どのブログでも、どのモットーでも、人は自分が思っている以上のことができる。
https://blog.csdn.net/weixin_39190382?type=blog
0. 序文
DBSCAN、OPTICS クラスタリングを補完
1.本文
1.0 DBSCAN の問題
以前に、密度に従ってクラスタリングできるDBSCANを紹介しました。
しかし、次のような問題があります。
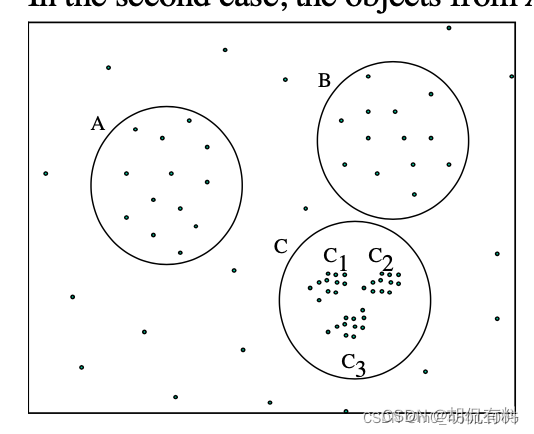
- epsが大きい場合、A、B、Cが分割されます
- epsが小さい場合、C1、C2、C3が分割され(A、Bはノイズとみなされます)、
A、B、C、C1、C2、C3は取得されません
異なるクラスターの密度は異なる場合があります。2 つの DBSCAN は固定の eps を設定し、それらの一部を無視します。
1.1 基本概念
核心点: DBSCAN を参照
コア距離: 点 p をコア点にする最小距離。
例: 近傍の半径は eps=2、サンプルの最小数は min_samples= 5、
点 p です。半径 eps=2 の場合、サンプル点は 8 つあります。すると p が中心点になります。
点 pに最も近い 5 番目の点は、その中心点 p からの距離が 0.8 であるため、点 p の中心距離は 0.8 です。
注: min_samples を計算する場合、コア ポイント自体が含まれるため、上記では近傍 eps で 7 つのポイントを見つけるだけで済み、p がコア ポイントになります。
到達可能距離:点 pからコア点o までの到達可能距離は、 p と o の間の距離と o の中心距離の間の最大値です。( LOFアルゴリズムの到達可能距離と同様に参照できます)
人間の言葉で言えば、点はドメインの半径内にも半径外にもあります。
例1:
- 点 p は、コア点 o1 のコア距離の外側にあるため、到達可能距離reach-dist=d(p,o1)
- ポイント p はコア ポイント 02 のコア距離内にあるため、到達可能距離reach-dist = d_5(o2)

例2:
点 1、2、3 はコア距離内にあるため、それらからコア点までの到達可能な距離 = コア距離

1.2 アルゴリズム処理
一般的に言えば、オフラインでの発展は依然として日常的なことであり、オフラインでの関係の親密さには1つだけ違いがあります。
- 2 つのキューを定義する
- コアポイントと密度ダイレクトポイント(コアポイントの近傍のポイント)を格納し、到達可能な距離の短い順に並べた順序付けされたキュー、処理対象のサンプル
- 結果キュー、サンプルポイント出力の保存、処理されたサンプル
- 未処理のコアポイントを選択して結果キューに入れ、近傍のサンプルの到達可能距離を計算し、到達可能距離の昇順で順序付きキューに入れます。
- 順序付きキューから最初のサンプルを抽出します。コア ポイントの到達可能距離が計算された場合は、到達可能な距離が最も小さいものを結果キューに入れます。コア ポイントでない場合は、このポイントをスキップし、新しいコア ポイントを選択します。 、ステップ 2 を繰り返します
- すべてのサンプル ポイントが処理されるまでステップ 2 と 3 を繰り返し、サンプルと到達可能な距離を結果キューに出力します。
1.3 結果
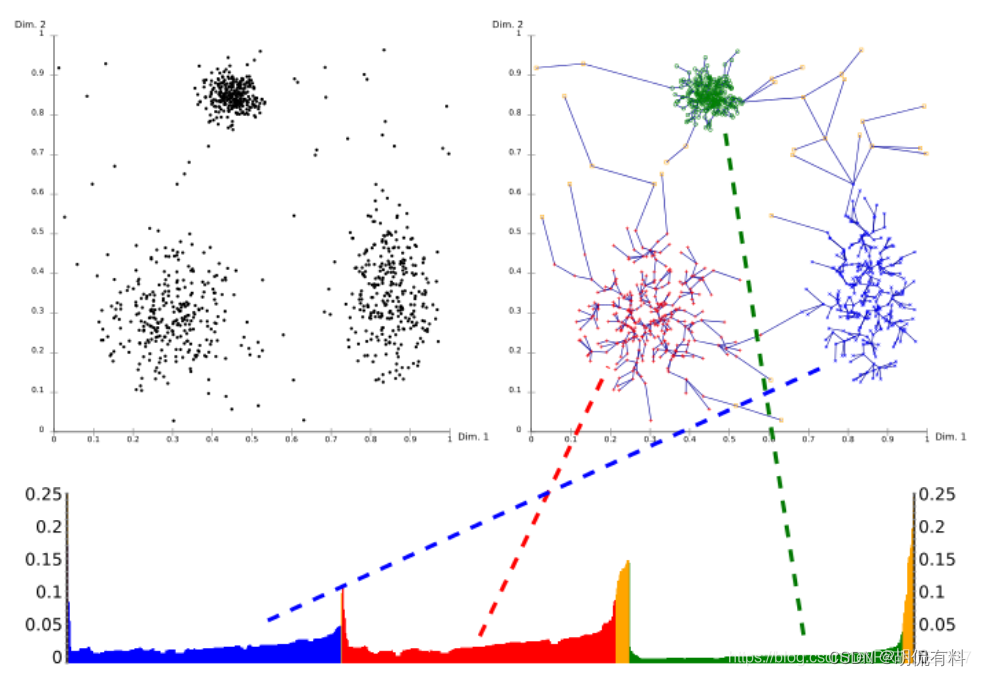
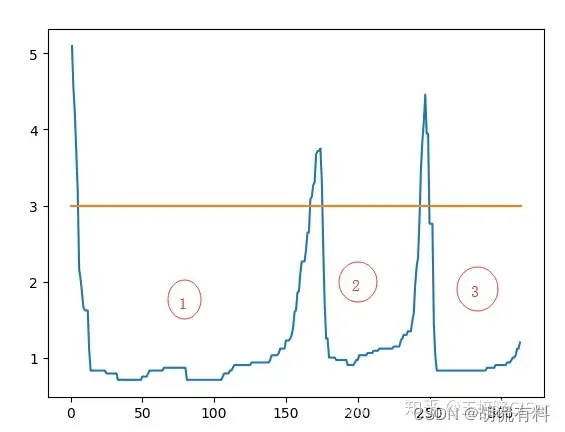
出力は到達可能な距離とサンプル点の順序です。
- クラスターはグラフ内で谷として表示されます。谷が深いほど、クラスターの密度は高くなります。
- 黄色はノイズを表し、谷を形成しません

1.4 概要
OPTICS アルゴリズムは、到達可能な距離に従って各クラスター内のポイントを並べ替え、特定のパラメーターの下で出力します。サンプル ポイントの到達可能な距離を計算するプロセスでは、コア ポイントから開始して、その ϵ \ イプシロンを見つけます。ϵ内のすべての点および中心点を中心としたこれらの点の中心距離を順番に計算し、それらのϵ \epsilon がϵフィールド点コア点が、新しいϵ \epsilonϵフィールド内のすべてのサンプル ポイント、および新しいコア ポイントに関してこれらのサンプル ポイントの到達可能な距離を計算し、それらを並べ替えます。これらが新しいϵ \epsilonϵ領域内の特定のサンプル点は、ϵ \epsilonϵがすでにフィールド内に存在する場合、サンプル点の到達可能距離は、2 つのコア点に対するサンプル点の到達可能距離のうち小さい方として定義されます。など、クラスター内で到達可能な距離が増加する順列を。最初のクラスターの中心点のϵ \epsilonϵフィールドにコア ポイントがなくなった場合は、この時点でクラスターの境界に到達したことを示します。次に、別のクラスターの始まりを示す次のコア ポイントを選択します。これにより、OPTICS 出力結果の曲線で、最高点に達した後、急速に低い点に下降する傾向が見られます。これは、別の密集していることを示します。クラスタの始まりは最初のクラスタの処理フローと同じであり、各クラスタの処理後に出力曲線が得られます。
参考
[1] https://zhuanlan.zhihu.com/p/408243818
[2] https://zhuanlan.zhihu.com/p/77052675
[3] https://blog.csdn.net/haveanybody/article/details /113782209
[4] https://zhuanlan.zhihu.com/p/395088759
[5] https://blog.csdn.net/PRINCE2327/article/details/110412944
[6] https://blog.csdn.net /markaustralia/article/details/120155061
[7] https://blog.csdn.net/m0_45411005/article/details/123251733#t1