Yidiandata の独自の技術アーキテクチャは、オフラインのコンピューター室で CDH を使用して構築されたビッグ データ クラスターです。会社設立以来、毎年急成長を続けており、事業の成長に伴いデータ量も急増しています。
ここ数年は1~2年ごとに計画に従ってハードウェアの容量を拡張してきましたが、半年後に再度容量を拡張しなければならないことがよくあります。そして、それぞれの拡張には多大な労力が必要です。
長期にわたる拡張期間、コンピューティングとストレージのリソースの不一致、高額な運用保守コストなどの課題を解決するため、データ アーキテクチャを変革し、データをクラウドに移行し、ストレージとコンピューティングを分離する構造を採用することにしました。今回は、Hadoop のアーキテクチャ設計、モデル選択、コンポーネント評価、クラウドへのデータ移行の全プロセスを紹介します。
現在では、JuiceFSをベースにコンピューティングとストレージの分離アーキテクチャを実現し、総ストレージ容量は2倍に増加しており、性能に明らかな変化はなく、運用保守コストも大幅に削減されています。ケースの最後には、Alibaba Cloud EMR と JuiceFS の実際の運用とメンテナンスの経験が添付されており、このケースが同様の問題に直面している他のピアにとって貴重な参考となることを願っています。
01 古いアーキテクチャと課題
ビジネスニーズを満たすために、Yidian Dataは国内外の大規模Webサイト数百のデータを収集しており、その数は現在500を超え、大量の生データ、中間データ、結果データが蓄積されています。クロールするサイトの数とサービスを提供するクライアント ベースの数が増加し続けるにつれて、データの量は急速に増加しています。そこで私たちは、需要の増加に対応するための規模拡大を開始しました。
本来のアーキテクチャは、CDH を使用してオフラインのコンピューター室にビッグ データ クラスターを構築するものです。以下の図に示すように、主に Hive、Spark、HDFS などのコンポーネントを使用します。CDH の上流にはさまざまなデータ生成システムがありますが、ここでは JuiceFS に関連するため Kafka のみを示します。Kafka 以外にも、TiDB、HBase、MySQL などのストレージ方式があります。
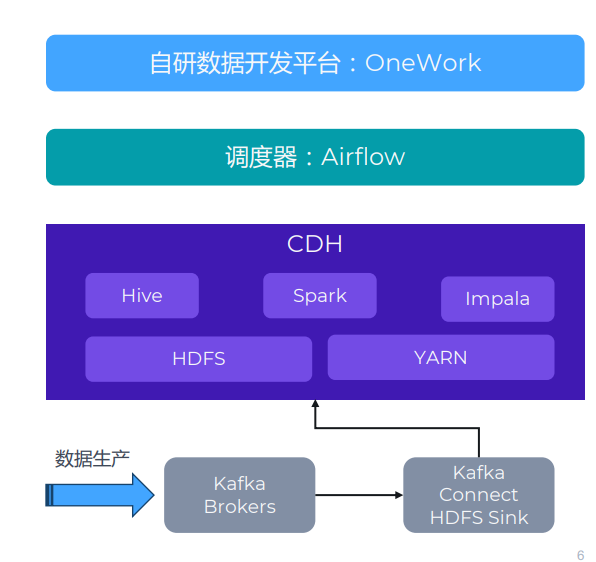
データの流れとしては、上流の業務システムとデータ収集システムがあり、データが収集されてKafkaに書き込まれます。次に、Kafka Connect クラスターを使用してデータを HDFS に同期します。
このアーキテクチャに加えて、OneWork と呼ばれる自社開発のデータ開発プラットフォームを使用して、さまざまなタスクの開発と管理を行っています。これらのタスクは、スケジュール設定のために Airflow を通じてタスク キューに送信されます。
チャレンジ
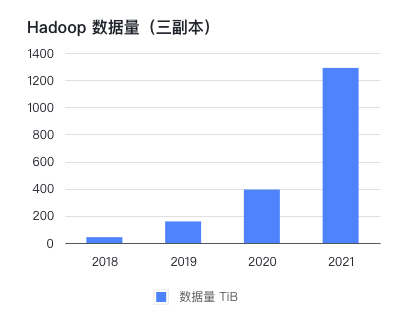
ビジネス/データは比較的急速に成長し、ビジネス拡大サイクルは長期化すると予想されます。同社は 2016 年にオフライン コンピューター ルームに CDH クラスターを導入し、2021 年までに PB レベルのデータを保存および処理しました。同社は設立以来、毎年2倍という高い成長率を維持しており、Hadoopクラスタのデータ量はビジネス量を上回るスピードで増加しています。ここ数年、予想を超えるデータ増加により、1~2年で計画したハードウェアが半年後に再度拡張しなければならないことがよくあります。各拡張サイクルは 1 か月に及ぶ場合があり、ビジネス側は管理プロセスや技術プロセスのフォローアップに多大なエネルギーを費やすことに加えて、データ量を制御するためにより多くの工数を手配する必要があります。容量拡張のためにハードドライブとサーバーを購入する場合、実装期間は比較的長くなります。
ストレージとコンピューティングは結びついているため、容量計画が難しくなり、構成を間違えやすくなります。従来の Hadoop アーキテクチャでは、ストレージとコンピューティングが密接に結合されており、ストレージやコンピューティングの要件に応じて個別に拡張したり計画したりすることが困難です。たとえば、ストレージを拡張する必要があるとします。そのため、まず新しいハード ドライブを購入し、同時にコンピューティング リソースを購入する必要があります。当初は、実際に必要なコンピューティング リソースがそれほど多くないため、コンピューティング リソースが冗長になり、ある程度の投資が必要になる可能性があります。
CDH のバージョンは比較的古いので、あえてアップグレードしません。以前にクラスターを構築したため、安定性を確保するために、あえてアップグレードしませんでした。
運用保守コストが高い(常勤の運用保守員は全社で1人しかいない) 当時、社内に200名以上の社員がいたのに、運用保守員は1人しかいなかったため、運用・保守の負担が非常に大きかったことがわかります。したがって、より安定したシンプルなアーキテクチャを採用してサポートを提供したいと考えています。
コンピューター室には単一のリスクポイントがあります。長期的な要因を考慮すると、すべてのデータは同じコンピューター室に保管されるため、一定のリスクが伴います。たとえば、光ファイバー ケーブルが切断された場合、これは非常に頻繁に発生しますが、依然として 1 つの部屋が単一障害点のリスクにさらされています。
02 新しいアーキテクチャと選択
選択に関する考慮事項
これらの要因と課題を考慮して、いくつかの新しい変更を加えることにしました。以下は、アーキテクチャのアップグレードに関して考慮される主な寸法の一部です。
- クラウドへの移行、柔軟なスケーリング、柔軟な O&M。クラウド上のサービスを活用することで、運用や保守を簡素化できます。たとえば、ストレージに関して言えば、HDFS 自体は安定した成熟したソリューションですが、私たちは基盤となる運用やメンテナンスの作業ではなく、ビジネス レベルに時間を費やすことを好みます。したがって、クラウド サービスを使用する方が簡単かもしれません。また、クラウド上のリソースを活用することで、ハードウェアの導入やシステム構成に長時間を要することなく、柔軟なスケーリングを実現できます。
- ストレージとコンピューティングを分離します。私たちは、柔軟性とパフォーマンスを向上させるために、ストレージとコンピューティングを分離したいと考えています。
- クラウド ベンダーとの束縛を避けるために、オープン ソース コンポーネントを使用するようにしてください。クラウドを選択しても、クラウド サービス自体にあまり依存したくありません。当社は、AWS Redshift などのサービスを顧客に提供する際にはクラウドネイティブ ソリューションを使用しますが、当社自身のビジネスではオープンソース コンポーネントを使用することを好みます。
- 既存のソリューションと可能な限り互換性を持たせて、変更のコストとリスクを制御します。追加の開発コストの発生やビジネスへの影響を避けるために、新しいアーキテクチャが既存のソリューションと互換性があることを望んでいます。
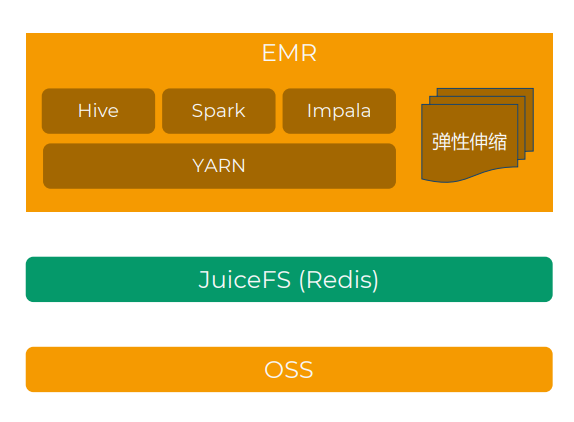
新しいアーキテクチャ: Alibaba Cloud EMR + OSS + JuiceFS
最終的な選択肢は、「Alibaba Cloud EMR + JuiceFS + Alibaba Cloud OSS」を使用してストレージとコンピューティングを分離したビッグデータ プラットフォームを構築し、オフクラウド データセンターのビジネスを段階的にクラウドに移行することです。
このアーキテクチャでは、HDFS の代わりにオブジェクト ストレージを使用し、JuiceFS が POSIX および HDFS プロトコルと互換性があるため、プロトコル層として JuiceFS を選択します。さらに、クラウド上のセミマネージド Hadoop ソリューションである EMR を使用しました。Hive、Impala、Spark、Presto/Trino など、多くの Hadoop 関連コンポーネントが含まれています。
Alibaba Cloud と他のパブリック クラウドの比較
1 つ目は、どのクラウド ベンダーを使用するかを決定することです。ビジネス上のニーズにより、AWS、Azure、Alibaba Cloud が使用されていますが、総合的に検討した結果、Alibaba Cloud が最適であると考えられます。
- 物理的距離:Alibaba Cloudはオフラインコンピュータルームと同じ都市にアベイラビリティゾーンがあり、ネットワーク専用線の遅延が少なく、コストが低い
- オープン ソース コンポーネントの完全なセット: Alibaba Cloud EMR には多くのオープン ソース コンポーネントが含まれており、頻繁に使用される Hive、Impala、Spark、Hue に加えて、Presto、Hudi、Iceberg も簡単に統合できます。調査の結果、Impala には Alibaba Cloud EMR のみが付属しており、AWS と Azure は下位バージョンであるか、独自にインストールしてデプロイする必要があることがわかりました。
ジュースFS vs ジンドFS
Alibaba Cloud の EMR 自体にも、JindoFS を使用したストレージとコンピューティングの分離ソリューションがありますが、次の考慮事項に基づいて、最終的に JuiceFS を選択しました。
JuiceFS は、基盤となるストレージとして Redis とオブジェクト ストレージを使用しており、クライアントは完全にステートレスであり、異なる環境にある同じファイル システムにアクセスできるため、ソリューションの柔軟性が向上します。JindoFS メタデータは EMR クラスターのローカル ハードディスクに保存されますが、保守、アップグレード、移行は簡単ではありません。
- JuiceFS には豊富なストレージ ソリューションがあり、さまざまなソリューションのオンライン移行をサポートしているため、ソリューションの移植性が向上します。JindoFS ブロック データは OSS のみをサポートします。
- オープンソース コミュニティに基づいた JuiceFS は、すべてのパブリック クラウド環境をサポートし、その後のマルチクラウド アーキテクチャへの拡張を容易にします。
ジュースFSについて
公式ドキュメントの導入を直接傍受します。
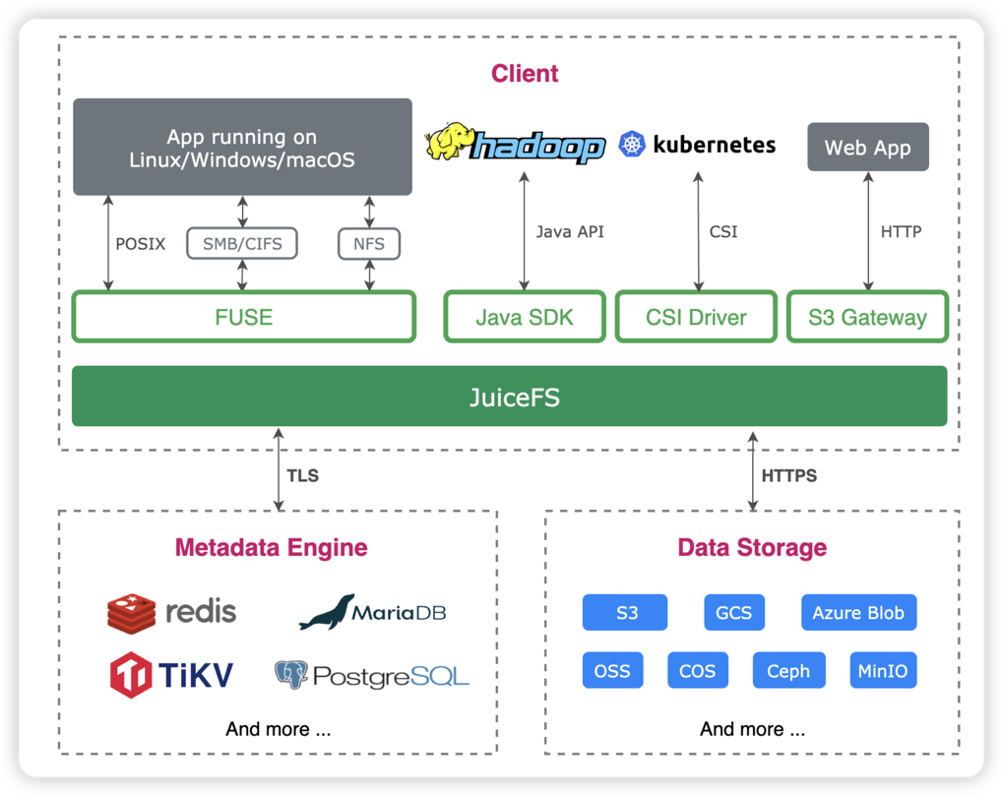
JuiceFS は、クラウド ネイティブ向けに設計された高性能共有ファイル システムであり、Apache 2.0 オープンソース契約に基づいてリリースされています。完全なPOSIX互換性を提供し、ほぼすべてのオブジェクト ストレージを大規模なローカル ディスクとしてローカルに接続でき、また、プラットフォームやリージョンをまたがる異なるホストに同時にマウントして読み取ることもできます。
JuiceFSは、「データ」と「メタデータ」を分離したストレージアーキテクチャを採用し、ファイルシステムの分散設計を実現します。JuiceFS を使用してデータを保存すると、データ自体はオブジェクト ストレージ(Amazon S3 など)に保存され、対応するメタデータはオンデマンドで Redis、MySQL、TiKV、SQLite などのさまざまなデータベースに保存できます。
POSIX に加えて、JuiceFS は HDFS SDK と完全な互換性があり、オブジェクト ストレージと組み合わせて使用すると、HDFS を完全に置き換えて、ストレージとコンピューティングの分離を実現できます。
Hadoop移行クラウドPoC設計
PoC の目的は、いくつかの具体的な目標を掲げて、スキームの実現可能性を迅速に検証することです。
- EMR + JuiceFS + OSS ソリューション全体の実現可能性を検証
- Hive、Impala、Spark、Ranger などのコンポーネントのバージョンの互換性を確認します。
- TPC-DS テスト ケースといくつかの社内の実際のビジネス シナリオを使用したパフォーマンスの評価と比較。非常に正確な比較はありませんが、ビジネス ニーズを満たすことができます。
- 本番環境に必要なノードインスタンスの種類と数を評価(コストを計算)
- データ同期ソリューションを探索する
- 検証クラスターと自社開発のETLプラットフォーム、Kafka Connectなどの統合スキームを探索します。
期間中、多くのテスト、ドキュメント調査、社内外 (Alibaba Cloud + JuiceFS チーム) での議論、ソースコードの理解、ツールの適応などの作業が行われ、最終的に続行が決定されました。
03 実装
2021 年 10 月に Hadoop のクラウド移行ソリューションの検討を開始しました。11 月に多くの調査と議論を行い、ソリューションの内容を基本的に決定しました。12 月と 2022 年 1 月の春節の前に PoC テストを実施し、構築を開始しました春節後の 3 月に正式なクラウド ソリューションを導入し、移行を手配します。ビジネスの中断を避けるため、移行プロセス全体は比較的ゆっくりとしたペースで段階的に実行され、移行後のクラウド上の EMR クラスターのデータ量は単一コピーで 1 PB を超えることが予想されます。

建築デザイン
テクノロジーの選択が完了したら、アーキテクチャ設計も迅速に決定できます。Hadoop クラスターが一部の業務を除いてデータセンターに残ることを考慮すると、実際には全体がハイブリッド クラウド アーキテクチャになります。
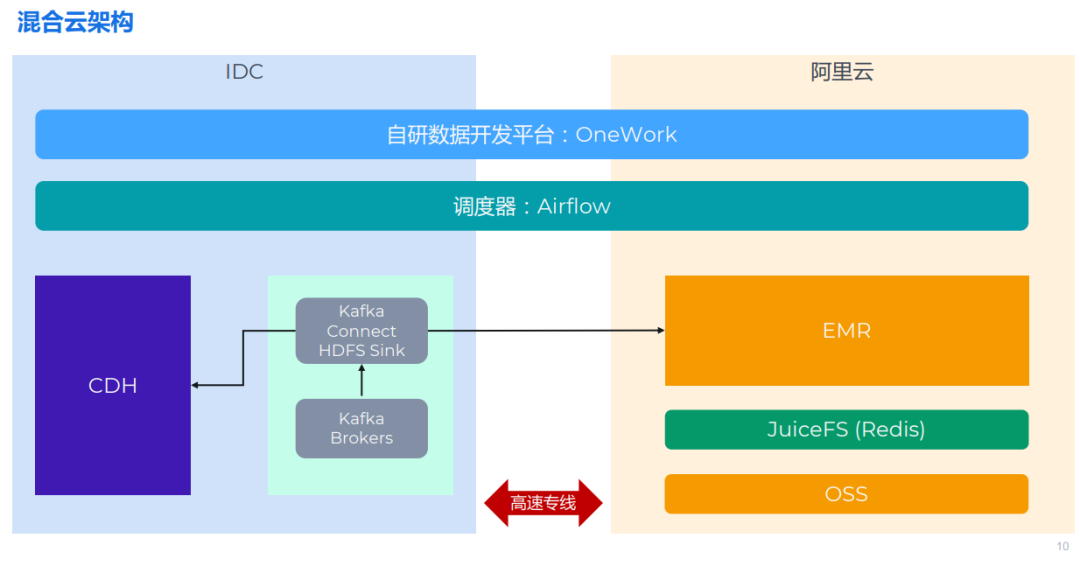
全体的なアーキテクチャはおおよそ上の図に示されているとおりです。左側はオフライン コンピュータ ルームで、従来の CDH アーキテクチャといくつかの Kafka クラスタが使用されています。右側は、Alibaba Cloud にデプロイされた EMR クラスターです。この 2 つの部分は高速の専用線で接続されています。最上位には Airflow と OneWork があり、どちらも分散展開をサポートしているため、簡単に水平方向に拡張できます。
データ移行の課題
課題 1: Hadoop 2 から Hadoop 3 へのアップグレード
CDH バージョンは比較的古いため、あえてアップグレードしませんが、移行したので、新しいクラスターが新しいバージョンにアップグレードできることを期待しています。移行プロセス中は、HDFS 2 と 3 の違いに注意する必要があり、インターフェイス プロトコルとファイル形式が変更される可能性があります。JuiceFS は HDFS 2 および 3 と完全に互換性があり、この課題を十分に満たします。
課題 2: Spark 2 から Spark 3 へのアップグレード
互換性のないアップデートが多数あるため、Spark のアップグレードは比較的大きな影響を及ぼします。これは、もともと Spark 2 で書かれたコードを新しいバージョンに適応させる前に変更する必要があることを意味します。
**課題 3: Hive on Spark は Spark 3 をサポートしていません**
コンピュータ室の環境では、CDH に付属する Hive on Spark がデフォルトで使用されていますが、当時 CDH の Spark バージョンは 1.6 しかありませんでした。クラウド上で Spark 3 を使用していますが、Hive on Spark は Spark 3 をサポートしていないため、Hive on Spark エンジンを引き続き使用できません。
調査とテストの結果、Hive on Spark を Hive on Tez に変更しました。Hive 自体がさまざまなコンピューティング エンジンに抽象化と適応を提供するため、この変更は比較的簡単です。そのため、上位レベルのコードへの変更は比較的小さいです。Tez 上の Hive は、Spark よりもパフォーマンスが若干遅い可能性があります。さらに、Hive と互換性があり、いくつかの新機能を提供する、中国の NetEase によってオープンソース化された新しいコンピューティング エンジン、Kyubi にも注目します。
課題 4: Hive 1 が Hive 3 にアップグレードされ、メタデータ構造が変更されました
Hive アップグレードの場合、最も重要な影響の 1 つはメタデータ構造の変更であるため、移行プロセス中にデータ構造を変換する必要があります。Hive を直接使用してこの移行を処理することはできないため、データ構造を変換するための対応するプログラムを開発する必要があります。
課題 5: 権限管理を Sentry から Ranger に置き換える
これは比較的小さな問題です。つまり、以前は権限管理に Sentry を使用していましたが、コミュニティはあまり活発ではなく、EMR が統合されていないため、Ranger に置き換えました。
技術的な課題に加えて、より大きな課題はビジネス面からもたらされます。
ビジネス上の課題 1: 多くのビジネスが関係しており、配送に影響を与えることはできません
当社は、さまざまなサイト、クライアント、プロジェクトにわたって複数のビジネスを展開しています。ビジネスの提供を中断することはできないため、移行プロセスは段階的な移行アプローチを使用してビジネスによって処理される必要があります。移行プロセス中にデータの変更は、ETL データ ウェアハウス、データ アナリスト、テスト、製品開発など、企業のさまざまな側面に影響を与えます。したがって、十分なコミュニケーションと調整を行い、プロジェクト管理計画とスケジュールを策定する必要があります。
ビジネス課題 2: 複数のデータ テーブル、メタデータ、ファイル、コード
データに加えて、データ ウェアハウス コード、ETL コード、およびこれらのデータをクエリする必要がある BI アプリケーションなどの一部のアプリケーション コードを含む、上位層に多くのビジネス コードもあります。
データ移行: ストック ファイルと増分ファイル
移行するデータには、Hive Metastore メタデータと HDFS 上のファイルの 2 つの部分が含まれます。業務を中断できないため、移行にはストック同期+増分同期(二重書き込み)の方式を採用し、データ同期後に整合性チェックが必要となります。
在庫同期
ストック ファイルの同期の場合、JuiceFS が提供するフル機能のデータ同期ツールsync サブコマンドを使用して、効率的な移行を実現できます。JuiceFS sync コマンドは、単一ノードと複数マシンの同時同期をサポートしています。実際の使用では、単一ノードが複数のスレッドを使用して専用線の帯域幅を最大限に活用できることがわかります。CPU とメモリの使用量は低く、パフォーマンスは優れています。とても良い。sync コマンドは同期プロセス中にローカル ファイル システムにキャッシュを書き込むため、パフォーマンスを向上させるには SSD ディスクにマウントすることが最善であることに注意してください。
Hive Metastore のデータ同期は比較的面倒です。
- 2 つの Hive バージョンは一貫性がなく、メタストア テーブルの構造が異なるため、MySQL のエクスポートおよびインポート機能を直接使用することはできません。
- 移行後、ライブラリ、テーブル、パーティションのストレージ パス (つまり、
dbstableDB_LOCATION_URIとsdstableLOCATION)を変更する必要があります。
したがって、テーブルとパーティションの粒度でのデータ同期をサポートする、非常に使いやすいスクリプト ツールのセットを開発しました。
増分同期
増分データは主に 2 つのシナリオから取得されます。Kafka Connect HDFS シンクと ETL プログラムです。二重書き込みメカニズムを使用します。
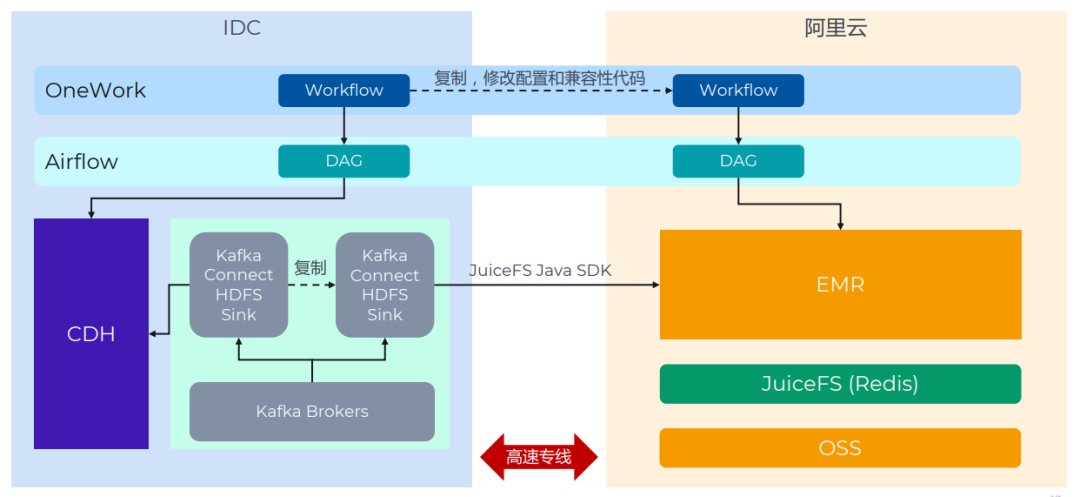
Kafka Connect の Sink タスクはすべてコピーでき、設定方法は上で紹介されています。ETL タスクは OneWork 上で一元的に開発され、最下層はスケジューリングに Airflow を使用します。通常は、関連する DAG をコピーし、クラスター アドレスを変更するだけで済みます。実際の移行プロセスでは、このステップで最も多くの問題が発生し、解決するまでに多くの時間がかかりました。主な理由は、Spark、Impala、および Hive コンポーネントのバージョンの違いによりタスク エラーやデータの不整合が発生し、ビジネス コードの変更が必要になるためです。これらの問題は PoC や初期の移行ではカバーされていませんでしたが、これが教訓となりました。
データ検証
企業が新しいアーキテクチャを安心して使用できるようにするには、データの検証が不可欠です。データを同期した後は、整合性チェックが必要です。これは 3 つの層に分かれています。
-
ファイルは一致します。インベントリ同期フェーズ中にチェックする通常の方法は、チェックサムを使用することです。元の JuiceFS sync コマンドはチェックサム メカニズムをサポートしていませんでした。私たちの提案と議論の後、JuiceFS チームはすぐにこの機能を追加しました (問題、プル リクエスト)。チェックサムに加えて、ファイル属性の比較を使用することも検討できます。2 つのファイル システム内のすべてのファイルの数、変更時刻、属性が一致していることを確認します。チェックサムよりも信頼性はわずかに劣りますが、軽量で高速です。
-
メタデータは一貫しています。考え方には 2 つあります。Metastore データベース内のデータを比較する方法と、Hive の DDL コマンドの結果を比較する方法です。
-
計算結果は一貫しています。つまり、Hive/Impala/Spark を使用していくつかのクエリを実行し、両側の結果が一貫しているかどうかを比較します。参照できるクエリ: テーブル/パーティションの行数、特定のフィールドによるソート結果、数値フィールドの最大値/最小値/平均値、ビジネスでよく使われる統計集計など。
データ検証の機能もスクリプトにカプセル化されているため、データの問題を迅速に発見するのに便利です。
階層型ストレージ
移行してビジネスを安定的に運営した後、階層型ストレージの検討を開始しました。階層ストレージは、さまざまなデータベースやストレージ システムでよくある問題です。ホット データとコールド データには違いがあり、ストレージ メディアの価格も異なります。そのため、コストを抑えるためにコールド データをより安価なストレージ メディアに保存したいと考えています。
以前の HDFS では、階層ストレージ戦略を実装し、2 種類のハードディスクを購入し、ホット データを高速ハードディスクに保存し、コールド データを低速ハードディスクに保存しました。
ただし、パフォーマンスを最適化するために JuiceFS が採用したデータ ブロック モードでは、階層ストレージに制限が課されます。JuiceFS の処理によれば、ファイルがオブジェクト ストレージに保存されるとき、ファイルは論理的に多数のチャンク、スライス、ブロックに分割され、最終的にはブロックの形式でオブジェクト ストレージに保存されます。
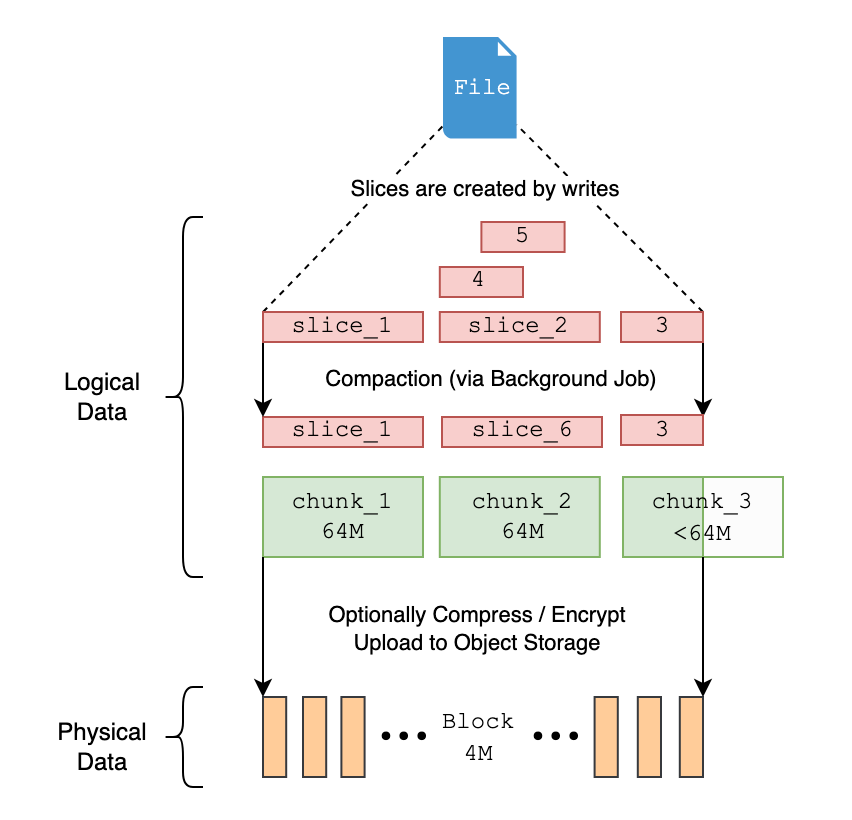
したがって、オブジェクト ストア内のファイルを確認する場合、実際にはファイル自体を直接見つけることはできず、ファイルが分割された小さな部分しか確認できません。OSS はライフサイクル管理機能を提供しますが、テーブル、パーティション、またはファイル レベルに基づいてライフサイクルを構成することはできません。
今後は以下の方法で解決させていただきます。
-
2 つのバケット: 標準 (JuiceFS) + 低頻度 (OSS) : 2 つのバケット (JuiceFS 用に 1 つ) を作成し、すべてのデータを標準ストレージ層に保存します。さらに、追加の低頻度 OSS ストレージ バケットを作成します。
-
ビジネス ロジックに基づいて、テーブル/パーティション/ファイルのストレージ ポリシー テーブルを構成します。テーブル、パーティション、またはファイルに基づいてストレージ ポリシーを設定し、これらのポリシーをスキャンして実行するスケジュールされたタスクを作成できます。
-
Juicesync を使用して低周波ファイルを JuiceFS から OSS にエクスポートし、Hive メタデータを変更します。ファイルが JuiceFS から OSS に転送されると、ファイルは JuiceFS から削除され、ファイルの完全な内容が OSS で表示されるため、ライフサイクル ルールを設定できます。ファイルを転送した後、Hive メタデータを変更し、Hive テーブルまたはパーティションの場所を新しい OSS アドレスに変更する必要があります。EMR の Hive/Impala/Spark などのコンポーネントは OSS をネイティブにサポートしているため、アプリケーション層は基本的に影響を受けません (低頻度のファイルにアクセスすると追加のオーバーヘッドが発生することに注意してください)。
この操作を完了すると、コストを削減するために階層化ストレージを実装することに加えて、JuiceFS メタデータの量を削減できるという追加の利点があります。これらのファイルは JuiceFS に属さず、OSS によって直接管理されるため、JuiceFS の i ノードの数が減り、メタデータ管理への負担が減り、Redis リクエストの数と容量も減ります。 。安定性の観点から、これはシステムにとってより有益です。
04 アーキテクチャアップグレード&フォローアッププランのメリット
ストレージとコンピューティングを分離する利点総ストレージ容量は 2 倍になりましたが、コンピューティング リソースは変更されず、一時的なタスク ノードがオープンされることがあります。このシナリオでは、データ量は非常に急速に増加しますが、クエリ要件は比較的安定しています。データ量は 2021 年から現在までに 3 倍に増加しました。コンピューティング リソースは基本的に初期段階ではあまり変更されていません。特定のビジネス ニーズでより高速なコンピューティング速度が必要な場合を除き、高速化するためにエラスティック リソースと一時的なタスク ノードをオープンします。
パフォーマンスの変化
- 全体として、明らかな認識はありませんが、PoC 期間中の単純な TPCDS テストではほとんど違いが見られず、アドホック Impala クエリの応答が速くなりました。
- HDFS -> JuiceFS、コンポーネントのバージョンのアップグレード、Hive コンピューティング エンジンの変更、クラスターの負荷など、多くの影響要因があります。
当社のビジネス シナリオでは、主にビッグ データのバッチ処理とオフライン コンピューティングを実行します。これは通常、パフォーマンスの遅延の影響を受けません。PoC では、いくつかの簡単なテストを実行しました。ただし、テストプロセスは多くの影響要因の影響を受けるため、これらのテストを正確にすることは困難です。まずストレージシステムをHDFSからJuiceFSに切り替え、同時にコンポーネントのバージョンアップを行い、Hiveエンジンも変更しました。さらに、クラスターの負荷を完全に一貫させることはできません。このシナリオでは、以前に物理サーバーにデプロイされた CDH と比較して、クラスター アーキテクチャのパフォーマンスの違いは大きくありません。
使いやすさと安定性
- JuiceFS自体には問題ありません
- EMR の使用にはいくつかの小さな問題がありますが、全体的には CDH の方が安定していて使いやすいです。
**実装の複雑さ**
- 私たちのシナリオでは、増分二重書き込みとデータ検証プロセスに最も時間がかかります (振り返ってみると、検証への投資は大きすぎるため、合理化することができます)。
- ビジネス シナリオ (オフライン/リアルタイム、テーブル/タスクの数、上位層アプリケーション)、コンポーネントのバージョン、サポート ツール、予備など、多くの影響要因があります。
同様のアーキテクチャまたはソリューションの複雑さを評価する場合、考慮すべき影響要因が多数あります。これには、ビジネス シナリオの違いやレイテンシー要件に対する感度が含まれます。さらに、テーブルのデータ量のサイズも影響します。このシナリオでは、比較的多数のファイルを含む多数のテーブルとデータベースがあります。さらに、上位アプリケーション プログラムの特性、使用されるサービスの数、および関連プログラムも複雑さに影響します。もう 1 つの重要な影響要因は、バージョン移行の段階的な分岐です。翻訳だけを行ってバージョンを同じにしておけば、コンポーネントの影響は基本的に排除できます。
補助ツールと予備は重要な影響要因です。データ ウェアハウスまたは ETL タスクを実行する場合、Hive SQL ファイル、Python または Java プログラムを手動で作成する方法、一般的なスケジュール ツールを使用する方法など、多くの実装方法から選択できます。ただし、どの方法を使用する場合でも、二重書き込みが必要となるため、これらのプログラムをコピーして修正する必要があります。
弊社では、タスク構成が非常に充実した自社開発の開発プラットフォーム OneWork を使用しています。OneWork プラットフォームを通じて、ユーザーは Web インターフェイス上でこれらのタスクを設定し、統合管理を実現できます。Spark タスクのデプロイにはサーバーにログインする必要はなく、OneWork によってそれらのタスクが Yarn クラスターに自動的に送信されます。このプラットフォームは、コードの構成と変更のプロセスを大幅に簡素化します。タスク構成をコピーするスクリプトを作成し、いくつかの変更を加えることで、ほぼ 80 ~ 90% という高度な自動化を実現し、これらのタスクをスムーズに実行できるようになりました。
フォローアップ計画にはいくつかの方向性があります。
- 残りのビジネスのクラウド移行を引き続き完了する
- JuiceFS + OSS のホットおよびコールド階層型ストレージ戦略を検討します。JuiceFS ファイルは OSS 上で完全に分割されており、ファイル レベルに基づいて分類できません。現在のアイデアは、コールド データを JuiceFS から OSS に移行し、アーカイブ ストレージとして設定し、使用状況に影響を与えることなく Hive テーブルまたはパーティションの LOCATION を変更することです。
- 現在、JuiceFS はメタデータ エンジンとして Redis を使用していますが、将来的にデータ量が増加し、Redis の使用が必要になった場合は、TiKV または他のエンジンへの切り替えを検討することもできます。
- EMR のエラスティック コンピューティング インスタンスを検討し、ビジネス SLA を満たしながら使用コストの削減に努めます。
05 付録
導入と構成
IDC-Aliyun専用線について:
専用線サービスを提供できるプロバイダーはIDC、Alibaba Cloud、オペレーターなど多数ありますが、選定の際は主に回線品質、コスト、工期などを考慮し、最終的にIDCのソリューションを選択しました。IDCはAlibaba Cloudと協力し、間もなく専用回線の開通を完了した。この点で問題が発生した場合は、IDC および Alibaba Cloud からのサポートを見つけることができます。Alibaba Cloud は、専用線のレンタル費用に加えて、ダウンリンク (Alibaba Cloud から IDC へ) の伝送料金も請求します。専用回線の両端のイントラネット IP は完全に相互運用可能であり、Alibaba Cloud と IDC の両側でいくつかのルーティング設定が必要です。
EMR コア/タスク ノード タイプの選択について:
JuiceFS はローカル ハードディスクをキャッシュとして使用できるため、OSS 帯域幅要件をさらに削減し、EMR パフォーマンスを向上させることができます。ローカルストレージスペースが大きいほど、キャッシュヒット率が高くなります。
Alibaba Cloud のローカル SSD インスタンスは、(クラウド ディスクと比較して) コスト効率の高い SSD ストレージ ソリューションであり、キャッシュとしての使用に適しています。JuiceFS Community Edition は分散キャッシュをサポートしていません。つまり、各ノードにキャッシュ プールが必要となるため、できるだけ大きなノードを選択する必要があります。
上記の考慮事項と構成の比較に基づいて、各ノードに 64 個の仮想コア、512GiB のメモリ、および 1.8T*8 SSD を備えた ecs.i2.16xlarge を選択することにしました。
EMRバージョンについて:
ソフトウェアに関しては、主にコンポーネントのバージョンの決定、クラスターの有効化、構成の変更が含まれます。私たちのコンピューター室では CDH 5.14 を使用しており、Hadoop のバージョンは 2.6、Alibaba Cloud で最も近いバージョンは EMR 3.38 です。ただし、調査中に、このバージョンの Impala は Ranger と互換性がないことがわかりました (実際、私たちのコンピューター室では、 Sentry は権限管理に使用されますが、EMR では使用できません)、評価と比較の結果、最新バージョンの EMR 5 を直接使用することが決定され、ほぼすべてのコンポーネントのメジャー バージョンがアップグレードされました (Hadoop 3、Spark 3、Impala 3.4 を含む) )。また、Hive Metastore、Hue、Ranger のデータベースとして外部 MySQL を使用します。
JuiceFS 構成について:
基本的には JuiceFS 公式ドキュメント「Hadoop の Java クライアントを介した JuiceFS へのアクセス」を参照して設定を完了してください。さらに、次のパラメータも設定しました。
- キャッシュ関連: 最も重要なのは
juicefs.cache-dirキャッシュ ディレクトリです。このパラメータはワイルドカードをサポートしており、複数のハードディスクのインスタンス環境に非常に適しています。これが設定されている場合/mnt/disk*/juicefs-cache(ディレクトリを手動で作成するか、EMR ノードの初期スクリプトで作成する必要があります)、すべてのローカル SSD がキャッシュ。juicefs.cache-size2 つのパラメータにも注意してくださいjuicefs.free-space。 juicefs.push-gateway: JuiceFS Java クライアントからメトリクスを収集するために Prometheus Push Gateway をセットアップします。juicefs.users、 :複数のノードの uid と gid が均一でない可能性がある問題を解決するために、juicefs.groupsそれぞれ JuiceFS 内のファイル (例jfs://emr/etc/users: ) に設定されます。jfs://emr/etc/groups
JuiceFS を使用した Kafka Connect について:
いくつかのテストの結果、JuiceFS が Kafka Connect の HDFS Sink プラグインに完全に適用できることが確認されました (公式ドキュメントにも設定方法を追加しました)。HDFS シンクを使用して HDFS に書き込むのと比較して、JuiceFS に書き込むには次の構成項目を追加または変更する必要があります。
-
JuiceFS Java SDK の JAR パッケージを Kafka Connect の各ノードの HDFS Sink プラグイン ディレクトリに公開します。Confluent プラットフォームのプラグイン パスは次のとおりです。
/usr/share/java/confluentinc-kafka-connect-hdfs/lib -
JuiceFS 構成を含む任意のディレクトリを書き込み
core-site.xml、Kafka Connect の各ノードに公開します。次の必須の構成項目を含めます。
fs.jfs.impl = io.juicefs.JuiceFileSystem
fs.AbstractFileSystem.jfs.impl = io.juicefs.JuiceFS
juicefs.meta = redis://:[email protected]:6379/1
JuiceFS Java SDK の構成ドキュメントを参照してください。
Kafka コネクタのタスク設定:
hadoop.conf.dir=<core-site.xml所在目录>
store.url=jfs://<JuiceFS文件系统名称>/<路径>
実際の操作とメンテナンスの経験
導入プロセス全体を通じて、私たちはいくつかの落とし穴を次々と踏み、経験を蓄積し、それを参考のために共有しました。
Alibaba Cloud EMR とコンポーネント関連
互換性
- EMR 5 の Hive バージョンと Spark バージョンには互換性がないため、Hive on Spark は使用できません。デフォルトのエンジンを Hive on Tez に変更できます。
- Impala の統計データが古いバージョンから新しいバージョンに同期された後、IMPALA-10230が原因でテーブルがクエリされなくなる場合があります。解決策は、メタデータを同期するときに を . に
num_nulls=-1変更することです。CatalogObjects.thriftnum_nulls=0ファイルの使用が必要になる場合があります。 - 元のクラスターには、snappy で圧縮されたテキストファイル形式のファイルが少量ありましたが、新しいバージョンの Impala はそれらを読み取ることができず、 IMPALA-10005が原因で
Snappy: RawUncompress failedある可能性のあるエラーを報告しました。回避策は、Textfile ファイルに対して Snappy 圧縮を使用しないことです。 - Impala 2.11 と比較すると、Impala 3.4 の関数の動作
CONCAT_WSは異なり、古いバージョンはCONCAT_WS('_', 'abc', NULL)を返しますNULLが、新しいバージョンは を返します'abc'。 - Impala 3.4 では、SQL での予約キーワード参照がより厳密になり、「''」を追加する必要があります。実際、ビジネス コードでは予約キーワードを使用しないのが良い習慣です。
- PoC または事前テストの範囲は可能な限り完全であり、実際のビジネス コードが実行に使用されます。PoC および初期移行ビジネスで使用したコンポーネント機能は比較的少なく、基本的に最もよく使用され互換性のある機能であったため、スムーズに進みました。しかし、2回目の移行で多くの問題が露呈し、最終的には解決したものの、診断や位置決めに余計な時間がかかり、リズムが崩れてしまいました。
パフォーマンス
- EMR 5 の Impala 3.4 にはIMPALA-10695のパッチが適用されており、
oss://とのjfs://独立 IO スレッド数の設定をサポートします (本来の目的は JindoFS をサポートすることですが、JuiceFS もデフォルトで jfs スキームを使用します)。EMR コンソールで Impala 構成項目を追加または変更しますnum_oss_io_threads。 - Alibaba Cloud OSS にはアカウント レベルの帯域幅制限があり、デフォルトは 10Gbps ですが、ビジネス規模が増大するにつれてボトルネックになりやすくなります。Alibaba Cloudと通信して調整することができます。
運用と保守
- EMR は、通常、ビジネス プログラムの展開に使用されるゲートウェイ クラスターに関連付けることができます。ゲートウェイ上のクライアント モードで Spark タスクを送信する場合は、最初にゲートウェイ マシンの IP を EMR ノードのホスト ファイルに追加する必要があります。クラスタモードはデフォルトで使用できます。
- EMR 5 は Spark ThriftServer を起動し、Hue 上で Spark SQL を直接記述することができるため、非常に使いやすくなります。ただし、デフォルト構成には落とし穴があり、大量のログ (パスはおそらく
/mnt/disk1/log/spark/spark-hadoop-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-emr-header-1.cluster-xxxxxx.out) が書き込まれ、ハードディスクがいっぱいになります。解決策は 2 つあります。ログ ローテーションを設定するか、spark.driver.extraJavaOptions設定をクリアします (Alibaba Cloud テクニカル サポートが推奨します)。
JuiceFS関連
- JuiceFS では各ノードで同じ UID と GID が必要です。そうでないと、アクセス許可の問題が発生しやすくなります。実装には 2 つあります。オペレーティング システムのユーザーを変更する(履歴の影響を受けず、新しいマシンにより適しています)、またはJuiceFS 上でユーザー マッピング テーブルを維持します。また、以前にJuiceFS + HDFS のアクセス許可の問題の場所に関する記事を共有し、詳しく説明しました。通常、マッピングを維持する必要があるユーザーには、impala、hive、hadoop などが含まれます。Confluent Platform を使用して Kafka Connect を構築する場合は、cp-kafka-connect ユーザーも構成する必要があります。
- デフォルトのJuiceFS IO 構成を使用する場合、Tez および Spark 上の Hive は、同じ書き込みクエリに対して Impala よりもはるかに高速です (ただし、コンピューター ルームでは Impala の方が高速です)。最後に、juicefs.memory-size をデフォルトの 300 (MiB) から 1024 に変更した後、Impala の書き込みパフォーマンスが 2 倍になったことがわかりました。
- JuiceFS の問題の診断と分析を行う場合、クライアント ログは非常に役立ちます。POSIX と Java SDK のログは異なることに注意してください。詳細については、JuiceFS のトラブルシューティングと分析 | JuiceFS ドキュメント センターを参照してください。
- Redis のスペース使用量の監視に注意してください。Redis がいっぱいの場合、JuiceFS クラスター全体に書き込むことができません。(この点は特に注意が必要です) JuiceFS sync を使用してコンピューター室のデータをクラウドに同期する場合、パフォーマンスを向上させるために SSD を搭載したマシンで実行することを選択してください。
お役に立てましたら、私たちのプロジェクト Juicedata/JuiceFSにご注目ください 。(0ᴗ0✿)
マスク氏はTwitterの名前をXに変更し、ロゴを置き換えると 発表した Reactコア開発者のダン・アブラモフ氏がメタ社からの辞任を発表 MyBatis-FlexのMyBatis-Plus盗用に関する明確化 OpenAIがChatGPTのAndroid版を正式に開始 Android版ChatGPTは来週開始される、事前登録開始 Arc ブラウザ正式リリース 1.0、Chrome Musk の代替品と称して 「ゼロ元で購入」、@x Twitter アカウントを強奪 VS Code で名前難読化圧縮を最適化し、組み込み JS を 20% 削減! 新しい高速 JavaScript ランタイム Bun 0.7 が正式にリリースされ ました