潜在力を調整する: 潜在拡散モデルを使用した高解像度ビデオ合成
0.ソース
この記事は論文を読んだ後の個人的なメモであり、個人的なレベルに合わせて編集されており、話の順序や内容は原論文とは若干異なりますが、原論文の翻訳ではありません。
すべての詳細を知りたい場合は、arxiv に移動することをお勧めします。
論文アドレス: https://arxiv.org/abs/2304.08818
プロジェクトアドレス: https://research.nvidia.com/labs/toronto-ai/VideoLDM/
1. 全体構成
画像生成の分野における典型的なフレームワーク LDM に基づいて、本稿はそれをビデオ生成の分野に拡張し、低計算コストで圧縮された低次元の潜在空間で高品質の画像を生成するという利点を維持し、最終的にはグローバルに一貫した画像を低コストで生成、高解像度の長時間ビデオ。
モデルの全体的なトレーニング プロセスは次のように表現できます:
a. 画像データ上で LDM を事前トレーニングするか、利用可能な画像 LDM 事前トレーニング モデルを使用します; b
. LDM (潜在空間拡散モデル) に時間層を導入することによって)、固定空間層(空間層)パラメータ、およびビデオ データの微調整により、画像ジェネレータからビデオ ジェネレータへの変換が実現されます。これは 2 つの部分に分かれています。 1.画像の潜在ベクトル ジェネレーターをビデオの潜在ベクトルジェネレーターに変換します。2. ピクセル空間でオートエンコーダーのタイミングを調整します。
c. より長いビデオ生成のための予測モデルに変換します (長期生成)
d. 時間補間を使用して高いフレーム レートを取得します
e. 画像 DM のアップサンプラーを時間調整し、時系列の一貫したビデオ スーパー ビデオに変換します。解像度モデル。(高解像度ビデオを合成する必要がある場合にのみこの項目を選択してください。ビデオ アップサンプラーは計算コストを低く抑えるためにローカルでのみ動作します)
連続した長いビデオを生成するプロセスは、次の図に示されています。
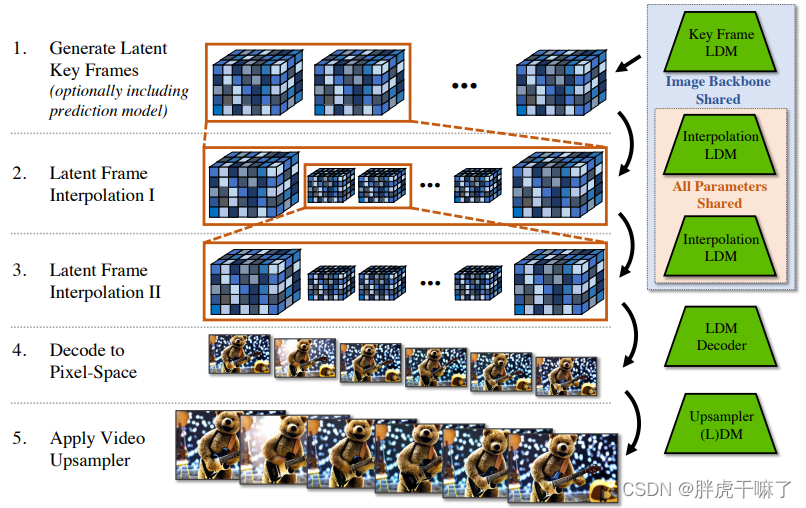
1. まず離散キーフレームを生成します;
2+3. 同じ補間モデルを 2 つのステップで使用してキーフレーム間のタイミング補間を実行し、より高いフレーム レートを実現します (
上記の 3 つのステップは LDM モデルに基づいており、同じイメージを共有します) 4.潜在
ベクトルをピクセル空間にデコードします。
5. (オプション) ビデオ アップサンプリング DM を使用して、より高い解像度を取得します。
このモデルのトレーニング プロセスは、実際には同じ事前トレーニング画像 LDM (および DM アップサンプラー) に対する異なる微調整プロセスです。次の 3 つのステップ a、b、c について順を追って説明します。
2. 具体的な実装
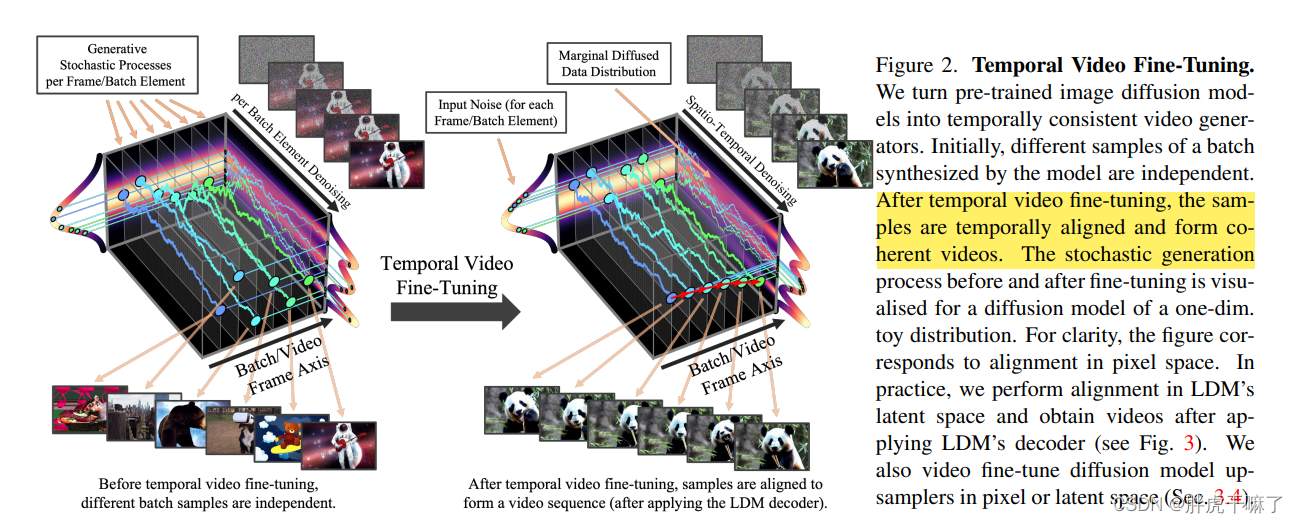
b.1 潜在ベクトル生成器を画像ドメインからビデオドメインに転送する
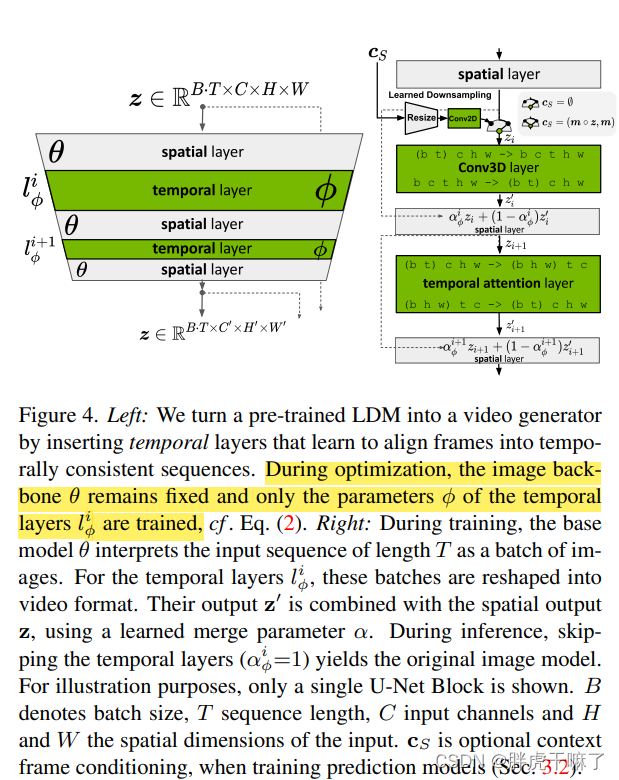
既存の空間LDMは、独立したフレームを高品質に生成できますが、時間の概念がないため、連続した複数のビデオフレームを生成することが困難です。
上図左に示すように、時間層は元の LDM の空間層にインターリーブされており、時間層には 3D 畳み込み層と時間的アテンション層が含まれており、独立したフレームを時系列の一貫した方法で整列させる必要があります。空間レイヤは最適化プロセス中に修正されますが、時間レイヤのみが最適化されます。
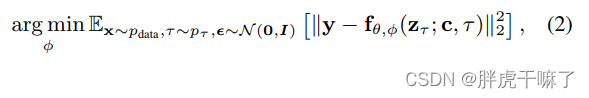
上右図では計算過程を説明するために「空間層+時間層」を取り出していますが、空間層と時間層では(TxCxHxW)映像に対する理解が異なります。空間層には時間次元が組み込まれています。バッチ次元に変換すると、ビデオはバッチ内の無関係な写真の小さなシリーズとみなされ、B*T が新しいバッチ サイズになるため、入力空間層のテンソル形式は (bt) chw となり、時間層は次のように配置されます。時間次元に従ったビデオ全体。つまり、全体として、入力時間層のテンソル形式は bcthw です。テンソルは、時間層を通過する前後で次のように変換する必要があります。
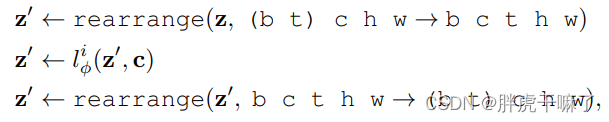
演算の各ステップの後、入力時間層の前後のテンソル z と z' に重みを付ける必要があります。
α ϕ iz + ( 1 − α ϕ i ) z ′ 、ここで α ϕ i ∈ [ 0 , 1 ] \alpha ^i_\phi z + (1-\alpha ^i_\phi)z'、ここで \alpha ^i_ \phi \in [0,1]あるϕ私はz+( 1−あるϕ私は) z「、」ここで、αϕ私は∈[ 0 ,1 ]
c sなど、図内の他の疑わしい点に関しては、予測モデルのトレーニング時に使用されるコンテキスト フレームへのマスクを表します。
b.2 オートエンコーダのタイミング微調整
時間的にコヒーレントなビデオの画像ドメインで LDM オートエンコーダを直接使用すると、生成されたビデオにちらつきアーティファクトが発生します。
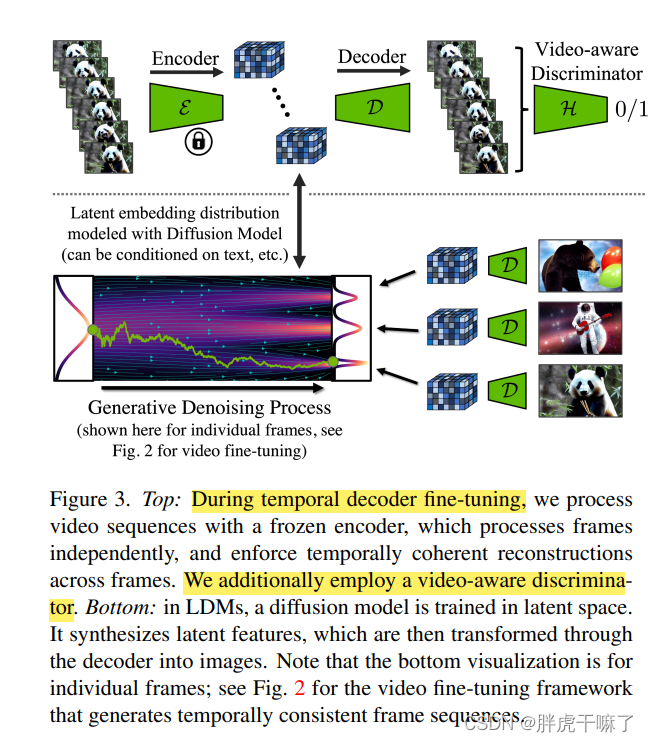
潜在ベクトル空間上で事前にトレーニングされた LDM モデルを確実に再利用できるようにするために、エンコーダーは変更されず、デコーダーのみが微調整されます。
ビデオは微調整データセットとして使用され、微調整サンプリングは 3D 畳み込みによって構築された (パッチごとの) タイミング弁別器です。
b.1 で生成されるのは、特徴の形で存在する画像またはビデオの潜在ベクトルであることに注意してください。上図の下部に示すように、さまざまな潜在特徴が画像にデコードされます。さまざまな分布ピークのデコーダ。異なる間隔の潜在ベクトルにより、異なる画像がデコードされます。この特徴を観察すると、フレームワークがビデオ用に微調整されると、フレーム間のタイミングの一貫性が
確認できることが説明できます。異なるピークの周りに散在する元の画像コンテンツは独立しています。ビデオの微調整後は、それらはほぼ一致します。同じピークであり、画像も内容の一貫性を示しています。
c. 長期的な生成結果のための予測モデルへの変換
セクション b で使用される方法は、長いビデオ シーケンスを生成するのが難しいため、S コンテキスト フレームをフィードし、予測モデルになるようにモデルをトレーニングします。これは時間バイナリ マスクによって実現され、長さ T のビデオでは、S ビデオ フレームが予約され、予測される TS ビデオ フレームがマスクされます。ビデオ フレームをエンコードした後、それにマスクを掛けて、学習したダウンサンプリング操作を実行します (学習したダウンサンプリング操作:size+conv2d、ダウンサンプリングの学習方法は明確ではありません。コードを参照してください)。それをタイミング層の中央に送ります。
推論中、サンプリング プロセスを繰り返し実行してフィールド ビデオを生成し、最新の予測を新しいコンテキストとして再利用できます。最初の初期シーケンス生成方法: 基本画像モデルから 1 つのコンテキスト フレームを生成し、これに基づいて初期シーケンスを生成します; 残りのシーケンス生成方法: 2 つのコンテキスト フレームを使用して動きを符号化します。このプロセスを安定させるために、この論文では、次のように分級器を使用しない拡散ガイドを使用してサンプリング プロセスをガイドします。
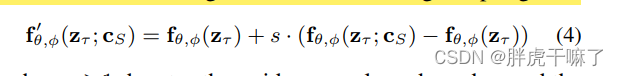
この章の目的は、キー フレームを生成することです。フレームの数が少なくなるとメモリが節約されますが、異なるフレーム間には大きな意味の変化が依然として存在します。高いフレーム レートを達成し、一貫性を達成するために、次の章ではタイミング補間を実行します。
d. より高いフレームレートのためのタイミング補間
2 つのキー フレーム間を補間するには、章 c で説明したマスキング コンディショニング メカニズムを使用します。ただし、マスクのオブジェクトは補間されるフレームです。それ以外の場合は、章 c と同じになり、画像モデルはビデオにリファインメントされます。補間モデル。実験では、1 回の補間の結果としてビデオの長さが T から 4T に変換され、これを 2 回繰り返し使用して 16T に変換できます。
e. 超解像モデルのタイミング微調整
カスケード DM に触発されて、著者はピクセル空間 DM や LDM アップサンプラーなどのアップサンプラーの別の層を使用して単一画像の解像度を向上させようとしましたが、各フレームを個別にアップサンプリングすると時間の一貫性が低下するため、スーパーモデルには時間的なビューも必要であり、セクション b で紹介した方法のようにアップサンプラーを微調整することを選択します。アップサンプラーはクラスター上でのみ動作するため、すべてのアップサンプラーをパッチ上で効率的にトレーニングし、モデルに畳み込み適用できます。
3. さまざまなミッションエリアとそれぞれの詳細
このモデルは、屋外走行データのシミュレーションと text2video に基づくクリエイティブ コンテンツの生成に適用されます。
さらに、このモデルは、既存の画像 LDM に対して時間的に調整されたモデルのセットのみをトレーニングできますが、LDM のさまざまな (画像 LDM の微調整されたバリアント) ビデオ バージョンのロックを解除できます。