論文のタイトル:リアルタイム物体検出で DETR が YOLO に勝つ
論文アドレス: https://arxiv.org/abs/2304.08069
ペーパーコード:ミラー / facebookresearch / ConvNeXt · GitCode
YOLOに勝つのは卒業するまで待ってください。YOLOには勝てません。大学院生の大半は反対です
1. 概要
最近、エンドツーエンドのトランスベース検出器 (DETR) が目覚ましいパフォーマンスを達成しました。しかし、DETR の高い計算コストは効果的に対処されておらず、実際の応用が制限され、非最大値抑制 (NMS) などの後処理がない利点を十分に活用できません。この論文ではまず、最新のリアルタイム物体検出器における推論速度に対する NMS の影響を分析し、エンドツーエンドの速度ベンチマークを確立します。NMS によって引き起こされる推論遅延を回避するために、私たちの知る限り初のリアルタイム エンドツーエンド オブジェクト検出器である Real-Time DEtection TRanformer (RT-DETR) を提案します。具体的には、スケール内の相互作用とスケール間の融合を分離することでマルチスケール機能を効率的に処理する効率的なハイブリッド エンコーダーを設計し、オブジェクト クエリの初期化を改善するための IoU を認識したクエリ選択を提案します。さらに、私たちが提案する検出器は、再学習せずに異なるデコーダ層を使用することで推論速度の柔軟な調整をサポートしており、リアルタイム物体検出器の実用化が容易になります。当社の RT-DETR-L は COCO val2017 の T4 GPU で 53.0% の AP と 114 FPS を達成し、RT-DETR-X は 54.8% の AP と 74 FPS を達成し、速度と精度の両方で優れています。すべての YOLO 検出器は同じスケールです。さらに、当社の RT-DETR-R50 は、DINO-Deformable-DETR-R50 と比較して精度で 2.2% の AP 向上、FPS で約 21 倍の向上を達成しています。
2. 主な貢献
この文書の主な貢献は次のように要約されます。
(1) 精度と速度の点で現在の最先端のリアルタイム検出器を上回るだけでなく、後処理を必要としない、初のリアルタイム エンドツーエンド物体検出器を提案します。推論速度が遅延せず、安定化を維持します。
(2) NMS がリアルタイム検出器に及ぼす影響を詳細に分析し、後処理の観点から CNN ベースのリアルタイム検出器に関する結論を導き出します。
(3) 私たちが提案した IoU を意識したクエリ選択は、モデルで優れたパフォーマンスの向上を示し、ターゲット クエリの初期化スキームを改善するための新しいアイデアを提供します。
(4) 私たちの研究は、エンドツーエンド検出器のリアルタイム実装のための実現可能なソリューションを提供し、提案された検出器は、再トレーニングすることなく、異なるデコーダ層を使用することでモデルのサイズと推論速度を柔軟に調整できます。
3. 関連作品
3.1 リアルタイム物体検出器
長年にわたる継続的な開発を経て、YOLO シリーズはリアルタイム物体検出器の代名詞となりました。これは、アンカーベースとアンカーフリーの 2 つのカテゴリに大別できます。これらの検出器の性能から判断すると、アンカー ポイントはもはや YOLO の開発を制限する主な要因ではありません。ただし、上記の検出器は多数の冗長な境界ボックスを生成するため、後処理段階で NMS によってフィルタリングする必要があります。残念ながら、これはパフォーマンスのボトルネックにつながり、NMS のハイパーパラメータは検出器の精度と速度に大きな影響を与えます。これはリアルタイム物体検出器の設計理念と相容れないと考えています。
3.2 エンドツーエンドのオブジェクト検出器
エンドツーエンドのオブジェクト検出器は、簡素化されたパイプラインで有名です。DETR は、従来の検出パイプラインで手動で設計されたアンカーおよび NMS コンポーネントを排除します。代わりに、2 部グラフ マッチングを採用し、1 対 1 のオブジェクト セットを直接予測します。この戦略を採用することで、DETR は検出プロセスを簡素化し、NMS によって引き起こされるパフォーマンスのボトルネックを軽減します。DETR には明らかな利点があるにもかかわらず、トレーニングの収束が遅いこととクエリの最適化が難しいという 2 つの大きな問題があります。これらの問題に対処するために、多くの DETR バリアントが提案されています。具体的には、Deformable-DETR は、アテンション メカニズムの効率を高めることで、マルチスケール フィーチャのトレーニング コンバージェンスを加速します。条件付き DETR とアンカー DETR は、クエリ最適化の困難さを軽減します。DAB-DETR は 4D 参照ポイントを導入し、予測ボックスをレイヤーごとに繰り返し最適化します。DN-DETR はクエリのノイズ除去を導入することでトレーニングの収束を高速化します。DINO は以前の研究を改良し、最先端の結果を達成します。私たちは DETR のコンポーネントを継続的に改善していますが、目標はモデルのパフォーマンスをさらに向上させるだけでなく、リアルタイムのエンドツーエンドの物体検出器を作成することです。
3.3 物体検出のためのマルチスケール機能
最新の物体検出器は、特に小さな物体のパフォーマンスを向上させるためにマルチスケール機能を活用することの重要性を実証しています。FPN は、隣接するスケールのフィーチャを融合するフィーチャ ピラミッド ネットワークを導入します。その後の研究により、この構造が拡張および強化され、リアルタイムの物体検出器で広く使用されています。変形可能なアテンション メカニズムにより計算コストはある程度軽減されますが、マルチスケール フィーチャの融合は依然として高い計算負荷につながります。この問題を解決するために、いくつかの研究では、計算効率の高い DETR を設計しようとしています。効率的な DETR は、高密度事前確率を使用してオブジェクト クエリを初期化することにより、エンコーダ層とデコーダ層の数を削減します。スパース DETR は、エンコーダ フラグを選択的に更新して、デコーダの計算オーバーヘッドを削減します。Lite DETR は、インターリーブによって低レベル機能の更新頻度を減らし、エンコーダの効率を高めます。これらの研究は DETR の計算コストを削減しましたが、これらの研究の目標は DETR をリアルタイム検出器として一般化することではありません。
4. リアルタイム DETR
4.1 モデルの概要 提案
する RT-DETR は、バックボーン ネットワーク、ハイブリッド エンコーダ、および補助予測ヘッダを備えたトランスフォーマ デコーダで構成されます。モデル アーキテクチャの概要を図に示します。
具体的には:
(1) まず、Backbone の S3、S4、および S5 の最後の 3 ステージの出力機能をエンコーダーの入力として使用します。
(2) 次に、ハイブリッド エンコーダが、スケール内相互作用とスケール間融合 (セクション 4.2 で説明) を介して、マルチスケール特徴を一連の画像特徴に変換します。
(3) その後、デコーダの最初のターゲット クエリとして IoU 認識クエリ選択を使用して、エンコーダ出力シーケンスから固定数の画像特徴が選択されます。
(4) 最後に、補助予測ヘッドを備えたデコーダーがオブジェクト クエリを繰り返し改良して、ボックスと信頼スコアを生成します。
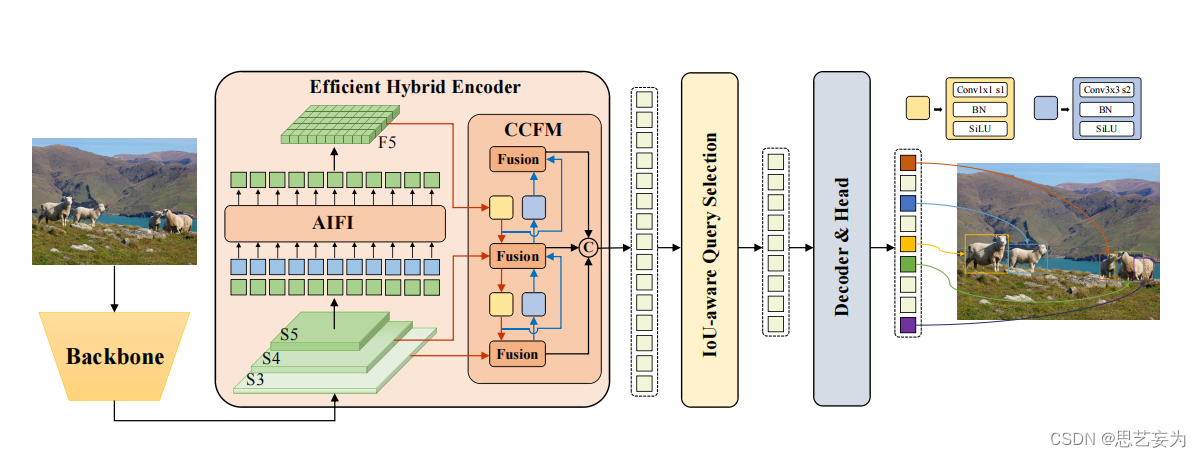
4.2 高効率ハイブリッドエンコーダ
(1) 計算ボトルネック解析。トレーニングの収束を高速化し、パフォーマンスを向上させるために、Zhu et al. [43] は、マルチスケール機能を導入し、計算を削減するための変形可能なアテンション メカニズムを提案しています。ただし、アテンション メカニズムの改善により計算オーバーヘッドは減少しますが、入力シーケンスの長さの急激な増加により依然としてエンコーダーが計算ボトルネックとなり、DETR のリアルタイム実装が妨げられます。[17] で報告されているように、エンコーダは Deformable-DETR [43] の GFLOP の 49% を占めますが、AP には 11% しか寄与しません。この障害を克服するために、マルチスケール変圧器エンコーダに存在する計算の冗長性を分析し、スケール内機能とスケール間機能の同時相互作用が計算的に非効率であることを示す一連のバリアントを設計します。
高レベルの特徴は、画像内のオブジェクトに関する豊富な意味情報を含む低レベルの特徴から抽出されます。直観的には、連結されたマルチスケール フィーチャのフィーチャ相互作用は冗長です。図 5 に示すように、このアイデアをテストするために、著者らはエンコーダの構造を再考し、異なるエンコーダを備えた一連のバリアントを設計しました。
このバリアント グループは、マルチスケール フィーチャの相互作用をスケール内相互作用とスケール間融合の 2 段階の操作に分離することで、計算コストを大幅に削減しながら、モデルの精度を徐々に向上させます。まずベースライン A として DINO-R50 のマルチスケール変換エンコーダーを削除します。次に、次のように、さまざまな形式のエンコーダーが接続され、ベースライン A に基づいて一連のバリアントが生成されます。
• A → B: バリアント B は、トランス ブロックのレイヤーを使用するシングルスケールのトランス エンコーダーを挿入します。各スケールのフィーチャは、スケール間のフィーチャ相互作用のためにエンコーダを共有し、出力されたマルチスケール フィーチャが連結されます。
• B → C: バリアント C は、B に基づいてクロススケール特徴融合を導入し、特徴相互作用のためにカスケードされたマルチスケール特徴をエンコーダーに供給します。
• C → D: バリアント D は、マルチスケール フィーチャのスケール間相互作用とスケール間融合を分離します。まず、シングルスケールのトランスエンコーダがスケール内の相互作用に使用され、次に PANet のような構造がスケール間の融合に使用されます。
• D → E: バリアント E は、D に基づいてスケール内相互作用とマルチスケール機能のスケール間融合をさらに最適化し、当社が設計した効率的なハイブリッド エンコーダーを採用します。

(2) ハイブリッド設計
上記の分析に基づいて、著者らはエンコーダの構造を再考し、新しい効率的なハイブリッドエンコーダを提案します。図3に示すように、提案されたエンコーダは、注意ベースのスケール内特徴相互作用(AIFI)モジュールとニューラルネットワークベースのクロススケール特徴融合モジュール(CCFM)の2つのモジュールで構成されます。AIFI は、S5 上でスケール内インタラクションのみを実行するバリアント D に基づいて計算の冗長性をさらに削減します。著者らは、より豊かなセマンティック概念を持つ高レベルの特徴にセルフアテンション操作を適用すると、画像内の概念的エンティティ間のつながりを捉えることができ、後続のモジュールによる画像内のオブジェクトの検出と認識が容易になると考えています。一方、下位レベルの機能のスケール内相互作用は、セマンティック概念が欠如しており、高レベルの機能との相互作用では重複や混乱が生じるリスクがあるため、不必要です。このアイデアをテストするために、スケール内相互作用はバリアント D の S5 に対してのみ実行されました。実験結果は表 3 に示されています (DS5 行を参照)。バリアント D と比較して、DS5 は遅延を大幅に短縮 (35% 高速) しますが、精度は向上します (AP は 0.4% 高くなります)。この結論は、リアルタイム検出器の設計にとって重要です。
CCFM もバリアント D に基づいて最適化されており、融合パスに畳み込み層で構成されるいくつかの融合ブロックが挿入されます。融合ブロックの役割は、隣接するフィーチャを新しいフィーチャに融合することであり、その構造を図 4 に示します。融合ブロックには N RepBlock が含まれており、2 つのパス出力は要素ごとの加算によって融合されます。

このプロセスは次のように表現できます。
Q= K = V = 平坦化 ( )
= 変形 (Attn (Q,K,V) )
出力 = CCFM ( { } )
このうち、Attn は多頭自己注意を意味し、Reshape はフィーチャの形状を S5 と同じ形状に戻すことを意味し、Faltten の逆演算です。
4.3 IoU を意識したクエリの選択
DETR のオブジェクト クエリは、デコーダによって最適化され、予測ヘッドによって分類スコアと境界ボックスにマッピングされる学習可能な埋め込みベクトルのセットです。DINO のオブジェクト クエリは、分類スコアを使用してエンコーダから上位 K 個の特徴を選択し、オブジェクト クエリを初期化します。ただし、分類スコアと位置信頼度の分布に一貫性がないため、一部の予測ボックスは高い分類スコアを持っていますが、GT ボックスには近くないため、高い分類スコアと低い IoU スコアを持つボックスが選択される一方で、低い分類スコアを持つボックスが選択されます。高い IoU スコアが選択され、ボックスは破棄されます。これにより、検出器の性能が損なわれます。この問題に対処するために、このペーパーでは、トレーニング中に IoU スコアが高い特徴に対しては高い分類スコアを生成し、IoU スコアが低い特徴に対しては低い分類スコアを生成するようにモデルを制約することで、IoU を認識したクエリ選択を提案します。したがって、分類スコアに従ってモデルによって選択された上位 K 個のエンコーダー特徴に対応する予測ボックスは、高い分類スコアと高い IoU スコアを持ちます。このペーパーでは、DETR のバイナリ マッチングを次のように再定式化します。
(
、
) =
(
、
) +
(
、c、IoU)
IoU を意識したクエリ選択により、COCO MAP は大幅に改善されました。ここで、 と は
それぞれ予測値とグランドトゥルース値を示し、c と b はそれぞれカテゴリと境界ボックスを示します。IoU スコアを分類ブランチの目的関数に導入して、陽性サンプルの分類と位置特定に関する一貫性制約を実現します。
具体的には、まず分類スコアに従って上位 K (実験では K = 300) のエンコーダー特徴を選択し、次に分類スコアが 0.5 を超える散布図を視覚化します。赤と青の点は、それぞれ通常のクエリ選択と IoU 対応クエリ選択を使用してトレーニングされたモデルから計算されます。点がプロットの右上隅に近づくほど、対応する特徴の品質が高くなります。つまり、分類ラベルと境界ボックスが画像内の実際のオブジェクトを表す可能性が高くなります。可視化結果によると、最も顕著な特徴は、グラフの右上隅に多数の青い点が集中し、右下隅に赤い点が集中していることです。これは、IoU を認識したクエリ選択でトレーニングされたモデルが、より高品質のエンコーダー機能を生成できることを示しています。
さらに、これら 2 種類の点の分布特性も定量的に分析されます。図には、赤色のポイントよりも青色のポイントが 138% 多く存在します。つまり、分類スコアが 0.5 以下の赤色のポイントが多く、これは低品質の特徴と見なすことができます。次に、分類スコアが 0.5 より大きいフィーチャの IoU スコアを分析し、IoU スコアが 0.5 より大きい場合、青色のポイントが赤色のポイントより 120% 多く存在することがわかります。定量的な結果はさらに、IoU を意識したクエリ選択により、オブジェクト クエリに対して正確な分類 (高い分類スコア) と正確な位置特定 (高い IoU スコア) を備えたより多くのエンコーダ機能を提供できるため、検出器の精度が向上することを示しています。