目次
1.3 Inpaint Anything の機能とは何ですか
3 Inpaint Anything 実行中のエフェクト表示
1 Inpaint Anything の概要
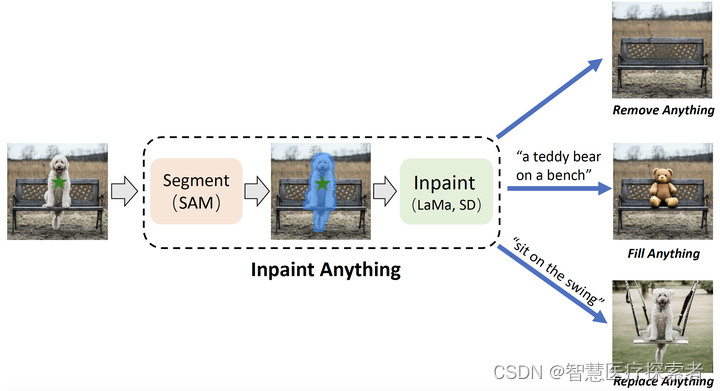
選択したオブジェクトをワンクリックでマークするだけで、指定したオブジェクトを削除し、指定したオブジェクトを塗りつぶし、すべてのシーンを置き換えることができます。これにより、オブジェクトの削除、オブジェクトの塗りつぶし、背景の置き換えなど、さまざまな一般的な画像修復アプリケーションのシナリオに対応できます。
最新の画像修復システムは、マスクの選択や穴の穴埋めで困難に直面することがよくあります。著者らは、SAM (Segment-Anything Model) に基づいてマスクフリーの画像修復を初めて試み、「Inpaint Anything (IA)」、つまり「クリック アンド フィル」という新しいパラダイムを提案しました。
IA の中心となるアイデアは、さまざまなモデルの利点を組み合わせて、修復関連の問題を解決するための非常に強力でユーザーフレンドリーなプロセスを構築することです。IA は 3 つの主要な機能をサポートします。
- 任意のオブジェクトを削除します。ユーザーがオブジェクトをクリックすると、IA がオブジェクトを削除し、スムーズなコンテキストで「穴」を埋めます。
- 任意のコンテンツを埋める: いくつかのオブジェクトを削除した後、ユーザーはテキストベースのプロンプトを IA に提供できます。その後、IA は安定拡散 [11] などの AIGC モデルを駆動することによって空白と対応する生成されたコンテンツを埋めます。
- 背景を置き換える: IA を使用すると、ユーザーはクリックして選択したオブジェクトを保持し、残りの背景を新しく生成されたシーンに置き換えることができます。
論文: https://arxiv.org/pdf/2304.06790.pdf
コード: https://github.com/geekytao/Inpaint-Anything
1.1 Inpaint Anything が必要な理由
- LaMa、Repaint、MAT、ZITS などの最先端の画像修復手法は、大規模な領域の修復と複雑な繰り返し構造の処理において大きな進歩を遂げました。これらは高解像度の画像にうまくインペイントでき、一般に他の画像にもうまく一般化できます。ただし、通常は各マスクのきめ細かい注釈が必要であり、これはトレーニングと推論に不可欠です。
- Segment Anything Model (SAM) は、ポイントやボックスなどの入力キューに基づいて高品質のオブジェクト マスクを生成できる強力なセグメンテーション ベース モデルであり、画像内のすべてのオブジェクトに対して包括的で正確なマスクを生成できます。ただし、マスク セグメンテーションの予測は十分に調査されていません。
- さらに、既存の修復方法は、削除された領域を埋めるためにコンテキストを使用することしかできません。AIGC モデルは、創作の新たな機会をもたらし、大きな需要を満たし、人々が望むコンテンツを生成できるよう支援する可能性を秘めています。
- したがって、SAM、最先端の画像修復ツール LaMa、および AI 生成コンテンツ (AIGC) モデルの長所を組み合わせることで、より一般的な修復関連の問題を解決するための強力で使いやすいパイプラインを提供します。オブジェクトの削除、新しいコンテンツの充填、背景の置換など。
1.2 Inpaint Anything の動作原理
Inpaint Anything は、SAM などのビジョンベースのモデル、画像修復モデル (LaMa など)、および AIGC モデル (安定拡散など) を組み合わせます。
- SAM (Segment Anything Model) は、ポイントやボックスなどの入力プロンプトを通じて高品質のオブジェクト セグメンテーション領域を生成し、指定されたターゲットのセグメンテーションを実現します。
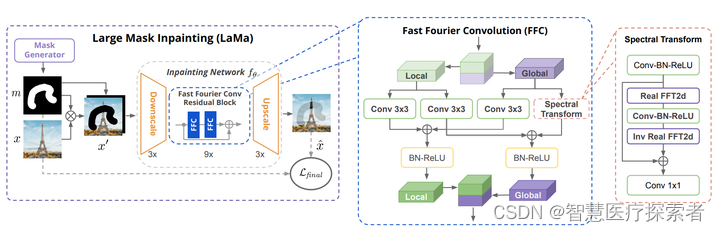
- 画像修復モデル LaMa は、高解像度画像の場合、画像内のさまざまな要素を自由に削除できます。モデルの主なアーキテクチャを次の図に示します。マスクの白黒画像と元の画像が含まれています。マスク イメージはイメージにオーバーレイされ、修復ネットワークに入力されます。最初に低解像度にダウンサンプリングされ、次にいくつかの高速フーリエ畳み込み FFC 残差ブロックの後、最後にアップサンプリングを出力して高解像度の修復が生成されます。画像。
- AIGC モデル Stable Diffusion は、テキストを入力するだけで、すぐに画像に変換できます。
3 つのモデルを組み合わせると、多くの機能を作成できます。この記事では、写真/ビデオ内のすべてのオブジェクトを削除する、写真内のすべてのオブジェクトを塗りつぶす、写真内のすべての背景を置き換えるという 3 つの機能を実現します。具体的な実装手順は次のとおりです。
1.3 Inpaint Anything の機能とは何ですか
- SAM + SOTA Restorer を使用して任意のオブジェクトを削除: IA を使用すると、ユーザーはオブジェクトをクリックするだけで、インターフェイスから特定のオブジェクトを簡単に削除できます。さらに、IA はユーザーが結果として生じる「穴」をコンテキスト データで埋めるオプションを提供します。この要件に対して、当社は SAM と LaMa などの最先端の復元機能の利点を組み合わせています。浸食と膨張による手動調整を通じて、SAM によって生成されたマスク予測が修復モデルへの入力として使用され、消去および塗りつぶされるオブジェクト領域の明確な指示が提供されます。
- SAM+AIGC モデルを使用して、任意のコンテンツを入力または置換します。
(1) オブジェクトを削除した後、IA は結果として生じる「穴」を埋める 2 つのオプションを提供します。つまり、コンテキスト データまたは「新しいコンテンツ」を使用します。具体的には、安定拡散 [11] のような強力な AI 生成コンテンツ (AIGC) モデルを活用して、テキストの手がかりから新しいオブジェクトを生成します。たとえば、ユーザーは「犬」という単語または「ベンチに座っているかわいい犬」のような文を使用して、穴を埋める新しい犬を生成できます。
(2) さらに、ユーザーは、クリックによってオブジェクトを選択したまま、残りの背景を新しく生成されたシーンに置き換えることも選択できます。IA は、さまざまな画像を視覚的なキューとして使用したり、短いタイトルをテキスト キューとして使用したりするなど、AIGC モデルにプロンプトを表示する複数の方法をサポートしています。たとえば、ユーザーは画像内に犬を残したまま、元の屋内の背景を屋外の背景に置き換えることができます。

1.4 セグメント何でもモデル (SAM)
Segment Anything は、大規模な視覚コーパス (SA-1B) でトレーニングされた ViT ベースの CV モデルです。SAM はさまざまなシナリオで有望なセグメンテーション機能を実証しており、基礎となるモデルはコンピューター ビジョンの分野で大きな可能性を秘めています。これは視覚的な汎用人工知能への先駆的な一歩であり、SAM はかつて「ChatGPT の CV バージョン」としてもてはやされました。
- SOTA Inpainter: 画像修復は、不正設定逆問題として、コンピューター ビジョンと画像処理において広く研究されてきました。その目標は、破損した画像の欠落領域を、視覚的に妥当な構造とテクスチャを持つコンテンツに置き換えることです。Inpaint Anything (IA) では、著者らは、高速フーリエ畳み込み (FFC)、知覚損失、および反復的な視覚構造の生成に優れた積極的なトレーニング マスク生成戦略を組み合わせることにより、マスク ベースの修復のための単純な 1 段階法 LaMa を研究します。
- AIGC モデル: ChatGPT およびその他の生成 AI (GAI) テクノロジーは、AI モデルによる画像、音楽、自然言語などのデジタル コンテンツの作成を伴う人工知能生成コンテンツ (AIGC) のカテゴリに分類されます。これは、コンテンツ作成の新しい方法とみなされており、コンテンツ生成のさまざまな側面で最先端のパフォーマンスを発揮します。私たちの IA 作業では、著者は強力な AIGC モデルの安定拡散を直接使用して、テキスト ヒントに基づいてホール内に目的のコンテンツを生成します。
1.5 何でも修復する
著者らが提案した Inpaint Anything (IA) の原理は、既製の基本モデルを組み合わせて、幅広い画像修復問題を解決することです。さまざまなベース モデルの長所を組み合わせることで、IA は高品質のペイント イメージを生成できます。具体的には、私たちの IA には、Remove Anything、Fill Anything、Replace Anything という 3 つのスキームが含まれており、それぞれ何かを削除、塗りつぶし、置換するために使用されます。
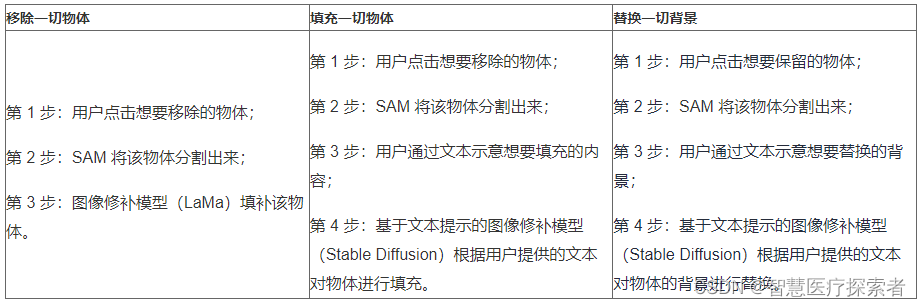
1.5.1 オブジェクトを削除する
Remove Anything は、ユーザーが画像から任意のオブジェクトを削除できるようにすると同時に、結果として得られる画像が視覚的に健全であることを保証することで、オブジェクト削除の問題を解決することに重点を置いています。
「何でも削除」は、クリック、分割、削除の 3 つのステップで構成されます。
- 最初のステップでは、ユーザーは画像から削除するオブジェクトをクリックして選択します。
- 次に、Segment Anything などの基本的なセグメンテーション モデルを使用して、オブジェクトを自動的にセグメント化し、クリック位置に基づいてマスクを作成します。
- 最後に、LaMa [13] などの高度な修復モデルを使用して、除去されたオブジェクトによって残された穴を埋めるためにマスクが使用されます。
オブジェクトがイメージ内に存在しなくなったため、修復モデルは背景情報で穴を埋めます。
プロセス全体を通じて、ユーザーは画像から削除したいオブジェクトをクリックするだけでよいことに注意してください。
1.5.2 任意の内容を入力します
「何でも塗りつぶす」を使用すると、ユーザーは画像内の任意のオブジェクトを好きなもので塗りつぶすことができます。
このツールは、クリック、セグメント、テキストヒント、生成の 4 つのステップで構成されます。
- 「Fill Anything」の最初の 2 つのステップは「Remove Anything」と同じです。
- 3 番目のステップでは、ユーザーはオブジェクトの空洞を埋める内容を示すテキスト プロンプトを入力します。
- 最後に、安定拡散 [11] などの強力な AIGC モデルを使用して、テキスト ヒント修復モデルに基づいてホール内に目的のコンテンツを生成します。
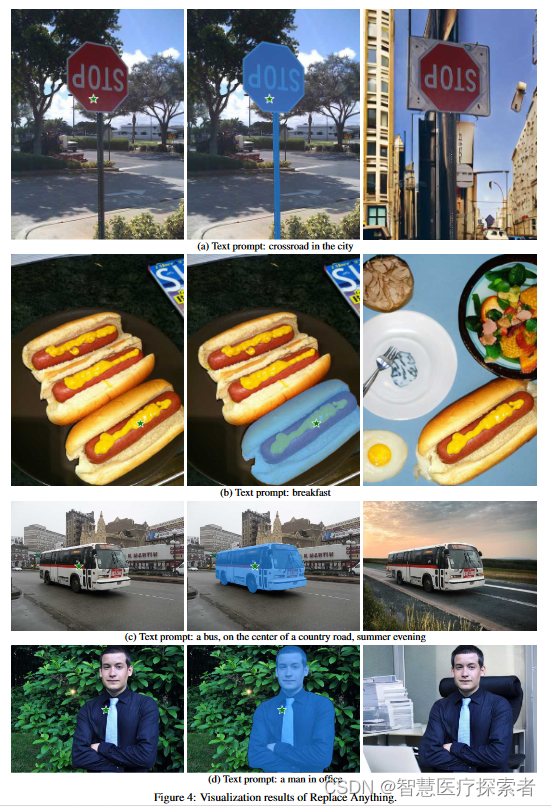
1.5.3 コンテンツを置き換える
「何でも置換」は、任意のオブジェクトを任意の背景に置き換えることができます。「何でも置換」のプロセスは「何でも塗りつぶす」と似ていますが、この場合、AIGC モデルは、指定されたオブジェクトの外観と一致する背景を生成するように求められます。
1.5.4 練習
基本モデルを組み合わせてタスクを解決すると、非互換性や不適切な問題が発生する可能性があります。モデルとタスク間のより適切な調整を実現するには、中間処理を考慮する必要があります。この研究では、画像修復シナリオの構成に関するいくつかの優れた実践方法を次のように要約します。
- 拡張操作の重要性。
SAM セグメンテーションの結果 (つまり、オブジェクト マスク) には、オブジェクト領域内の不連続性や滑らかでない境界、または穴が含まれている可能性があることが観察されています。これらの問題により、オブジェクトを効率的に削除または塗りつぶすことが困難になります。したがって、拡張操作を使用してマスクを最適化します。さらに、塗りつぶされたオブジェクトの場合、大きなマスクは AIGC モデルに大きな創造的なスペースを提供し、ユーザーの意図との「調整」に有益です。したがって、Fill Anything では大きな膨張操作が使用されます。
- 忠実さの重要性。
ほとんどの最先端の AIGC モデル (安定拡散など) では、画像の解像度が固定 (通常は 512 × 512) である必要があります。単純に画像のサイズをこの解像度に変更すると、忠実度が失われ、最終的な修復結果に悪影響を及ぼす可能性があります。したがって、トリミング技術を使用したり、サイズ変更時に画像の縦横比を維持したりするなど、元の画質を維持するための措置を講じる必要があります。
- ヒントの大切さ。
私たちの研究は、テキスト キューが AIGC モデルに重要な影響を与えることを示しています。ただし、テキストで指示された修復シナリオでは、「ベンチ上のテディベア」や「壁にあるピカソの絵」などの単純な手がかりで満足のいく結果が得られることが多いことがわかります。対照的に、長く複雑なプロンプトは印象的な結果を生み出す可能性がありますが、ユーザーフレンドリーではない傾向があります。

1.6 実験の概要
著者らは、Inpaint Anything の「Remove Anything」、「Fill Anything」、および「Replace Anything」を、それぞれオブジェクトの削除、オブジェクトの塗りつぶし、背景の置換の 3 つのケースで評価しました。著者らは、COCO データセット、LaMa テスト セット、および携帯電話で撮影した写真からテスト画像を収集しました。実験結果は、提案された Inpaint Anything が多用途かつ堅牢であり、さまざまなコンテンツ、解像度、アスペクト比の画像を効果的に修復できることを示しています。
2 Inpaint Anything の展開と操作
2.1 conda環境の準備
conda 環境の準備については、annoconda を参照してください。
2.2 動作環境のインストール
git clone https://github.com/geekyutao/Inpaint-Anything
cd Inpaint-Anything
conda create -n ia python=3.9
conda activate ia
pip install torchvision==0.15.2
pip install torchaudio==2.0.2
pip install -e segment_anything
pip install -r lama/requirements.txt
pip install diffusers==0.16.1
pip install transformers==4.30.2
pip install accelerate==0.19.0
pip install scipy==1.11.1
pip install safetensors==0.3.1
pip install numpy==1.23.5
pip install jpeg4py==0.1.4
pip install lmdb==1.4.12.3 モデルのダウンロード
(1) 何でも削除モデル
モデルの保存ディレクトリを作成します。
mkdir -p pretrained_models/big-lamaSAM モデルのダウンロード: SAM アドレス
ラマ モデルのアドレス:ラマのアドレス
ダウンロードが完了したら、上記のモデル アドレスからモデル ファイルをダウンロードします。
SAM モデル ファイルは pretrained_models ディレクトリに移動されます。
ラマ モデル ファイルは pretrained_models/big-lama に移動されました
完了後、コマンド ラインは次のように表示されます。
[root@localhost Inpaint-Anything]# ll pretrained_models/
总用量 2504448
drwxr-xr-x 3 root root 51 8月 4 18:13 big-lama
-rw-r--r-- 1 root root 2564550879 8月 4 15:32 sam_vit_h_4b8939.pth
[root@localhost Inpaint-Anything]# ll pretrained_models/big-lama/
总用量 4
-rw-r--r-- 1 root root 3947 8月 4 15:28 config.yaml
drwxr-xr-x 2 root root 31 8月 4 15:28 models(2) 何でも埋めるモデル
mkdir -p stabilityai/stable-diffusion-2-inpaintingモデルのダウンロード アドレス: Huggingface アドレス、ダウンロードが完了したら、上記のディレクトリに保存します。
(3) 何でも削除ビデオモデル
モデルのダウンロード アドレス: sttn model、sttn モデル ファイルは pretrained_models ディレクトリに移動されます。
mkdir -p pytracking/pretrainモデルのダウンロード アドレス: osTrack モデル、ダウンロードが完了したら、上記のディレクトリに保存します。
3 Inpaint Anything 実行中のエフェクト表示
3.1 何かを削除する
(1) 座標点を指定してオブジェクトを削除する
python remove_anything.py \
--input_img ./example/remove-anything/dog.jpg \
--coords_type key_in \
--point_coords 200 450 \
--point_labels 1 \
--dilate_kernel_size 15 \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pth \
--lama_config ./lama/configs/prediction/default.yaml \
--lama_ckpt ./pretrained_models/big-lama正常に実行されると、結果は結果ディレクトリに保存されます。




(2) クリックでオブジェクトを削除
python remove_anything.py \
--input_img ./example/remove-anything/dog.jpg \
--coords_type click \
--point_coords 200 450 \
--point_labels 1 \
--dilate_kernel_size 15 \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pth \
--lama_config ./lama/configs/prediction/default.yaml \
--lama_ckpt ./pretrained_models/big-lamaこの方法は表示と操作が必要です
3.2 何でも埋める
座標点を指定してオブジェクトを塗りつぶし、プロンプトを表示します
python fill_anything.py \
--input_img ./example/fill-anything/sample1.png \
--coords_type key_in \
--point_coords 750 500 \
--point_labels 1 \
--text_prompt "a teddy bear on a bench" \
--dilate_kernel_size 50 \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pthテキストプロンプト: 「ベンチに座っているテディベア」





3.3 何でも置き換える
座標点とプロンプトを指定してオブジェクトを置き換えます
python replace_anything.py \
--input_img ./example/replace-anything/dog.png \
--coords_type key_in \
--point_coords 750 500 \
--point_labels 1 \
--text_prompt "sit on the swing" \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pthテキストプロンプト: 「オフィスにいる男」





3.5 何でも削除するビデオ
python remove_anything_video.py \
--input_video ./example/video/paragliding/original_video.mp4 \
--coords_type key_in \
--point_coords 652 162 \
--point_labels 1 \
--dilate_kernel_size 15 \
--output_dir ./results \
--sam_model_type "vit_h" \
--sam_ckpt ./pretrained_models/sam_vit_h_4b8939.pth \
--lama_config lama/configs/prediction/default.yaml \
--lama_ckpt ./pretrained_models/big-lama \
--tracker_ckpt vitb_384_mae_ce_32x4_ep300 \
--vi_ckpt ./pretrained_models/sttn.pth \
--mask_idx 2 \
--fps 25以下のケースはすべてビデオ ファイルの削除のデモです。



4 まとめ
Inpaint Anything (IA) は、Remove Anything、Fill Anything、Replace Anything の機能を組み合わせた多機能ツールです。IA は、セグメンテーション モデル、SOTA 修復モデル、および AIGC モデルに基づいて、マスクなしの画像修復を実現でき、「クリックして削除、プロンプトで入力」というユーザーフレンドリーな操作モードをサポートします。
さらに、IA は、任意のアスペクト比や 2K 解像度など、さまざまな高品質の入力画像を処理できます。このプロジェクトは、既存の大規模 AI モデルの強力な機能を活用し、「コンポーザブル AI」の可能性を実証します。将来的には、Inpaint Anything (IA) がさらに開発され、きめ細かい画像キーイングや編集などのより実用的な機能をサポートし、より現実世界のアプリケーションに適用される予定です。