使用されており、アリババが電子サービス分野で蓄積してきた競争力の核となる製品です。商業分野で10年以上。Ha3 SQL は、オリジナルの Ha3 エンジンをベースにした新しい SQL クエリ関数であり、エンジンには SQL 形式のクエリ構文が組み込まれており、ユーザーは SQL ステートメントを記述してエンジン クエリを構築できます。
I. 概要
検索とプロモーションのビジネス シナリオでは、サンプルの構築は特徴データ リンクの重要な部分であり、ワークフローの観点から見ると、サンプルの作成は通常、アルゴリズムの学生にとって新しい実験を開始する最初のステップです。このリンクでのテクノロジーの選択に関しては、機能、安定性、アップストリーム データの場所を考慮して、ほとんどのチームが最終的に MaxCompute を選択します。MaxCompute は一流のオフライン データ処理プラットフォームですが、アルゴリズムの学生とのコミュニケーションでは、使用中に次のような問題が発生することをよく聞きました。
-
サンプル ストレージは MaxCompute スペースを大量に消費します。
-
サンプル構築タスクは大量のコンピューティング リソースを消費し、クラスターは一年中サンプル タスクによって使い果たされます。
-
特徴量の追加やサンプル分布の調整など、実験用のサンプルを構築するサイクルは非常に長く、時間コストが高くなります。
私たちは、これらのトラブルの背後にある本質的な原因を分析し、ここでの重要なポイントに対する新しい解決策のサンプル セットを提供しました: HA3 SQL サンプル実験機能。
HA3 SQL によって提供されるクエリ レイヤーを「サンプルの構築とトレーニング」のプロセスに挿入することにより、上記の主な問題が非常に正確に解決されます。現在、いくつかのアルゴリズム チームがこのサンプル ソリューションのセットにアクセスし、そこからデータ リンクの総合的な最適化を実現しています。
この記事では、サンプル構築の問題について分析と考え方を示し、HA3 SQL サンプル実験のスキーム アーキテクチャと共有する価値のあるいくつかの技術的詳細を紹介し、アクセス前後のパフォーマンス レポートとコストの比較も示します。最後に、この機能開発の過程で得られたいくつかの教訓と今後の作業の展望について説明します。
2.サンプルシナリオ問題の紹介と分析
2.1 サンプルの現状
まず、サンプルが通常どのようなもので、検索プロモーション シナリオでどのように構築されるかを簡単に紹介します。最も一般的な CTR サンプル (露出クリック サンプル) を例として取り上げ、Google WDL 論文の例を参照すると、典型的なサンプル レコードは次のようになります。
| pv_id |
アプリID |
ユーザーID |
クリック |
アプリのタイトル |
アプリケート |
app_download_count |
ユーザー年齢 |
ユーザーの性別 |
| xxx_xx |
1234 |
4321 |
1 |
ツイッター |
社交 |
3000 |
20 |
0 |
pv_id は、特定のリクエストに対応する uuid です。このサンプルの意味は、特定のリクエストによって返されたアプリが携帯電話上のユーザーによってクリックされたときです。クリックされた時点で、アプリの名前、ダウンロード量、その他の属性が表示されます。ユーザーの年齢、性別、その他の属性はまあまあです。サンプルはそのようなレコード数億件で構成されており、このデータはトレーニング中に機械学習モデルによって消費され、クリックの動作とさまざまな機能の間の相関関係を学習します。
この種のサンプルの一般的な構築方法は次のとおりです: pv_id app_id user_id click これらの属性は、ユーザーの行動が発生したときにいくつかのキー ID を記録する、ユーザー行動の埋め込まれたポイント ログから取得されます。アルゴリズムの学生は、一連の上流と下流を確立します。データのこの部分を収集するタスク それを MaxCompute にインポートしてユーザーの行動を表すパーティション テーブルにし、pv_id/app_id/user_id などのフィールドを主キーとして持つ複数の属性テーブル (通常はディメンション テーブルと呼ばれます) を準備します。テーブルはユーザーの行動に基づいています。 まず、上記の ID を使用してこれらの属性テーブルを結合し、最後にトレーニング プラットフォームの要件に従ってフォーマット処理を実行して、最終的なサンプル テーブルを生成します。
SQL 疑似コードで表現すると、主要なステップは基本的に次のようなロジックになります。
select pv_id, app_id, user_id, timestamp, click, download
from clean_behaviour_table
left outer join app_profile_table
on clean_behaviour_table.app_id = app_profile_table.app_id
left outer join user_profile_table
on clean_behaviour_table.user_id = user_profile_table.user_id現時点では、MaxCompute サンプルに対するほとんどのトレーニング プラットフォームのサポートは、基本的に 1 つの MaxCompute テーブルの走査と読み取りに限定されているため、アルゴリズムの学習者は MaxCompute 上で上記の SQL を実行し、結果を最終サンプルとして別の結果テーブルに書き込む必要があります。
同時に、サンプルに関するアルゴリズム スチューデントの実験的反復は、主にランクと列の 2 次元で実行されます。
-
行レベルの反復実験とは、負の例のサンプリング比率を変更したり、さまざまなシナリオからサンプルをスクリーニングしたりするなど、サンプルをつなぎ合わせる動作フローに実験的な変更が加えられることを意味します。
-
列レベルでの反復実験は主に、アプリ属性テーブルの追加や元のテーブルへのいくつかのフィールドの追加など、さまざまな次元のさまざまな機能を追加することです。
また、上記のトレーニング プラットフォームの制限のため、アルゴリズムは基本的に、そのような実験ごとに上記の疑似コードと同様の MaxCompute タスクを追加し、さらにサンプル テーブルを生成する必要があります。
この一連の制作プロセスが公共業界の概念に相当するものであれば、主にフィーチャーストアシステムにおけるオフラインバッチデータ処理プロセスになりますが、MaxCompute は通常 Hive/Spark などのシステムに相当しますので、興味のある方はご自身で参照してください。
2.2 主な矛盾の分析
上記の現状から、サンプルなどのタスクの 2 つの重要な属性を抽出できます。
-
構築ロジックの観点から見ると、サンプル テーブルは非常に典型的なスター モデルです。動作フロー テーブルはファクト テーブル、その他のテーブルはディメンション テーブルです。同時に、トレーニング プラットフォームの制限により、サンプル テーブルはこのスターモデルの実体化を完了するには、 が必要です。
-
サンプル実験の構築ロジックに特有のものは、実際にはファクト テーブルとディメンション テーブルの増減であり、SQL の完全な構築と比較して、各実験の変更は通常 1 つまたは 2 つのテーブルに限定されます。
次に、アリの電子商取引分野のシナリオでは、スターモデルの完全な拡大により、次の 3 つの側面が影響を及ぼしています。
-
単一のサンプル タスクは複雑で、多くのリソースを消費します。グループの多くのシナリオでは、1 日のサンプル数が数億、さらには数十億であり、各ディメンション テーブルのディメンションが小さくないため、製品テーブルはもともと 10 億レベルのディメンションです。クラスは数千億に達する場合があります。サンプル タスクは通常、少なくとも 7 つまたは 8 つのそのようなテーブルを結合します。MaxCompute などのオフライン コンピューティング プラットフォームの場合、このレベルのタスクの最も基本的な方法は、ソート マージ結合をラウンドごとに実行することです。結合キーの再シャッフル非常にリソースを大量に消費するため、特定の規模のシナリオでは、デフォルトの実装はまったく実行することさえできず、最適化のためにハッシュ クラッザーや分散マップジョインなどのメソッドを使用する必要があります。この結合を高速化するために、MaxCompute の上に kv タイプの外部サービスの別の層も導入されており、過去数年間、内部アルゴリズム プラットフォームは同様の原理で機能してきました。
-
ストレージの冗長性: 一部のディメンション テーブルでは、動作テーブルの大きなテーブルと結合されるため、ディメンション テーブルの行が最終サンプル テーブルで何十万回も繰り返されることがあります。ターゲット製品と動作シーケンスのサンプルがいくつ存在するか、および iPhone 製品側の機能が完全に冗長的に格納されている数がいくつあるか。統計によると、メインの検索サンプルでは、さまざまな動作シーケンスの製品属性がデータ スペースの 2/3 を占めていました。完全なマテリアライゼーション展開の最終結果は、ヘッド シーン内の ttl が 30 日のサンプルが、数ペタバイトの MaxCompute ストレージ スペースを直接占有する可能性があることです。
-
データを追加および変更するにはテーブル全体を更新する必要があります: MaxCompute 自体には既存のパーティション テーブルの一部の列を変更する機能がないため、データを修正したり機能を追加したりする必要がある場合、唯一のオプションはそれを再度実行することです。このプロセスでは、他の無関係なフィールドも再度完全に読み書きされます。また、アルゴリズムの実験要件は、上で説明した膨大な量の計算とストレージの消費量が直接的に 1 桁増加することを意味します。どれだけの実験を行いたいですか? これらのタスクはどれくらいの数のサンプル タスクを完全に実行する必要がありますか?この 2 つの結合の間には、結合が 1 つ多いか 1 つ少ないかの違いしかない可能性があります。これら 2 つの点を理解すると、サンプル タスクが MaxCompute のリソース キラーと呼ばれる理由が十分に理解できます。
2.3 解決策
シーンから抽出され、データベース ドメインの概念を使用してサンプルの問題を説明すると、MaxCompute サンプルの問題の本質は次のように抽象化できます。複数の複雑だが非常に類似した星型モデル ビューが強制的に表示されます。コンピューティングとストレージのリソースの問題を具体化し、拡大します。
この問題を抽象化すると、私たちの解決策のアイデアは非常に明確になります。データ処理層とトレーニング層の間にクエリ層を追加し、トレーニング中に計算ロジックの一部をクエリ層に遅延させて、実験サンプルを論理的に繰り返すことができるようにします。一部はクエリフェーズで繰り返されるクエリとなり、コンピューティング層はコンピューティングプラットフォームによる処理に適したロジックの一部と実際の増分データのみを処理するため、リソースと効率の点で最適に近づくことができます。
行と列の実験では、ネガティブ サンプルのサンプリング比の調整と特徴テーブルの追加という 2 つの典型的なシナリオを考えることができます。
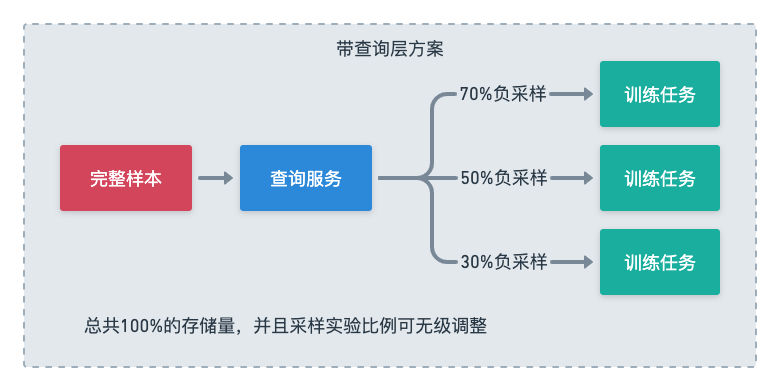
ネガティブ サンプルの調整とは、サンプル内のネガティブ サンプルをサンプリングすることを指します。これは、シーンによってはネガティブ サンプルが多すぎる可能性があり、モデルのトレーニングには役に立たないためです。以前のモデルでは、この種の実験は、複数のファクト テーブルを作成し、複数のサンプル テーブルを構築することによってのみ実行できました。
システムに SQL クエリを実行できる機能がある場合は、完全な負の例を含むファクト テーブルを保持し、SQL で条件付きステートメントをクエリすることでいくつかの負の例を直接フィルタリングしてから、さまざまなディメンション テーブルをフィルタリングされたレコードと結合することしかできません。異なる比率でのトレーニングは、SQL パラメーターを調整するだけで済みます。サンプルを繰り返し生成する必要はなく、異なる構成で複数のトレーニング タスクを直接開始できます。

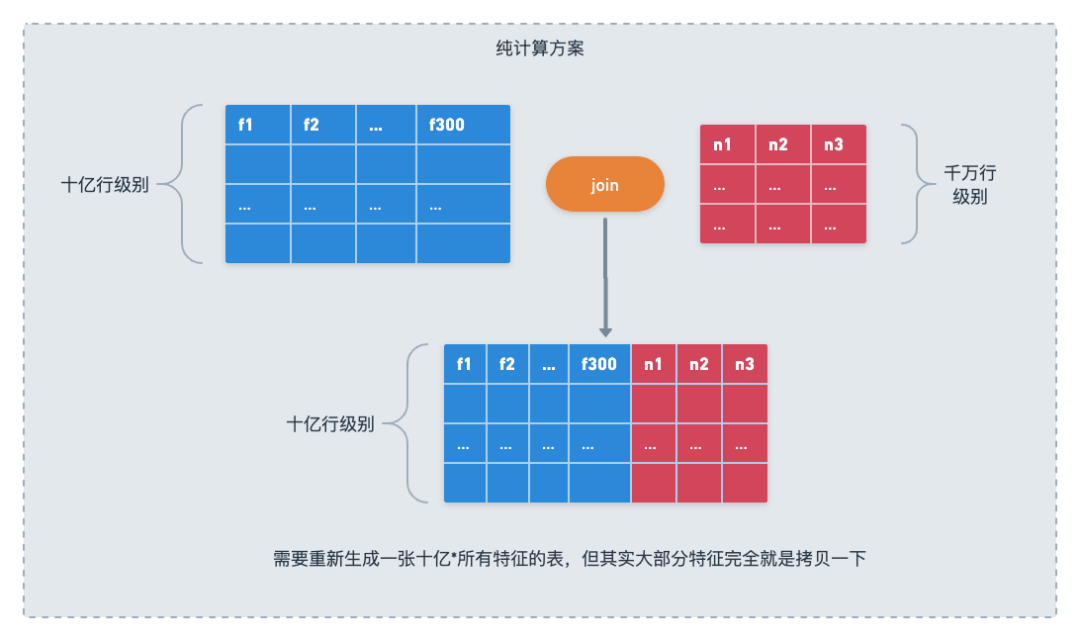
新しく追加されたフィーチャ テーブルも、従来のモードで新しいサンプル テーブルを生成する必要があります。これは、サンプル テーブル データ全体を書き換えることを意味します。SQL クエリ機能を備えたシステムでは、これは、スター モデルの処理方法と同じです。従来のデータベースの場合、この新しいフィーチャ テーブルのデータを準備するだけで済み、以前のファクト テーブルとディメンション テーブルをまったく変更することなく、クエリ時に直接結合できます。

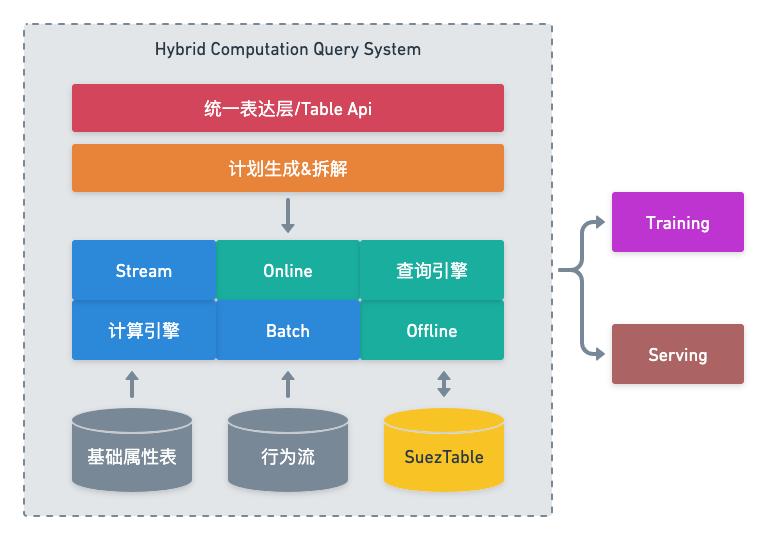
私たちはこのシステム全体をハイブリッド計算クエリ システム (ハイブリッド計算クエリ システム) と呼びます。これは、完全にコンピューティング層を通じてサンプルを生成する以前のシステムとは異なります。
3. システムアーキテクチャ
3.1 クエリ層テクノロジーの選択
アイデアを決めたら、次はテクノロジーを選択する必要がありますが、サンプル シナリオの観点から、どのようなクエリ レイヤーが必要でしょうか? 要点を次のように要約します。
フル機能の SQL のサポート: 前述のように、サンプル自体の完全な構築プロセスは、SQL ベースのロジックの 1 つ以上の段落で記述するのに適しています。従来の MaxCompute バッチ サンプル構築自体は、サンプル構築を記述するために特定の MaxCompute SQL を使用します。クエリ層はフル機能の SQL もサポートしているため、適切な計算をクエリ層に柔軟に転送できるほか、このプロセスや内部ロジックがユーザー (アルゴリズムの学生) にとって理解しやすくなります。
堅牢なインデックス作成機能: 結合をクエリ ステージに転送する場合は、ディメンション テーブルに事前にインデックスを作成する必要があります。また、クエリ レイヤーには堅牢で安定したインデックス作成機能と、成熟した高速な構築プロセスが必要です。
読み取りおよび書き込みの超高スループット、ミリ秒レベルの遅延のサポート: トレーニングおよび読み取りプロセス中に、サンプルは実際に完全なファクト テーブルをスキャンし、複数のディメンション テーブルを結合します。また、集計関数が後に続く olap タイプのタスクとは異なり、トレーニングには行全体のすべてのデータが必要であり、大規模なシナリオでは全体のスループットが数十 GB/秒に達することもあります。同時に、トレーニング側のデータキュー自体は通常比較的小さいため、トレーニングを妨げないように、単一クエリのレイテンシもミリ秒レベルに保つ必要があります。
ネイティブ コンピューティングとストレージの分離: サンプルのロジック構築プロセスで最終的にどの物理テーブルと対応する組み合わせロジックが分解されるかに関係なく、複数のサンプルと各サンプルをクエリ クラスターのメモリまたはストレージに複数日間保存することは不可能です。ローカル ディスク はい。客観的には、クエリ システムがコンピューティングとストレージの分離をネイティブにサポートする必要があります。同時に、暗黙の要件は、ストレージ層への負担を軽減し、トレーニング側のスループット要件を満たすために、クエリ層が豊富で柔軟なキャッシュ メカニズムを備えている必要があるということです。
リアルタイムデータのサポート:
-
一方で、odl (オンラインディープラーニング) サンプルのサンプル実験で遭遇する問題は、バッチサンプルの場合と本質的に同じですが、odl サンプルは長期間保存されず、ストレージの問題は発生しません。第 2 に、長い間、ODL サンプルを構築するのは明らかに困難であり、多くのシナリオでは実験サンプルを維持できません。また、クエリ レイヤー自体がテーブル ソースとしてリアルタイム データ ソースをサポートしている場合、実際には、ODL サンプルをさまざまな行と列の実験に使用することもできます。
-
一方、フィーチャ ディメンション テーブルには、実際には強いリアルタイム性が要求されます。多くのフィーチャは、イベントの発生時間に関連しています。以前は、この種のディメンション テーブルは MaxCompute 上で作成できなかったため、近似シミュレーションまたは埋め込みポイントが使用されていました。特徴のこの部分はある方法で生成でき、クエリ レイヤー自体が時系列データベースと同様のデータ ストレージと読み取りをサポートしている場合、特徴のこの部分は実際にオフラインで生成できます。
クエリ層の要件を分析し、さまざまな実際の調査を行った結果、サンプル実験計画のクエリ層として ha3 SQL を使用することを最終的に決定しました。
ha3 sql の基礎となるコンポーネントは、グループ検索をサポートする ha3 エンジン (havenask、オープン ソース) から開発されており、そのコア コンポーネントの Indexlib は、上記の最後の 4 つの懸念事項を十分にサポートでき、長期間にわたってテストされています。ただし、ha3 SQL 自体は、従来のクエリ式をカスタムの ha3 SQL 方言に置き換えます。サンプル シナリオのタスクの主な難しさは、複数テーブルの連続結合の規模と性質にあります。ロジック自体を構築するために必要な SQL 式は、現在、ha3 SQL は完全に機能します。
同時に、ha3 sql も AIOS システム内のプロジェクトであり、問題のトラブルシューティングや機能の拡張など、ロジックまたは意志の限界を達成することができます。
3.2 製品機能の形式
クエリ レイヤーの実行時の選択はまだ完了していません。このアイデアを使用可能な製品機能に変える方法については、次のような一連の質問に答える必要があります。
-
サンプルの構築ロジックをどのように記述するか? ユーザーはこのロジックをどこに記述しますか?
-
サンプル ビルドが依存する MaxCompute テーブルをいつ、どのように ha3 システムにインポートしますか?
-
トレーニング プラットフォームはこの新しいクエリ レイヤーとどのように連携するのでしょうか?
この作品の全体的なアイデアは次のとおりです: 上記のサンプルと同様の DSL のセットを使用して疑似コードを構築し、ユーザーがサンプル ロジックを記述できるようにします。この DSL を通じて、依存する MaxCompute テーブルの情報を取得できます。 ha3 をインポートするための定期的な ETL タスクを作成するため、DSL に従って最終トレーニング クエリ サンプルに必要な ha3 SQL を生成することもできます。
DSL 部分については、最終的なテクノロジーの選択は RTP Table Api (以前はオンライン機能の構築に使用されていた Python SDK のセット、インターフェース設計は主に Flink の Table Api を参照しており、以下では Table Api の名前を使用します) です。具体的な例技術的な詳細については、次の章で詳しく説明します。機能プロセスの観点から見ると、システム全体のプロセス アーキテクチャは次のとおりです。

4.技術的な詳細と最適化作業
4.1 DSLモジュール
DSL 自体の設計に関しては、DSL を構築するためのサンプルとして Table API にいくつかの拡張を行うことを選択しました。説明されているサンプル構築ロジックは大まかに次のとおりです。
from turing_script.sdk.itable import ITable as Table
from turing_script.biz_plugin.default_modules.base_sample_module import BaseSampleModule
class SampleDemo(BaseSampleModule):
def build(self, table_env) -> Table:
##获取基础样本表
base_sample = table_env.get_table('odps_project.base_sample')
#需要join的维表,指明pk_name和需要的字段
video_rtp_feature = table_env.get_table("odps_project.video_rtp_feature", pk_name = "video_id") \
.select("video_id, gmv_score, video_pageview")
#需要join的维表可支持多张
author_feature = table_env.get_table("odps_project.mainse_vs_author_feature", pk_name = "author_id")
#三张表按条件join,字段类型需一致,如字段名相同,可用_right_前缀来区分
sample_exp = base_sample.left_outer_join(video_rtp_feature, 'int64(video_id)=_right_video_id') \
.left_outer_join(author_feature, 'video_authorid=author_id') \
.filter("reserverd_rand_key > 0.5")
return sample_exp上記のサンプルコード自体もほぼSQLにマッピングできる処理であることが分かりますが、実際Table Apiとha3 SQLは同じルートに関連付けられており、最下層ではiqanなど多くのコンポーネントが再利用されています。そして方解石。サンプル実験自体の DSL として Table API に基づく変換を選択した理由は、主に次の考慮事項によるものです。
-
オンライン RTP サービス中のサンプルの構築と入力の構築は、実際には同じ機能の両面です。長期的には、私たちの目標はオンラインとオフラインの機能構築式を統合することなので、RTP サービス提供ステージと同じ DSL を使用して構築する傾向があります。 。
-
スケジュールやインポートなどのロジックが含まれるため、サンプル実験の DSL は実際には DDL と DML のロジックの一部を融合したものになります。SQL 構文の一部を拡張する必要があることを ha3 SQL を使用して記述すると、ワークロードが大幅に増加し、一部のロジックと関係代数のマッピングは直接的ではないため、探索段階での開発効率に影響を及ぼし、ha3 SQL に不必要な負担を加える可能性もあります。比較的、sdk 形式のインターフェースの方が SQL 以外の機能の拡張やインターフェースの互換性を確保しやすいのは、上で紹介した get_table インターフェースの性質からも明らかです。
DSL 自体に戻ると、コア インターフェイスは主に 2 つの部分で構成されます。
-
get_table は、元の Table API の scanregister_table の 2 つのインターフェイスの代替です。純粋なオンライン クエリとは異なります。サンプル シナリオでは、ユーザーがインデックスや構成などの DDL 情報を提供できるようにする必要があります。pk_name を渡すことを選択します。このインターフェースで指定するクラスパラメータ。
-
選択フィルター結合などの一般的に使用される SQL セマンティック インターフェイス。インターフェイスのこの部分の意味と構文は、元の Table API と完全に一致しており、サンプルの構築に必要な SQL アクションを基本的にカバーできます。
インターフェイスの下に、次の関数を実装します。
-
依存テーブルの分析と導出により、対応する ha3 インデックス テーブル構成が生成されます。
-
iqan や calcite などの基本コンポーネントの共有により、冗長なフィールドが自動的に削除され、欠落しているフィールドが表示されるため、これらの機能は基本的に最下層から直接利用されます。
-
クエリに使用するha3 SQLは自動生成されます。
4.2 インデックステーブルの設計
もう 1 つ慎重に設計する必要があるのは、各 MaxCompute テーブルに対応するクエリ システム インデックス テーブルの構成です。ha3 の基礎となるインデックス システム Indexlib は、多くのインデックス タイプと詳細なパラメータ構成を提供します。少し詳細すぎるため、この層の概念はユーザーに直接公開すべきではありません。サンプル シナリオの要件に従って適切なインデックス テーブル構成を見つけて、ユーザーが理解できる DSL 層のいくつかの概念とリンクする必要があります。
✪ 4.2.1 ファクトテーブル
通常、サンプル シナリオにはファクト テーブルの典型的な例が 2 つあります。1 つは、いくつかの外部キー ID と動作ラベルのみを持ち、フィールドが少ない純粋な動作フロー テーブルです。もう 1 つは、その他の構築されたサンプルです。ユーザーの期待はこれに基づいています。基本サンプルには実験用のいくつかの機能も追加されています。前のタイプのすべてのフィールドに加えて、このタイプのテーブルには生成された多数の機能も含まれています。多くのフィールドがあり、テーブルの規模は比較的大きくなります。
同時に、サンプル シナリオでのファクト テーブルの使用方法はテーブル全体を走査することですが、別の実験ではフィールドの一部のみが必要な場合があり、フィールドは他のテーブルと結合されません。この機能は、ファクト テーブルとしての上記のサンプルの大きなデータ サイズと組み合わせることで、ファクト テーブルが列格納テーブルの形式での格納に適していると判断します。列ごとに読み取ることで大量のシークを削減できる一方で、列の格納形式は圧縮に適しているため、サンプル ファクト テーブルの格納サイズを削減できます。したがって、最終的に、ファクト テーブルを、indexlib でもサポートされている AliOrc 形式のテーブルとして構成することにしました。
✪ 4.2.2 寸法表
ディメンション テーブルの要件は比較的明確です。サンプル シナリオのディメンション テーブルにはインデックス、つまり主キーが必要です。そうでない場合、同じレコードが複数の結果を結合します。ディメンション テーブルは結合ロールであり、高速な取得機能を提供するためにインデックスが必要なため、インデックスを備えた行ストレージ テーブルへの格納に適しています。また、サンプル シナリオでは、ディメンション テーブルは基本的に単一フィールドまたは二重フィールドの主キーであるためです。したがって、ディメンション テーブルの格納形式として、indexlib の kv および kkv インデックス テーブルを選択します。重複排除機能と単一主キーによる検索機能、二重主キーによる検索機能をそれぞれ提供します。
4.3 スケジュールシステム
毎日のサンプル インポート プロセスには、複数の段階のアクションが含まれます。まず、対応するソース テーブルが MaxCompute 上で生成された後、ETL 作業を実行するタスクを開始する必要があります。次に、ha3 テーブルの構築やクラスターなどの後続のプロセスの完了を待ちます。サンプルが依存するすべてのテーブルがインポートされた後にのみ、完全なクエリの ha3 SQL をメタ システムに書き込むことができます。テーブルが多数ある場合、この依存関係プロセスは依然として比較的複雑であり、完了を支援するスケジューリング システムが必要です。
MaxCompute のタスク スケジューリング自体は DataWorks システムに基づいており、アルゴリズムの学生は DataWorks のワークフローやデータの補足などの操作に精通しているため、スケジューリングのこの部分を DataWorks に基づいて実装することにしました。
3 つのきめ細かいスケジューリング タスク (シンク、待機、コミット)に分割しました。
シンク ノードは、MaxCompute のソース テーブル出力ノードのスケジューリングに依存して、データ エクスポート タスクを開始します。待機ノードは、シンク ノードのスケジューリングに依存し、ビルドとスイッチオーバーが完了するまで待機します。シンクと待機が 2 つのノードに分割されている理由は、次のとおりです。他の場合には、データ インポートの繰り返しを避けるために個別に再実行できます。コミットはサンプル タスク内のすべてのテーブルの待機ノードに依存し、すべてのテーブルが切り替えられた後、DSL ロジックを再実行して、その日の特定の出力パーティションを含むテーブル名 テーブルの名前、出力完了クエリは SQL を使用してメタ システムに書き込まれます。
DataWorksのOpenApiシステムに接続し、インターフェースを介して各チームのプロジェクトに上記ノードを直接登録することで、ユーザーは上記DSLを用いてサンプル構築プロセスを記述するだけで、これらのノードが自動で作成されます。
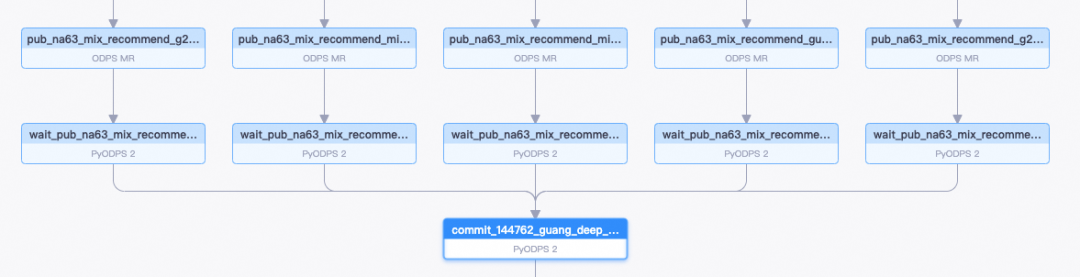
より複雑なサンプル スケジューリングの例は次のとおりです。
4.4 クラスターの展開と管理
外部的には、私たちがユーザーに公開しているのは、データベースに似た DB の概念です。同じ DB 内のすべてのテーブルが表示されます。複数のサンプルが同じテーブルに依存している場合、これらのテーブルは繰り返し作成およびインポートされず、共有されます。これにより、その後の機能、ラベル、その他の動作のチーム間共有の可能性のためのスペースも確保されます。
現在、私たちは国内のさまざまな地域にコンピューター室のパブリッククラスターを構築しており、アルゴリズムチームプロジェクトが所属するコンピュータールームに応じてどのパブリッククラスターを使用するかを決定しています。インポート リンクでは、リージョン間の長距離伝送帯域幅を避けるために、MaxCompute クラスター、transit swift クラスター (Kafka と同様)、ビルド クラスター、および Pangu クラスターが同じリージョン内にあることが保証されます。 、トレーニング クラスターはデフォルトで構成されており、DB クラスターおよび Pangu クラスターと完全に同じコンピューター ルームに配置されるため、同じ都市内でコンピューター ルーム間の帯域幅が完全に回避され、コストが削減されます。
この部分は全体としてユーザーに対して完全に透過的であり、ユーザーは最初に MaxCompute コンピューター室の場所に応じて適切な DB を選択するだけで済みます。
ただし、現在のクラスター管理の運用および保守作業では、このモードにはいくつかの問題も発見されました。
業務分離:クラスタを共有しているため、業務チーム間で相互影響を与えるリスクがある(例えば、あるチームがある日大量のテーブルをインポートすると、他のチームのテーブル切り替えを妨げたり、リソースを占有したりする可能性がある) 。その一方で、これはサービスの請求に多大な問題を引き起こしており、各ビジネスがクラスターのリソースをどれだけ使用しているかを知るのが困難です。
単一クラスターの規模が大きすぎる:クラスターの混合使用と各チームの MaxCompute コンピューター室の偏在により、一部のクラスターの上の表の規模はすでに大きすぎ、リソースを確保できない問題があります。ビジネス ニーズに応じて直線的に拡張する必要がありますが、より大きな問題は、ha3 ベースのシステムと運用保守プラットフォームが以前はオンライン クラスターを中心に設計されていたためです。サンプル シナリオのように 1 つのクラスターに数百のテーブルが存在するわけではないため、運用保守の過程で一連の問題が発生し、木樽のショートボードではスイッチングが著しく遅くなったり、サービスが利用できなくなったりする問題が発生し、さまざまな手段で問題を解決してきましたが、短期的には、単一クラスター規模のリスクは常にダモクレスの剣です。
したがって、この部分における次の変革の方向性は、上記の問題を回避するために、小さなクラスターを解体し、チームとタスクの粒度に基づいたクラスター管理モデルを提供することです。
4.5 トレーニングプラットフォームのドッキング
同時に、HA3 SQL サンプルのモデル トレーニング プラットフォームへの適応も行っており、トレーニング終了によって最終的に取得される各パーティションのクエリ SQL はおおよそ次のようになります。
SELECT *
FROM (SELECT *
FROM (SELECT *
FROM mainse_video_ha3_sample_ds_20221123
/*+ SCAN_ATTR(batchSize='1', partitionIds='0', localLimit='100')*/) AS t0
WHERE pv = 1 AND content_type = 'video') AS t1
INNER JOIN (SELECT pv_id, item_id, label, cart
FROM mainse_video_click_to_pay_backbone_v2_ds_20221123) AS t2 ON t1.pv_id = t2.pv_id AND t1.item_id = t2.item_idトレーニング セッションの場合は、さまざまなパーティションからのサンプル。おそらく SQL ステートメントは異なるでしょう。たとえば、ある日からフィールドがディメンション テーブルからファクト テーブルに転送され、このパーティションから始まる SQL が変更されますが、これは実際にはトレーニング側には透過的であり、トレーニング側では SQL を使用するだけで済みます。クエリすることができます。
パーティション分割されたサンプルの場合、エンジン サービスのメモリ負荷を考慮し、データをシャッフルするために、通常は 256 列に分割します。クエリを実行する場合は、ヒント パラメーター SCAN_ATTR で特定の列を指定します。開始点と制限を指します。これは、すべてのデータを多数の小さなフラグメントに分割することと同じです。
データ読み取りの実装に特有のものは、次の操作を連結することで実現します。
GenStreamSqlOp:サンプル名とパーティション リストに従ってフィーチャー センター API から毎日のメタ情報 (ドキュメント数、毎日の SQL ステートメント テンプレートなど) を取得し、それを多くの小さな文字列に分割します。各文字列は、part_id、 start_row など;
WorkQueueOp:グローバル キュー。すべてのワーカーがトレーニングしているとき、このグローバルに一意のキューから読み取られるサンプル フラグメントを取得し、GenStreamSqlOp の結果をキューに入れ、毎回チェックポイントを保存します。キューの消費情報の一部を記録します。通常のトレーニングフェイルオーバーを実現します。
SqlReadUpToOp:キューから取得されたシャードは、対応するパーティション情報に従って完全な SQL に復元され、操作でストリーミング クライアントを介してリモート ha3 から結果が取得されます。オフライン トレーニング環境はオンライン環境のコンパイル環境とは異なるため、互換性の問題を防ぎ、その後のバックエンド サービスのアップグレードを容易にするために、オンライン結果を一度カプセル化し、テンソルの形式で返します。
4.6 パフォーマンスの最適化
✪ 4.6.1 ETL
サンプル実験機能の基本的な考え方は、サンプル構築のロジックの一部をクエリに置き換えることであるため、データ インポートの効率は私たちの注目すべき重要なポイントです。MaxCompute タスクのこの部分は保存でき、それに応じて、複数のテーブルの ETL が新たに追加されたタスクである場合、2 つのタスクの速度の違いは、ユーザーがプラットフォームの機能を使用するときに最初に感じる詳細であり、このリンクでユーザーに印象的な比較を提供する必要があると考えます。
従来の MaxCompute データ エクスポート タスクは、基本的に MaxCompute トンネル機能を通じて実装されていましたが、使用中に次の 2 つの大きな問題に気づきました。
-
トンネル機能では、対応する転送サービスと対応するフロー制御クォータをポートするために MaxCompute が必要です。比較的大きなテーブルをインポートする場合、フロー制御により速度が急激に低下することがよくあります。
-
一部の列のみをエクスポートする機能がないため、テーブル内の少数の列のデータのみをエクスポートする必要がある場合があり、トンネルを使用すると無駄が発生します。
つまり、ETL プロセスでは最初に元のデータ システムからデータを読み取るときにボトルネックが発生するため、タスク全体の速度について話す必要はありません。この部分の問題を解決するために、独自の Swift サービスを使用してレイヤー転送を実行し、MR タスクを介して Swift にソース テーブル データを書き込み、後続のビルド タスクで Swift トピックを使用するという考え方を変更しました。情報元。このような MR タスクは基本的に最も単純なトラバーサル ロジックであり、消費する CU が非常に少なく、必要なフィールドをオンデマンドで読み取ることができます。
エクスポート レベルでの問題を解決した後、ファクト テーブルとして前述した基本的なサンプルに対して特別な最適化も行いました。このタイプのテーブルは、大規模、多くのフィールド、シンプルなインデックスが特徴です。 swiftを使用する トランジットとして、swiftを利用してデータシャッフルを実装することができます この前提の下では、従来のインデックス構築タスクにおけるプロセッサ-ビルダー-マージの3段階のプロセスは少し無駄に思え、不安定なオフラインの現状タスクのリソースや頻繁な起動と停止もテーブルの構築速度に影響します。
したがって、読み取りおよび書き込み機能を備えた AIOS ストレージ サービス 2.0 を使用し、オンライン リソースを使用してテーブルの構築を行うサービス指向書き込みクラスターを使用します。一連のパラメータ調整テストの後、30T サンプルテーブルのインポートを 1 時間で安定して完了できます。
✪ 4.6.2 ストリーミングの実行
上記のトレーニング プラットフォームのドッキング セクションで述べたように、トレーニング側で実行される最終クエリはスライスされた SQL であり、トレーニング データのバッチ処理の必要性を考慮すると、このスライスのサイズは通常約 1w です。初期測定によると、この種のクエリは、キャッシュがすでにヒットしている場合でも依然として大きな rt を持ちます。そのため、後続のモデルの消費量を満たすのに十分なスループットを実現するには、トレーニング側で複数のクエリを同時に開始する必要があります。 。調査の結果、主な理由は、ha3 SQL の実行スケジューリング層がバッチ タスクのスケジューリング モードに比較的近いためであることがわかりました。たとえば、次の実行図の場合:
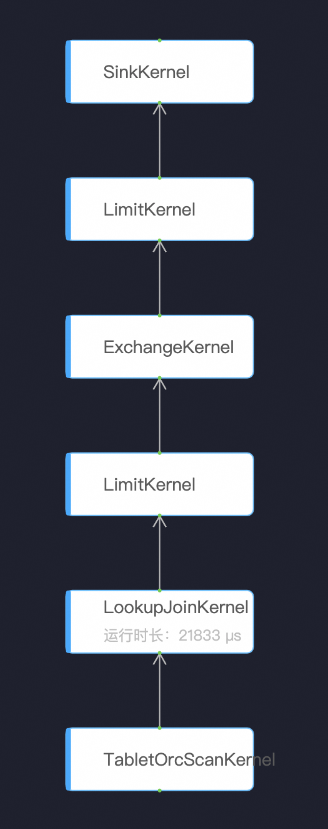
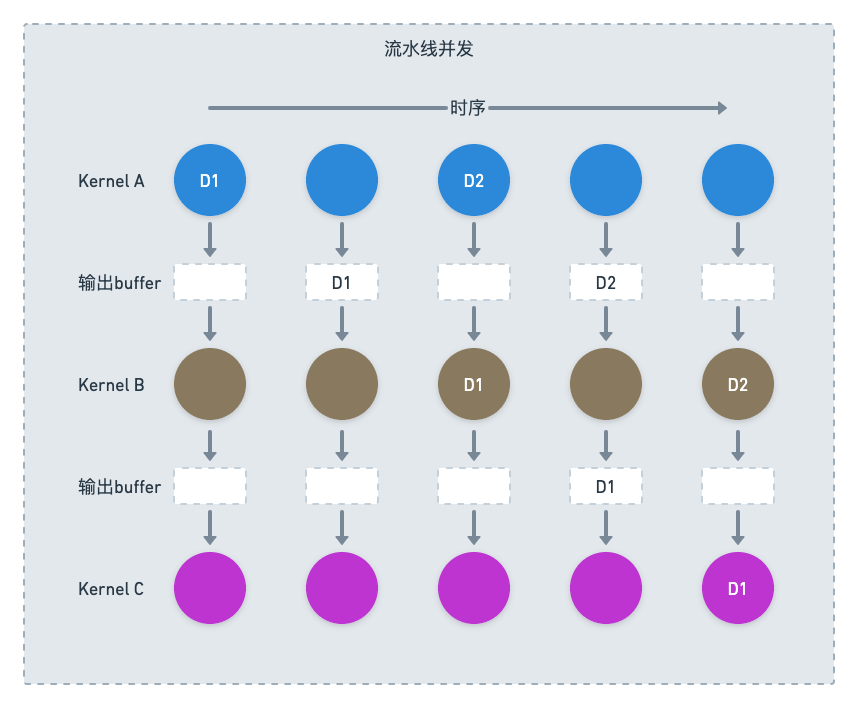
これは確かにシリアル依存関係グラフであるため、サーバーは並列処理なしで直接実行することしかできず、rt は非常に印象的です。この問題を解決するために、ha3 の学生たちは新しいストリーミング実行エンジンを開発しました。新しい実行エンジンでは、上流カーネルと下流カーネルがキューによって接続されます。各カーネルは、上流キューにミニバッチがあることを発見します。データの後で計算を刺激できるため、論理的に純粋なシリアル プロセスが並列化されます。
✪ 4.6.3 キャッシュ
クエリ レイヤー テクノロジの選択で述べたように、サンプル シナリオのため、テーブルの合計サイズはクラスターのメモリ制限を確実に超えるため、完全なデータは Pangu クラスターなどの DFS システムにのみ配置できます。 HDD オフライン Pangu の場合、インデックスのクエリなど、複数のシーク アクションを伴う操作は、クエリ速度が期待を満たすためにキャッシュ メカニズムを経由する必要があります。Indexlib には、IO 層に統合されたブロック キャッシュ メカニズムがあり、このテクノロジーはファクト テーブルとディメンション テーブルを同時にキャッシュするのに役立ちます。
さらに、使用の面では、サンプル シナリオのいくつかの一般的なビジネス特性を考慮して、より良いキャッシュ ヒット率が得られるようにデータ分散モードのいくつかのプリセットを作成しました。通常、ファクト テーブルには pv_id と item_id の 2 つの主キーがあるため、ファクト テーブル クエリのキャッシュ局所性が向上するように、pv_id に従ってファクト テーブルを 256 列に分割します。 -dimension 通常 pv_id を保持するディメンション テーブル 主キーの 1 つとして、このタイプのテーブルを pv_id に従って 256 列に分割します。その後、単一列のローカル結合として実行プランを最適化できます。他のディメンションのディメンション テーブルの最適な状態は、主キーの性質と規模に従ってテーブルを個別の列に分割し、デプロイメント上で個別にデプロイすることです。
さらに、オンライン クラスターのディスクは SSD であり、ディスクからの読み取り速度はオフラインの Pangu からの読み取り速度よりも 2 ~ 3 桁高速であることにも気付きました。ディスクをキャッシュのレイヤーとして使用すると、キャッシュスペース。また、indexlib の機能のおかげで、簡単な設定でこの層の機能を使用できるようになります。クラスターの現在の一般的な構成は、LRU の排除に基づいて、128G ディスク ストレージと 16G メモリです。
5.シナリオコストのケース
MaxCompute サンプルを接続して置き換えたいくつかのシナリオの前後の具体的な使用方法とコストの比較事例を共有します。
5.1 マルチシナリオの一般的なサンプル
私たちがサービスを提供しているアルゴリズム チームの 1 つは、複数のシナリオの推奨モデルを管理しています。各シナリオで使用される特徴は同じです。以前に特徴プラットフォームの完全埋め込みポイント機能に接続したことがあり、すべてのシナリオはセットを通じて均一に埋め込まれていますその後、各シーンは、オフライン トレーニング中に個別にトレーニング用に独自のシーンのサンプルを使用する必要があります。概念的に言えば、この使用方法は前述の行レベルの実験ですが、その前に、アルゴリズムは MaxCompute で生成した完全に埋め込まれたポイント サンプルのみを追跡し、さまざまなシナリオのいくつかのサンプル テーブルをフィルターで除外し、個別に読み取りをトレーニングします。サンプル実験機能の導入後は、すべてのシーンを含む完全に埋め込まれたポイントサンプルをインポートするだけで済み、学習時に各シーンがシーンIDに従って直接フィルタリングされる構造になります。
アルゴリズムチームにアクセスした後、オンラインでの微調整と厳格なABが行われ、以前のリンクと比較してオフライン効果が一貫しており、モデルは毎日2時間早くオンラインに切り替えることができます。すべてのシナリオで、使用される Pangu ストレージは PB レベルから TB レベルに直接削減されます (両方の物理ストレージ サイズ)。
5.2 リコールサンプル
ビジネス リコール シナリオのサンプルは、スター モデル構築サンプルの非常に典型的な例であり、サンプル コードを直接見ることができます。
from turing_script.sdk.itable import ITable as Table
from turing_script.biz_plugin.default_modules.base_sample_module import BaseSampleModule
class SampleDemo(BaseSampleModule):
def build(self, table_env) -> Table:
base_sample = table_env.get_table('odps_project.base_sample', shard_key="pvid", with_extra_rand_key = True)
#需要join的维表,指明pk_name和需要的字段,可支持多张
user_feature = table_env.get_table("odps_project.user_feature", pk_name = "id")
content_pos_feature = table_env.get_table("odps_project.content_pos_feature", pk_name = "id")
content_neg_feature = table_env.get_table("odps_project.content_neg_feature", pk_name = "id")
# sequence feature
sequence_feature = table_env.get_table("odps_project.sequence_feature", pk_name = "pvid")
#三张表按条件join,字段类型需一致,如字段名相同,可用_right_前缀来区分
sample_exp = base_sample.left_outer_join(user_feature, 'user_id=_right_id') \
.left_outer_join(content_pos_feature, 'content_id=_right_id') \
.left_outer_join(content_neg_feature, 'neg_content_id=_right_id') \
.left_outer_join(sequence_feature, 'pvid=_right_pvid') \
.select("is_clk as label, *")
return sample_expこのコードは基本的に、MaxCompute でサンプル テーブルを生成する最後のタスクと同等の置き換えです。以前は、このサンプルは MaxCompute に 8 日間保存され、PB レベルのストレージを占有する可能性がありました。HA3 SQL サンプルに移行した後は、テーブルとディメンション テーブル、サンプルを 14 日間保存しただけで、数十 TB のストレージ スペースが使用されました。
6.学んだ教訓と展望
サンプルシーンは当社が長年注目し、投資してきた分野であり、技術的な試みは2、3年前に遡ることもできますが、これまでの歩みを振り返ると、技術や製品には多くの思いが込められていますあなたと共有する価値のあるデザイン:
-
フルリンク技術スタックを制御できるかどうかは、この複雑なシステム間プロジェクトの成否に直接影響します。実際、サンプルの構築と保存の問題を解決するためにクエリ レイヤーを導入するというアイデアはありましたが、適切なシナリオ、要件の特定の実装を見つけることができませんでした。しかし、今振り返ってみると、この記事で言及されている ha3 ストリーミング実行エンジンの変換、書き込みクラスターの直接書き込みインデックス、または言及されていないさまざまなクエリ プランによって生成されるバグ チェック、および詳細なランタイム メモリ管理ロジックの変更については、など、さまざまな基盤となるシステムを直接変換する方法がなければ、このプロジェクトを最終的に完了できるとは想像しにくいです。
-
統合されたコードベースによってもたらされる統合の反復速度の利点は重要であり、蓄積されます。この記事では、基盤となるシステム チームが開発した多くの新機能を使用し、プロジェクト メンバーもさまざまなシステムで多くの機能を追加したり、バグを修正したりしたと述べました。また、AIOS チーム全体のコードは基本的に統一されたモノ リポジトリにあるため、他のシステムの最新機能を使用する場合でも、自分でシステムを学習して変更する場合でも、非常に低コストで行うことができ、効率が大幅に向上します。
-
システムを迅速にデバッグできることは非常に重要ですが、当初は、ユーザーがサンプル DSL を学習するのにかかるコストが非常に高く、この部分に答えるのに多くの時間を費やすことになるのではないかと非常に心配していました。しかし、オンラインになってからは、Web IDE 開発環境を構築しているため、ユーザーはページ上で DSL を直接コンパイルし、特定のエラー レポートを直接確認できることがわかりました。この試行プロセスは非常に高速であり、質問に答えるよりもはるかに高速です。私たちのニーズへの答えは主に特定のスキームといくつかのテーブルの推奨構成であるため、試してみてください。
サンプル実験機能はまだ若い製品ですが、今後も以下の点で改良を加えていきます。
-
クラスターの導入形式は、チームとタスクの粒度によって進化する傾向があり、ユーザーの分離と柔軟性が向上し、超大規模クラスターでの一部のリスクが回避されます。しかし同時に、規模の問題に備えるために、運用、メンテナンス、およびランタイム システム全体をオフライン規模のシナリオに合わせてタイムリーにリファクタリングおよび最適化する必要もあります。
-
クエリ パフォーマンスの最適化に関しては、サンプルの読み取りがトレーニングのボトルネックにならないように、マルチゾーン分割テーブル最適化キャッシュ、自動拡張と縮小、およびスケジューリング パラメーターの自動調整を通じて、サンプル クラスターのクエリ パフォーマンスとコストが継続的に最適化されます。 、同じスループット LF の下でサンプル クラスターが削減されます。
-
サンプル実験の具体的な機能は、あらゆるレベルでの多値MaxComputeテーブルのインポートのサポート、補足データ機能の商用化、udfのサポート、ビジネスアラームメカニズムの確立など、さまざまなニーズに対応するために継続的に強化する必要があります。サンプルの反復に関するビジネスの機能要件。
-
現在、計算層のロジックは前処理としてユーザーに投げ込まれていますが、将来的には計算層のタスク生成も含まれ、部分結合の事前計算やサンプルなどの機能も担う予定です。製品全体を真に実行できるようにするためのデータ分析、ハイブリッド コンピューティング クエリへの対応。