目次
src/runoob/heap/IndexMaxHeap.java ファイルコード:
インデックスヒープとその最適化
1. コンセプトと紹介
インデックス ヒープは、ヒープのデータ構造を最適化したものです。
インデックス ヒープは、インデックス情報を格納するために新しい int 型配列を使用します。
ヒープと比較すると、次のような利点があります。
- 交換要素の消費を最適化しました。
- 追加されたデータの場所は固定されており、見つけやすいです。
2. 適用される命令
ヒープに格納されている要素が大きい場合、交換に時間がかかりますが、このときインデックスヒープのデータ構造を利用することができます。ヒープには配列のインデックスが格納されており、インデックスを操作します。それに応じて。
3. 構造図
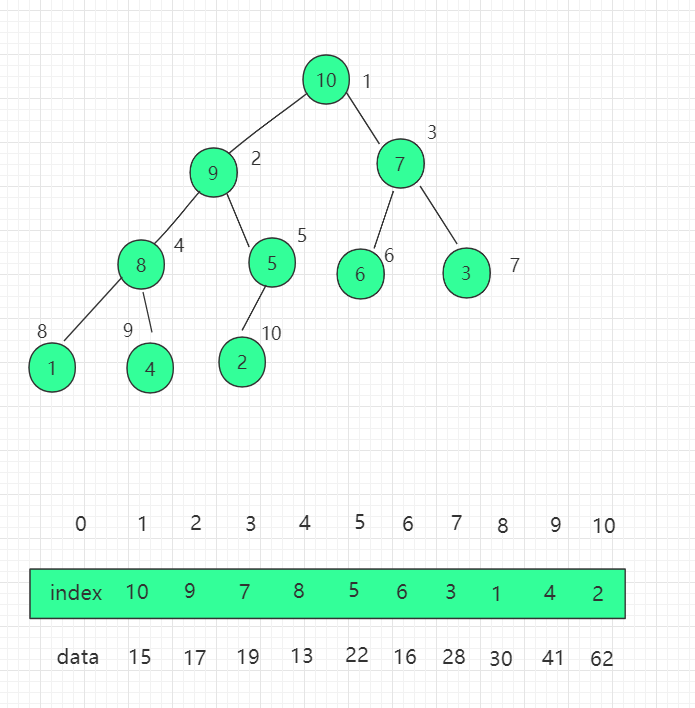
ヒープの以前のコード実装を変換し、インデックスを直接操作する考え方に置き換える必要があります。まず、コンストラクターはインデックス配列プロパティのインデックスを追加します。
protected T[] data; // 最大のインデックス ヒープ内のデータ
protected int[] Indexes; // 最大のインデックス ヒープ内のインデックス
protected int count;
protected int Capacity;
対応するコンストラクターは、初期化されたインデックス配列を追加するように調整されます。
...
public IndexMaxHeap(int Capacity){ data = (T[])new Comparable[capacity+1]; インデックス = 新しい int[容量 + 1]; カウント = 0; this.capacity = 容量; } ...
挿入操作を調整します。インデックス配列に追加される要素は、実データ配列のインデックス Indexes[count+1] = i になります。
...
// 新しい要素を最大インデックス ヒープに挿入します。新しい要素のインデックスは i、要素は item
// ユーザーにとって、受信する i は
public void insert(int i, item item) { アサートカウント + 1 <= 容量; アサート i + 1 >= 1 && i + 1 <= 容量; i += 1; データ[i] = アイテム; インデックス[カウント+1] = i; カウント ++ ; シフトアップ(カウント); } ...
シフトアップ操作を調整します。比較はデータ配列内の親ノード データのサイズであるため、data[index[k/2]] < data[indexs[k]]、つまりノードのインデックスとして表す必要があります。インデックス配列は交換され、データ配列は何も変更されません。シフトダウンも同様です。
...
//k はヒープのインデックス
// インデックスヒープでは、データ間の比較はデータのサイズに応じて行われますが、実際の操作はインデックスです
private void shftUp(int k){ while( k > 1 && data[indexes[k/2]].compareTo(data[indexes[k]]) < 0 ){ swapIndexes(k, k/2); k /= 2; } } ...
インデックスヒープから要素を取り出し、ルート要素data[index[1]]のデータとして大きい要素をシフトダウン演算し、インデックス位置を交換します。
...
public T extractMax(){ アサート数 > 0; T ret = データ[インデックス[1]]; swapIndexes( 1 , count ); カウント - ; シフトダウン(1); retを返します。} ...
最大値のデータ配列インデックス値を直接取り出すこともできます
...
// 最大インデックス ヒープから最上位要素のインデックスを抽出します
public int extractMaxIndex(){ assert count > 0; int ret = Indexes[1] - 1; swapIndexes( 1 , count ); count --; ShiftDown ( 1); 戻り値; } ...
インデックスの位置データを変更する
...
// 最大のインデックス ヒープ内のインデックス i を持つ要素を newItem に変更します
public void change(int i , Items newItem ){ i += 1; data[i] = newItem; // インデックス [j] = i を検索します, j は、ヒープ内の data[i] の位置を示します // shiftUp(j) の後、shiftDown(j) の後に for( int j = 1 ; j <= count ; j ++ ) if( Indexes[j] == i ){ シフトアップ(j); シフトダウン(j); リターン; } } ...
4. Java サンプルコード
ソース パッケージのダウンロード: https://www.runoob.com/wp-content/uploads/2020/09/runoob-algorithm-IndexMaxHeap.zipをダウンロードします。![]()
src/runoob/heap/IndexMaxHeap.java ファイルコード:
package runoob.heap;
import java.util.Arrays;
/**
* インデックス ヒープ
*/
// 最大インデックス ヒープ、アイデア: 要素はデータ data と比較され、要素はインデックスと交換されます
public class IndexMaxHeap<T extends Comparable> { protected T[] data; // 最大のインデックス ヒープ内のデータ protected int[] Indexes; // 最大のインデックス ヒープ内のインデックス protected int count; protected int Capacity; // コンストラクター、容量要素を保持できる空のヒープを構築 public IndexMaxHeap(int Capacity){ data = (T[])new Comparable[capacity+1]; Indexes = new int[capacity+1]; count = 0; this.capacity = Capacity; } // インデックス ヒープの数を返します。要素 public int size(){ 戻り値;
}
// インデックス ヒープが空かどうかを示すブール値を返します
public boolean isEmpty(){ return count == 0; } // 新しい要素を最大のインデックス ヒープに挿入します。新しい要素のインデックスは i です。要素は item です // 受信 i は 0 からユーザーまでのインデックスが付けられます public void insert(int i, T item){ assert count + 1 <= Capacity; assert i + 1 >= 1 && i + 1 <= Capacity ; i += 1; data[i] = item; indexes[count+1] = i; count ++; shftUp(count); } // インデックスに格納されている最大のインデックス ヒープから最上位の要素を取り出しますheap 最大データ public T extractMax(){ assert count > 0; T ret = data[indexes[1]]; swapIndexes( 1 , count );
count --;
shiftDown(1);
return ret;
}
// 最大インデックス ヒープから最上位要素のインデックスを取得
public int extractMaxIndex(){ assert count > 0; int ret =indexes[1] - 1; swapIndexes( 1 , count ); count --; shiftDown(1); return ret; } // 最大のインデックス ヒープの先頭要素を取得 public T getMax(){ assert count > 0; return data[indexes[1]]; } // 最大のインデックス ヒープ内の最上位要素のインデックスを取得 public int getMaxIndex(){ assert count > 0; return Indexes[1]-1; } // 最大のインデックス ヒープ内のインデックス i の要素を取得
public T getItem( int i ){ assert i + 1 >= 1 && i + 1 <= Capacity; return data[i+1]; } // 最大のインデックス ヒープ内のインデックス i を持つ要素を newItem に変更します public void change ( int i , T newItem ){ i += 1; data[i] = newItem; // インデックス[j] = i を見つけます、j はヒープ内の data[i] の位置を示します // shiftUp(j) の後、 thenshiftDown(j) for( int j = 1 ; j <= count ; j ++ ) if(indexes[j] == i ){ shiftUp(j); shiftDown(j); return; } } // インデックスを交換しますプライベートのヒープインデックス i と j void swapIndexes(int i, int j){
int t = インデックス[i];
インデックス[i] = インデックス[j];
インデックス[j] = t;
}
//**********************
// * 最大インデックス ヒープ コア補助関数
//*********************
//k はヒープのインデックス
//インデックス ヒープでは、データはデータ サイズに基づいていますが、実際の操作はインデックス
private void shftUp(int k){ while( k > 1 && data[indexes[k/2]].compareTo(data[indexes[k]]) < 0 ){ swapIndexes ( k, k/2); k /= 2; } } // インデックス ヒープでは、データ間の比較はデータのサイズに基づいて行われますが、実際の操作はインデックスの プライベート void シフトダウン( int k){ while( 2* k <= count ){ int j = 2*k;
if( j+1 <= count && data[indexes[j+1]].compareTo(data[indexes[j]]) > 0 )
j ++;
if( data[indexes[k]].compareTo(data[indexes[j]]) >= 0 )
ブレーク;
swapIndexes(k, j);
k = j;
}
}
// IndexMaxHeap
public static void main(String[] args) { int N = 1000000; IndexMaxHeap<Integer> IndexMaxHeap = 新しい IndexMaxHeap<Integer>(N); for( int i = 0 ; i < N ; i ++ ) IndexMaxHeap.insert( i , (int)(Math.random()*N) ); } }
上記の変更インデックス位置では、インデックス位置を見つけるためにトラバーサルを使用しましたが、これは効率的ではありません。また、インデックス (ヒープ) 内のインデックス i の位置を示す一連の reverse[i] 配列を維持して、再度最適化し、検索の時間計算量を O(1) に減らすこともできます。
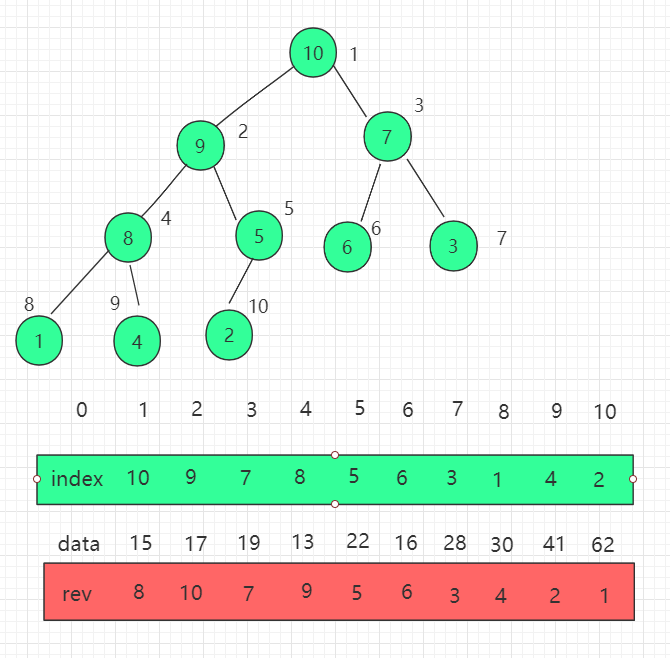
次のプロパティがあります。
インデックス[i] = j reverse[j] = i インデックス[reverse[i]] = i reverse[indexes[i]] = i