物体検出の応用は、セキュリティや自動運転車システムなど、私たちの日常生活に浸透しています。オブジェクト検出モデルは、ビジュアル (画像またはビデオ) を入力し、対応する各オブジェクトの周囲にラベル付けされたバージョンを出力します。物体検出モデルでは、これまでに完成され開発されてきた複雑なアルゴリズムとデータセットを考慮する必要があるため、これは言うは易く行うは難しです。
物体検出について包括的に紹介するために、今日取り上げる内容は次のとおりです。
ディープラーニングによる物体検出の概要
1. ターゲット検出の基礎
オブジェクト検出のアプリケーション、ユースケース、および基本的なオブジェクト検出方法に入る前に、オブジェクト検出自体についてしっかりと理解することが重要です。この用語は、画像分類、オブジェクト認識、セグメンテーションなどの技術と同じ意味で使用されることがよくあります。ただし、上記のタスクの多くは別個のタスクであり、通常は物体検出に属することを認めなければなりません。どちらも同じように重要なタスクに関係しているため、これらを同一視して使用するのは不正確です。

物体検出とは
オブジェクト検出は、画像、ビデオ、さらにはライブ映像内のオブジェクトの認識とラベル付けに焦点を当てたディープ コンピューター ビジョン技術です。新しいデータに対してこのプロセスを実行するには、残りの注釈付き視覚画像を使用してオブジェクト検出モデルをトレーニングします。ビジュアルを入力し、完全にラベル付けされた出力ビジュアルを受け取るのと同じくらい簡単になります。物体検出モデルについては後ほど詳しく説明します。重要なコンポーネントはオブジェクト検出境界ボックスです。これは、鋭い四角形 (通常は正方形または長方形) でマークされたオブジェクトのエッジを識別します。これらにはすべて、対象物体を説明するために、人、車、犬などの物体のラベルが付いています。モデルがラベルを付けるアイテムについての事前知識を持っている限り、境界ボックスを重ねて特定のショット内の複数のオブジェクトを表示できます。
物体検出とその他のタスク
それぞれのタスクをよりよく理解するために、他のコンピューター ビジョン タスクを個別に分類してみましょう。
- 画像分類: これは、画像内のアイテムのカテゴリの予測です。たとえば、Google で画像の逆検索を実行すると、「「x」が含まれている可能性があります。「x」は、この手法で検出された画像の主なオブジェクトです。画像分類により、画像が次のことを示すことができます。特定のオブジェクトを含みますが、これは主要なオブジェクトを指しており、ビジョン内でのオブジェクトの位置は提供されません。
- セグメンテーション: セマンティック セグメンテーションとも呼ばれ、境界ボックスでオブジェクトを識別するのではなく、同等の属性を持つピクセルをグループ化するタスクです。
- 物体の位置特定: 物体検出との違いは微妙ですが、明らかです。オブジェクトの位置特定は、画像内の 1 つまたは複数のオブジェクトの位置を特定することを目的としていますが、オブジェクト検出は、位置にあまり焦点を当てずに、すべてのオブジェクトとその境界を識別します。
2. ディープラーニングと機械学習
物体検出の基本を理解したところで、今度は物体検出の 2 つの主要なモデル、ディープ ラーニングと機械学習を見てみましょう。データ アナリストは、ディープ ラーニングの手法がより直観的であり、人間の介入をあまり必要としないため、比較的高度な手法であると考えることがよくあります。最終的にはどちらの方法でも正確な結果が得られますが、今回はディープラーニングによる物体検出に焦点を当てます。
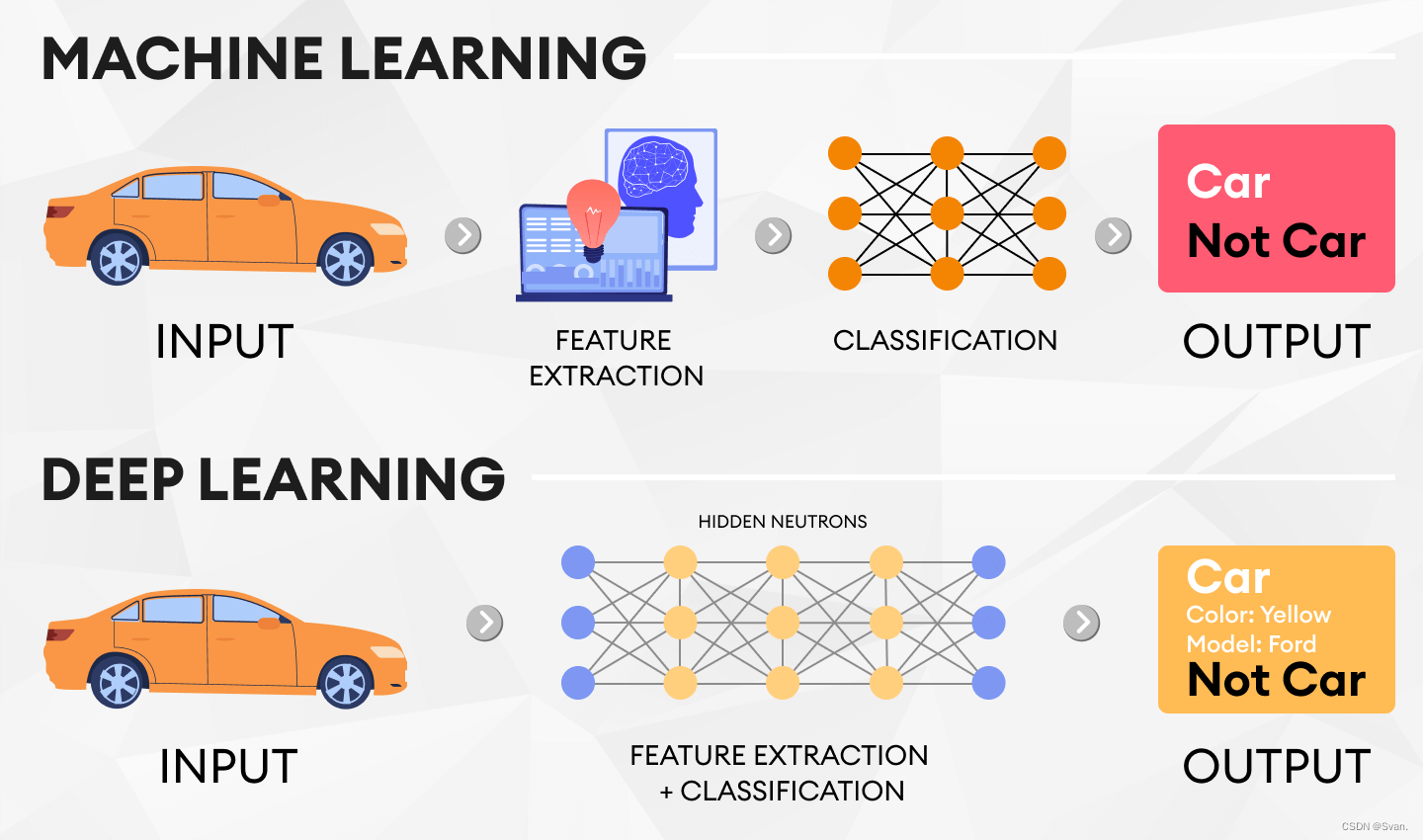
ディープラーニングによる物体検出とは何ですか?
ディープ ラーニングによる物体検出を他の方法と区別するのは、畳み込みニューラル ネットワーク (CNN) の使用です。ニューラル ネットワークは、人間の脳の複雑な神経構造を模倣します。これらは主に入力層、隠れた内部層、出力層で構成されます。これらのニューラル ネットワークの学習は、教師あり、半教師あり、教師なしで行うことができ、トレーニング データに注釈が付けられている場合 (教師なし) の量を参照します。CNN は人間工学をあまり使わずに自動的に学習できるため、物体検出用のディープ ニューラル ネットワークは、これまでで最速かつ最も正確な単一および複数の物体検出結果をもたらします。ディープ ラーニングと CNN の世界を解明する必要がありますが、今日は物体検出アルゴリズムとモデルに関する重要なポイントのみに焦点を当てます。
3. 手法とアルゴリズム
物体検出は、このタスクを処理するために特別に設計されたモデルがなければ不可能です。これらの物体検出モデルは、数万のビジュアル コンテンツを使用してトレーニングされ、後で自動的に検出精度を最適化します。COCO (Common Objects in Context) などのすぐに利用できるデータセットを利用してモデルを効率的にトレーニングし、洗練させることができるため、アノテーション パイプラインのスケーリングを有利に進めることができます。
最も著名な物体検出アルゴリズムとアプローチのいくつかを詳しく見てみましょう。
R-CNN、高速 R-CNN、高速 R-CNN
大きな成功を収めた最初の手法ファミリーは、2014 年に提案された R-CNN (地域ベースの畳み込みニューラル ネットワーク) でした。これは、以前は多数の領域があったのではなく、領域提案と呼ばれる画像から 2000 個の領域を抽出するだけで、以前の方法を上回りました。R-CNN のフローチャートは次のとおりです。入力画像が選択され、そこから 2000 個の領域候補が抽出されます。次に、個々の領域から特徴が抽出され、既知のクラスの 1 つに分類されます。R-CNN の主な欠点は、2000 地域の提案が抽出されるものの、プロセスが非常に長いことです。これが、新しく改良された Fast R-CNN への道を切り開いたものです。
多数の領域を使用したオブジェクト検出プロセスに時間がかかるだけでなく、非常に多くの領域を使用した CNN のトレーニングにも時間がかかります。Fast R-CNN は、事前トレーニング済み CNN に画像を入力して畳み込み特徴マップを生成することで、処理時間を大幅に短縮し、画像を 2000 個の領域提案に分解するプロセスを排除します。代わりに、領域提案は特徴マップから簡単に識別でき、それらを RoI プーリング層に送信し、特定の領域から特徴を抽出します。次に、前の層の出力は全結合層によって処理され、モデルは 2 つの出力に分割されます。1 つはソフトマックス層によるクラス予測用、もう 1 つは線形出力による境界ボックス予測用です。
R-CNN から Fast R-CNN への移行はどの程度重要ですか? CNN のトレーニング時間は84 時間から9 時間に短縮されました。また、テスト時間は50 秒から2.5 秒に短縮されました。
その後、Faster R-CNN と呼ばれる、よりアップグレードされた 3 番目のモデルが導入されました。アーキテクチャは Fast R-CNN に似ていますが、いくつかの注目すべき調整が加えられています。より高速な R-CNN は、類似した領域の階層的なグループ化に基づく選択的検索を使用しません。記録的な速さで地域提案を最終決定するために、地域提案ネットワークがその役割を果たします。これにより、Fast R-CNN の2.5 秒のテスト速度が比類のない0.2 秒に短縮され、これまでのバージョンの中で最速となり、リアルタイムの物体検出に最適な選択肢となりました。
ヨロ
R-CNN よりも高速な畳み込みニューラル ネットワークがあると言ったらどうなるでしょうか? はい、あります! 2015 年に、有名なフレーズ「人生は一度だけ」にちなんで、ニューラル ネットワークのファミリーが提案され、YOLO と略されます。 。これは、ネットワークが最終画像を出力する前に 1 回だけネットワークを「検索」する、またはネットワークを通過するという単純な事実に依存しています。これにより、リアルタイム映像による物体検出が可能になり、監視関連のアプリケーションにとって非常に望ましいものとなります。速度が非常に速いため、物体の検出精度は前述のモデルに比べて低くなりますが、それでも他のモデルの中でトップ候補として機能します。

4. ユースケースとアプリケーション
すでにいくつかの例を見てきたように、深層学習による物体検出は私たちの日常生活で非常に一般的です。現代世界におけるその重要性は、多くの人が当初想定しているよりもはるかに大きいです。
監視、セキュリティ、交通
データラベルは別として、ビデオやライブ映像での物体検出は最先端の監視の基礎です。コンピューター ビジョンは、盗難、交通違反、不審な人間の活動などの検出において革新をもたらし、期待を継続的に上回ることを目指しています。これらすべてのプロセスは徐々に、かつてないほど効果的に監視されるようになってきています。
車
自動運転では、車が次の瞬間に加速、ブレーキ、または方向転換するかどうかを決定できるように、物体検出が必要です。これには、車、歩行者、信号機、道路標識、自転車、オートバイなど、さまざまなものを識別するための物体検出が必要です。
医療
物体検出は、医学、特に放射線学の分野で完璧な発展を遂げています。このテクノロジーは、放射線科医やその他の専門家による専門知識の必要性を完全に置き換えるものではありませんが、毎日数百から数千の超音波スキャン、さらには X 線、MRI、CT スキャンの分析にかかる時間を大幅に短縮します。
小売り
手動の在庫確認を必要としないスマートな在庫管理、レジなしのショッピング体験、店舗に物体検出コンピュータービジョンを導入する小売業者が増えています。
5. 重要なポイント
物体検出では、画像分類と物体の位置特定を組み合わせて、画像からライブ映像までのさまざまなビジュアルを解釈してラベルを付けます。過去 10 年間で、ディープラーニングを使用した物体検出モデルの処理時間と速度は大幅に短縮されましたが、これは CNN なしでは実現できませんでした。物体検出が、スマートフォンの安全機能から次世代のスマート カーが依存する基盤に至るまで、さまざまなアプリケーションに普及していることがはっきりとわかります。結局のところ、物体検出モデルは、より正確になり、現代世界におけるよりリアルタイムの問題を解決するために、日々進化、成長、革新されています。
このディープラーニングによる物体検出の基本的な紹介が、さらに構築するための基礎として機能することを願っています。