漢字検出、文字検出、手書き数字検出、チベット語検出、甲骨碑文検出は以前の記事で実行しました。今日では、主に実際のプロジェクトのニーズのためです。以前の漢字検出モデルは比較的古く、 yolov3 時代に使用されていたモデル、検出精度、推論速度には大きな遅れがあります。ここでは、yolov5 軽量モデルに基づいて新しいバージョンのターゲット検出モデルを開発して構築する必要があります。まず、レンダリングを見てください。

次に、単純にデータセットを見てみましょう。

YOLO 形式のアノテーション ファイルのスクリーンショットは次のとおりです。
アノテーションの例の内容は次のとおりです。
17 0.245192 0.617788 0.038462 0.038462
6 0.102163 0.830529 0.045673 0.045673
16 0.894231 0.096154 0.134615 0.134615
4 0.456731 0.524038 0.134615 0.134615
15 0.367788 0.317308 0.269231 0.269231
VOC 形式のデータ アノテーション ファイルのスクリーンショットは次のとおりです。
アノテーションの例の内容は次のとおりです。
<annotation>
<folder>DATASET</folder>
<filename>0ace8eaf-8e86-488b-9229-95255c69158c.jpg</filename>
<source>
<database>The DATASET Database</database>
<annotation>DATASET</annotation>
<image>DATASET</image>
</source>
<owner>
<name>YMGZS</name>
</owner>
<size>
<width>416</width>
<height>416</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>17</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>214</xmin>
<ymin>302</ymin>
<xmax>230</xmax>
<ymax>318</ymax>
</bndbox>
</object>
<object>
<name>16</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>210</xmin>
<ymin>67</ymin>
<xmax>229</xmax>
<ymax>86</ymax>
</bndbox>
</object>
<object>
<name>18</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>260</xmin>
<ymin>7</ymin>
<xmax>274</xmax>
<ymax>21</ymax>
</bndbox>
</object>
<object>
<name>10</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>121</xmin>
<ymin>103</ymin>
<xmax>143</xmax>
<ymax>125</ymax>
</bndbox>
</object>
<object>
<name>11</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>296</xmin>
<ymin>289</ymin>
<xmax>352</xmax>
<ymax>345</ymax>
</bndbox>
</object>
<object>
<name>0</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>56</xmin>
<ymin>132</ymin>
<xmax>196</xmax>
<ymax>272</ymax>
</bndbox>
</object>
<object>
<name>0</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>213</xmin>
<ymin>142</ymin>
<xmax>353</xmax>
<ymax>282</ymax>
</bndbox>
</object>
</annotation>メインの軽量ネットワークであるため、ここでは最も軽量な n シリーズ モデルが選択されています。最終的なモデルのファイル サイズは 4MB 未満です。ネットワーク構造図は次のとおりです。

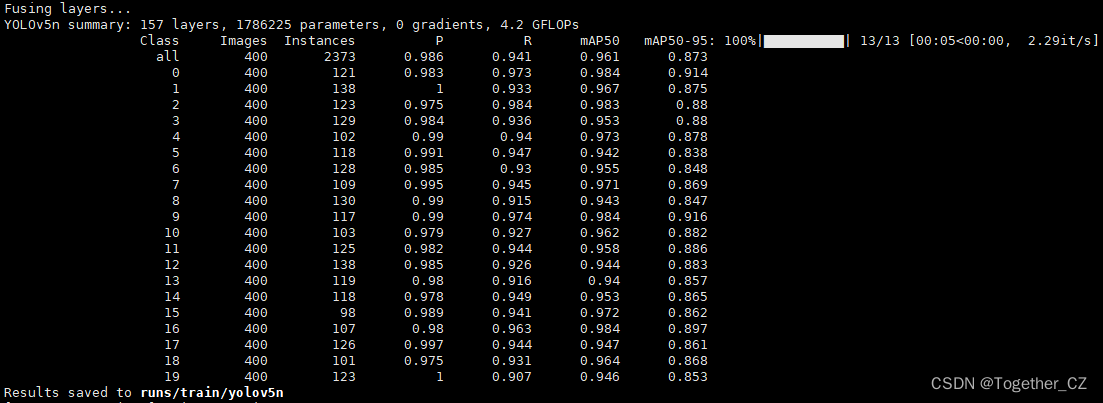
デフォルトの計算は 100 エポックで、結果のディレクトリは次のとおりです。
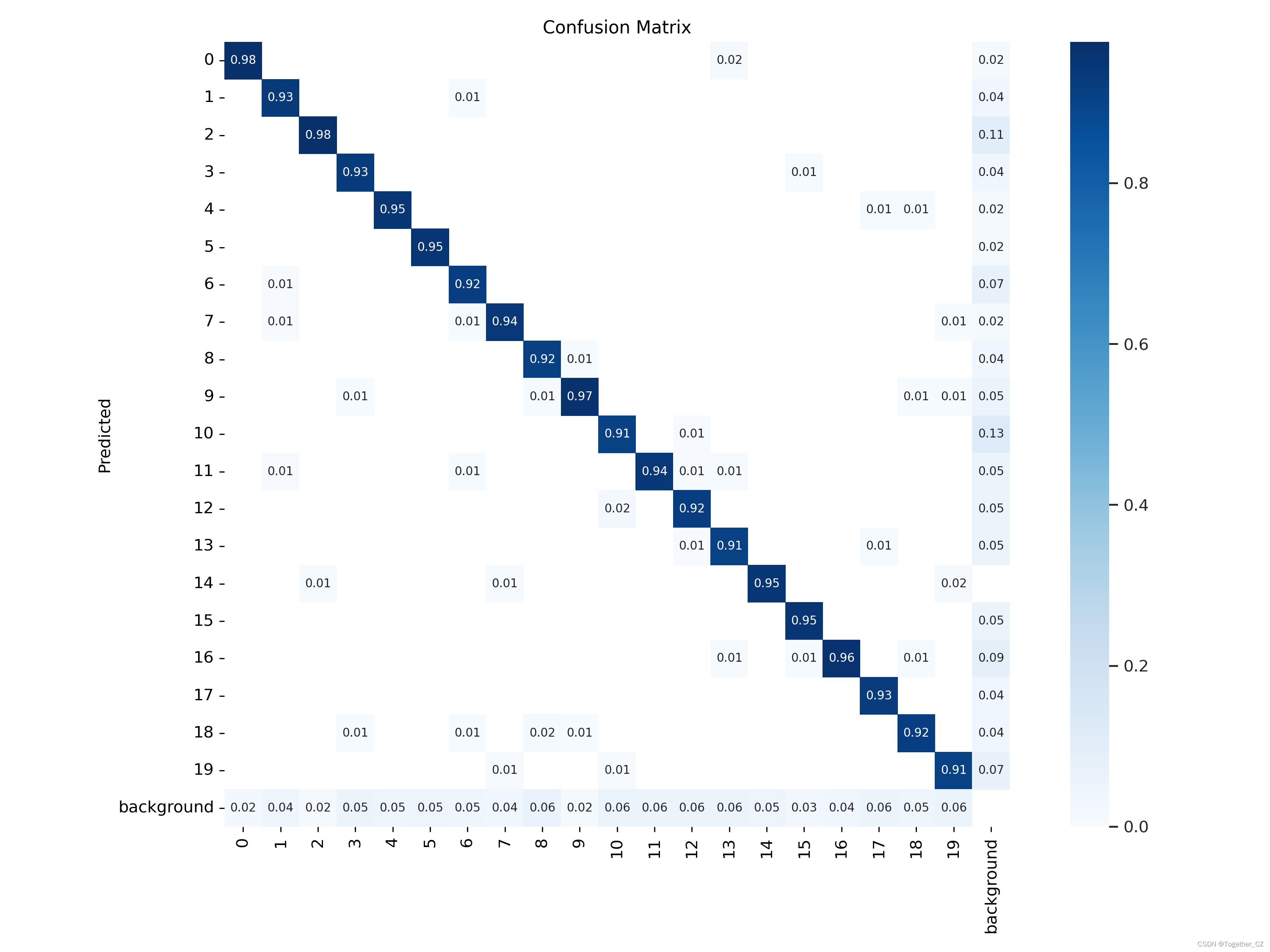
【混同マトリックス】
【F1値カーブ】

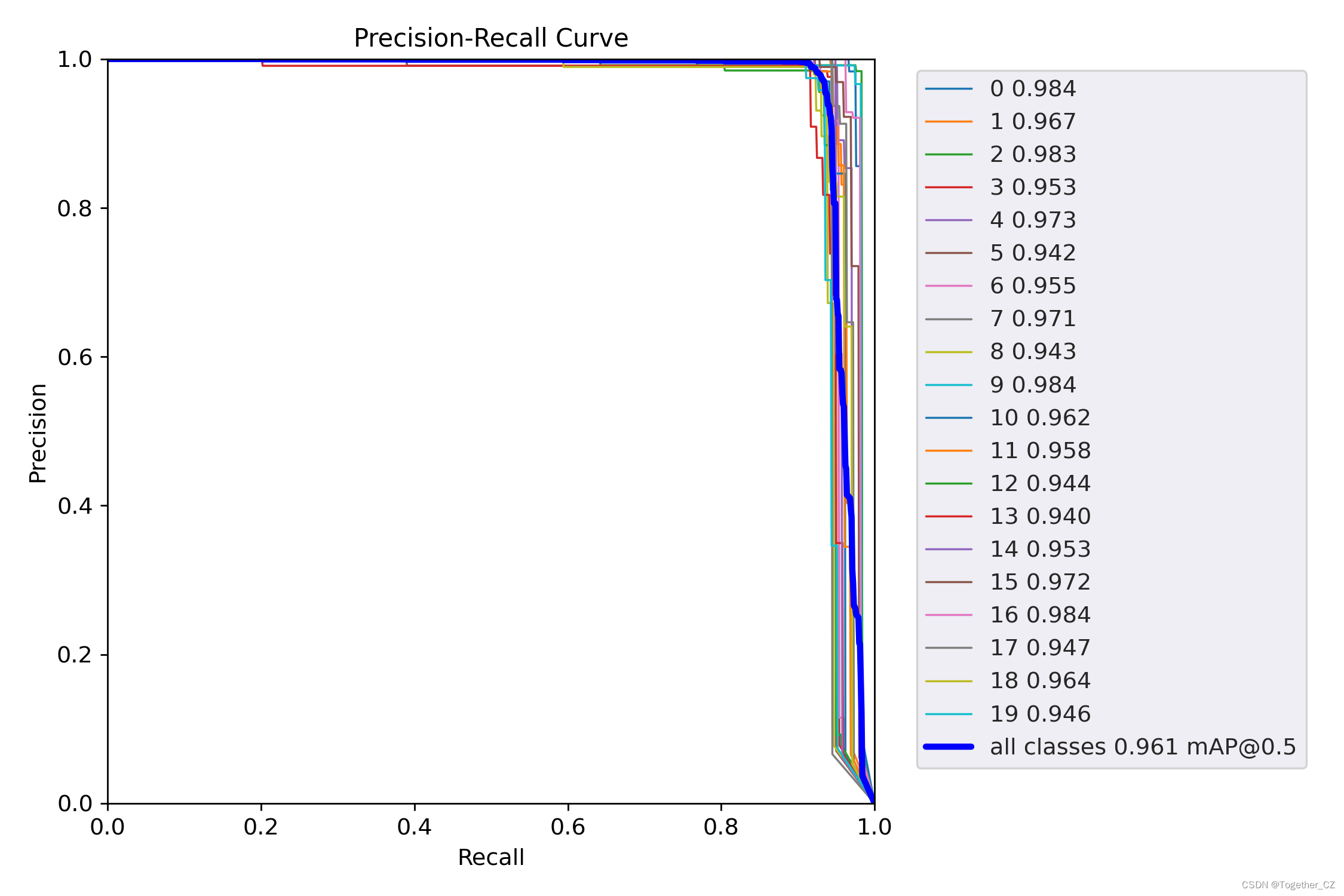
【PRカーブ】
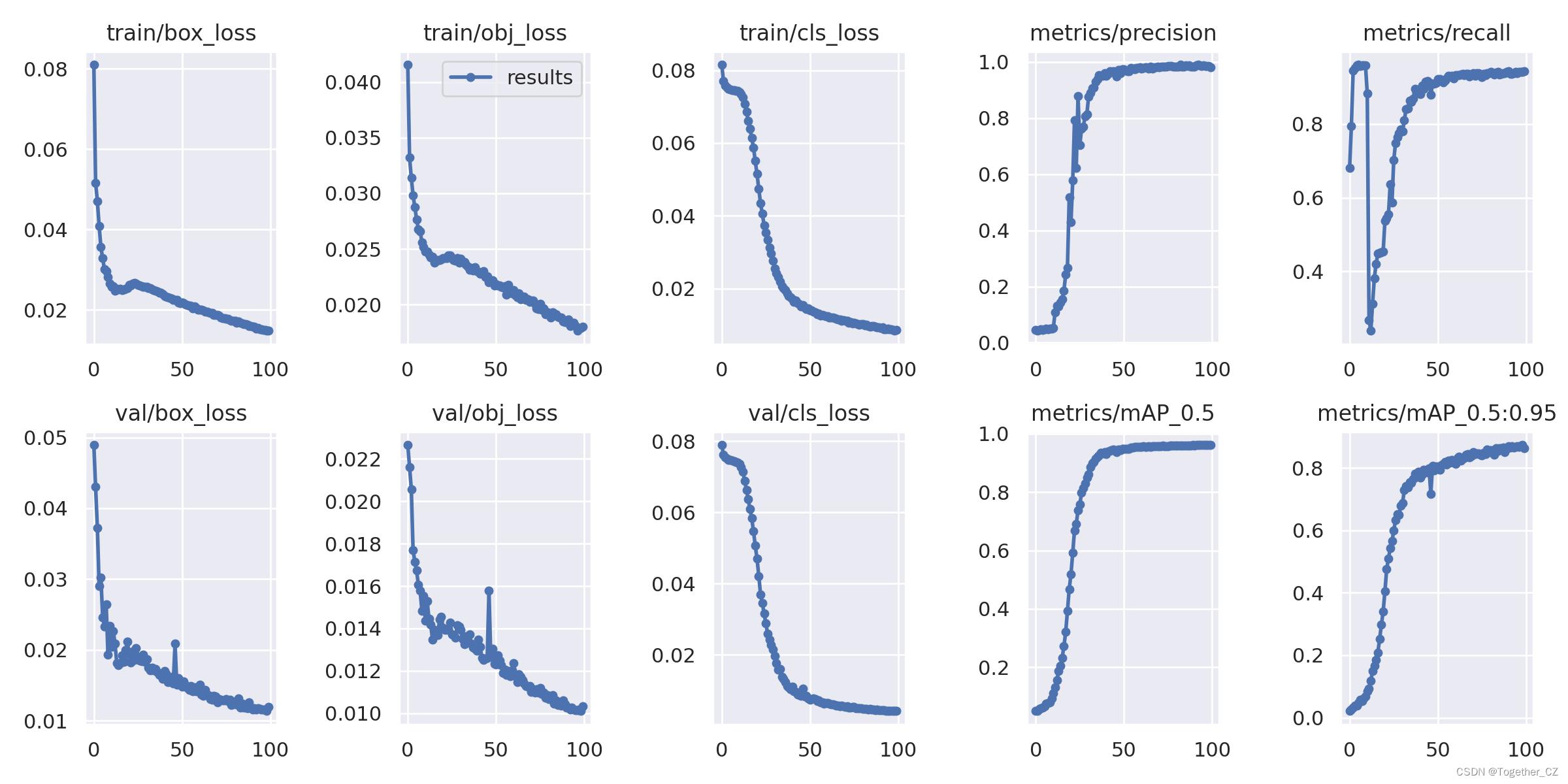
【トレーニングログの可視化】
【一括計算例】

ビジュアル インターフェイス推論の例は次のとおりです。



評価指標の結果から判断すると、検出効果は依然として非常に良好です。