
公式ウェブサイト
https://github.com/ben-manes/caffeine
ウィキ:
https://github.com/ben-manes/caffeine/wiki
概要
Caffeine は、Java アプリケーション用の高性能キャッシュ フレームワークです。アプリケーションで使用できる強力で使いやすいキャッシュ ライブラリを提供し、データ アクセスの速度と効率を向上させます。
Caffeine キャッシュ フレームワークの主な機能をいくつか示します。
-
高いパフォーマンス: Caffeine の設計目標の 1 つは、優れたパフォーマンスを提供することです。効率的なデータ構造と最適化されたアルゴリズムを使用することで、高速なキャッシュ アクセスを実現します。他の一般的なキャッシュ フレームワークと比較して、Caffeine はキャッシュ アクセス速度と応答時間の点で優れたパフォーマンスを発揮します。
-
メモリ管理: Caffeine は、柔軟なメモリ管理オプションを提供します。サイズベース、カウントベース、および重みベースのキャッシュ サイズ制限をサポートします。アプリケーションのニーズに応じて適切なキャッシュ サイズ戦略を選択でき、構成パラメータを通じてさらに調整できます。
-
強力な機能: Caffeine は、さまざまなニーズを満たす多くの強力な機能を提供します。キャッシュ項目の非同期読み込みとリフレッシュをサポートし、有効期限とタイミング更新戦略を設定でき、キャッシュ項目の自動削除と手動無効化などをサポートします。さらに、Caffeine はキャッシュのステータスと変更を簡単に監視および管理できる統計情報とリスナー メカニズムも提供します。
-
スレッド セーフ: Caffeine はスレッド セーフであり、マルチスレッド環境でも安全に使用できます。きめ細かいロック メカニズムを使用して共有リソースを保護し、同時アクセスの正確性と一貫性を確保します。
-
統合の容易さ: Caffeine は、既存のアプリケーションと簡単に統合できるスタンドアロン Java ライブラリです。標準の Java 同時実行ライブラリやその他のサードパーティ ライブラリと互換性があり、さまざまなフレームワークやテクノロジ (Spring、Hibernate など) とシームレスに統合できます。
Caffeine は、高速かつ効率的なメモリ内キャッシュ ソリューションを提供するように設計された高性能 Java キャッシュ フレームワークです。これは Google によって開発され、Guava キャッシュのアップグレード バージョンです。
Caffeine は、高スループット、低遅延のキャッシュ アクセスを提供するように設計されており、さまざまなキャッシュ戦略と機能をサポートしています。以下に、Caffeine フレームワークの主な機能をいくつか示します。
-
高いパフォーマンス: Caffeine の設計はキャッシュのメモリ アクセス モードを最適化し、さまざまな技術を使用してキャッシュ アクセスのオーバーヘッドを削減することでパフォーマンスを向上させます。Java ConcurrentHashMap に似たデータ構造を使用し、同時アクセスをサポートし、構成可能な同時実行レベルを提供します。
-
メモリ管理: Caffeine は、キャッシュの最大サイズ、エントリの最大数、または最大重みを設定することによってキャッシュのサイズを制御できる、柔軟なメモリ管理オプションを提供します。また、ボリューム、時間、参照などのポリシーに基づいて、期限切れのキャッシュ エントリの自動クリーニングもサポートします。
-
強力なキャッシュ戦略: Caffeine は、アクセス時間、書き込み時間、またはカスタム ルールに基づく有効期限戦略など、さまざまなキャッシュ戦略を提供します。また、最も最近使用されていない (LRU)、最も最近使用されていない (LFU)、固定サイズなどの他のポリシーもサポートしています。
-
非同期ロード: Caffeine は、キャッシュ エントリを非同期にロードする機能をサポートしています。必要なエントリがキャッシュに存在しない場合にロード プロセスを自動的にトリガーし、ロードが完了すると結果をキャッシュに入れることができます。
-
統計と監視: Caffeine は、キャッシュ ヒット率、読み込み時間、キャッシュ サイズ、その他の指標を追跡できる豊富な統計と監視機能を提供します。この情報は、チューニングとパフォーマンス分析に非常に役立ちます。
-
拡張性: Caffeine の設計により、開発者はポリシー、キャッシュ ローダー、リスナーをカスタマイズしてフレームワークの機能を拡張できます。
Caffeine キャッシュ フレームワークの使用は非常に簡単です。次の手順に従って開始できます。
-
Caffeine 依存関係をインポートする: Caffeine 依存関係をプロジェクトに追加します。これは、Maven、Gradle、または JAR ファイルを直接ダウンロードしてインポートできます。
-
キャッシュ インスタンスを作成する: Caffeine のビルダー モードを使用してキャッシュ インスタンスを作成し、キャッシュ パラメーターと戦略を設定できます。
-
データの保存と取得: キャッシュ
putメソッドを使用してデータをキャッシュに保存し、getメソッドを使用してキャッシュからデータを取得します。必要なデータがキャッシュに存在しない場合は、非同期ロードをトリガーするか、カスタム ロード ロジックを提供するかを選択できます。 -
チューニングと構成: アプリケーションのニーズに応じて、キャッシュのパラメーターとポリシーを調整して、最適なパフォーマンスとメモリ管理を実現できます。
つまり、Caffeine は強力で高性能な Java キャッシュ フレームワークであり、さまざまなアプリケーション シナリオ、特に高速アクセス、低遅延、高スループットを必要とするメモリ キャッシュ要件に適しています。
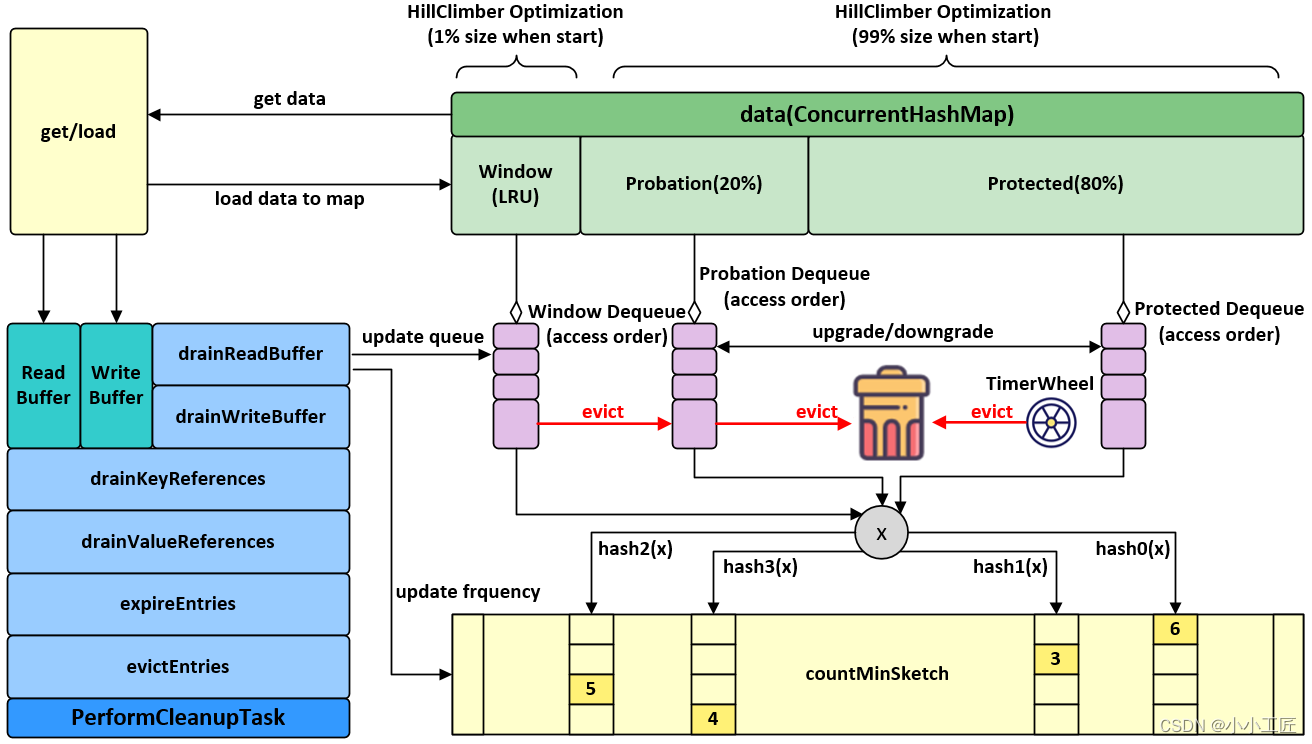
デザイン
コード
POM
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<!-- Java 8 users can continue to use version 2.x, which will be supported -->
<version>2.9.3</version>
</dependency>
Caffeine 3.x バージョンの場合は、JDK 11 以降が必要です。
人口
https://github.com/ben-manes/caffeine/wiki/Population
package com.artisan.caffeinedemo.java;
import com.github.benmanes.caffeine.cache.AsyncLoadingCache;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import lombok.Builder;
import lombok.Data;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import java.util.*;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.TimeUnit;
/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/
@Slf4j
public class CaffeineBaseExampleWithJava {
@SneakyThrows
public static void main(String[] args) {
// initFirstWay();
// initSecondWay();
initThirdWay();
TimeUnit.SECONDS.sleep(10);
}
/**
* Cache手动创建
* <p>
* 最普通的一种缓存,无需指定加载方式,需要手动调用put()进行加载。需要注意的是put()方法对于已存在的key将进行覆盖,这点和Map的表现是一致的。
* 在获取缓存值时,如果想要在缓存值不存在时,原子地将值写入缓存,则可以调用get(key, k -> value)方法,该方法将避免写入竞争。调用invalidate()方法,将手动移除缓存。
* <p>
* 在多线程情况下,当使用get(key, k -> value)时,如果有另一个线程同时调用本方法进行竞争,则后一线程会被阻塞,直到前一线程更新缓存完成;
* 而若另一线程调用getIfPresent()方法,则会立即返回null,不会被阻塞。
*/
@SneakyThrows
public static void initFirstWay() {
Cache<Object, Object> cache = Caffeine.newBuilder()
//初始数量
.initialCapacity(10)
//最大条数
.maximumSize(10)
//expireAfterWrite和expireAfterAccess同时存在时,以expireAfterWrite为准
//最后一次写操作后经过指定时间过期
.expireAfterWrite(3, TimeUnit.SECONDS)
//最后一次读或写操作后经过指定时间过期
.expireAfterAccess(3, TimeUnit.SECONDS)
//监听缓存被移除
.removalListener((key, val, removalCause) -> {
log.info("listener remove : {} ,{} ,{}", key, val, removalCause);
})
//记录命中
.recordStats()
.build();
cache.put("name", "小工匠");
//小工匠
log.info((String) cache.getIfPresent("name"));
// 结合初始化的时候设置的过期时间, 模拟程序运行5秒后,再此获取
TimeUnit.SECONDS.sleep(5);
log.info("5秒后再次获取:{}", (String) cache.getIfPresent("name"));
//存储的是默认值
log.info((String) cache.get("noKey", o -> "默认值"));
}
/**
* Loading Cache自动创建
* <p>
* LoadingCache是一种自动加载的缓存。其和普通缓存不同的地方在于,当缓存不存在/缓存已过期时,若调用get()方法,则会自动调用CacheLoader.load()方法加载最新值。
* 调用getAll()方法将遍历所有的key调用get(),除非实现了CacheLoader.loadAll()方法。
* <p>
* 使用LoadingCache时,需要指定CacheLoader,并实现其中的load()方法供缓存缺失时自动加载。
* <p>
* 在多线程情况下,当两个线程同时调用get(),则后一线程将被阻塞,直至前一线程更新缓存完成。
*/
@SneakyThrows
public static void initSecondWay() {
Map<Integer, Artisan> map = getArtisanMap();
log.info("size:{}", map.size());
LoadingCache<String, String> loadingCache = Caffeine.newBuilder()
//创建缓存或者最近一次更新缓存后经过指定时间间隔,刷新缓存;refreshAfterWrite仅支持LoadingCache
.refreshAfterWrite(10, TimeUnit.SECONDS)
.expireAfterWrite(10, TimeUnit.SECONDS)
.expireAfterAccess(10, TimeUnit.SECONDS)
.maximumSize(10)
//根据key查询数据库里面的值,这里是个lambda表达式
// TODO 根据其概况初始化 ,比如 build(userId -> getUserFromDatabase(userId));
// private User getUserFromDatabase(String userId) {
// // 这里会从数据库查询用户信息
// // ...
// return user;
// }
.build(key -> map.get(Integer.parseInt(key)).toString());
// 当执行get的时候,会触发 build 中的 lambda表达式
log.info(loadingCache.get("1"));
log.info(loadingCache.get("2"));
log.info(loadingCache.get("3"));
log.info(loadingCache.get("4"));
log.info(loadingCache.get("4", o -> "默认值"));
// 获取一个不存在的值
log.info(loadingCache.get("noKey", o -> "默认值"));
}
/**
* AsyncCache是Cache的一个变体,其响应结果均为CompletableFuture,
* 通过这种方式,AsyncCache对异步编程模式进行了适配。
* <p>
* 默认情况下,缓存计算使用ForkJoinPool.commonPool()作为线程池,如果想要指定线程池,则可以覆盖并实现Caffeine.executor(Executor)方法。
* <p>
* synchronous()提供了阻塞直到异步缓存生成完毕的能力,它将以Cache进行返回。
* <p>
* 在多线程情况下,当两个线程同时调用get(key, k -> value),则会返回同一个CompletableFuture对象。由于返回结果本身不进行阻塞,可以根据业务设计自行选择阻塞等待或者非阻塞。
*/
@SneakyThrows
public static void initThirdWay() {
Map<Integer, Artisan> map = getArtisanMap();
log.info("size:{}", map.size());
AsyncLoadingCache<String, String> asyncLoadingCache = Caffeine.newBuilder()
//创建缓存或者最近一次更新缓存后经过指定时间间隔刷新缓存;仅支持LoadingCache
.refreshAfterWrite(1, TimeUnit.SECONDS)
.expireAfterWrite(1, TimeUnit.SECONDS)
.expireAfterAccess(1, TimeUnit.SECONDS)
.maximumSize(10)
//根据key查询数据库里面的值
.buildAsync(key -> {
Thread.sleep(1000);
return map.get(Integer.parseInt(key)).toString();
});
//异步缓存返回的是CompletableFuture
CompletableFuture<String> future = asyncLoadingCache.get("1");
future.thenAccept(System.out::println);
}
private static Map<Integer, Artisan> getArtisanMap() {
Map<Integer, Artisan> map = new HashMap<>(16);
map.put(1, Artisan.builder().id(1).name("artisan1").hobbies(Arrays.asList("Java")).build());
map.put(2, Artisan.builder().id(2).name("artisan2").hobbies(Arrays.asList("AIGC")).build());
map.put(3, Artisan.builder().id(3).name("artisan3").hobbies(Arrays.asList("HADOOP")).build());
map.put(4, Artisan.builder().id(4).name("artisan4").hobbies(Arrays.asList("GO")).build());
return map;
}
@Data
@Builder
private static class Artisan {
private Integer id;
private String name;
private List<String> hobbies;
}
}
expireAfterWriteとexpireAfterAccessが同時に存在する場合、expireAfterWriteが優先されます。
立ち退きポリシー
https://github.com/ben-manes/caffeine/wiki/Eviction
package com.artisan.caffeinedemo.java;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.Scheduler;
import com.github.benmanes.caffeine.cache.Weigher;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import java.util.concurrent.TimeUnit;
/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
* @desc: 驱逐策略在创建缓存的时候进行指定。常用的有基于容量的驱逐和基于时间的驱逐。
* <p>
* 基于容量的驱逐需要指定缓存容量的最大值,当缓存容量达到最大时,Caffeine将使用LRU策略对缓存进行淘汰;基于时间的驱逐策略如字面意思,可以设置在最后访问/写入一个缓存经过指定时间后,自动进行淘汰。
* <p>
* 驱逐策略可以组合使用,任意驱逐策略生效后,该缓存条目即被驱逐。
* <p>
* LRU 最近最少使用,淘汰最长时间没有被使用的页面。
* LFU 最不经常使用,淘汰一段时间内使用次数最少的页面
* FIFO 先进先出
* Caffeine有4种缓存淘汰设置
* <p>
* 大小 (LFU算法进行淘汰)
* 权重 (大小与权重 只能二选一)
* 时间
* 引用
*/
@Slf4j
public class CaffeineEvictionPolicy {
/**
* 缓存大小淘汰
*/
@Test
public void maximumSizeTest() throws InterruptedException {
Cache<Integer, Integer> cache = Caffeine.newBuilder()
//超过10个后会使用W-TinyLFU算法进行淘汰
.maximumSize(10)
.evictionListener((key, val, removalCause) -> {
log.info("淘汰缓存:key:{} val:{}", key, val);
})
.build();
// 模拟写入数据
for (int i = 1; i < 20; i++) {
cache.put(i, i);
}
//缓存淘汰是异步的
Thread.sleep(1000);
// 打印还没被淘汰的缓存
log.info("未淘汰的缓存:{}", cache.asMap());
}
/**
* 权重淘汰
*/
@Test
public void maximumWeightTest() throws InterruptedException {
Cache<Integer, Integer> cache = Caffeine.newBuilder()
//限制总权重,若所有缓存的权重加起来>总权重就会淘汰权重小的缓存
.maximumWeight(100)
.weigher((Weigher<Integer, Integer>) (key, value) -> key)
.evictionListener((key, val, removalCause) -> {
log.info("淘汰缓存:key:{} val:{}", key, val);
})
.build();
//总权重其实是=所有缓存的权重加起来
int maximumWeight = 0;
for (int i = 1; i < 20; i++) {
cache.put(i, i);
maximumWeight += i;
}
log.info("总权重={}", maximumWeight);
//缓存淘汰是异步的
Thread.sleep(1000);
// 打印还没被淘汰的缓存
log.info("未淘汰的缓存:{}", cache.asMap());
}
/**
* 访问后到期(每次访问都会重置时间,也就是说如果一直被访问就不会被淘汰)
*/
@Test
public void expireAfterAccessTest() throws InterruptedException {
Cache<Integer, Integer> cache = Caffeine.newBuilder()
.expireAfterAccess(1, TimeUnit.SECONDS)
//可以指定调度程序来及时删除过期缓存项,而不是等待Caffeine触发定期维护
//若不设置scheduler,则缓存会在下一次调用get的时候才会被动删除
.scheduler(Scheduler.systemScheduler())
.evictionListener((key, val, removalCause) -> {
log.info("淘汰缓存:key:{} val:{}", key, val);
})
.build();
cache.put(1, 2);
log.info("{}", cache.getIfPresent(1));
Thread.sleep(5000);
//null
log.info("{}", cache.getIfPresent(1));
Thread.sleep(500);
}
/**
* 写入后到期
*/
@Test
public void expireAfterWriteTest() throws InterruptedException {
Cache<Integer, Integer> cache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.SECONDS)
//可以指定调度程序来及时删除过期缓存项,而不是等待Caffeine触发定期维护
//若不设置scheduler,则缓存会在下一次调用get的时候才会被动删除
.scheduler(Scheduler.systemScheduler())
.evictionListener((key, val, removalCause) -> {
log.info("淘汰缓存:key:{} val:{}", key, val);
})
.build();
cache.put(1, 2);
Thread.sleep(3000);
//null
log.info("{}", cache.getIfPresent(1));
}
}
リフレッシュ
https://github.com/ben-manes/caffeine/wiki/Refresh
package com.artisan.caffeinedemo.java;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import java.util.concurrent.TimeUnit;
/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
* <p>
* <p>
* refreshAfterWrite()表示x秒后自动刷新缓存的策略可以配合淘汰策略使用,
* <p>
* 注意的是刷新机制只支持LoadingCache和AsyncLoadingCache
*/
@Slf4j
public class CaffeineRefreshPolicy {
private static int NUM = 0;
@Test
public void refreshAfterWriteTest() throws InterruptedException {
LoadingCache<Integer, Integer> cache = Caffeine.newBuilder()
.refreshAfterWrite(1, TimeUnit.SECONDS)
//模拟获取数据,每次获取就自增1
.build(integer -> ++NUM);
//获取ID=1的值,由于缓存里还没有,所以会自动放入缓存
// 返回结果 1
log.info("get value = {}", cache.get(1));
// 延迟2秒后,理论上自动刷新缓存后取到的值是2
// 但其实不是,值还是1,因为refreshAfterWrite并不是设置了n秒后重新获取就会自动刷新
// 而是x秒后&&第二次调用getIfPresent的时候才会被动刷新
Thread.sleep(2000);
// 返回结果 1
log.info("get value = {}", cache.getIfPresent(1));
//此时才会刷新缓存,而第一次拿到的还是旧值 ,这时候拿到的就是新的值了 2
// 返回结果2
log.info("get value = {}", cache.getIfPresent(1));
}
}
統計
https://github.com/ben-manes/caffeine/wiki/Statistics
package com.artisan.caffeinedemo.java;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import java.util.Date;
import java.util.concurrent.TimeUnit;
/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/
@Slf4j
public class CaffeineStatstic {
@Test
public void testStatistic() {
LoadingCache<String, String> cache = Caffeine.newBuilder()
//创建缓存或者最近一次更新缓存后经过指定时间间隔,刷新缓存;refreshAfterWrite仅支持LoadingCache
.refreshAfterWrite(1, TimeUnit.SECONDS)
.expireAfterWrite(1, TimeUnit.SECONDS)
.expireAfterAccess(1, TimeUnit.SECONDS)
.maximumSize(10)
//开启记录缓存命中率等信息
.recordStats()
//根据key查询数据库里面的值
.build(key -> {
Thread.sleep(1000);
return new Date().toString();
});
cache.put("1", "shawn");
cache.get("1");
/*
* hitCount :命中的次数
* missCount:未命中次数
* requestCount:请求次数
* hitRate:命中率
* missRate:丢失率
* loadSuccessCount:成功加载新值的次数
* loadExceptionCount:失败加载新值的次数
* totalLoadCount:总条数
* loadExceptionRate:失败加载新值的比率
* totalLoadTime:全部加载时间
* evictionCount:丢失的条数
*/
log.info("统计信息如下:\n {}", cache.stats());
}
}
