最近、私は LLama の中国語強化トレーニングで忙しかったです。その結果、中国語の語彙の拡張が継続的に事前トレーニングされ、コマンド データが監視および微調整された後、ナレッジ ベースと検索コンテンツを組み合わせると、いくつかの興味深い現象が発見されました。また、グループの全員と簡単にコミュニケーションを取りました。その後、著者がいくつかのトレーニング経験に基づいていくつかの経験を共有します。人それぞれ異なるトレーニング戦略とデータがあるため、トレーニング前の参考経験として使用することをお勧めします。
まず、Q&A を取得するためのプロンプトは次のとおりです。
问题:北京高考真的更容易吗?\n
请结合以下支撑信息,回答上述问题:
支撑信息:\n
[1]考到较低和中等分数(<660)很容易;考到较高分(670-680)高分(680-690)和极高分(690-710)不会比全国I卷容易。(本人做过全国I,II,III,江苏,上海,天津等卷,较为客观)xxx
...
[n]是的,更容易,但不是因为某些人吹的什么“北京卷简单”“人大附中的学生转学来衡水月考当场崩溃(这条拿肚脐眼想都知道是假的)”。xxxxxxx
それを大規模モデルに入力して回答するのですが、おそらくここでの知識の組み合わせを取り出すヒントは構築しやすい、あるいはsftデータのモードと組み合わせて構築できると考えられます。
そこで見つかった問題は、検索モデルによって想起された知識が大規模モデルの生成効果に影響を与えるため、自分で学習させた大規模モデルによって生成された答えが短すぎるという直感です。これを考えると、私たちは崩壊してしまいます。計算能力とエネルギーを費やし、xxxgpt のトレーニングに無駄な労力を費やしました。効果は非常に低いです。どうすれば違いを生むことができるでしょうか?
パニックにならない!改善策もありまして、まずsftのデータが短いかどうか、命令が単一かどうか、連続書き込みで発生するシーンが含まれているかなどを考えて、出力される解答の長さに応じて文字数を予約するなどしてデータをフィルタリングすることで、実際に500ワードで視覚効果を満たしています。次に、検索+生成された指示データを構築することもできますが、注目すべきは答えを得る方法であり、ローカル検索システムや検索エンジンに基づいて文書を取得することも可能です。
大丈夫!上記で選択した「高品質」データの一部に基づいて微調整した後、効果がまだ満足できず、モデル出力の長さが比較的短い傾向にあることが判明したとします。chatgpt や数百億のモデルと比較すると、効果はまだ弱いので、どうすればよいでしょうか? 現時点では、まだ基地の機能を分析する必要があります。まず、ベースのコンテキスト ウィンドウのサイズを選択します。たとえば、LLama-7b、bloom、chatglm などの第一波はすべて 2048 ですが、chatglm2-6b、baichuan-7b、および最新の llama2-7b と比較すると、すべて 4096 であり、2 倍の差があります。また、中国語強化トレーニング後の llama-7b の効果はそれほど悪くない可能性があり、いくつかのテストの結果、 (1) 取得した知識がゴミであっても、chatgpt や 100 億レベルを超える大規模モデルは依然として非常によく答えることができ、
大規模モデルが学習した視野から直接出力されます。

(2) 検索知識が良くない場合、7b の大きなモデルの効果に影響し、生成される長さが比較的短くなります。この点は十分に訓練されていない可能性があります。大きなモデルはどのようにして拒否能力を持つことができますか?

(3) 大規模なモデルが検索知識の影響を受けない場合でも、生成された長さは可能です。
非洲土地肥沃,为什么很多非洲人宁可挨饿也不种地?
1. 缺乏知识和技能:许多非洲农民没有受过农业培训或专业教育。他们可能不知道如何种植作物、管理土壤和灌溉系统等基本知识。
2. 经济条件不佳:由于贫困和不良基础设施等原因, 一些农户无法获得必要的种子、化肥和其他农业生产工具。
3. 文化因素:一些传统文化认为耕作是女性责任,男性则专注于狩猎采集活动。
4. 政府政策问题:政府往往未能提供足够的支持来帮助农民提高生产效率并改善他们的生活水平。
5. 农业技术落后:在非洲的一些地区,传统的农用机械设备已经过时且难以维修维护,这限制了农田的产量和质量。
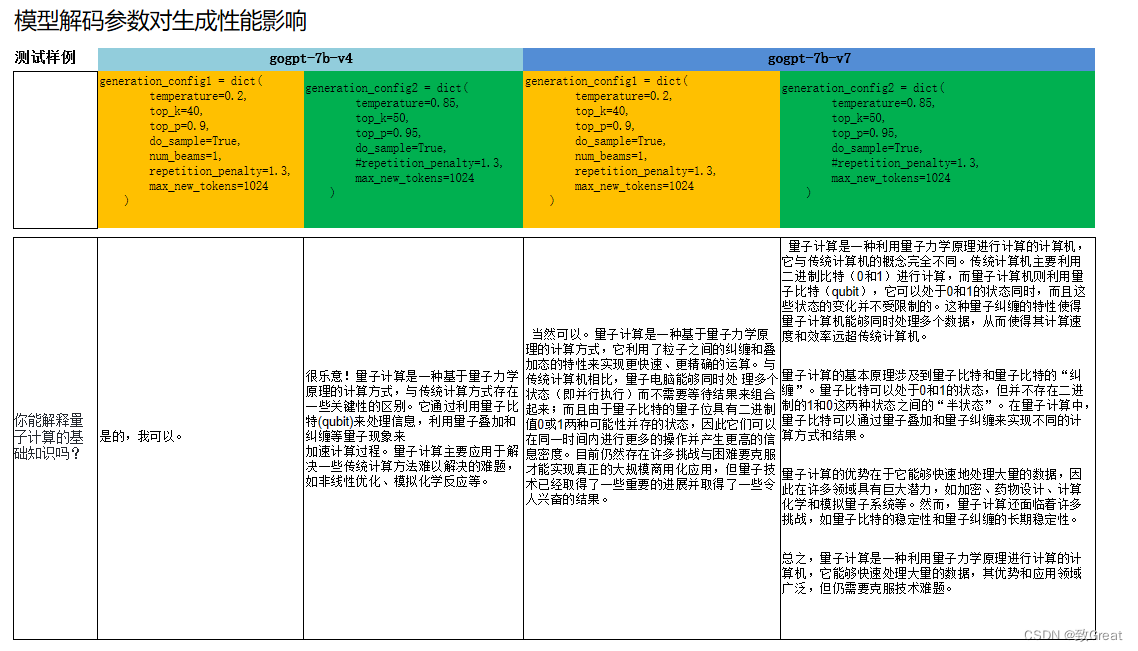
(4) モデルデコードハイパーパラメータは生成性能に影響を与える
デコードパラメータは以下の 2 セットである. 設定 1 と比較して, 設定 2 ではモデル生成がより多様かつ柔軟になり, よりランダムになり, 生成されるテキストが長くなる. より自由度の高いデコードパラメータを使用することで, gogpt-7b テキスト生成の長さを増加させることができる. 単独で Q&A を実行することは問題ないはずである

.
次に要約すると:
(1) 大規模モデルへの知識注入の影響は良くも悪くもあり、これはベースの基本効果、取得精度、データ品質に関係します (2) 大規模モデルをトレーニングするときは、より良いデータに適合するように努めてください。この良好なデータは、高コストで手動でラベル付けされたデータ、または chatgpt によって生成されたデータである可能性があり
ます
。コンピューティング能力が利用可能な場合は、大きなコンテキスト ウィンドウと大量のパラメーターを使用してモデルをトレーニングしてみてください。