前に書いてある
前回の記事では、実現可能なリファクタリング技術ソリューションを設計する方法、つまり理論的な記事について説明しましたが、 この記事では主に、最近のオンライン リファクタリング プロジェクトである乗客待ち行列システムのリファクタリングに基づいた完全なシステム リファクタリング プロジェクトを紹介し、技術ソリューションを構築します。
詳細な技術ソリューションの紹介
1. 背景
1. ステータス:
* 現時点では、オンライン旅客キューイングのパフォーマンスのボトルネックは明らかであり、主に Redis List ストレージ構造が使用されています。キュー内の注文の数が増加すると、クエリ、挿入、注文がキューにあるかどうかの判断などの操作の RT が指数関数的に増加します。
※現状の旅客待ち構造では事業拡大に対応できず、今後の迅速な事業拡大に対応するため、旅客待ち構造の再構築が急務となっております。
2.調査項目
* Mysqlを使用したキュー情報の保存の実現可能性分析(オフライン環境負荷テスト)
* 外部インターフェースと影響範囲の結合(現在提供されている約20の外部インターフェースの分析)、
形式は次のとおりです。
| インターフェース名 | インターフェースパス | 発信者 | SWC | RT(995) | 平均RT | 述べる |
|---|---|---|---|---|---|---|
| エンキューする | /キュー/入力 | XXX | XXX | XXX | XXX |
2. 目標
1. 外部インターフェイスは変更されず、基礎となるストレージから変換され、現在のオンライン表示シーンと互換性があり、乗客ランキング表示とデキュー分離が行われます。
通常キュー、チャネルキュー、優先キュー(絶対優先含む)をキュー時間順に予約したランキング表示
キューのソート係数はキューに入るときに固定ルールに従って計算され、より柔軟な戦略アルゴリズムを使用してキューの優先順位が計算されます。
2. データ ストレージのランキングには Redis の秩序ある収集が使用され、キュー情報には mysql ストレージが追加され、128 のテーブルに分割されます。
3. 現在のパフォーマンスのボトルネック問題を解決し、その後のビジネスの迅速な反復とその後の要件の拡大をサポートします。
3. 全体計画
1. 新旧ソリューションの比較
リファクタリング前のストレージアーキテクチャ: redis: リストデータ構造、キー: ハニカム中心点 + モデル + キュータイプ
リファクタリングされたストレージ アーキテクチャ:
ランキングキュー: Redis 順序セット、キー: ハニカム中心点 + モデル + キュータイプ (古いものとの互換性のため)
キュー情報テーブル: queue_info_xxx、mysql に保存され、ハイブの中心点のハッシュに従ってテーブルに分割され、注文番号 + モデルによって結合一意のインデックスが構築されます。
一部インターフェースの新旧比較
| インターフェース | ランキングを見る | 列に並んでいます | エンキューする | デキューする | 列に並んでジャンプする |
|---|---|---|---|---|---|
| リファクタリングの前に | 1. すべてのキュー内のすべての要素をループし、ループして計算位置を決定します 2. アルゴリズム グループをクエリして推定時間を計算します | キューのすべての要素を走査してクエリを実行し、ループして次の要素が含まれるかどうかを判断します。 | 最初にキューに存在するかどうかを判断し、ここで、ヒットしたさまざまなキューの種類に応じて、redis キュー (リスト) に書き込まれるかどうかも判断します。 | モデルサイクルおよびマルチキュータイプに従ってチーム外のサイクルを実行し、ログを記録します | 列に並ぶ特典カード |
| リファクタリング後 | 「キュー情報テーブル」から順番番号でキューイング情報を問い合わせる キューイング記録がある場合はランキングの有無を判定する ランキングがない場合はM+を表示(ランキングキューはオンライン制御あり)、そうでない場合はクエリ「ランキングキュー」を使用して、注文を直接返します。推定時間を計算するためにアルゴリズム グループをクエリする | 「キュー情報テーブル」に直接クエリを実行し、レコードがあるかどうかを確認します。 | まず「キュー情報テーブル」に書き込み、ランキング閾値を超えていない場合は、対応する「ランキングキュー」に書き込みます。 | 「キュー情報テーブル」のステータスを更新し、順位があればランキングキューから削除し、非同期で候補者に通知し、ログを記録します | キューの順序は、キュー情報テーブルの「order_by」フィールドを更新することで直接変更できます。 |
リファクタリング前のボトルネック分析: 各リクエストはキュー内のすべての要素を取り出してループスルーします (キューに入れられた注文の数が増加すると、RT は指数関数的に増加します。これは大きな問題です。その理由を考えてみませんか?)
リファクタリングされたストレージ アーキテクチャの利点: 元の O(n) 時間の計算量を O(1) の計算量に変更します。
2. リファクタリング後のアーキテクチャ図
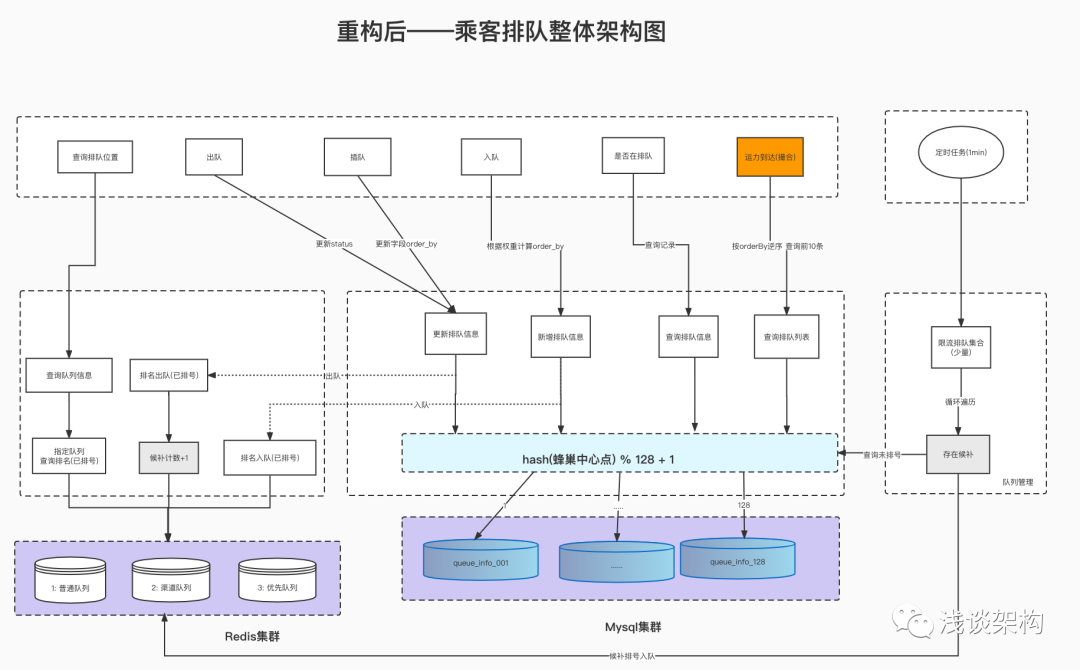
キュー サイズ統計に関する質問:
ランキング無制限フロー キュー: ZCARD 経由で直接取得 (時間計算量は O(1))
ランキング電流制限キュー: カウンタを通じて全長 (O(1)) を取得し、ZCARD を通じてダウングレードを取得します。
2) 新しい容量のマッチングに関しては、クエリ リスト [オレンジ色の部分] にボトルネックの問題がある可能性があります。後の段階では 2 つの最適化方向があり、上位 N にランク付けしてバッファ収集キューから抽出できます。
その他のフローチャート: エンキューおよびデキューのフローチャート (ここでは省略)
テーブル構造設計
queue_info_[001 ~ 128] : キュー情報テーブルはハイブ中心線ポイント ハッシュ % 128 ルールに従ってテーブルに分割され、データは日ごとにアーカイブされます
queue_manager : ランキング キュー管理テーブルは主に、現在の制限状態が存在するかどうか、およびハイブ キュー情報を制御します。
queue_log_[001~128]: 注文入退出記録テーブル。ハイブ正中点ハッシュ % 128 ルールに従ってテーブルに分割され、後でアーカイブするために考慮されます。
詳細なテーブル構造 - 省略
4. ソートフィールド(order_by)の設計
キューイング シナリオの場合、時間が短いほど早くなります。時差は逆順に計算できます。式は次のとおりです: ~(-1L << 39L) & (~(ミリ秒の時差))
その他のルールはここでは省略します。
5. 過去のキューシナリオとの互換性の問題
ランク表示:共通キュー、チャネルキュー、優先キュー
キューからの順序付け: 重み係数のさまざまな構成を通じて、さまざまな種類が最終的に計算されます。
6. グレースケールスキーム
都市のグレースケールに従って、最初に交通量の少ない都市を選択します。
7. ロールバックスキーム
都市のグレースケール スイッチをオフにすると、キュー内の既存のデータが影響を受け、移行ツールでデータを更新する必要があります。
8. データアーカイブ計画とボトムアップ計画
データアーカイブ: 乗客の待ち行列情報は日ごとにアーカイブされます。
肝心な戦略: 長期 (構成可能) キュー ステータスは変化せず (異常である可能性がある)、強制終了
9. データ監視とアラーム
乗客のキューイング Grafana モニタリング: モニタリング指標: 都市、ハイブ、モデル、共通キューの数、チャネル キューの数、優先キューの数 アラーム: キューの数がしきい値を超えた場合の Dingding アラーム
10. 時間の計画
プログラム調査用のインターフェース (20 インターフェース) には、改修プログラム、責任者、進捗項目が追加されます。
| インターフェース名 | インターフェースパス | 発信者 | SWC | RT(995) | 平均RT | 述べる | 改修計画 | 責任者 | スケジュール |
|---|---|---|---|---|---|---|---|---|---|
| エンキューする | /キュー/入力 | XXX | XXX | XXX | XXX |
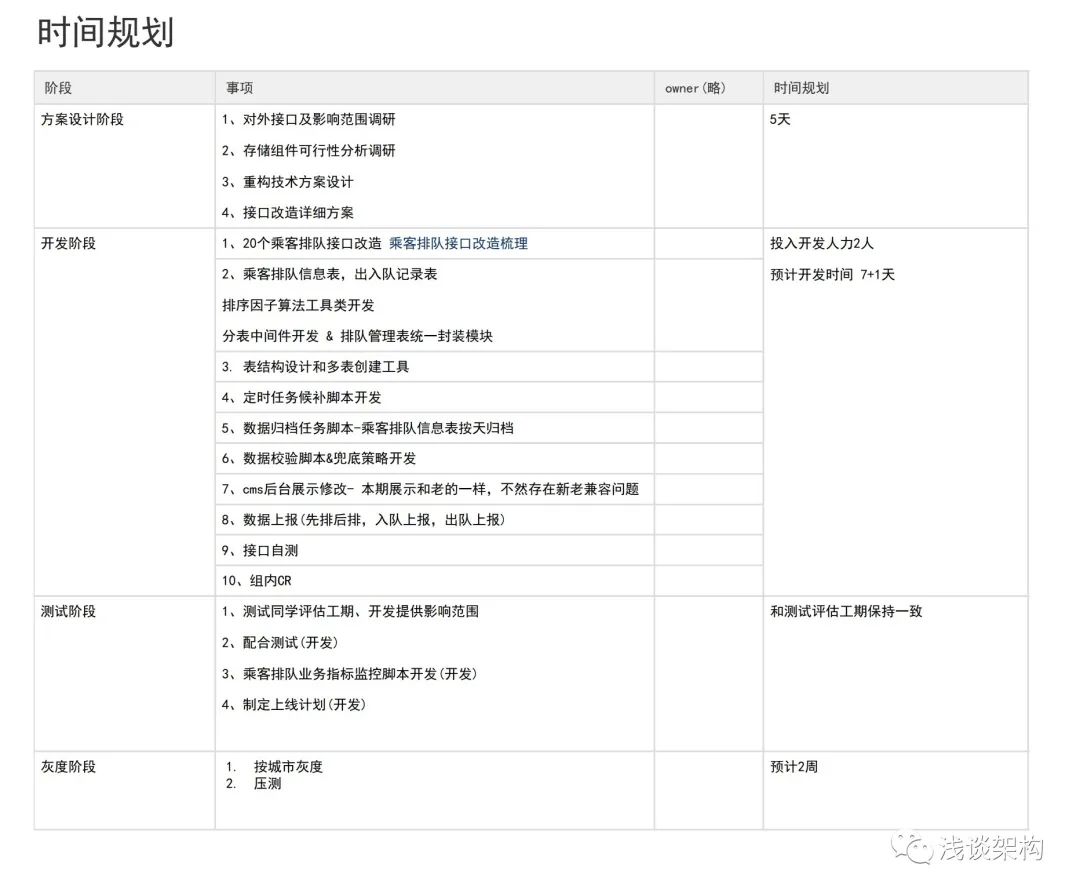
注: インターフェイスのセルフテストと CR は開発段階で完了しますが、監視アラームはテストの開発に影響を与えず、テスト段階で開発できます。
11. 協会団体
わずかに
12. 必要なリソース
わずかに
要約する
リファクタリングでは多くの詳細を考慮する必要があり、考えられるすべてのボトルネック、およびその後の最適化や拡張の問題も考慮する必要があります。
すべての変更は (漏れを避けるために) 個人的に責任を負う必要があり、テスト前にすべてのセルフテスト (単体テスト) に合格する必要があります。
現在、このソリューションのコード開発はほぼ完了していますが、次回は引き続きキューシステムの再構築をシナリオとして、グレースケール段階でのストレステストソリューションの設計方法についてお話していきますので、ご期待ください。それに。
「アーキテクチャについて語る」公開アカウントに注目し、オリジナルの技術記事を随時共有し、将来的にはシステム再構築の技術的な詳細を共有する機会を持つことを歓迎します。
