Hadoop: MapReduce の高度なプログラミング (WritableComparable とクリーンアップの使用)
1. ケースの要件
実験内容1、カスタムタイプ
1) 既知のデータ形式は次のとおりです (ユーザー名\t 収入\t 支出\t 日付); PS: 実際には、次のデータのようなスペースに基づいています。
張三 6000 0 2016-05-01
リシ 2000 0 2016-05-01
リシ 0 100 2016-05-01 張三
3000 0 2016-05-01王武
9000 0 2016-05-01
王武 0 200 20 16- 05-01
張山200 400 2016-05-01
2) 要件として、各ユーザーの収入、支出、利益を計算し、利益の大きいユーザーを優先して表示します
(利益が大きい順、または利益が同じ場合は収入の多い順
)。
zhangsan 9200 400 8800
wangwu 9000 200 8800
lisi 2000 100 1900
3) 実験の説明
(1) Hadoop WritableComparable インターフェイス
Writable インターフェイスは、シリアル化プロトコルを実装するシリアル化されたオブジェクトです。Hadoop で構造化オブジェクトを定義するには、構造化オブジェクトをバイト ストリームにシリアル化し、バイト ストリームを構造化オブジェクトに逆シリアル化できるように、Writable インターフェイスを実装する必要があります。WritableComparable インターフェイスは、シリアル化可能で比較可能なインターフェイスです。MapReduce のすべてのキー値型はこのインターフェイスを実装する必要があります。シリアル化可能であるため、2 つのシリアル化関数と逆シリアル化関数 readFields() および write() を実装する必要があります。比較可能なため、実装である CompareTo() 関数を実装する必要があります。比較と並べ替えのルール。このようにして、MR のキー値をシリアル化して比較することができます。
(2) MR の計画と設計のステップ A
、カスタム クラス TradeBean (各トランザクション レコード)、write、readFields、compareTo、toString メソッドと各メンバーの get メソッドと set メソッドを実装する; B、読み取りステップ (Map ステージ) を
取り出すユーザーの各収入と支出。出力段階ではユーザー名をキーとして使用し、値を TradeBean タイプとして使用します。
C、集計ステップ(Reduceステージ)では、各ユーザーの複数の収支記録をカウントし、出力(TradeBean、NullWritable)します。このとき、TradeBean は特定のユーザーの要約統計結果を表します。
実験内容2、トップNソリューション
既知のファイル データは次のとおりです。各行には整数データが 1 つだけ含まれます。
たとえば、mfile1 ファイルは次のようになります。
4
56
7
89
1234
56
789
666
1500
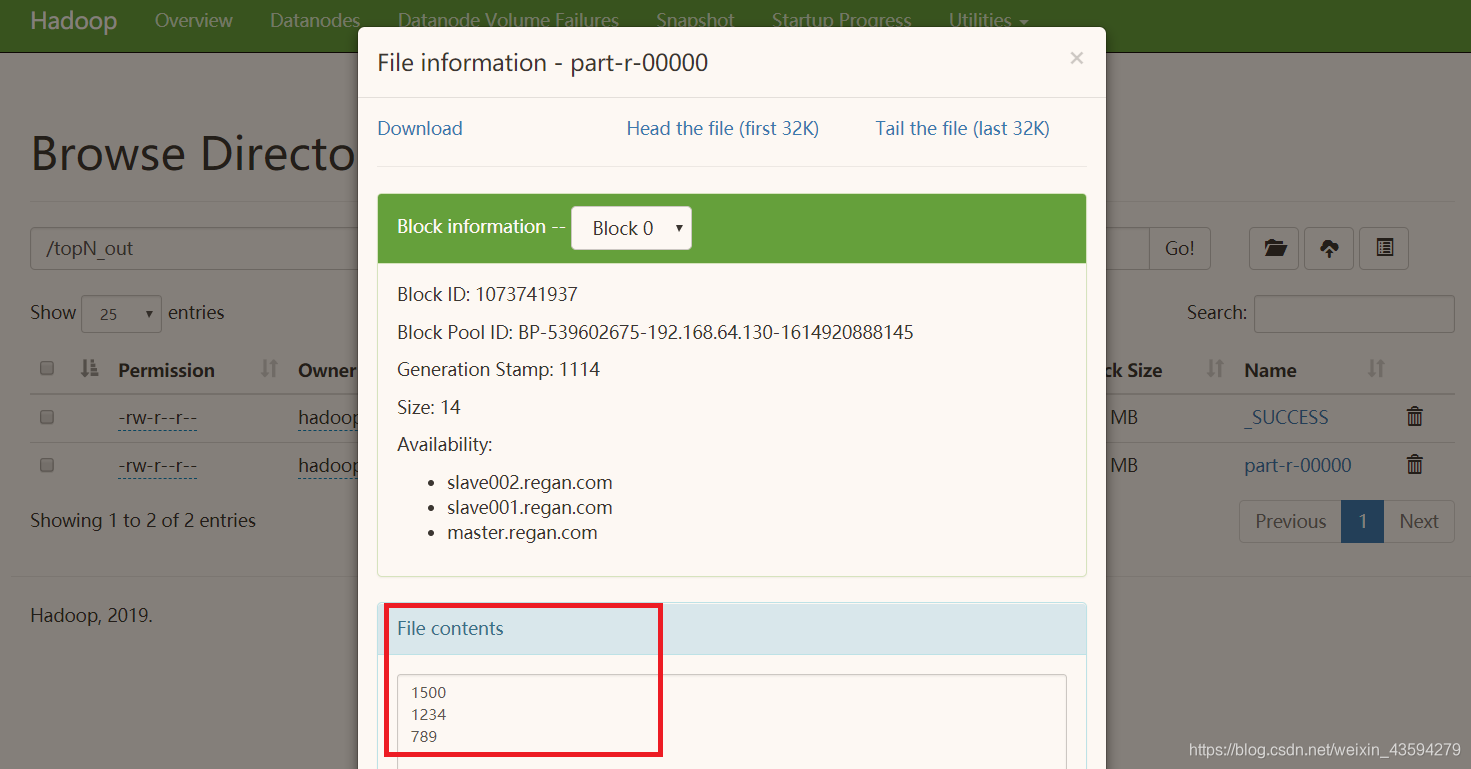
これらすべてのファイルから最大 3 つの値 (上位 3 つ) を見つけて降順に出力する;
問題解決のアイデア: ソートの Reduce ステージにすべてのデータが集中することを回避し、最大 3 つの値を見つけるには、 Mapper以降のCombinerステージが必要 現在のデータブロックの値は、事前に「小さなデータセット」の3つの最大値を取得し、それをReducerステージに渡して3つの最大値を取得します「すべてのデータセット」の。つまり、Mapper クラス、Combiner クラス、Reducer クラスを記述する必要があります。
実験の簡単な分析
実際、これら 2 つのサブ実験は同じ性質の実験であり、両方ともクリーンアップ関数を書き直す必要があります。クリーンアップ関数は、現在のコンテキスト管理が終了するときに 1 回呼び出され、全体のコンテキスト管理が終了したときに最大でも 1 回だけ呼び出されます。プログラムが実行中です。最初の実験では、タイトルの要件に従って TradeBean を作成すると、WritableComparable インターフェイスが継承され、最終的に降順を達成できないことがわかります。これは、MapReduce がデフォルトで Key のみをソートし、Bean を Value に配置するためです。手動で追加することしかできません。並べ替えについては、詳細については以下のコードを参照してください。
2. 導入プロセス
1.IntelliJ IDEAはMavenプロジェクトを作成します
プロジェクトの階層を次の図に示します。
2. 完全なコード
まずpomファイルを設定し、先ほどと同様にHadoop: MapReduce逆インデックス(CombinerとPartitionerの使用)を見てコピーし
、それぞれの実験を一つずつ紹介していきます。
副実験1
TradeBean.java
package subExp1;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class TradeBean implements WritableComparable<TradeBean>{
private String username;
private int income;
private int outcome;
private int profit;
public TradeBean(){
}
//Getter & Setter
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public int getIncome() {
return income;
}
public int getOutcome() {
return outcome;
}
public int getProfit() {
return profit;
}
public void setIncome(int income) {
this.income = income;
}
public void setOutcome(int outcome) {
this.outcome = outcome;
}
public void setProfit(int profit) {
this.profit = profit;
}
@Override
public String toString() {
//重写toString方法,这是必要的,因为这直接决定TradeBean输出到最终文件的结果
return username + "\t" +
"\t" + income +
"\t" + outcome +
"\t" + profit;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
//顺序跟定义字段时的顺序保持一致以便序列化
dataOutput.writeUTF(username);
dataOutput.writeInt(income);
dataOutput.writeInt(outcome);
dataOutput.writeInt(profit);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
//顺序跟定义的顺序保持一致以便反序列化
this.username=dataInput.readUTF();
this.income=dataInput.readInt();
this.outcome=dataInput.readInt();
this.profit=dataInput.readInt();
}
@Override
public int compareTo(TradeBean bean) {
/**
重写比较方法,可以是>0 return 1,<0 return -1这种形式也可以是下面这种,
直接拿比较对象和本对象属性进行相减的比较。
默认是升序,比较的本质原则就是将正数或者说较大的数放到较小数之后,所以this-bean>0则this会放到bean后面。
我们需要的是降序所以需要bean-this
*/
int result = bean.profit-this.profit; //按利润降序
if(result==0) //利润相等则按收入降序
return bean.income-this.income;
return result;
}
}
TradeMapper.java
package subExp1;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class TradeMapper extends Mapper<LongWritable, Text,Text,TradeBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
TradeBean bean = new TradeBean();
//只提取收入和支出,忽略掉时间
int income = Integer.parseInt(words[1]);
int outcome = Integer.parseInt(words[2]);
bean.setUsername(words[0]);
bean.setIncome(income);
bean.setOutcome(outcome);
bean.setProfit(income-outcome);
context.write(new Text(words[0]),bean);
}
}
TradeReducer.java
package subExp1;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.TreeMap;
public class TradeReducer extends Reducer<Text, TradeBean,TradeBean, NullWritable> {
TreeMap<TradeBean,String> treeMap = new TreeMap<>(); //使用TreeMap自动排序的特性,其他数据结构均可
@Override
protected void reduce(Text key, Iterable<TradeBean> values, Context context) throws IOException, InterruptedException {
int income = 0;
int outcome = 0;
int profit = 0;
//整合同用户的收入和支出
for (TradeBean bean : values) {
income+=bean.getIncome();
outcome+=bean.getOutcome();
profit+=bean.getProfit();
}
TradeBean tradeBean = new TradeBean();
tradeBean.setUsername(key.toString());
tradeBean.setIncome(income);
tradeBean.setOutcome(outcome);
tradeBean.setProfit(profit);
treeMap.put(tradeBean,""); //由于只对tradeBean排序,所以treeMap的value值无所谓,所以填了""
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
//foreach 将排好序的tradeBean写入上下文
for (TradeBean bean:treeMap.keySet()){
context.write(bean,NullWritable.get());
}
}
}
TradeJobMain.java
package subExp1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TradeJobMain {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(TradeJobMain.class);
job.setMapperClass(TradeMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(TradeBean.class);
job.setReducerClass(TradeReducer.class);
job.setOutputKeyClass(TradeBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,args[0]);
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//如果本地安装了Hadoop,可以本机运行,无需到虚拟机集群上验证
// FileInputFormat.setInputPaths(job,new Path("file:///D:\\mapreduce\\input"));
// FileOutputFormat.setOutputPath(job,new Path("file:///D:\\mapreduce\\trade"));
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
副実験2
TopMapper.java
package subExp2;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.TreeSet;
public class TopMapper extends Mapper<LongWritable, Text,IntWritable, IntWritable> {
TreeSet<Integer> set= new TreeSet<>(); //使用TreeSet进行排序
IntWritable outKey = new IntWritable();
IntWritable one = new IntWritable(1); //这步是必要的,否则会报错
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
int num = Integer.parseInt(value.toString().trim());
set.add(-num); //负数细节,由于TreeSet是默认升序,所以将数值变相反数以达到降序目的
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
//这里完全可以用set 遍历前3条数据
set.stream().limit(3).forEach( (num)->{
//流的形式读取前3个到写入上下文中
outKey.set(num);
try {
context.write(outKey,one);
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
});
}
}
TopCombiner.java
package subExp2;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class TopCombiner extends Reducer<IntWritable, IntWritable,IntWritable,IntWritable> {
int count = 0;
IntWritable outKey = new IntWritable();
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
if (count <= 3) {
//都只写入前三的数字
outKey.set(-key.get()); //这里要将数值的正负号反转,以便在Reducer阶段写入和原数值相同
context.write(outKey,values.iterator().next());
count++;
}
}
}
TopReducer.java
package subExp2;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class TopReducer extends Reducer<IntWritable, IntWritable,IntWritable, NullWritable> {
//和TopCombiner的代码几乎一致,逻辑上是相同的
int count = 0;
IntWritable outKey = new IntWritable();
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
if (count <= 3) {
outKey.set(key.get());
context.write(outKey, NullWritable.get());
count++;
}
}
}
トップジョブメイン.java
package subExp2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TopJobMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(TopJobMain.class);
job.setMapperClass(TopMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setCombinerClass(TopCombiner.class);
job.setReducerClass(TopReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,args[0]);
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
3. Maven のパッケージ化
必要に応じて、「Hadoop: MapReduce 逆インデックス (コンバイナーとパーティショナーの使用)」にアクセスして表示してください。
4. Hadoop クラスターの実行
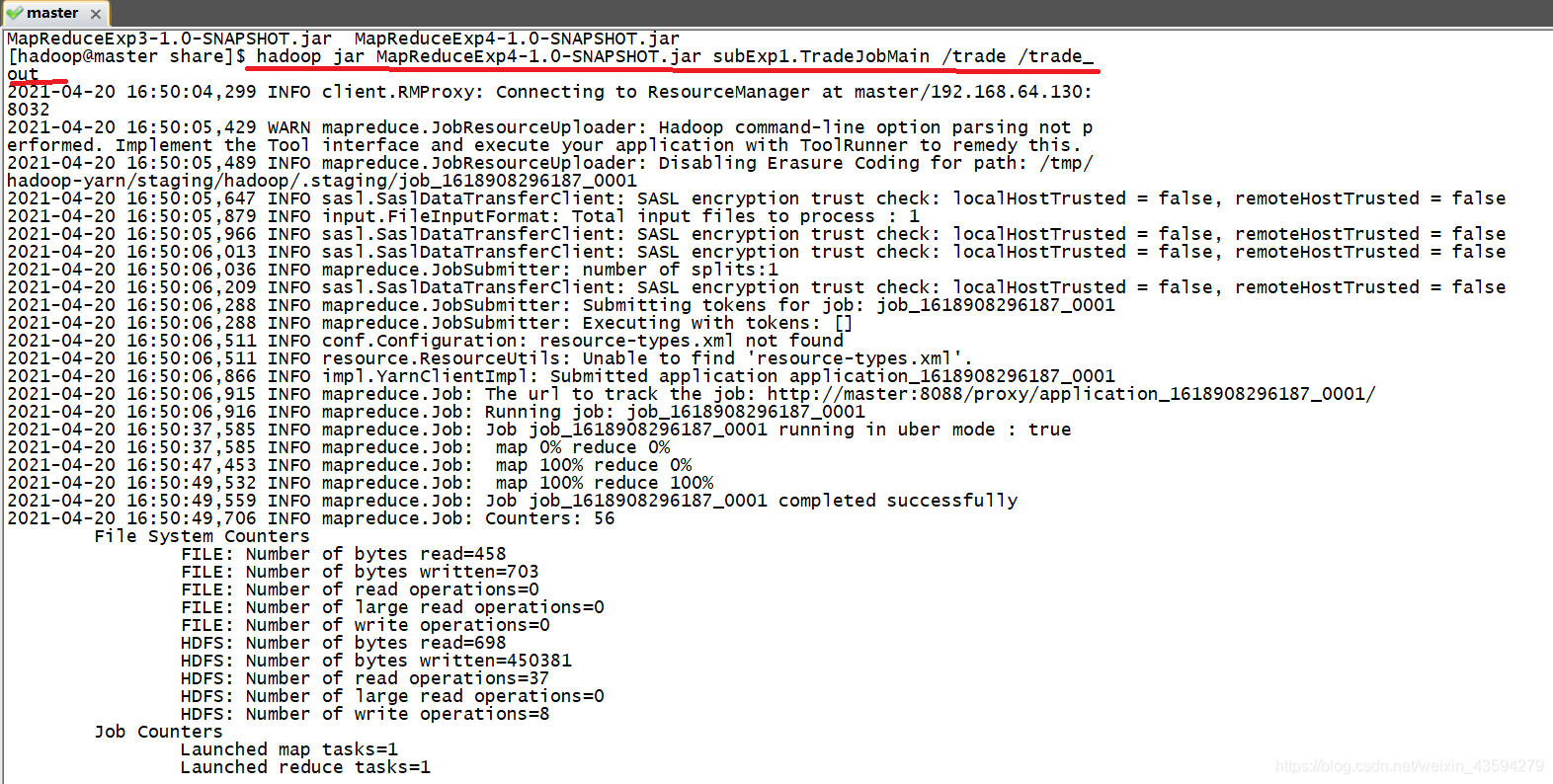
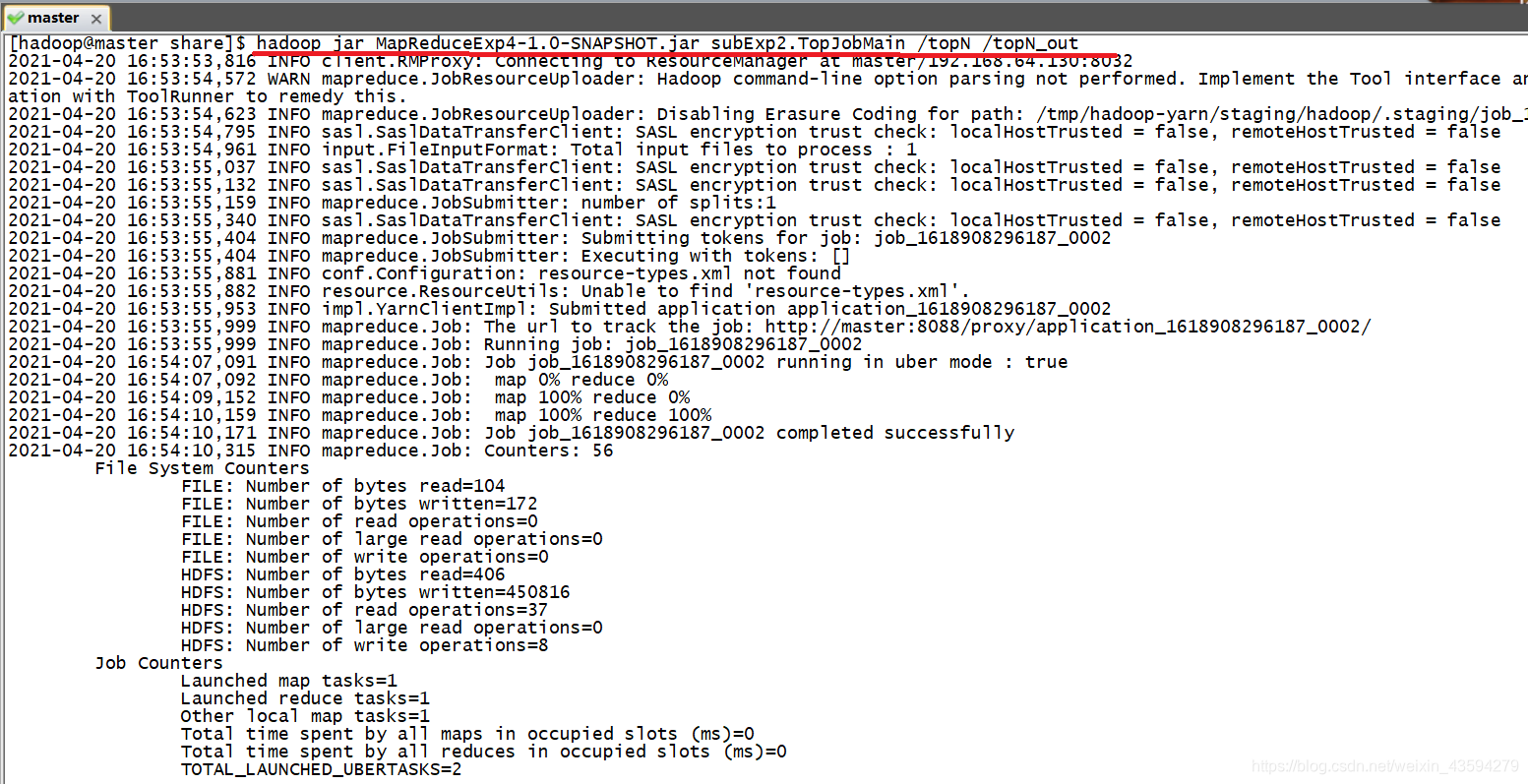
上のファイルの先頭をクリックすると、結果をブラウザで表示できます。
参考サイトと動画
[1] MapReduce は、cleanup() メソッドを使用して並べ替えとフィルタリングを実行し、出力します。
[2] 100w 個のデータ (数値) (各行に 1 つ) を使用し、このファイル内で最大の 3 つの数値を見つけて、より詳細な MapReduce 実装を設計します。効率的
[3] MapReduce 2—— —収支データ処理とカスタムソート
[4] Xiaopo Station ビデオ: MapReduce カスタムソート