このテキストは前のテキストの続きです。
「Python は、軽量の GhostNet モデルに基づいて 23 種類の一般的な漢方薬の画像認識システムを開発および構築します」
前回の記事では主に、小さなバッチと小さな種類のデータセットに対する軽量 CNN モデルに基づく漢方薬画像認識システムの開発と構築を試みましたが、この記事の本来の目的は、大きなカテゴリと大きなデータの基盤を構築することでした。を設定しましたが、漢方薬の種類は千種類以上あることが判明し、データ収集や手動処理の作業量が膨大なので、一時的に保留して空いた時間を待つしかありません投資を続ける前に。これは、MnasNet に基づいた識別システムを開発および構築するために、40 種類の一般的な漢方薬のデータ セットを構築するためのクローラーです。最初に効果の例を見てください。

MnasNet (Mobile Neural Architecture Search Net) は、Neural Architecture Search (NAS) に基づく軽量の畳み込みニューラル ネットワーク モデルです。ニューラル ネットワーク アーキテクチャの検索を自動化することで、モバイル デバイスに適した効率的なネットワーク構造を見つけます。強化学習アルゴリズムと多目的最適化戦略を使用して、最適なネットワーク アーキテクチャを検索します。ネットワークのさまざまな部分を検索して組み合わせることで、MnasNet は小さいモデル サイズを維持しながら、高いパフォーマンスと精度を実現できます。
モデル検索アルゴリズムを設計する場合、最も重要なポイントが 3 つあります。
1. 最適化目標: 検索されるネットワーク フレームワークのパフォーマンスと効率を決定します。
2. 探索空間: ネットワークがどの基本モジュールで構成されているかを決定します。
3. 最適化戦略: 強化学習の収束速度を決定します。
構築原理
MnasNet モデルのアルゴリズム構築原理は、弱い接続検索アルゴリズムと自動ネットワーク設計手法を使用して効率的な畳み込みニューラル ネットワーク モデルを構築することです。 MNasNet の検索空間は主に MobileNet v2 を参照しており、強化学習を通じて他のモデル検索アルゴリズムとそのリファレンスを上回る MobileNet v2 アルゴリズムを取得しています。人工設計と強化学習の連携がより良い方向であることがわかります。開発の。 MNasNetで提案されている階層型検索空間は、各ネットワークブロックに固有のネットワーク構造を生成することができ、ネットワークのパフォーマンス向上にも非常に役立ちますが、MobileNetを参照したことで検索空間が大幅に削減されるというメリットもあります。 v2 で検索スペースを設計し、検索の難易度を設定します。
弱い接続検索アルゴリズムでは、MnasNet は、ネットワークの各位置に弱い接続を導入し、接続を選択的に追加および削除することでネットワーク構造を検索することにより、弱い接続ベースの検索戦略を使用します。このアプローチにより、検索スペースが大幅に削減され、検索効率が向上します。
MnasNet は、自動ネットワーク設計手法のうち、ネットワーク構造を最適化するための自動ネットワーク設計手法を使用します。この方法では、実行可能な操作と重み空間のセットを定義し、強化学習アルゴリズムを使用して、最適なネットワーク構造を検索します。このアプローチでは、ネットワーク構造を自動的に学習し、高いパフォーマンスを維持しながらモデルのサイズと計算リソースの使用量を削減できます。
利点
高性能: MnasNet は、弱い接続検索アルゴリズムと自動ネットワーク設計手法を使用して、高性能畳み込みニューラル ネットワークを検索および設計できます。これらのネットワークは、複数の画像分類および物体検出タスクで優れたパフォーマンスを実証しています。
軽量: MnasNet は、ネットワーク設計プロセス中にモデルのサイズとコンピューティング リソースの使用を考慮します。ネットワーク設計手法を自動化することで、MnasNet はモデルのサイズと計算量を削減し、高いパフォーマンスを維持しながら軽量化を実現します。
スケーラビリティ: MnasNet の自動ネットワーク設計手法は、強力なスケーラビリティを備えています。さまざまなタスクやデータセットに基づいて自動化されたネットワーク設計を実行でき、さまざまなコンピューティングリソースの制約やアプリケーションシナリオの要件に適応できます。
欠点
トレーニング時間が長い: MnasNet は自動ネットワーク設計手法を使用しているため、大規模な検索空間で検索とトレーニングを行う必要があるため、トレーニング時間が長くなります。
導入と推論が遅い: MnasNet のネットワーク構造は比較的複雑であるため、導入と推論中により多くのコンピューティング リソースが必要になります。特にコンピューティング リソースが限られているデバイスでは、モデルのデプロイメントとリアルタイム推論の効果に影響を与える可能性があります。
MnasNet モデルは、弱い接続検索アルゴリズムと自動ネットワーク設計手法を通じて、高性能で軽量なモデルを構築します。ただし、学習時間が長く、展開や推論の速度が遅いため、実用化にはこれらの要素を総合的に考慮する必要があります。
MnasNet コアの実装は次のとおりです。
class MNASNet(torch.nn.Module):
def __init__(
self,
alpha: float,
num_classes: int = 1000,
dropout: float = 0.2
) -> None:
super(MNASNet, self).__init__()
assert alpha > 0.0
self.alpha = alpha
self.num_classes = num_classes
depths = _get_depths(alpha)
layers = [
nn.Conv2d(3, depths[0], 3, padding=1, stride=2, bias=False),
nn.BatchNorm2d(depths[0], momentum=_BN_MOMENTUM),
nn.ReLU(inplace=True),
nn.Conv2d(depths[0], depths[0], 3, padding=1, stride=1,
groups=depths[0], bias=False),
nn.BatchNorm2d(depths[0], momentum=_BN_MOMENTUM),
nn.ReLU(inplace=True),
nn.Conv2d(depths[0], depths[1], 1, padding=0, stride=1, bias=False),
nn.BatchNorm2d(depths[1], momentum=_BN_MOMENTUM),
_stack(depths[1], depths[2], 3, 2, 3, 3, _BN_MOMENTUM),
_stack(depths[2], depths[3], 5, 2, 3, 3, _BN_MOMENTUM),
_stack(depths[3], depths[4], 5, 2, 6, 3, _BN_MOMENTUM),
_stack(depths[4], depths[5], 3, 1, 6, 2, _BN_MOMENTUM),
_stack(depths[5], depths[6], 5, 2, 6, 4, _BN_MOMENTUM),
_stack(depths[6], depths[7], 3, 1, 6, 1, _BN_MOMENTUM),
nn.Conv2d(depths[7], 1280, 1, padding=0, stride=1, bias=False),
nn.BatchNorm2d(1280, momentum=_BN_MOMENTUM),
nn.ReLU(inplace=True),
]
self.layers = nn.Sequential(*layers)
self.classifier = nn.Sequential(nn.Dropout(p=dropout, inplace=True),
nn.Linear(1280, num_classes))
self._initialize_weights()
def forward(self, x: Tensor, need_fea=False) -> Tensor:
if need_fea:
features, features_fc = self.forward_features(x, need_fea)
x = self.classifier(features_fc)
return features, features_fc, x
else:
x = self.forward_features(x)
x = self.classifier(x)
return x
def forward_features(self, x, need_fea=False):
if need_fea:
input_size = x.size(2)
scale = [4, 8, 16, 32]
features = [None, None, None, None]
for idx, layer in enumerate(self.layers):
x = layer(x)
if input_size // x.size(2) in scale:
features[scale.index(input_size // x.size(2))] = x
return features, x.mean([2, 3])
else:
x = self.layers(x)
x = x.mean([2, 3])
return x
def _initialize_weights(self) -> None:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out",
nonlinearity="relu")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.kaiming_uniform_(m.weight, mode="fan_out",
nonlinearity="sigmoid")
nn.init.zeros_(m.bias)
def cam_layer(self):
return self.layers[-1]
def _load_from_state_dict(self, state_dict: Dict, prefix: str, local_metadata: Dict, strict: bool,
missing_keys: List[str], unexpected_keys: List[str], error_msgs: List[str]) -> None:
version = local_metadata.get("version", None)
assert version in [1, 2]
if version == 1 and not self.alpha == 1.0:
depths = _get_depths(self.alpha)
v1_stem = [
nn.Conv2d(3, 32, 3, padding=1, stride=2, bias=False),
nn.BatchNorm2d(32, momentum=_BN_MOMENTUM),
nn.ReLU(inplace=True),
nn.Conv2d(32, 32, 3, padding=1, stride=1, groups=32,
bias=False),
nn.BatchNorm2d(32, momentum=_BN_MOMENTUM),
nn.ReLU(inplace=True),
nn.Conv2d(32, 16, 1, padding=0, stride=1, bias=False),
nn.BatchNorm2d(16, momentum=_BN_MOMENTUM),
_stack(16, depths[2], 3, 2, 3, 3, _BN_MOMENTUM),
]
for idx, layer in enumerate(v1_stem):
self.layers[idx] = layer
super(MNASNet, self)._load_from_state_dict(
state_dict, prefix, local_metadata, strict, missing_keys,
unexpected_keys, error_msgs)この記事で提案するデータ セットは、自己構築処理から派生したもので、以下に示すように次のカテゴリが含まれています。
三七
人参
佛手片
元胡
厚朴
天南星
天麻
安息香
川芎
巴戟天
当归
木香
朱砂
杜仲
枸杞
桔梗
熊胆
牛黄
玉果
瓜蒌
甘草
生地
白前
白术
白芍
羚羊角
肉苁蓉
苏合香
苦参
茯苓
荜拨
菊花
蔓荆子
贝母
连召
银花
香附
麦冬
黄芪
黄连今後、これをもとにカテゴリーを拡大していきます。
データの例は次のようになります。


データ分布の視覚化は次のようになります。

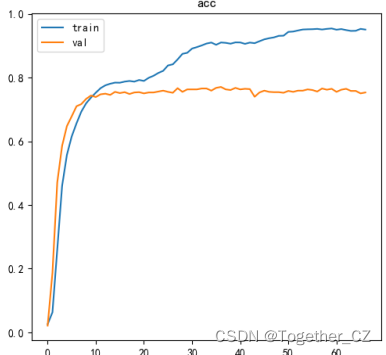
全体的なトレーニング プロセスの損失は次のとおりです。

精度曲線は次のとおりです。
混同行列は次のようになります。
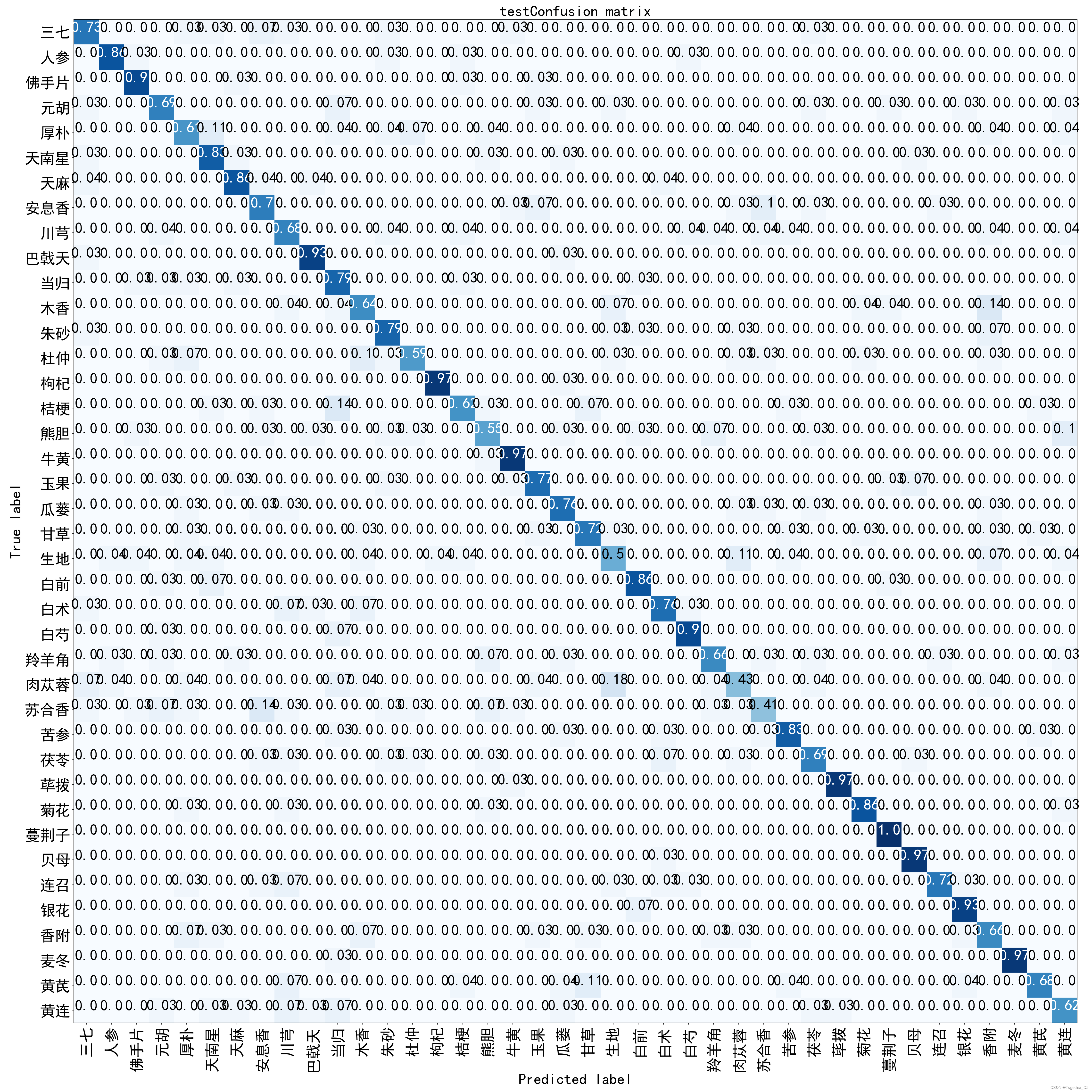
以下に詳しく説明するように、カテゴリごとに個別の指標レビューを実施しました。
+--------+-----------+---------+----------+---------+----------+
| 三七 | 0.70968 | 0.73333 | 0.72131 | 0.71376 | 0.73333 |
| 人参 | 0.89286 | 0.86207 | 0.87719 | 0.87409 | 0.86207 |
| 佛手片 | 0.83871 | 0.89655 | 0.86667 | 0.86312 | 0.89655 |
| 元胡 | 0.66667 | 0.68966 | 0.67797 | 0.66954 | 0.68966 |
| 厚朴 | 0.56667 | 0.60714 | 0.58621 | 0.57557 | 0.60714 |
| 天南星 | 0.70588 | 0.82759 | 0.76190 | 0.75528 | 0.82759 |
| 天麻 | 0.80000 | 0.85714 | 0.82759 | 0.82316 | 0.85714 |
| 安息香 | 0.63636 | 0.70000 | 0.66667 | 0.65735 | 0.70000 |
| 川芎 | 0.57576 | 0.67857 | 0.62295 | 0.61280 | 0.67857 |
| 巴戟天 | 0.87097 | 0.93103 | 0.90000 | 0.89734 | 0.93103 |
| 当归 | 0.58974 | 0.79310 | 0.67647 | 0.66688 | 0.79310 |
| 木香 | 0.64286 | 0.64286 | 0.64286 | 0.63399 | 0.64286 |
| 朱砂 | 0.71875 | 0.79310 | 0.75410 | 0.74745 | 0.79310 |
| 杜仲 | 0.77273 | 0.58621 | 0.66667 | 0.65929 | 0.58621 |
| 枸杞 | 0.96552 | 0.96552 | 0.96552 | 0.96463 | 0.96552 |
| 桔梗 | 0.75000 | 0.62069 | 0.67925 | 0.67179 | 0.62069 |
| 熊胆 | 0.61538 | 0.55172 | 0.58182 | 0.57166 | 0.55172 |
| 牛黄 | 0.84848 | 0.96552 | 0.90323 | 0.90057 | 0.96552 |
| 玉果 | 0.76667 | 0.76667 | 0.76667 | 0.76045 | 0.76667 |
| 瓜蒌 | 0.73333 | 0.75862 | 0.74576 | 0.73911 | 0.75862 |
| 甘草 | 0.77778 | 0.72414 | 0.75000 | 0.74380 | 0.72414 |
| 生地 | 0.53846 | 0.50000 | 0.51852 | 0.50702 | 0.50000 |
| 白前 | 0.83333 | 0.86207 | 0.84746 | 0.84346 | 0.86207 |
| 白术 | 0.78571 | 0.75862 | 0.77193 | 0.76617 | 0.75862 |
| 白芍 | 0.86667 | 0.89655 | 0.88136 | 0.87825 | 0.89655 |
| 羚羊角 | 0.76000 | 0.65517 | 0.70370 | 0.69666 | 0.65517 |
| 肉苁蓉 | 0.52174 | 0.42857 | 0.47059 | 0.45876 | 0.42857 |
| 苏合香 | 0.60000 | 0.41379 | 0.48980 | 0.47913 | 0.41379 |
| 苦参 | 0.82759 | 0.82759 | 0.82759 | 0.82315 | 0.82759 |
| 茯苓 | 0.71429 | 0.68966 | 0.70175 | 0.69422 | 0.68966 |
| 荜拨 | 0.96552 | 0.96552 | 0.96552 | 0.96463 | 0.96552 |
| 菊花 | 0.89286 | 0.86207 | 0.87719 | 0.87409 | 0.86207 |
| 蔓荆子 | 0.87879 | 1.00000 | 0.93548 | 0.93371 | 1.00000 |
| 贝母 | 0.87500 | 0.96552 | 0.91803 | 0.91582 | 0.96552 |
| 连召 | 0.91304 | 0.72414 | 0.80769 | 0.80333 | 0.72414 |
| 银花 | 0.87097 | 0.93103 | 0.90000 | 0.89734 | 0.93103 |
| 香附 | 0.57576 | 0.65517 | 0.61290 | 0.60228 | 0.65517 |
| 麦冬 | 1.00000 | 0.96552 | 0.98246 | 0.98201 | 0.96552 |
| 黄芪 | 0.86364 | 0.67857 | 0.76000 | 0.75477 | 0.67857 |
| 黄连 | 0.66667 | 0.62069 | 0.64286 | 0.63400 | 0.62069 |
+--------+-----------+---------+----------+---------+----------+一部のカテゴリの精度は高くありませんが、全体的には比較的安定しています。