1. 爬虫類によく使われるライブラリ
import requests
from bs4 import BeautifulSoup
import re
import time
import json
2、セッションを使用する
Python のrequestsライブラリにある、SessionHTTP リクエストを HTTP サーバーに接続し、セッション状態を維持する方法を提供するオブジェクトです。これは、リクエスト間で Cookie を自動的に保持する Web ブラウザーのようなセッションを実装します。
Session オブジェクトを使用する利点は、基盤となる同じ TCP 接続を複数のリクエスト間で再利用できるため、接続の接続と終了のオーバーヘッドが節約され、セッション レベルの状態とパラメータ ( 、 、 など) を共有できるcookieことHTTP头ですSSL证书。これにより、複数のリクエストを行う必要がある複雑な Web アプリケーションやタスクをより簡単かつ効率的に処理できるようになります。
具体的には、Session オブジェクトを使用して次のタスクを実行できます。
-
永続セッション: Session オブジェクトを使用すると、Cookie やその他のパラメーターを複数のリクエスト間で共有して、同じセッション中のブラウザーの動作をシミュレートできます。
-
Cookie の管理: Session オブジェクトを使用すると、Cookie を自動的に管理できます。リクエストが送信されると、サーバーから返された Cookie は自動的に Session オブジェクトに保存され、これらの Cookie はセッション状態を維持するために後続のリクエストで送信されます。
-
接続プール: Session オブジェクトを使用すると、同じ基盤となる TCP 接続を再利用でき、その接続を複数のリクエスト間で共有できるため、接続と接続の終了にかかるオーバーヘッドが軽減されます。
-
SSL 証明書の検証: Session オブジェクトを使用して、安全な HTTPS Web サイトと通信する際の検証用の SSL 証明書を指定および管理できます。
要約すると、Session オブジェクトは、Web アプリケーションのテスト、自動化、データ スクレイピング、およびその他の同様のタスクを簡素化するのに役立ちます。
s = requests.session()
commonlogin_url = '真实登录地址'
login_data = {
'uname':'uname',
'password':'passeord',
'refer':'',
't':'true',
'fid':'-1',
'forbidotherlogin': '0'
# validate:
# doubleFactorLogin: 0
# independentId: 0
}
rep_commonlogin=s.post(commonlogin_url,data=login_data,allow_redirects = True)
print(rep_commonlogin.text)
分析:
1. セッションを呼び出してインスタンスを作成します
2. URL に実際のログイン アドレスを入力します ログイン アドレスには f12 を介してアクセスでき、開発者ツールを開き、ネットワークの監視下でログイン ページを更新し、実際のログインは同様のloginファイルによって送信され、URL の取得を要求します。

3. 自分のパスワードを入力してくださいdata。ログインするページのパスワードが暗号化されて保存されている場合は、最初に正しいアカウントと間違ったパスワードを入力し、次に正しいパスワードと間違ったアカウントを入力して、類似したファイルと対応する情報を検索することで再度ログインできますfanyaloin。
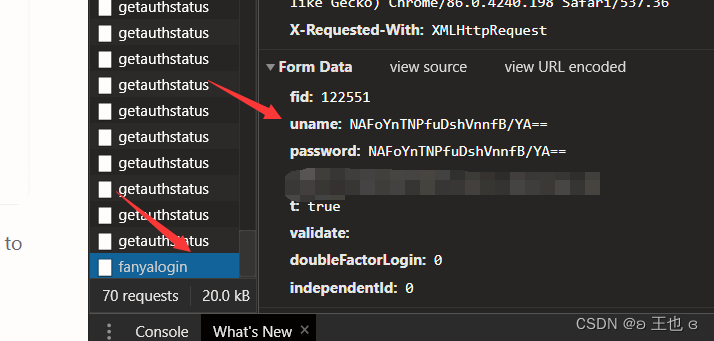
ここでのリクエストは辞書の形式であることに注意してください。それが何であるかの始まりを書く必要があります。たとえば、彼のキーは uname で、あなたのものは uname です: 暗号化されたパスワード。キーがあなたの名前の場合、同じです。真実。
リクエストが失敗した場合は、まず get 内のすべてのキーをコピーしてアクセスできることを確認してから、不要なリクエストを削除してください。
4..postこのメソッドは暗号化通信後に送信されたリクエストを受信し、その `.text` テキストを出力します。ログイン インターフェイスではなくなった場合は、ログインに成功したことがわかります。次の期間は、ログインせずに Web ページにアクセスできるようになります。
3番目、次は(3番目の古いもの)
1. 最初にヘッダーを作成します
2. .getURL から取得した情報を使用します
3.BeautifulSoupライブラリを使用して HTML を解析します
4..find_allメソッドを使用して、必要な特定のクラスの特定のタグのすべての情報を取得します
5. 空のリストを作成しますそして、forloopメソッドと+ str()を使用して、訪問したいページのリンクを順番に結合し、結合されたURLを作成された空のリストに保存します。
htmlから欲しい情報を取得するには正規表現を使うこともできますが、キーの後ろにある完全なデータであればそこまで面倒なことはせずに直接読み込めば大丈夫です。
6. ページがジャンプしたら、.get目的のページに進み、最後のページが見つかるまで 2 ~ 6 のプロセスを繰り返します。
アクセスしたいページは一夜にして得られるものではないことに注意してください。必要な情報を見つけるには複数の取得リクエストが必要であり、その後最後のページに入る必要があります。
ヒント:誰もがさまざまなページをクロールしたいと考えています。ここではアイデアを提供することしかできません。何かわからない場合は、プライベート メッセージを送ってください。
7. クロールするときは注意しないsleepと発見される可能性があります
time.sleep(5)
8. 必要なデータが含まれるページを見つけたら、js 内のコードをクロールし、次の関数を使用して解析することに注意してください。弦:
status_json=json.loads(status_json)
この時点で見つかったものは文字列であり、ロードを使用してそれをデータ フレームに変更する必要があることに注意してください。
9. 必要なリンクを取得したら、パケット キャプチャに従って結合する実際のアドレスを見つけ、上記の方法を使用して結合して完全な URL を取得します (クリックしてブラウザでダウンロードできます)。または、for ループ、バッチ ダウンロード方法を使用できます。
with open(path+'/'+filename, 'wb') as f:
# 给一个后缀
f.write(rep_download.content)