すいすい年号の表紙に「DataWale が開催する一連の学習活動に初めて参加し、船長の足跡をたどって、他の乗組員と一緒に楽しく習慣を乗り越えていきたい!」と書きたいと思います。私の乗組員はできるだけ早く出航するように!」
目次
1. 機械学習の概要
1. 人工知能、機械学習、深層学習の関係
人工知能は目標を達成すること、機械学習は技術を実装すること、ディープラーニングは機械学習の一分野です。人工知能の概念は 1950 年にはすでに提案されており、機械学習の手法は 1980 年まで登場しませんでした。初期の機械学習は手動の特徴抽出に依存していましたが、現在最も人気のある深層学習はデータの特徴を独立して学習できます。「人工知能」は、人間が機械に学習方法(機械学習アルゴリズム)を教え、機械をインテリジェントにするものとして理解できます。
2. 機械学習の 3 つのステップ
- 検索関数
- 機能がどれほど優れているかを評価する
- 最適な機能を自動スクリーニング
3. 関連テクノロジー (学習戦略、タスク、方法)
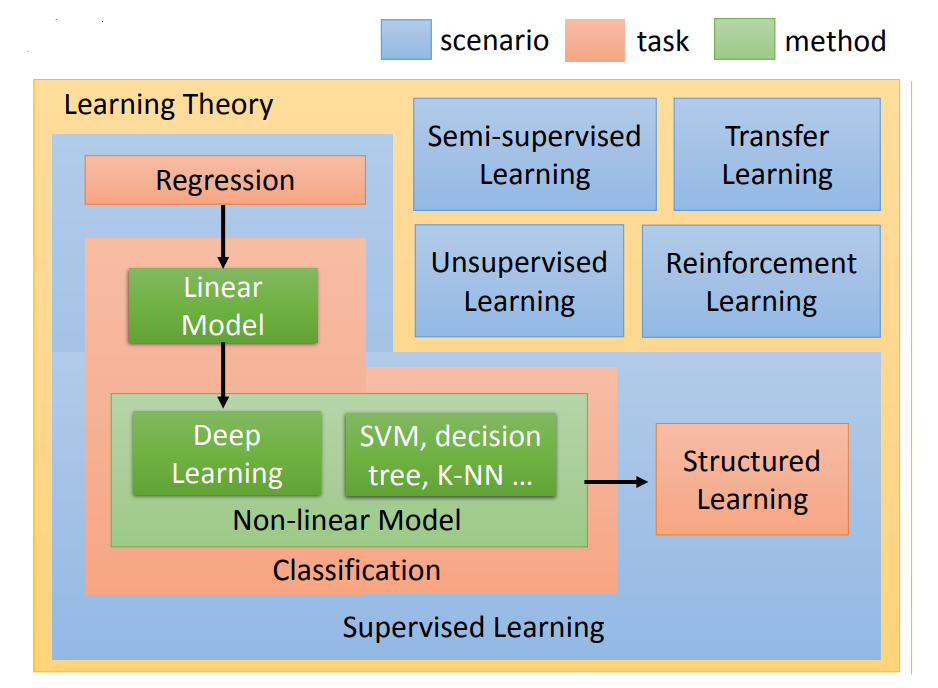
3.1. 教師あり学習
モデルのトレーニングにラベル付きサンプルを使用して、スカラーを予測するタスクは回帰と呼ばれ、離散的な結果を予測するタスクは分類と呼ばれます。構造化学習と呼ばれる別のタイプもあります。つまり、モデルの出力が構造化されています。
3.2. 半教師あり学習
教師あり学習ではモデルの入力とラベルを明示的に伝える必要があり、ラベルは通常人間によってマークされるため、時間と労力がかかります。ラベル付けコストを削減するために、半教師あり学習の概念が導入されます。モデルをトレーニングするための部分的にラベル付けされたデータ。
3.3. 転移学習
タスク A には大きなサンプル データがあり、タスク B には少量のデータがあります。A と B が考慮する実際の問題は異なりますが、A と B はどちらも分類タスクであるため、A の経験の重みをタスク B に転送することが転移学習です. 考えました。
3.4. 教師なし学習
本質的な考え方: 教師なしで独学。ラベルのないデータでモデルをトレーニングします。
3.5. 強化学習
代表例はアルファ碁。強化学習と教師あり学習を比較すると、前者のモデルでは固定された正解が得られますが、後者では継続的に学習して正解に近づくためにフィードバックのみに依存することができます。
なぜ強化学習をして教師あり学習をしないのでしょうか? ラベル付きデータが大量にある場合、誰が強化学習を行うのか。たとえば、医療画像解析の分野では、半教師ありモデルと教師なしモデルを作成する多数の医師のサンプルによってマークされた高品質の画像データを取得できればと考えられます。
概要: 学習戦略はデータのタイプ (ラベル付き、少数のラベル、ラベルなし) に基づいており、タスクはさまざまな学習戦略で出現する可能性があり、さまざまなタスクに対して複数の実装方法があります。
2. なぜ機械学習を学ぶのか
私見:「機械学習」を学ぶ過程で、「AIが人間の仕事を代替する」という話をよく聞きますが、まず、私はこの考え方には同意しません。人々の幸福度を高めるツールとして、現在では私たちの日常生活に溶け込んでいますが、今後はさらに私たちの生活に密接に関わってくるでしょう。AI の出現は多くの伝統的な産業に取って代わる可能性がありますが、同時により多くの新興産業を刺激することになります。人間は常に最先端の生き物です。AI をうまく活用することによってのみ、より良い未来を創造することができます。」
仕事で成果を出したいなら、まずツールを磨かなければなりません。機械学習アルゴリズムは数多くあります。タスクに適したアルゴリズムを選択することによってのみ、期待される結果を達成することができます。また、アルゴリズムを直接コピーするとうまく機能しない可能性があるため、経験豊富な人材がモデルを調整する必要があります。
初日にチェックインして、続けてください!