目次
Unet++:《UNet++: 医用画像セグメンテーションのための入れ子になった U-Net アーキテクチャ》
著者の Unet と Unet++ の理解: U-Net の研究
前回の記事の続き:セマンティックセグメンテーションシリーズ2 - Unet(pytorch実装)
この記事では、Unet++ ネットワークを紹介し、pytorch フレームワーク上で Unet++ を再現し、Camvid データセット上でトレーニングします。
Unet++ ネットワーク
密なつながり
Unet++ は Unet の構造を継承すると同時に、DenseNet の高密度接続方式 (図 1 のさまざまなブランチ) を利用します。
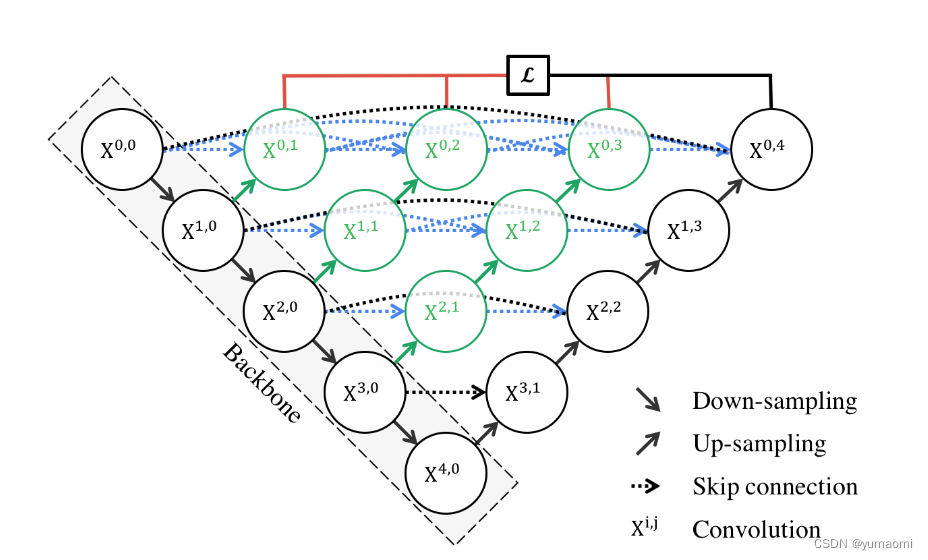
作者は、Dense と同様に、レイヤー間の密な接続を通じて相互に接続し、各モジュールが相互に作用し、各モジュールが互いを見ることができ、ペアがお互いに精通しており、セグメンテーション効果が自然に良くなります。
実際のセグメンテーションでは、ダウンサンプリングを行うと当然細かい特徴が失われますが、Unet ではスキップ接続を使用してこれらの詳細を復元しますが、これを改善できるでしょうか? この高密度接続方式では、各層が可能な限り多くの詳細情報とグローバル情報を保存し、層間にブリッジを構築して相互に通信し、最終的に最後の層と共有してグローバル情報を実現します。そして地域情報の再構築。
深い監督
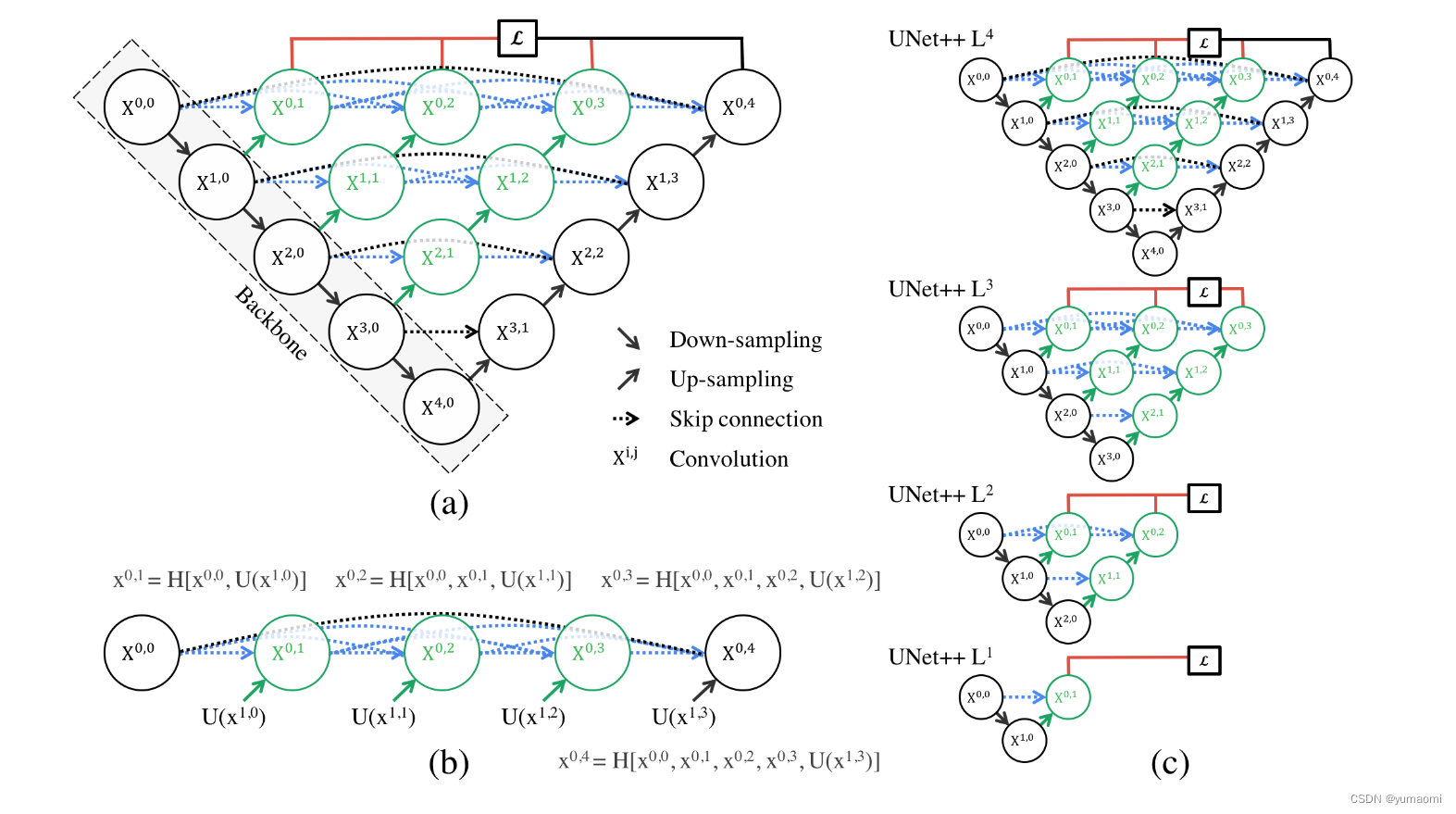
もちろん、さまざまなモジュールを接続するだけでも良い結果が得られます。そして、Unet++ は実際には、深さの異なる多くの Unet++ を重ね合わせたものであることがわかります。それでは、Unet++ の各深度で損失が出力される可能性があるでしょうか? 答えはもちろん「はい」です。
そこで著者は、各深いUnet++の出力を監視し、特定の方法(重み付け法など)でLossを重畳することで、1、2、3、4層のUnet++が得られるようにする深層監視を提案しました。 . 重み付けされた損失(図 2 異なる深さの Unet++ の融合)。
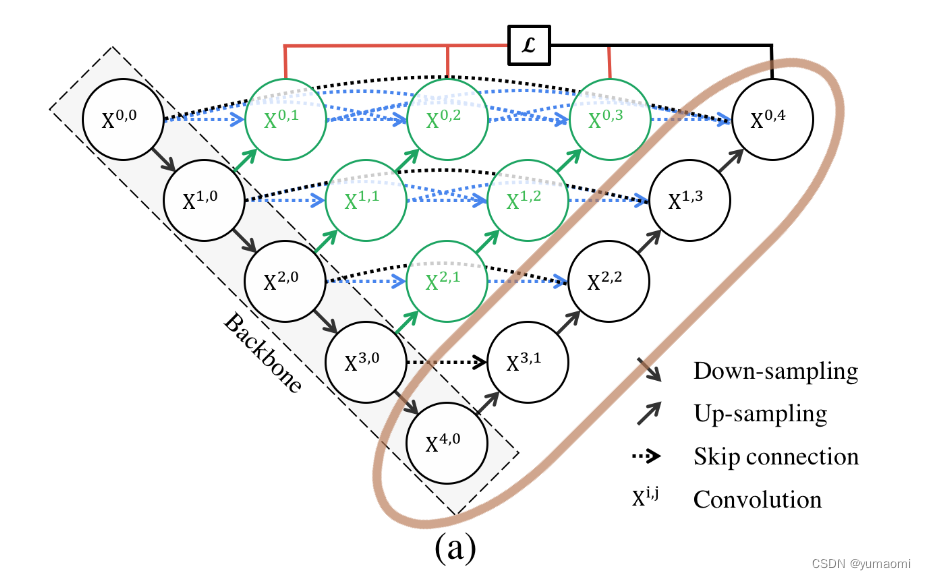
それでは、深い監視は何に役立つのでしょうか? -剪定
Unet++ は深さの異なる複数の Unet++ を重ね合わせているため、層を任意に削除しても順伝播の勾配は変わりませんが、Unet++ の 3 番目の出力は 4 番目の出力と似ており、深さのある Unet++ であることがわかります。 4つのレイヤーのうち、迷わず削除できます。たとえば、図 3 の茶色の部分を直接削除することで枝刈りを実現できます。このようにして、より軽量なネットワークが得られます。
モデルの再現
ドリームズ++
より直観的にするために、コード内のすべてのシンボルをネットワーク構造にマッピングしました。
import torch
import torch.nn as nn
class ContinusParalleConv(nn.Module):
# 一个连续的卷积模块,包含BatchNorm 在前 和 在后 两种模式
def __init__(self, in_channels, out_channels, pre_Batch_Norm = True):
super(ContinusParalleConv, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
if pre_Batch_Norm:
self.Conv_forward = nn.Sequential(
nn.BatchNorm2d(self.in_channels),
nn.ReLU(),
nn.Conv2d(self.in_channels, self.out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(self.out_channels, self.out_channels, 3, padding=1))
else:
self.Conv_forward = nn.Sequential(
nn.Conv2d(self.in_channels, self.out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(self.out_channels, self.out_channels, 3, padding=1),
nn.BatchNorm2d(self.out_channels),
nn.ReLU())
def forward(self, x):
x = self.Conv_forward(x)
return x
class UnetPlusPlus(nn.Module):
def __init__(self, num_classes, deep_supervision=False):
super(UnetPlusPlus, self).__init__()
self.num_classes = num_classes
self.deep_supervision = deep_supervision
self.filters = [64, 128, 256, 512, 1024]
self.CONV3_1 = ContinusParalleConv(512*2, 512, pre_Batch_Norm = True)
self.CONV2_2 = ContinusParalleConv(256*3, 256, pre_Batch_Norm = True)
self.CONV2_1 = ContinusParalleConv(256*2, 256, pre_Batch_Norm = True)
self.CONV1_1 = ContinusParalleConv(128*2, 128, pre_Batch_Norm = True)
self.CONV1_2 = ContinusParalleConv(128*3, 128, pre_Batch_Norm = True)
self.CONV1_3 = ContinusParalleConv(128*4, 128, pre_Batch_Norm = True)
self.CONV0_1 = ContinusParalleConv(64*2, 64, pre_Batch_Norm = True)
self.CONV0_2 = ContinusParalleConv(64*3, 64, pre_Batch_Norm = True)
self.CONV0_3 = ContinusParalleConv(64*4, 64, pre_Batch_Norm = True)
self.CONV0_4 = ContinusParalleConv(64*5, 64, pre_Batch_Norm = True)
self.stage_0 = ContinusParalleConv(3, 64, pre_Batch_Norm = False)
self.stage_1 = ContinusParalleConv(64, 128, pre_Batch_Norm = False)
self.stage_2 = ContinusParalleConv(128, 256, pre_Batch_Norm = False)
self.stage_3 = ContinusParalleConv(256, 512, pre_Batch_Norm = False)
self.stage_4 = ContinusParalleConv(512, 1024, pre_Batch_Norm = False)
self.pool = nn.MaxPool2d(2)
self.upsample_3_1 = nn.ConvTranspose2d(in_channels=1024, out_channels=512, kernel_size=4, stride=2, padding=1)
self.upsample_2_1 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=4, stride=2, padding=1)
self.upsample_2_2 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=4, stride=2, padding=1)
self.upsample_1_1 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=4, stride=2, padding=1)
self.upsample_1_2 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=4, stride=2, padding=1)
self.upsample_1_3 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=4, stride=2, padding=1)
self.upsample_0_1 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=4, stride=2, padding=1)
self.upsample_0_2 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=4, stride=2, padding=1)
self.upsample_0_3 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=4, stride=2, padding=1)
self.upsample_0_4 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=4, stride=2, padding=1)
# 分割头
self.final_super_0_1 = nn.Sequential(
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, self.num_classes, 3, padding=1),
)
self.final_super_0_2 = nn.Sequential(
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, self.num_classes, 3, padding=1),
)
self.final_super_0_3 = nn.Sequential(
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, self.num_classes, 3, padding=1),
)
self.final_super_0_4 = nn.Sequential(
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, self.num_classes, 3, padding=1),
)
def forward(self, x):
x_0_0 = self.stage_0(x)
x_1_0 = self.stage_1(self.pool(x_0_0))
x_2_0 = self.stage_2(self.pool(x_1_0))
x_3_0 = self.stage_3(self.pool(x_2_0))
x_4_0 = self.stage_4(self.pool(x_3_0))
x_0_1 = torch.cat([self.upsample_0_1(x_1_0) , x_0_0], 1)
x_0_1 = self.CONV0_1(x_0_1)
x_1_1 = torch.cat([self.upsample_1_1(x_2_0), x_1_0], 1)
x_1_1 = self.CONV1_1(x_1_1)
x_2_1 = torch.cat([self.upsample_2_1(x_3_0), x_2_0], 1)
x_2_1 = self.CONV2_1(x_2_1)
x_3_1 = torch.cat([self.upsample_3_1(x_4_0), x_3_0], 1)
x_3_1 = self.CONV3_1(x_3_1)
x_2_2 = torch.cat([self.upsample_2_2(x_3_1), x_2_0, x_2_1], 1)
x_2_2 = self.CONV2_2(x_2_2)
x_1_2 = torch.cat([self.upsample_1_2(x_2_1), x_1_0, x_1_1], 1)
x_1_2 = self.CONV1_2(x_1_2)
x_1_3 = torch.cat([self.upsample_1_3(x_2_2), x_1_0, x_1_1, x_1_2], 1)
x_1_3 = self.CONV1_3(x_1_3)
x_0_2 = torch.cat([self.upsample_0_2(x_1_1), x_0_0, x_0_1], 1)
x_0_2 = self.CONV0_2(x_0_2)
x_0_3 = torch.cat([self.upsample_0_3(x_1_2), x_0_0, x_0_1, x_0_2], 1)
x_0_3 = self.CONV0_3(x_0_3)
x_0_4 = torch.cat([self.upsample_0_4(x_1_3), x_0_0, x_0_1, x_0_2, x_0_3], 1)
x_0_4 = self.CONV0_4(x_0_4)
if self.deep_supervision:
out_put1 = self.final_super_0_1(x_0_1)
out_put2 = self.final_super_0_2(x_0_2)
out_put3 = self.final_super_0_3(x_0_3)
out_put4 = self.final_super_0_4(x_0_4)
return [out_put1, out_put2, out_put3, out_put4]
else:
return self.final_super_0_4(x_0_4)
if __name__ == "__main__":
print("deep_supervision: False")
deep_supervision = False
device = torch.device('cpu')
inputs = torch.randn((1, 3, 224, 224)).to(device)
model = UnetPlusPlus(num_classes=3, deep_supervision=deep_supervision).to(device)
outputs = model(inputs)
print(outputs.shape)
print("deep_supervision: True")
deep_supervision = True
model = UnetPlusPlus(num_classes=3, deep_supervision=deep_supervision).to(device)
outputs = model(inputs)
for out in outputs:
print(out.shape)
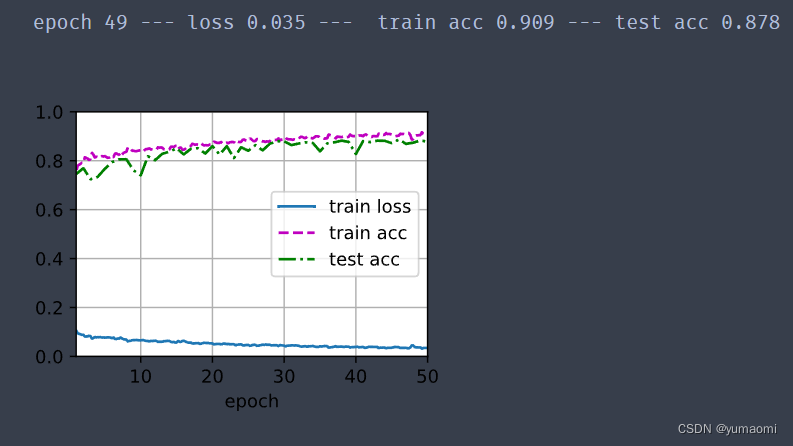
テスト結果は次のとおりです

データセットの準備
データセットは Camvid データセットを使用しており、構築方法はCamVid データセット-pytorch の作成と使用で参照できます。
# 导入库
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch import optim
from torch.utils.data import Dataset, DataLoader, random_split
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
import os.path as osp
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
torch.manual_seed(17)
# 自定义数据集CamVidDataset
class CamVidDataset(torch.utils.data.Dataset):
"""CamVid Dataset. Read images, apply augmentation and preprocessing transformations.
Args:
images_dir (str): path to images folder
masks_dir (str): path to segmentation masks folder
class_values (list): values of classes to extract from segmentation mask
augmentation (albumentations.Compose): data transfromation pipeline
(e.g. flip, scale, etc.)
preprocessing (albumentations.Compose): data preprocessing
(e.g. noralization, shape manipulation, etc.)
"""
def __init__(self, images_dir, masks_dir):
self.transform = A.Compose([
A.Resize(224, 224),
A.HorizontalFlip(),
A.VerticalFlip(),
A.Normalize(),
ToTensorV2(),
])
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
def __getitem__(self, i):
# read data
image = np.array(Image.open(self.images_fps[i]).convert('RGB'))
mask = np.array( Image.open(self.masks_fps[i]).convert('RGB'))
image = self.transform(image=image,mask=mask)
return image['image'], image['mask'][:,:,0]
def __len__(self):
return len(self.ids)
# 设置数据集路径
DATA_DIR = r'dataset\camvid' # 根据自己的路径来设置
x_train_dir = os.path.join(DATA_DIR, 'train_images')
y_train_dir = os.path.join(DATA_DIR, 'train_labels')
x_valid_dir = os.path.join(DATA_DIR, 'valid_images')
y_valid_dir = os.path.join(DATA_DIR, 'valid_labels')
train_dataset = CamVidDataset(
x_train_dir,
y_train_dir,
)
val_dataset = CamVidDataset(
x_valid_dir,
y_valid_dir,
)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True,drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=True,drop_last=True)モデルトレーニング
model = UnetPlusPlus(num_classes=33).cuda()
#载入预训练模型
#model.load_state_dict(torch.load(r"checkpoints/Unet++_25.pth"),strict=False)from d2l import torch as d2l
from tqdm import tqdm
import pandas as pd
#损失函数选用多分类交叉熵损失函数
lossf = nn.CrossEntropyLoss(ignore_index=255)
#选用adam优化器来训练
optimizer = optim.SGD(model.parameters(),lr=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1, last_epoch=-1)
#训练50轮
epochs_num = 50
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,scheduler,
devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
loss_list = []
train_acc_list = []
test_acc_list = []
epochs_list = []
time_list = []
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(
net, features, labels.long(), loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
scheduler.step()
print(f"epoch {epoch+1} --- loss {metric[0] / metric[2]:.3f} --- train acc {metric[1] / metric[3]:.3f} --- test acc {test_acc:.3f} --- cost time {timer.sum()}")
#---------保存训练数据---------------
df = pd.DataFrame()
loss_list.append(metric[0] / metric[2])
train_acc_list.append(metric[1] / metric[3])
test_acc_list.append(test_acc)
epochs_list.append(epoch)
time_list.append(timer.sum())
df['epoch'] = epochs_list
df['loss'] = loss_list
df['train_acc'] = train_acc_list
df['test_acc'] = test_acc_list
df['time'] = time_list
df.to_excel("savefile/Unet++_camvid1.xlsx")
#----------------保存模型-------------------
if np.mod(epoch+1, 5) == 0:
torch.save(model.state_dict(), f'checkpoints/Unet++_{epoch+1}.pth')
トレーニングを開始する
train_ch13(model, train_loader, val_loader, lossf, optimizer, epochs_num,scheduler)トレーニングの結果