1 Introduction
-
Use the CPU to run the C++ version of RWKV
-
rwkv.cpp can convert the parameters of the RWKV original model to float16 and quantize to int4 , which can run faster on the CPU and save more memory.
2. Download project
## git clone --recursive https://github.com/saharNooby/rwkv.cpp.git
cd rwkv.cpp
3. Download dependencies or compile by yourself
-
Use CPU-Z to check whether your CPU supports AVX2 or AVX-512. If so, you can directly download the dependency library compiled by the author
-

-
I support the AVX instruction set here, so I directly use the dependent library compiled by the author
-
The developers of rwkv.cpp have pre-compiled dependent libraries on different platforms, which can be downloaded here
-
Download rwkv-master-a3178b2-bin-win-avx-x64.zip
-

-
After decompression is a dll file, put it in the root directory
-
If there is no dependent library suitable for your platform above, you need to compile it yourself
compile
cmake .
cmake --build . --config Release
4. Prepare the model
- When downloading the project weight, there are two options, one is to download the bin model that the author has quantified, the other is to download the pat model, and then manually quantify it yourself
- BlinkDL (BlinkDL)
4.1. Parameters for the model name
- The unified prefix rwkv-4 indicates that they are all based on the 4th generation architecture of RWKV.
- Pile represents the base model, which is pre-trained on pile and other basic corpus without fine-tuning, and is suitable for Gaowan to customize for himself.
- novel represents the novel model, fine-tuned on novels in various languages, suitable for writing novels.
- raven stands for dialogue model, which is fine-tuned on various open source dialogue materials, suitable for chatting, question and answer, and writing code.
- 430m, 7b These refer to the parameter quantities of the model.

- I downloaded this here
Q8_0-RWKV-4-Raven-7B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230430-ctx8192.bin
Weights can be used directly after downloading without conversion and quantification. If you want to quantify manually, you can continue to see the following steps
- Q8_0-RWKV-4-Raven-7B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230430-ctx8192.bin BlinkDL/rwkv-4-raven at main
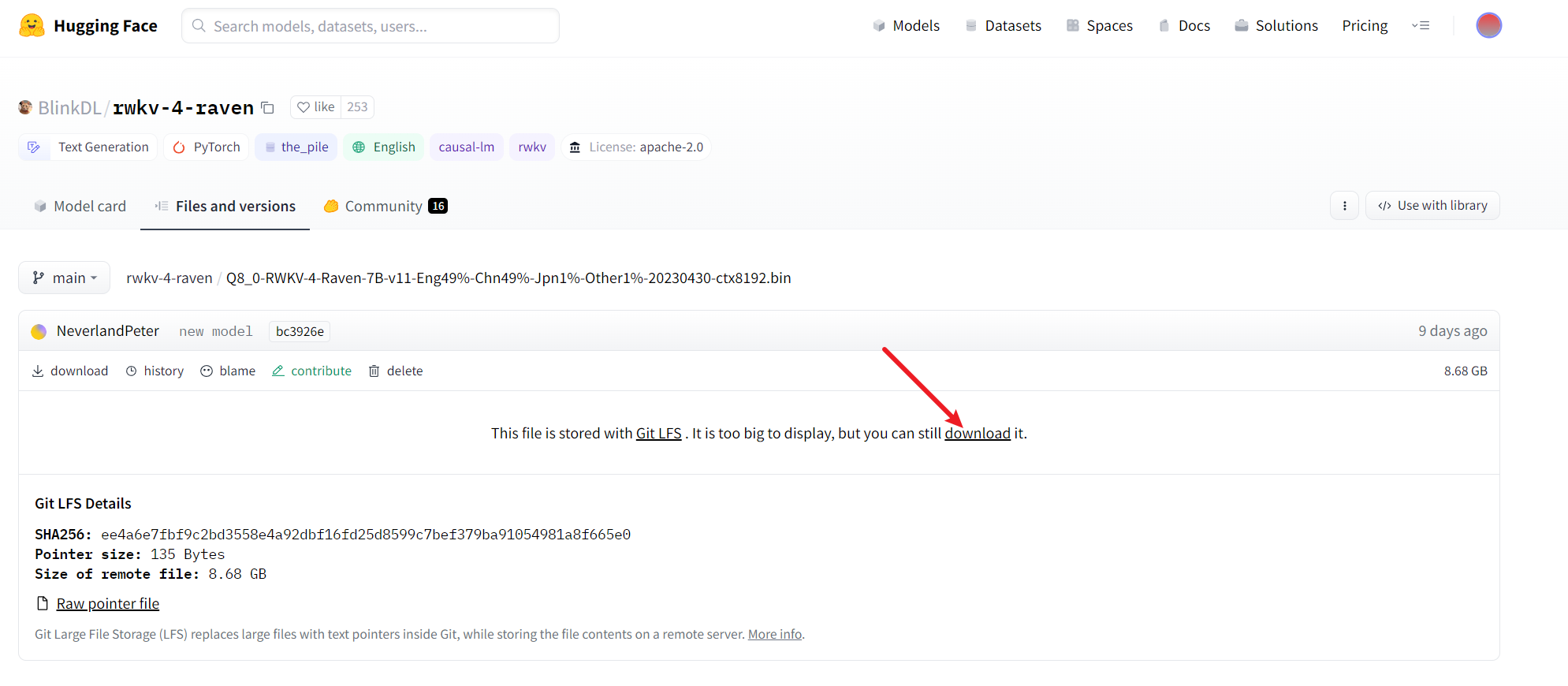
- The file is relatively large, if the network speed is slow, you have to wait a while
4.2. Conversion model
- Under normal circumstances, this model can run after downloading with the code in the ChatRWKV warehouse, but its CPU support is only FP32i8, and the 7B model needs 12GB of memory to run. Therefore, the rwkv.cpp we use can convert RWKV The parameters of the original model are converted to float16 and quantized to int4, which can run faster on the CPU and save more memory
- Place the downloaded PyTorch model in the path of rwkv.cpp and execute the following command
### python rwkv/convert_pytorch_to_ggml.py RWKV-4-Raven-7B-v7-EngAndMore-20230404-ctx4096.pth ./rwkv.cpp-7B.bin float16
- The command of this code is to let Python run the code of this rwkv/convert_pytorch_to_ggml.py conversion model,
- RWKV-4-Raven-7B-v7-EngAndMore-20230404-ctx4096.pth is the weight to be converted, according to the file you downloaded, modify it appropriately
- rwkv.cpp-7B.bin is the converted model path, and float16 refers to converting the model to float16 type


- The generated model, compared with the original model, has not changed in size

4.3. Quantization model
- The rwkv.cpp-7B.bin model after the above conversion is actually ready to use, but it still occupies a lot of video memory, about 16GB of memory. In order to further reduce the memory usage and speed up the reasoning speed of the model, you can use This model is quantized to int4, which can save half of the memory
### python rwkv/quantize.py ./rwkv.cpp-7B.bin ./rwkv.cpp-7B-Q4_1_O.bin Q4_0
- As shown below, the optional parameters here are Q4_0, Q4_1, Q4_2, Q5_0, Q5_1, Q8_0, you can choose according to your actual situation

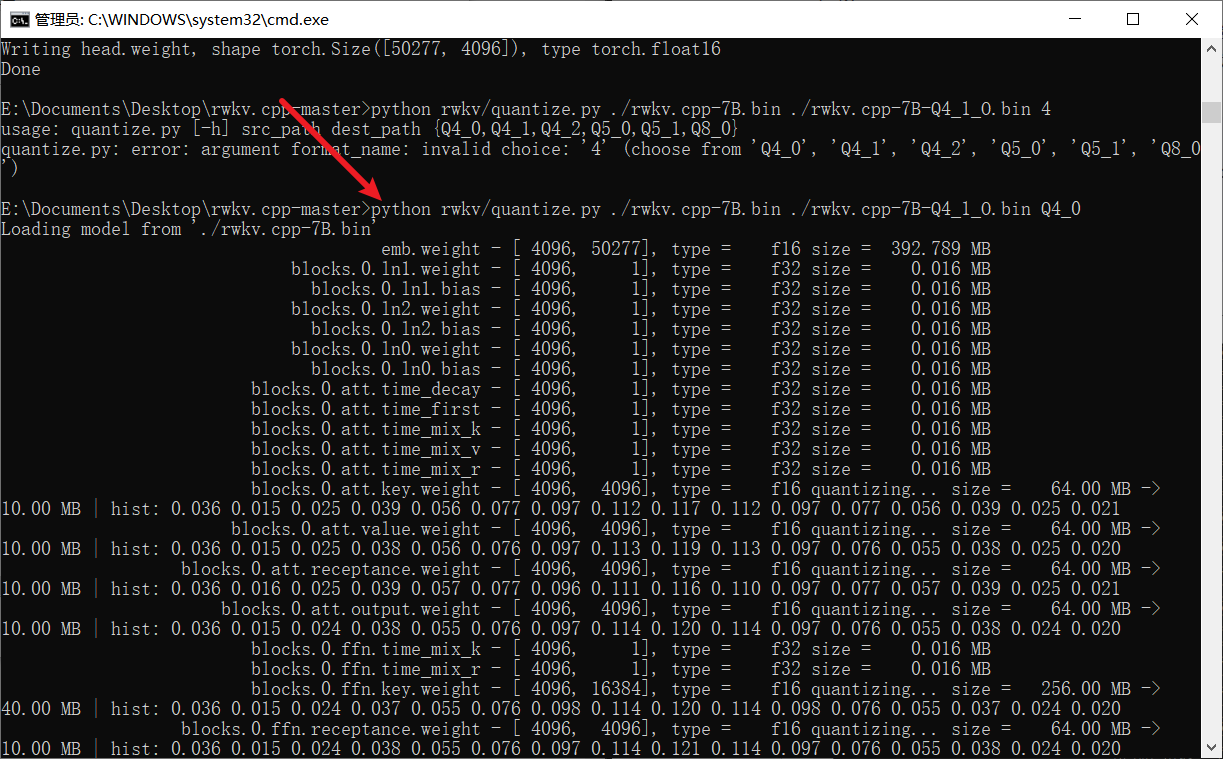

- It can be seen that the quantized model is only 6 G in size
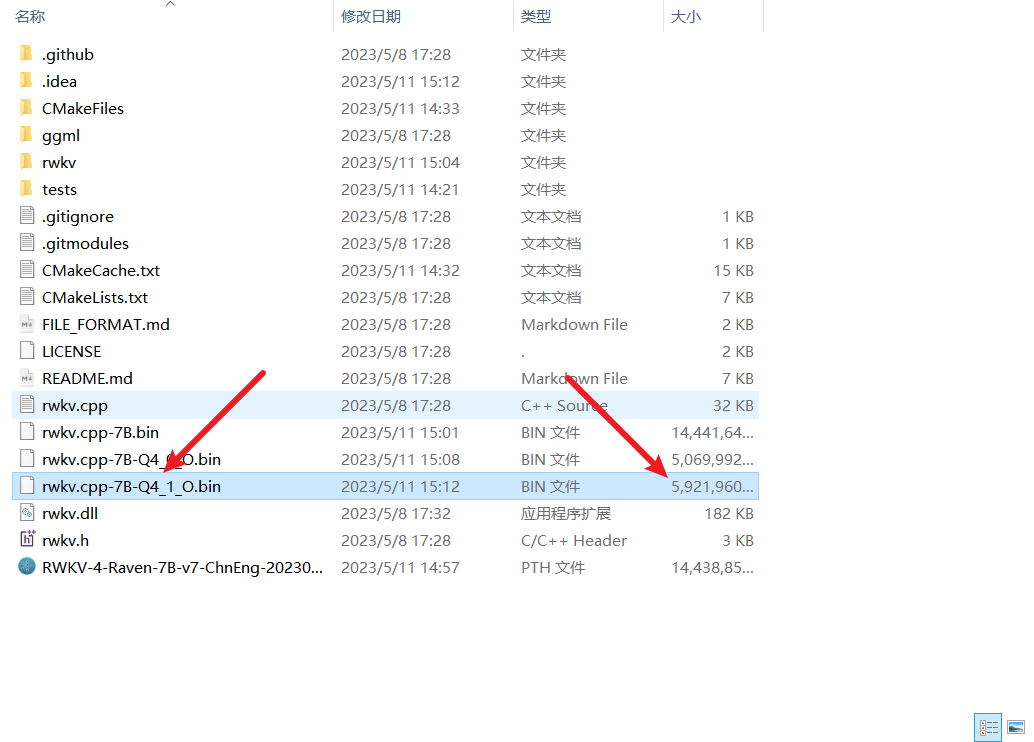
5. Run the model
- After the previous conversion and quantification, it is very simple to run the model, and only one line of commands is needed.
- If you want to generate the model then use the following one to run
### python rwkv\generate_completions.py rwkv.cpp-7B-Q4_1_O.bin
### python rwkv/chat_with_bot.py rwkv.cpp-7B-Q4_1_O.bin
- It takes a long time to start, please wait patiently for a while

After startup, test

6. Test effect
- I don't know why, he replied that he is ChatGPT trained by OpenAI

- The length of the generated text is quite acceptable. Tell him to continue during the dialogue, and he can continue to generate it

and can also be programmed
-

-
But when writing the code, there is still a problem that the output length is too short
-
[External link image transfer...(img-zVNWyhth-1683796408249)]
and can also be programmed
- [External link image transfer...(img-KiL0hZzE-1683796408250)]
- But when writing the code, there is still a problem that the output length is too short