この記事を読んでいると、必ず疑問が生じますが、この記事は前の記事と同じではないでしょうか? 前回の記事は大きく異なり、この記事も、私が以前から補足したいと思っていた記事です。前の記事。前回の記事をまだ読んでいない場合は、ここからジャンプできます。
タイトルにあるように、Beluga 最適化アルゴリズムは VMD パラメーターを最適化し、最小エンベロープ エントロピーが適合関数であり、最小エンベロープ エントロピーに対応する IMF コンポーネントを抽出し、最良の IMF コンポーネントの 9 つの時間領域インジケーターを収集し、特徴ベクトルを抽出します。 。よくわからない場合は、このドキュメントを参照してください。
[1] Yang Sen、Wang Hengdi、Cui Yongcun、Li Chang、Tang Yuanchao、改良された AFSA パラメータ最適化 VMD および ELM に基づくベアリング故障診断 [J]、工作機械と自動処理技術の組み合わせ、2023(04):67-70 。
ここに主なアイデアを皆さんに示すための浅いスクリーンショットもあります。赤い線がこの記事の内容です。

ここで今回の記事と前回書いた記事の違いについて簡単にお話します。読みたくない場合は、この段落を無視してかまいません。直接読んでください(ここをクリック)
- この記事では、VMD パラメータの最適化にベルーガ最適化アルゴリズムを使用しています。この方法を選択した理由は、①前の記事で使用したスパロー最適化アルゴリズムよりも理解しやすいことです。コメント欄に小さなパートナーがたくさんいたためです。アルゴリズムには多くのバグが発生しており、この方法はバグを可能な限り回避するためのものです; ②シロナガスクジラ最適化アルゴリズムは 2022 年に提案されており、現在では比較的新しいアルゴリズムであり、VMD 最適化を学習する際にもこの新しいアルゴリズムを学ぶことができます。
- まず、前回の記事の考え方について説明します。まず、スパロー最適化アルゴリズムを使用して VMD パラメーターを最適化し、最良の K 値と α 値を取得します。その基礎は最小エンベロープ エントロピーです。さて、ここの皆さんは明快でわかりやすいのですが、このK値とα値をさらに下でどう使うのか?
- 現在、著者が知っている方法は 2 つあります: ① K 値と α 値を戻して各 IMF 成分の近似エントロピーを求め、この近似エントロピー値を使用して特徴ベクトルを構築する; ② 最小エンベロープ エントロピーを計算する際に、インデックスを置く最小エンベロープエントロピーの値idx(つまり、分解したK個のIMF成分のうち、どの成分が最もエントロピーエントロピーが小さいか)を関数として出力し、K値、α値、およびこのインデックス値idxを戻します。 、特徴ベクトルを構築するために、インデックス値に対応するIMF成分の尖度値、ピーク値、平均値、マージン係数および他の指標を計算する。
- 2 つの方法にはそれぞれ長所と短所があり、最終的に機械学習モデルの診断結果は非常に良好です。どちらの方法でも参照を検索できます。最初の方法の欠点は、エンベロープ エントロピーが完全に使用されていないことです。この方法では、エンベロープ エントロピーを最小の目的関数として使用して VMD パラメーターを最適化し、最小エンベロープだけでなく、各 IMF コンポーネントの近似エントロピーを計算します。 . ネットワーク エントロピーに対応する IMF コンポーネントは近似エントロピーを計算しますが、もちろん特徴ベクトルを形成することは不可能です。2 番目の方法は、最小のエンベロープ エントロピーに対応する IMF コンポーネントのみを現在のデータの主な特徴とし、ピーク値、マージン ファクター、平均値、分散などのいくつかの指標を見つけて特徴ベクトルを構築する方法です。
ここでこの話をするとみんなが騙されるかどうかは分かりません。混乱しても構いませんので、結果を見てコードに問題がないことを確認し、コードを読んだ後に上記の説明に戻りましょう。
次はまだ最初の結果です。

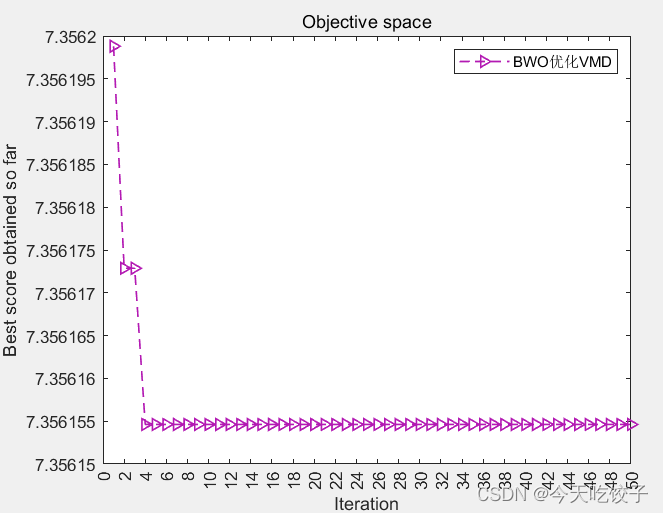
BWO-VMD 反復曲線:

ホワイトクジラ最適化アルゴリズムを使用して VMD パラメーターを最適化し、パラメーターを次のように設定します。プログラム内の母集団の数は 10、反復回数は 50 です。上の 2 つの図は、97 の通常データに基づいています。 2 つの VMD パラメータの値は次のとおりです: 2500、10 (ここでもう 1 つ説明します。この境界値に疑問がない場合は、次の段落を直接無視してください。
- 前回の記事では、なぜこの値が境界線上にあるのか、またなぜいくつかの参考文献と矛盾しているのかについて、誰もが非常に混乱していました。著者はここで声を揃えて言います。まず、さらに数回試してから、試してみてください。母集団の数は20から選択でき、探索範囲を増やすことができます それでも境界にある場合は、データのサンプリング点の数を増やします (データ点のサンプリング数については、以下のプログラムで説明します) 、マークします))。つまり、境界値であるかどうかに関係なく、最終的なマシン モデルには優れた診断効果があり、障害を正確に特定できます。この目標を達成するには十分ですか? 読者の皆様、一部の記事で言及されている値は、他の文書は必ずしも確実ではありません。正しいです (ここでは多くを言いません。理解できる人は理解します)。
- 以下にデータを変更した反復図を添付します。このデータは 105.mat です。ご覧のとおり、これは境界上にありません。

-
次のステップはコードをアップロードすることです。最初はデータ処理コードです。上記の変更されたサンプリング ポイントの数はこのコード内にあります。
- ウェスタン リザーブ大学のデータとデータ処理スクリプト ファイルをダウンロードする方法が記載されている私の他の記事もお読みください。データがある場合は、コードを直接コピーして方位データと同じフォルダーに置くこともできます。(賢い女性はご飯がなければ料理はできないということわざがあるように、まずデータを処理する必要があります。もちろん、さらに他のデータが必要な場合は、後で記事を整理します)
clc;
clear;
addpath(genpath(pwd));
%DE是驱动端数据 FE是风扇端数据 BA是加速度数据 选择其中一个就行
load 97.mat %正常
load 105.mat %直径0.007英寸,转速为1797时的 内圈故障
load 118.mat %直径0.007,转速为1797时的 滚动体故障
load 130.mat %直径0.007,转速为1797时的 外圈故障
load 169.mat %直径0.014英寸,转速为1797时的 内圈故障
load 185.mat %直径0.014英寸,转速为1797时的 滚动体故障
load 197.mat %直径0.014英寸,转速为1797时的 外圈故障
load 209.mat %直径0.021英寸,转速为1797时的 内圈故障
load 222.mat %直径0.021英寸,转速为1797时的 滚动体故障
load 234.mat %直径0.021英寸,转速为1797时的 外圈故障
% 一共是10个状态,每个状态有120组样本,每个样本的数据量大小为:1×2048
w=1000; % w是滑动窗口的大小1000
s=2048; % 每个故障表示有2048个故障点
m = 120; %每种故障有120个样本
D0=[];
for i =1:m
D0 = [D0,X097_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D0 = D0';
D1=[];
for i =1:m
D1 = [D1,X105_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D1 = D1';
D2=[];
for i =1:m
D2 = [D2,X118_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D2 = D2';
D3=[];
for i =1:m
D3 = [D3,X130_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D3 = D3';
D4=[];
for i =1:m
D4 = [D4,X169_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D4 = D4';
D5=[];
for i =1:m
D5 = [D5,X185_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D5 = D5';
D6=[];
for i =1:m
D6 = [D6,X197_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D6 = D6';
D7=[];
for i =1:m
D7 = [D7,X209_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D7 = D7';
D8=[];
for i =1:m
D8 = [D8,X222_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D8 = D8';
D9=[];
for i =1:m
D9 = [D9,X234_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D9 = D9';
data = [D0;D1;D2;D3;D4;D5;D6;D7;D8;D9];
ceshi_data = data;
save data data
folder='测试数据汇总/'; %%定义变量
if exist(folder)==0 %%判断文件夹是否存在
mkdir(folder); %%不存在时候,创建文件夹
end
xlswrite('/测试数据汇总/转速1797_测试数据汇总.xlsx',ceshi_data);
dd = [];
for i = 0:size(data,1)/m-1
dd(1+m*i:m+m*i) = i+1;
end
zj = [dd;data'];
ceshi_data = zj';
xlswrite('/测试数据汇总/转速1797_测试数据汇总带标签.xlsx',ceshi_data);
rmpath(genpath(pwd))次に、BWO-VMD の最適化と特徴抽出のメイン プログラムです。実行時にこのファイルを実行するだけです。注: このコードのコメントを注意深く読む必要があります。特に最後の数行!
- このメインファイルは VMD パラメータの最適化と 1 種類の障害の特徴抽出のみに使用されます。他の種類の障害の特徴を抽出したい場合は、手動でコードを修正する必要があります。コードの修正方法はメモに書きました。大きなループ全体を書かなかった理由は、次の理由からです: ①プログラムの実行が非常に遅く、各障害に対応する K 値と α 値を記録する必要がある。それぞれを確認できるようにする 初回実行時の最適なK値とα値②:2つ目のポイントも非常に重要です!それは、著者が少し怠け者であることを意味します。私はこの記事のすべての単語を 1 つずつ入力しました。エマも 2 時間入力しました...それを整理するのは簡単ではありません。支払いには下部にある小さなカードをクリックしてください注意!それ以上何も求めないでください...
%% 以最小包络熵为目标函数,采用BWO算法优化VMD,求取VMD最佳的两个参数
clear all
clc
addpath(genpath(pwd))
load data
%设置PSOCHOA算法的参数
D=2; % 优化变量数目
lb=[100 3]; % 下限值,分别是a,k
ub=[2500 10]; % 上限值
T=50; % 最大迭代数目
N=10; % 种群规模
y=@Cost;
da = data(190,:); %特别要注意,这里选择的时候要一类一类的选,比方说我要提取第种一类别的特征向量,那这里就从1-120行之间随便选一行,(为什么是120呢,是指我在数据处理阶段,每一类故障收集了120个样本的意思)
%然后计算最佳的两个VMD参数,计算完了之后,将最佳的k值和α值带入特征提取函数中,对这一类的数据进行近似熵的特征提取
%如果我提取第二类故障,那就在121-240之间随机选一行。
[bwoBest_pos,bwoBest_score,Bestidx,BWO_curve] = BWO(y,lb,ub,D,N,T,da);
%画适应度函数图
figure
plot(1:T,BWO_curve,'Color',[0.7 0.1 0.7],'Marker','>','LineStyle','--','linewidth',1);
% plot(1:T,BWO_curve,'Color','r')
title('Objective space')
xlabel('Iteration');
set(gca,'xtick',0:2:T);
ylabel('Best score obtained so far');
legend('BWO优化VMD')
display(['The best solution obtained by PSOCHOA is : ', num2str(round(bwoBest_pos))]); %输出最佳位置
display(['The best optimal value of the objective funciton found by BWO is : ', num2str(bwoBest_score)]); %输出最佳适应度值
%% 以下为将最佳的a,k,idx带入VMD中,并进行近似熵特征提取
bbh = round(bwoBest_pos);%最佳位置取整
new_data1 = tezhengtiqu(bbh(1),bbh(2),Bestidx,data(1:120,:)); %将优化得到的两个参数和最小包络熵的索引值带回VMD中
save new_data1.mat new_data1 %将提取的特征向量保存为mat文件,方便概率神经网络的处理
%% 删除路径,以免被其他函数混淆
rmpath(genpath(pwd))
%当想要寻优第其他故障类型的时候,就需要大家将da=data(111,:),改成da=data(125,:),(随机的从121-240之间挑一个数,因为这个区间是同一类的故障,我们默认优化同一类故障数据得到的最佳IMF分量索引是一致的!)
%其次还需要改new_data = tezhengtiqu(bbh(1),bbh(2),idx,data(1:120,:));将data(1:120,:),改成data(121:240,:)
%save new_data2.mat new_data2 这里也改成data2
%就这样,大家一种类型一种类型的提取,一遍一遍记录每次得到的最佳K和α的值,一遍一遍的把特征变量存储起来就ok啦
最後の 4 行のコメントからわかるように、診断対象として 10 種類の障害を選択すると、次のようになります。このメインプログラムを 10 回実行する必要があり、毎回いくつかの場所を変更する必要があります。最後に、次のような表をまとめることができます。
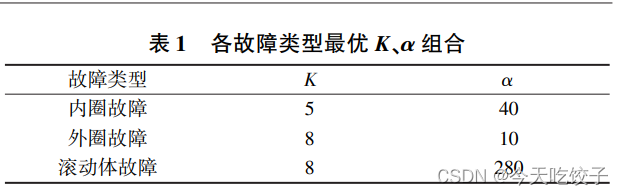
これはこの記事で得られた表ではなく、著者は「最適な組み合わせでこのような表が得られる」と皆さんに伝えているだけで、論文に書いた方が説得力が増しますよね?
この記事を例として挙げると、特徴抽出後のデータ処理段階で、合計 10 個の障害タイプが選択され、各タイプは 120 個の障害サンプルになります。各故障サンプルは、平均値、分散、ピーク値、尖度、実効値、波高率、パルス率、形状率、およびマージン率を含む 9 つの指標に置き換えられます。最終的に 1200*9 のデータを取得しました。これが特徴抽出後に得られたデータです。次に、このデータを取得して、トレーニングと予測のために各機械学習モデルに送信できます。
前回の記事で皆様の操作に様々な問題が出てくると思いますので、今回は圧縮パッケージ全体を直接整理してみようと思います!
以下のカード内のキーワードを答えてください: BWOVMD
ぜひコメント欄にメッセージを残してください。