記事ディレクトリ
試合終了から2ヶ月以上が経過しました。
プロセス全体は依然として非常に難しく、初期段階ではチーム全体が学習の基礎を築いており、すべてのデータが与えられた後のモデリングに主にエネルギーが集中しています。
弁護側の通知は届きましたが、残念ながら審査員の質問があまりにも突飛で、工夫を見せることができず、最終的には特別賞を受賞することはできませんでした。
私たちの研究の概要は、関連するコンテストの準備をしている多くの学生にとって非常に役立つと思うので、確認してみましょう
Prophet を使用して製品を 1 つずつ予測するのは明らかに間違っており、トレーニング時間が長すぎます。最初に構造化データを統合してから機械学習を使用するのが合理的です
トピック
タスク 1: データ分析
提供される過去の販売データ (order_train1.csv) については、詳細なデータ分析が必要です。分析トピックには以下が含まれますが、これらに限定されません。
1.1 製品の価格の違いが需要に与える影響
1.2 製品地域の需要への影響、および各地域の製品需要の特徴
1.3 さまざまな販売方法 (オンラインとオフライン) における製品需要の特徴
1.4 さまざまなカテゴリ 1.5 特徴とはさまざまな
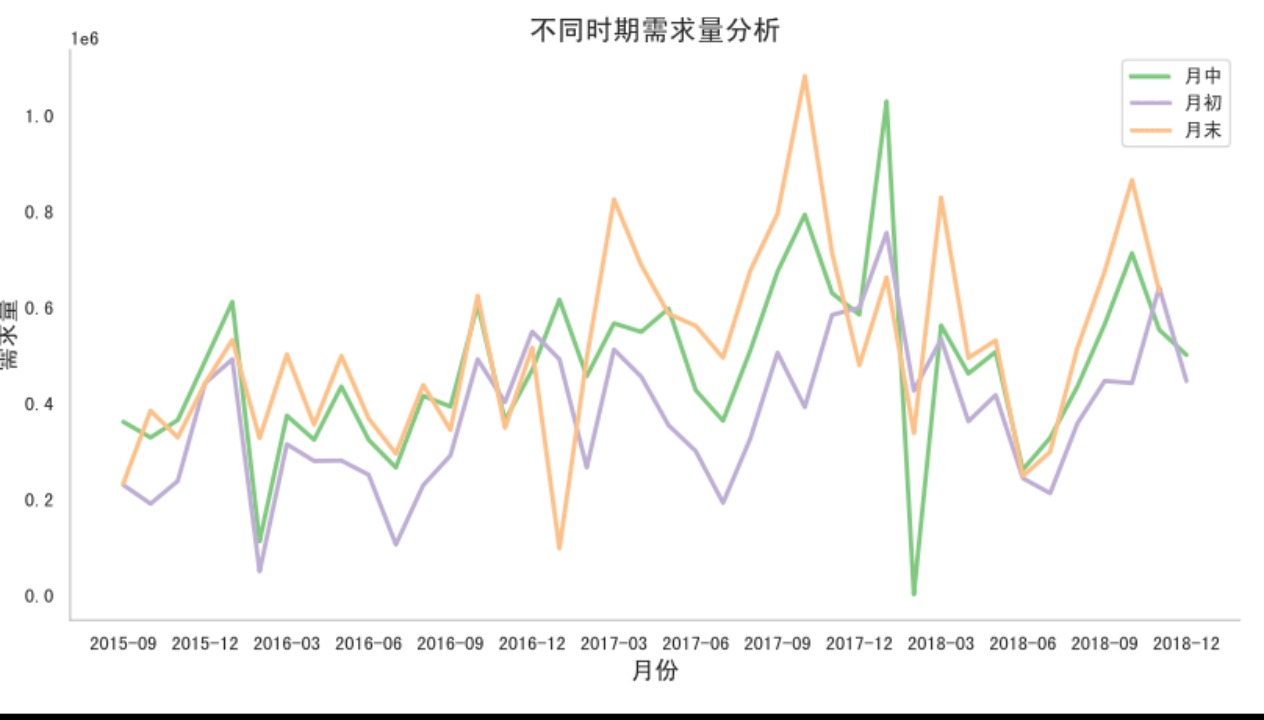
期間(月初、月中旬、月末など)での製品需要
の変化 1.6 製品需要に対する休日の影響
1.7 プロモーション(618、ダブルテンファーストクラスなど) ) 製品需要への影響
1.8 製品需要への季節要因の影響
タスク 2: 需要予測
上記の分析に基づいて、今後 3 か月 (つまり、2019 年 1 月、2 月、3 月) の特定の製品 (predict_sku1.csv) の月次需要を予測するための数学モデルを確立する必要があります。予測結果は、指定された形式に従って result1.xlsx ファイルとして保存する必要があります。
日、週、月の時間粒度に従って予測を実行し、さまざまな予測粒度が予測精度に与える影響を分析してください。
最初の質問
最初の質問はデータの探索的分析です。言うことはありません。これで、chatgpt を調整し、簡単な修正を加えて良い画像を作成できるようになりました。
タイトルの意味は、最初の質問の分析が 2 番目の質問のモデリングに役立ち、論文では見栄えがするかもしれないということかもしれませんが、正直言って役に立ちません。2 番目の質問は、特徴量エンジニアリングなどの経験に基づいています。最初の質問は重要な点ではありません。いくつかの写真を示しましょう。詳細には触れません。
- 価格と需要量の散布図

- 時間の経過に伴うオフライン/オンライン注文需要の傾向グラフ

- カテゴリ/サブカテゴリごとの需要の割合を示す二重円グラフ
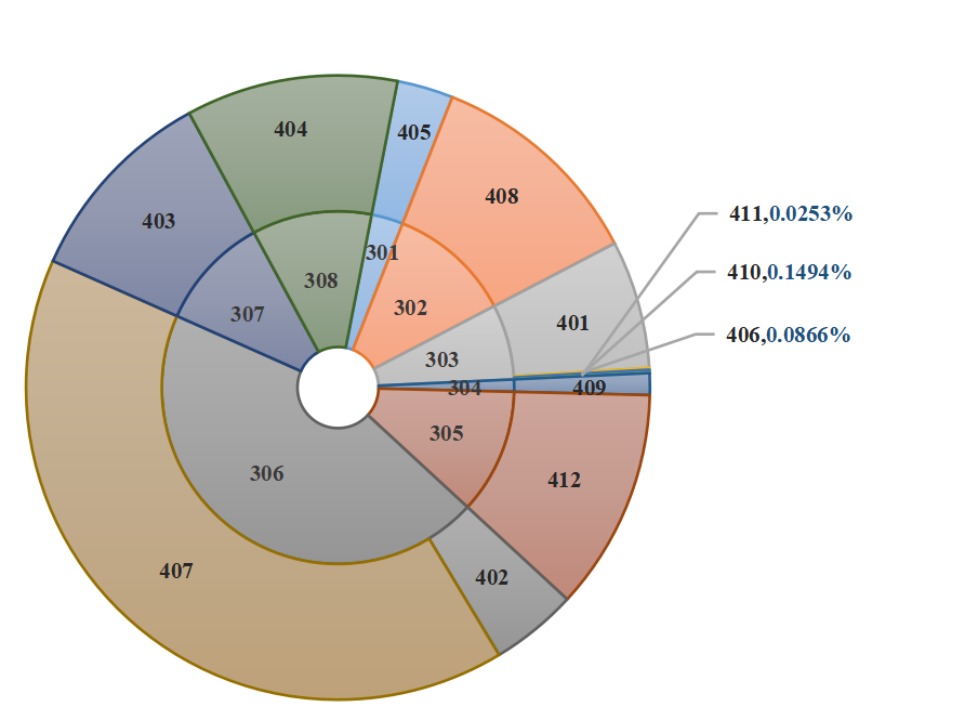
- さまざまな製品の月次需要のバブル チャート
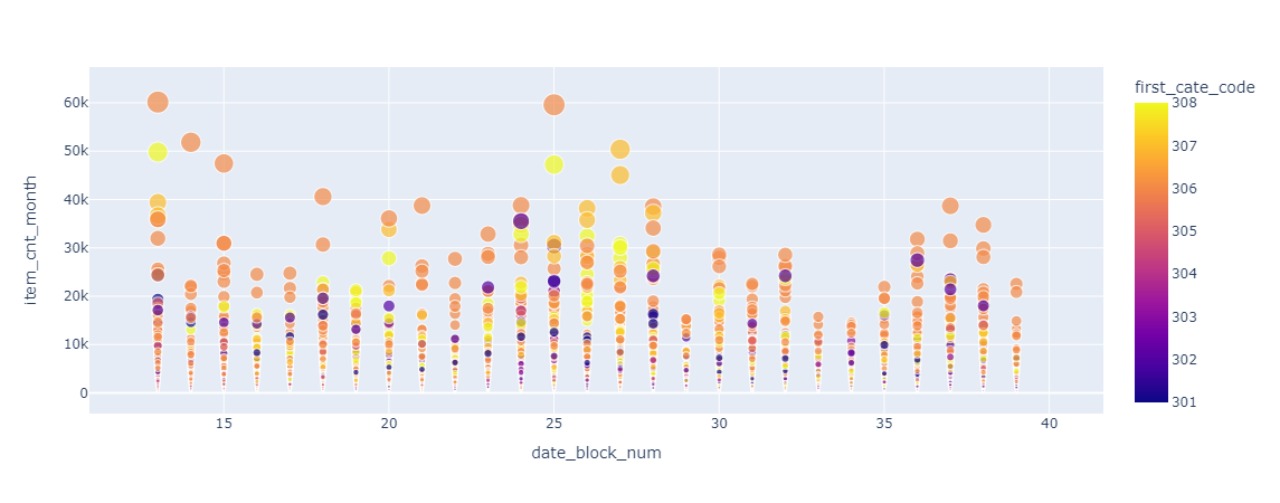
- さまざまな期間(月初、月中旬、月末)の製品需要の折れ線グラフ
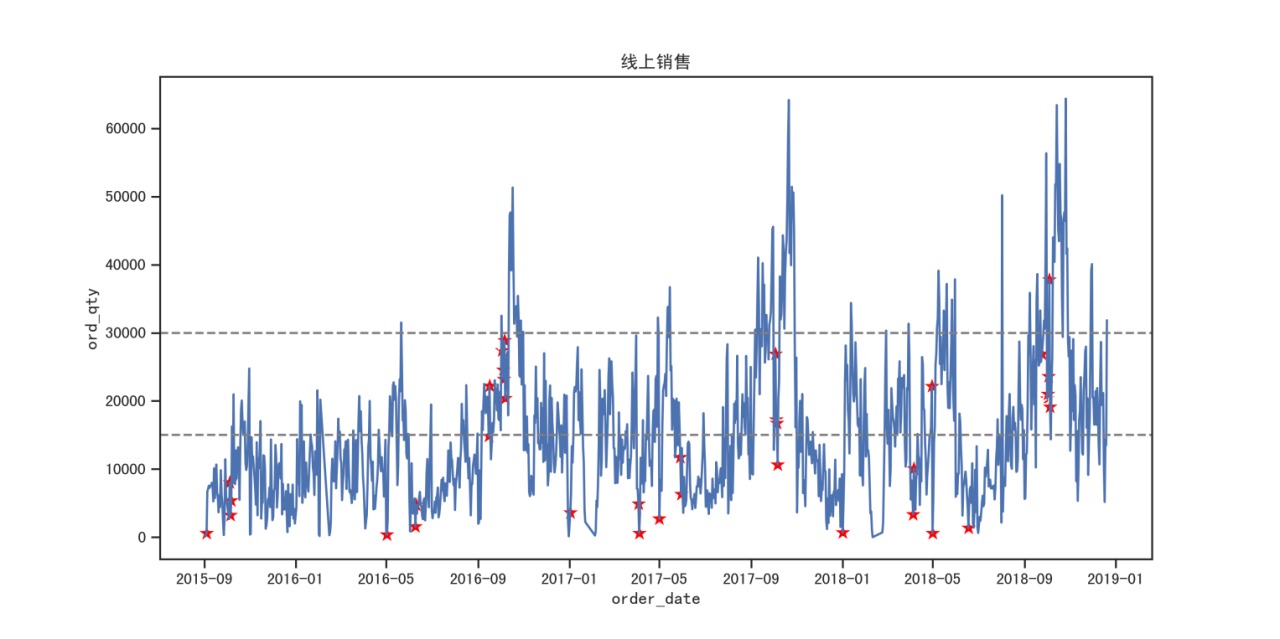
- オフライン/オンライン売上推移

- 「6.18」および「ダブルイレブン」中の上位 50 のプロモーション商品のカテゴリの双方向ヒストグラム

2番目の質問
2問目は正確に予測するというもので、学習とコーディング能力が試されるのですが、その時はkaggleを中心に売上予測コンテストのコードをいくつか読んで少しずつ変更していきました。ベースラインを設定した後、まず結果を予測し、次に独自のアイデアを段階的に追加できます。
以下内容都是先有Baseline后一步步试出来的,所以会有些跳跃性
いくつかのリンク (多くは見つかりません):
2.1 データの前処理
-
欠損値の処理
-
外れ値の検出
- 異常値が検出された製品について
- 予測セット内の項目は個別にモデル化されます (手動予測)
- 予測セット内の商品は直接削除されなくなりました
-
カテゴリデータを数値に変換する
- 販売チャネル
- 品番/商品カテゴリー/販売エリア
-
変動の大きい売上データには2つの指標があります。
- ラベルのスムージング: 対数を取得し、RMSE インデックスを使用します。
- 対数処理ではない: Tweedie 偏差を使用します (Tweedie deviance)
-
これに対処しない場合は、販売予測の精度を評価するために RMSE を使用することに問題があるはずです。
たとえば、5 元のペン (1 か月に約 5,000 個販売) の場合、予測偏差は 100 です。2,000 元(月に約 500 個販売)の時計の場合、予測偏差は 100 です。RMSEの評価も同様ですが、実は時計の予測のズレによる問題のほうが大きいはずです。トゥイーディーバイアスはこの問題を解決できる
もちろん、最初に対数を扱う場合は、RMSE を使用することもできます。
2 つのうちの 1 つを選択できますが、最終的には今でも後者を使用しています
2.2 データセット分析
2.2.1 トレーニングセット
ここでは非常に詳細なデータ分析を行っており、各カテゴリーの各製品の傾向を個別に見ると、多くの特徴が見つかります。時間的な理由からほとんど使用されませんが、これは実際のビジネス予測において重要なステップです。的を絞った方法で処理するには、このデータセットを詳細に理解する必要があります。
いくつかのポイントを列挙すると、次のようになります。
- 403/404/405:当初はオンライン、2017年からオフラインも追加予定
- 406: オフライン、小規模注文、2018.3 105 エリアから他のエリアに移動
- 407: 販売傾向には、季節的な傾向を持つ複数の小さなピークが示されています
- 411:2017年11月発売
- 2017 年以降、リージョン 104 での販売は停止され、リージョン 104 のほとんどの製品はリージョン 105 に移行され、データ移行を実装するための関数が作成されました。
- 商品によってはオンラインがオフラインをリードする性質があり、ある商品のラインが上がると、来月にはオフラインでもその商品が上がる可能性が高くなります。
- データは特徴エンジニアリングと機械学習のために月次ベースで統合されます
- 各製品の需要を地域別、月別に集約
- 販売地域、販売月、商品などの情報を組み合わせた構造化データセットを作成する
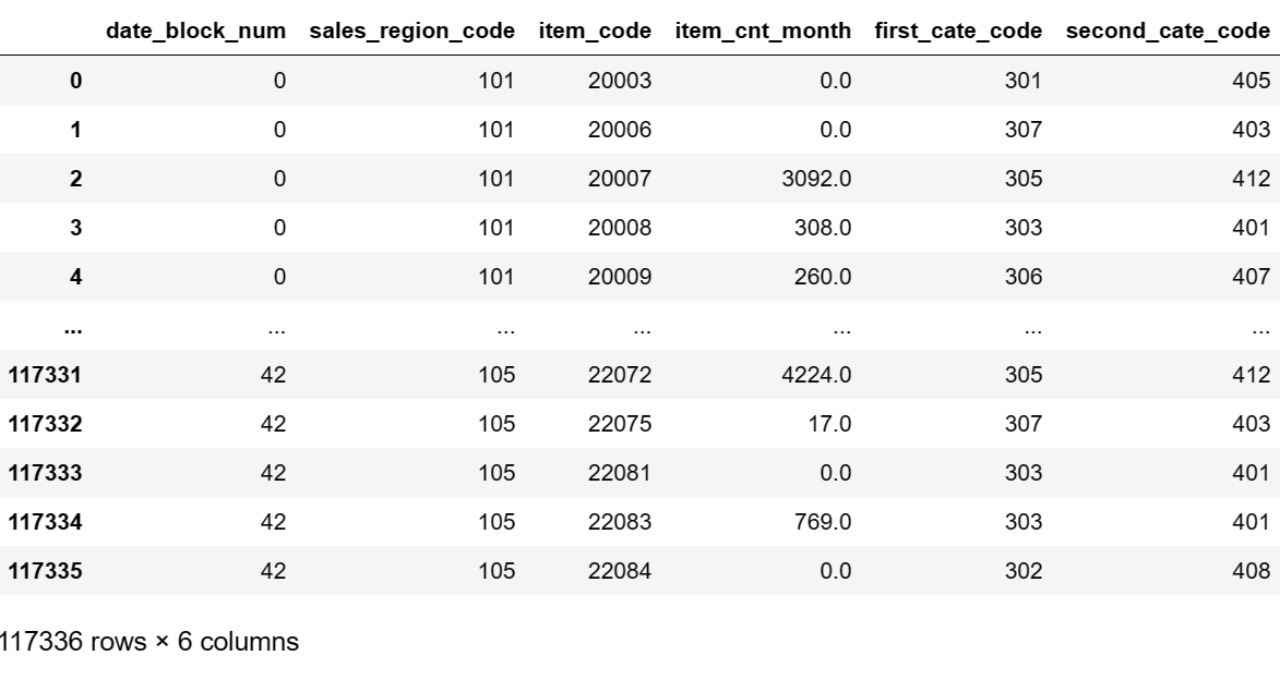
- 次に、より有用な戦略、つまり商品の階層化を提案します。このアイデアは、マーケティングクラスの広告から来ています。なぜなら、性質やポジショニングが異なる商品の販売ルールは異なるはずであるため、分類は
- New : 36 か月 (date_block_num) まで市場に登場し始めなかった製品。
- メテオ商品:突然現れるが、販売期間が5ヶ月を超えず、売上が激減する商品。
- 睡眠関連商品:目標的な売上を維持しているが、ある時期を境に売上が激減しているが、その理由は季節要因ではない。
- 通常商品: 常に売れている商品、39 週間以上販売されている、または 1 年以上販売されている商品。
- 本当は季節商品もあるはずですが、2年以上存在していないものがほとんどなのでアルゴリズムで判断できないので諦めました
2.2.2 予測セット
- 次に、どの製品が予測されるかを確認するために、予測セット内の製品を分類する分類関数を作成しました。

ほとんどが定番品であり、新品の割合も少なくないことが分かります。Baseline を設定した後、誤差分析(予測誤差がどこから来たのかを分析することについては後述します) を実行しました。新商品が多く、変動の大きい商品もあり、予測のずれが非常に大きいことが判明したため、別途新商品モデルを構築しました。
2.3 特徴量エンジニアリング
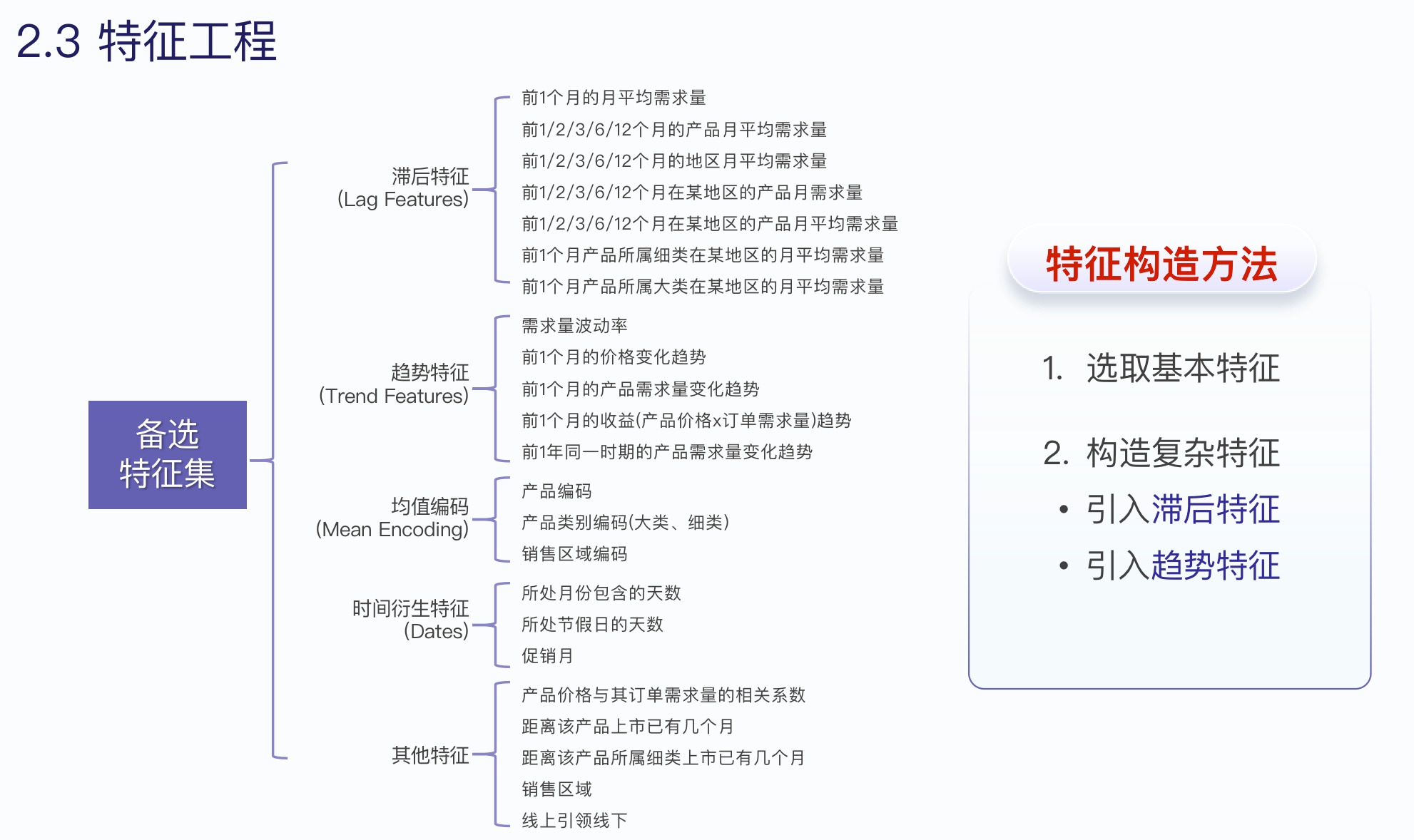
特徴エンジニアリングは最も重要であり、モデルの最終的な予測精度を決定する鍵となります。従来のものには、ラグ機能、トレンド機能などがあります。新しい機能を追加し続け、効果を検証するためにモデルをトレーニングし続け、最後に不要な機能を削除します。
- データを漏洩しないように注意し、機能を作成するときに将来のデータを導入しないようにしてください。たとえば、トレンドは先月→今月ではなく、先月→先月のトレンドである必要があります。今月のデータは予測されます
2.4 モデルの確立
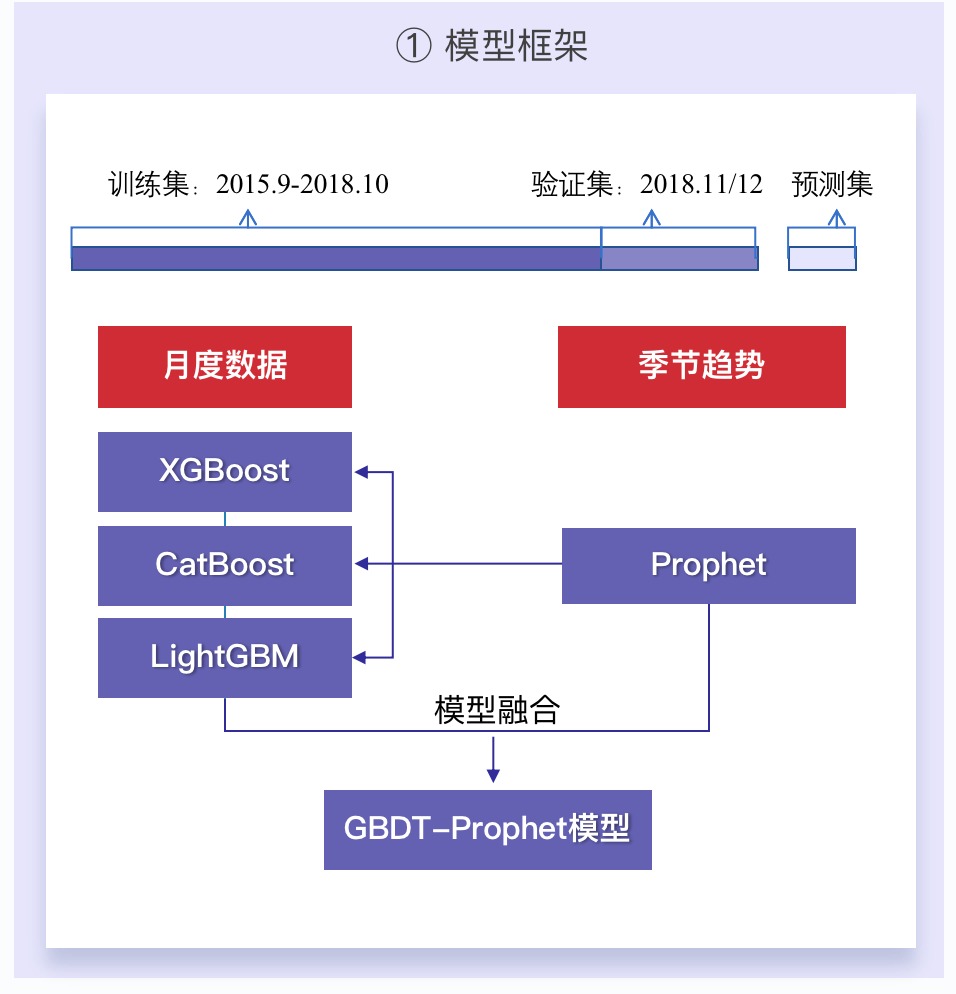
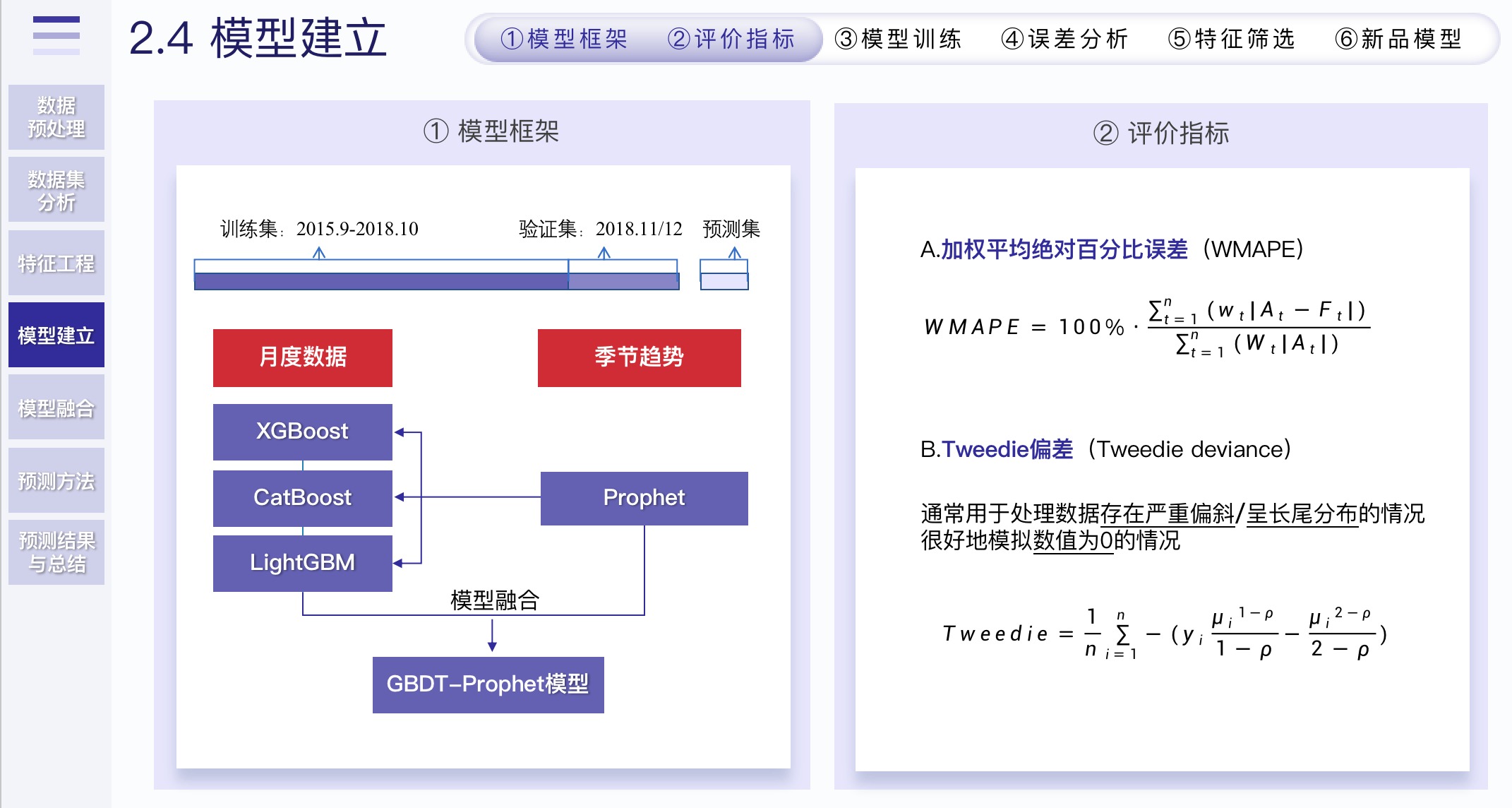
2.4.1 モデルの枠組みと評価指標
-
トピックが非常に突飛な場合は、日/週/月ごとに個別にモデル化して予測する必要があります。実際、その月に良い仕事ができれば良いのですが、そうしないと 3 セットの機能を実行する必要があり、それは不可能です。
-
私たちのソリューションは、毎月の予測に従って継続的に最適化することです。その日/週については、預言者と一緒にランダムに予測してください。しかしその過程で、預言者は予測できるだけでなく、いくつかの季節の特徴を抽出できることがわかりました。
-
実際に作った機能には季節性がないので、預言者から抽出した機能のこの部分を組み込んだところ、非常に良い効果が得られました。
-
2.4.2 モデルの確立
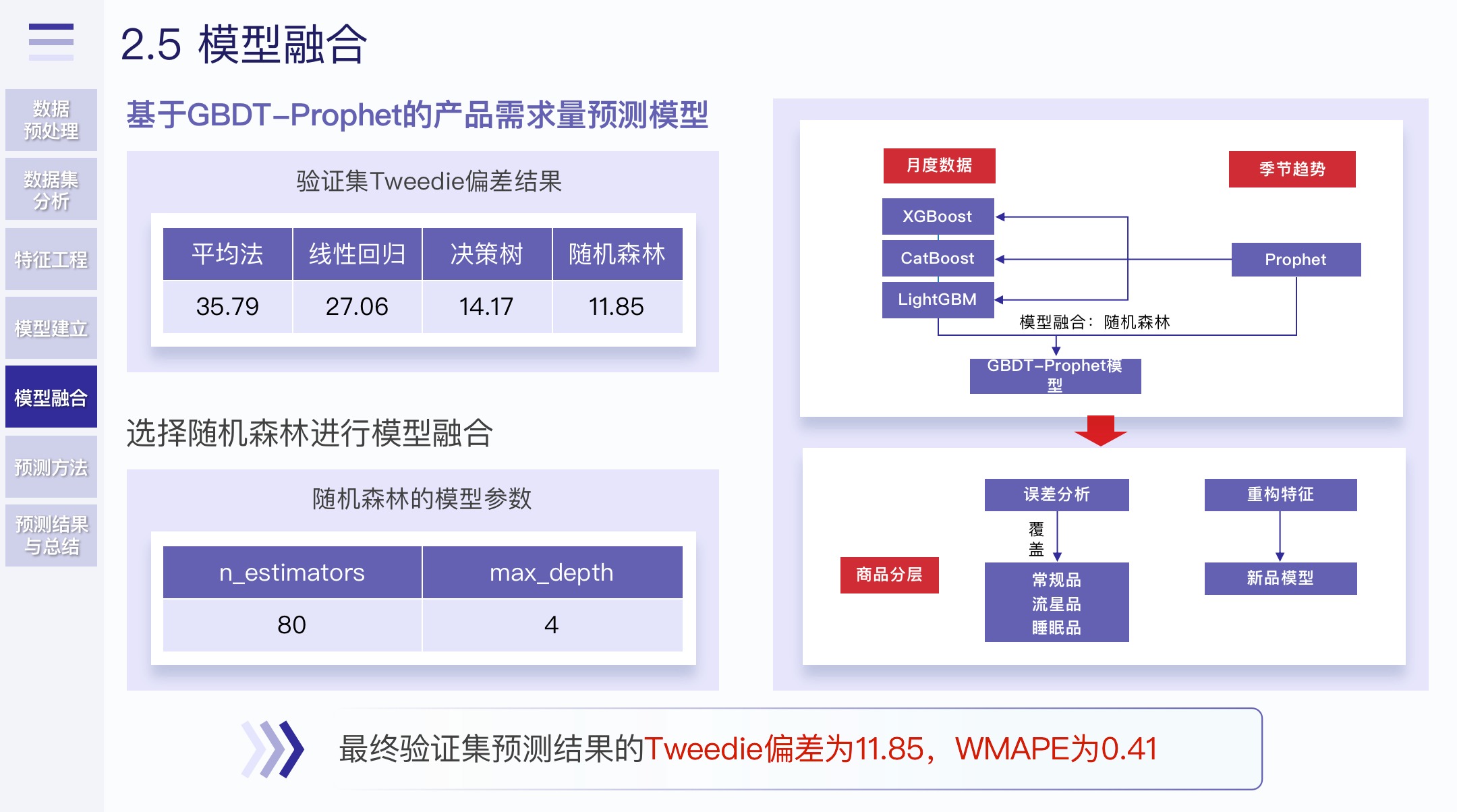
- モデルの選択には、ベースラインは LightGBM を使用します。これは、トレーニング時間が最も速く、継続的に最適化するのに便利です。
- 最後に、3 つの勾配ブースティング ツリー アルゴリズム (LightGBM、CatBoost、XGBoost) がモデルの融合に使用されました。
- なんというか、効果は確かに非常に良いのですが、これでは過学習も生じてしまいます。実際、それほど複雑である必要はなく、モデルを使用するのが最も効果的かもしれません。

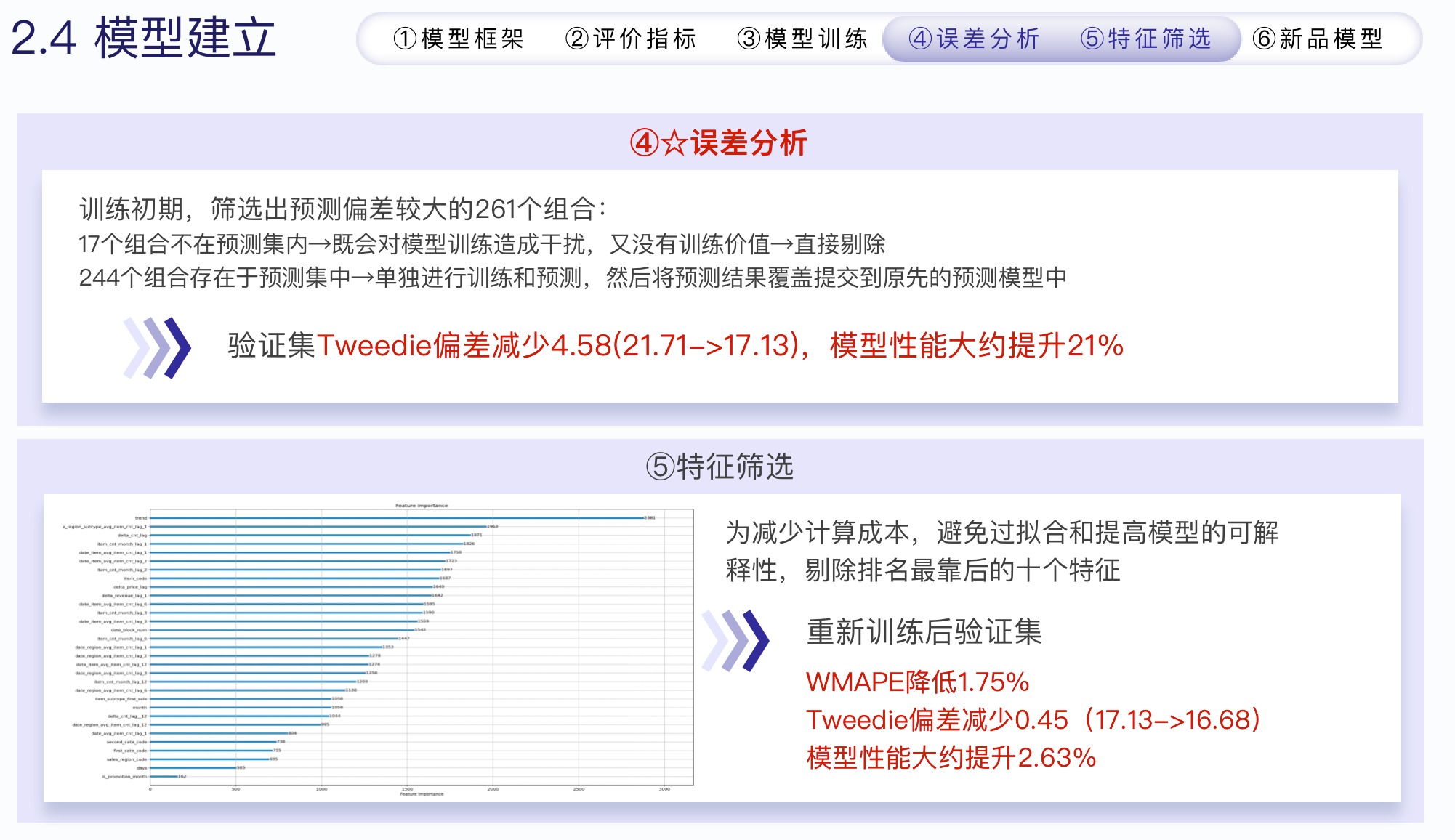
2.4.3 エラー分析と機能の選択
- エラー分析
- 事前トレーニングに大いに役立ちます
- 誤差が大きい積を再予測し、予測値のオーバーレイを元のモデルに送信します
- 特集上映
- 無駄な機能を排除する
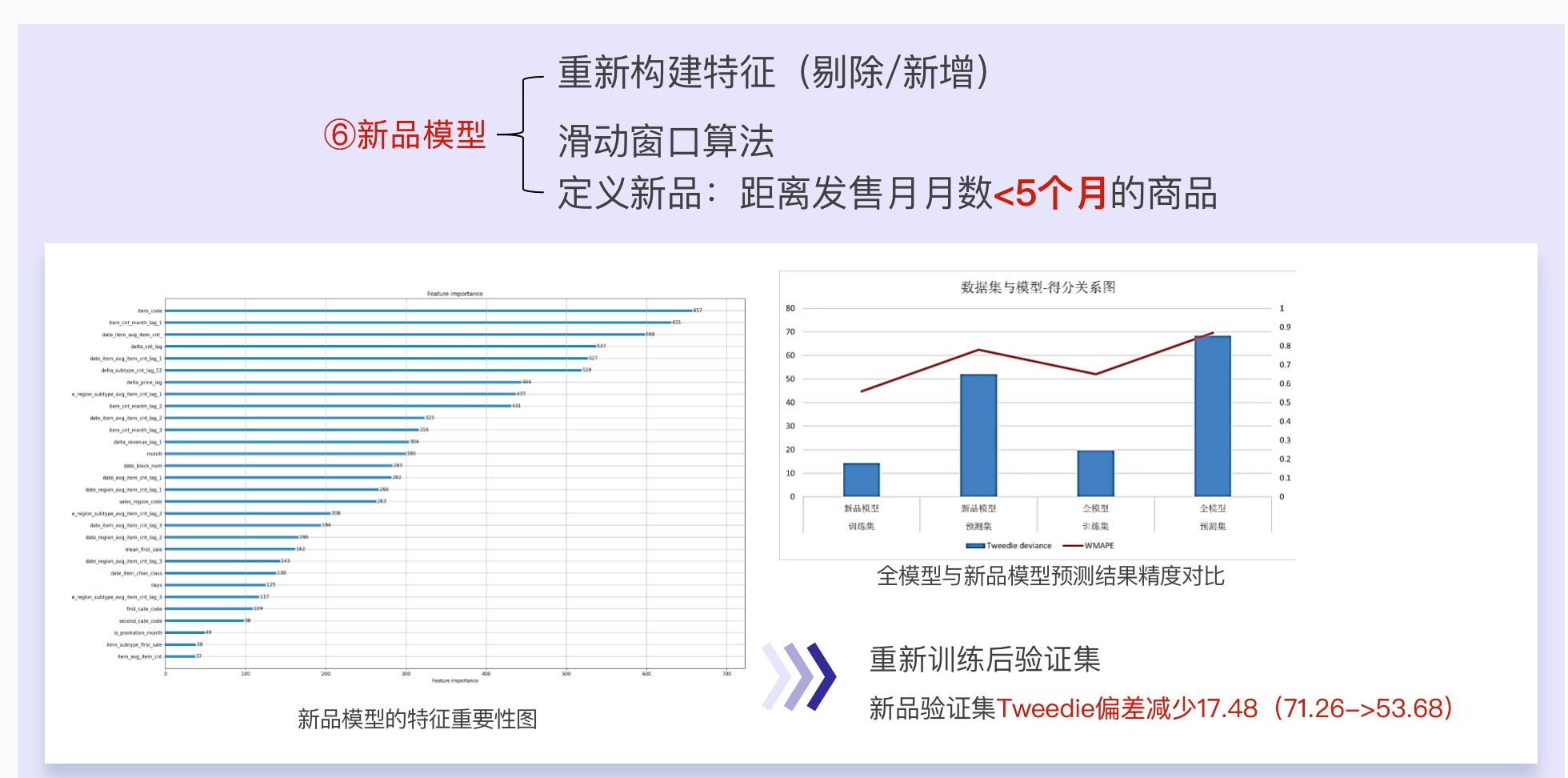
2.4.4 新製品モデル
- 新製品の場合、スライディング ウィンドウを使用して各月の新製品を抽出し、新製品モデルのトレーニング セットと予測セットを形成します。
- そして、特徴エンジニアリングをやり直します。新製品には履歴データがなく、予測は類似製品の一部の情報のみに依存するため、作成する機能はこの方向に依存します。
2.5 モデルの融合
比較した結果、モデル融合の方法が選択されました
繰り返しになりますが、モデルが複雑すぎるからといって、実際の予測効果がより優れているというわけではありません。しかし、論文発表ではそのような作業が必要です。
2.6 予測方法
また、3 つの予測方法もテストしました。タイトルには今後 3 か月間の予測データが必要なためです。
直接予測とローリング予測は理解しやすいはずです。
遅延予測では、M+2 売上の予測などの機能をやり直す必要があります。M+1ヶ月分のデータは機能として使用できません

2.7 概要

終わり
まず、このコンテストのテーマについてお話しますが、このテーマのデータの品質はあまり良くなく、初期段階で行うのは頭の痛い問題であり、これは販売データによくある問題かもしれません。2問目の日次・週次・月次の精度別の予想が分かりにくい。もう一度審査員について話しましょう。個人的には、防御側に入ることができるチームは機械学習/ディープラーニングを使用してデータセット全体を一緒にトレーニングする必要があると思います。審査員は私たちの仕事の革新に焦点を当てる必要があります。しかし、審査員たちは理解できないようで、いちいちトレーニングせずにどうすれば Prophet を使用できるのかを考えると、機械学習を使用して各製品を予測する方法を理解するのが難しいようです。私たちが達成するのは各製品の最適ではなく全体的な最適であり、Prophet を使用するかどうかとは関係ありません (Prophet を使用して機能を 1 つずつ抽出し、全体の作業は LGBM で継続的に最適化されます)。
なお、本コンテストは論文と予想データ(2019年1月、2月、3月のデータ)の提出が必要で、1月、2月、3月のデータは提出翌日に発表され、4つの予想が必要となります。 、5、6月のデータ。そのときはメーデーの祝日でしたけれども、あの朝、一月の販売実績が非常に高くて、全体の売り上げが予測の二倍から三倍くらいだったんですね。その後、5 月のデータも非常に高い可能性があることがわかったので、コードを再度変更し、各商品の月ごとの売上特性を合計し、別の日の予測を行いました。最終的には効果があれば良いと思います。トリックを合理的に使用して予測精度を高めることも勝利の重要な部分です。
最後に、ありがとうございます。チームメイトの二人の努力、競技中に絵を描いて理解してくれたnpy、助けてくれてディフェンスの指導をしてくれた先輩たち、そして私のインストラクターに感謝します。この概要が他の人に役立つことを願っています。