01
序章
iQIYIは2012年にビッグデータ事業を開始して以来、ビッグデータのオープンソースエコロジーサービスに基づいた一連のプラットフォームを構築し、データ収集、データ処理、データ分析、データアプリケーションなどのビッグデータプロセス全体をカバーし、データのサポートを提供してきました。企業の経営判断やさまざまなデータインテリジェンス事業を強力にサポートします。データ規模の継続的な成長と計算の複雑さの増加に伴い、データの潜在的な価値を迅速に掘り出す方法がビッグ データ プラットフォームに大きな課題をもたらしています。
大量データのリアルタイム分析ニーズに応えて、ビッグデータチームは2020年からビッグデータ加速プロジェクトを立ち上げ、ビッグデータ技術に基づいてiQIYIデータの流通を加速し、よりリアルタイムの運用上の意思決定などを促進しています。効率的な情報配信。その 1 つは、OLAP データ分析の Hive エンジンから Spark SQL エンジンへの切り替えを促進することです。これにより、タスクが 67% 高速化され、リソースが 50% 節約され、大きなメリットが得られ、以下のようなビジネスに効率性と収益の増加がもたらされました。 BI、広告、メンバーシップ、ユーザーの増加など。
02
バックグラウンド
iQIYI のビッグデータ プラットフォーム構築の初期段階では、オープンソースの Hadoop エコシステムに基づいてビッグデータ インフラストラクチャとデータ ウェアハウスが構築され、主にデータ処理と分析に Hive が使用されました。Hive は、Hadoop ベースのオフライン分析ツールで、Hadoop 分散ファイル システムに保存されたデータを分析するための豊富な SQL 言語を提供します。構造化データ ファイルのデータベース テーブルへのマッピングをサポートし、完全な SQL クエリ機能を提供します。SQL ステートメントの変換をサポートします。 Hadoop MapReduce タスクを実行し、SQL クエリを通じて必要なコンテンツを分析するため、Hadoop MapReduce に詳しくないユーザーでも SQL 言語を使用してデータのクエリ、要約、分析を簡単に行うことができます。ただし、Hive の処理速度は、特に大規模なデータを含む複雑なクエリを処理する場合に比較的遅くなります。
ビジネスの発展とデータ量の急増に伴い、特に広告インテリジェント入札、情報フローの推奨、リアルタイムのメンバーシップ操作、ユーザーの増加など、時間に敏感な新しいサービスにアクセスした後は、オフライン分析に Hive を使用することはできなくなりました。データの適時性に関するビジネス要件を満たします。この目的を達成するために、Trino や ClickHouse などの一連のより効率的な OLAP エンジンを導入しましたが、これらのエンジンはデータ分析により重点を置いており、データ分析が依存するデータ ウェアハウスと事前注文データ クリーニング処理は依然としてハイブの基礎。したがって、iQIYI のビッグデータリンクの全体的な高速化を実現するために、Hive の処理と分析のパフォーマンスをどのように向上させるかが、解決すべき緊急の問題となっています。
03
スキームの選択
私たちは、Hive on Tez、Hive on Spark、Spark SQL などのいくつかの主流の代替案を調査し、機能の互換性、パフォーマンス、安定性、変換コストなどの多次元から体系的に分析および比較し、最終的に Spark SQL を選択しました。
ハイブ・オン・テズ
このソリューションでは、Hive のプラグイン可能な実行エンジンとして Tez を使用し、MapReduce を置き換えてジョブを実行します。Tez は、DAG ジョブをサポートする Apache のオープン ソース コンピューティング フレームワークであり、その中心的なアイデアは、Map と Reduce の 2 つの操作をさらに分割して、大規模な DAG ジョブを形成することです。MapReduce と比較して、Tez は不必要な中間データの保存と読み取りのプロセスを大幅に節約し、MapReduce が完了するために複数のジョブの協力を必要とする処理を 1 つのジョブで直接表現します。
アドバンテージ:
無意味なスイッチング: SQL 構文は引き続き Hive SQL であり、Hive の実行エンジンは構成を通じて MapReduce から Tez に置き換えることができ、上位層のアプリケーションを変更する必要はありません。
短所:
パフォーマンスが低い: このスキームは大規模なデータ セットに対する並列処理能力が低く、データ スキューが発生すると明らかです。
コミュニティは活発ではありません: プログラムが業界で実施されることは比較的まれであり、コミュニティ内での交流や議論はあまりありません。
高い運用保守コスト: Tez エンジンが異常に動作した場合、参照資料がほとんどない
ハイブ・オン・スパーク
このソリューションでは、Hive のプラグイン可能な実行エンジンとして Spark を使用し、MapReduce を置き換えてジョブを実行します。Spark はメモリ コンピューティングに基づく大規模データ処理エンジンであり、MapReduce と比較して、スケーラビリティ、メモリのフル活用、および柔軟なコンピューティング モデルという特徴があり、複雑なタスクをより効率的に処理できます。
アドバンテージ:
鈍感な切り替え: SQL 構文は引き続き Hive SQL であり、Hive の実行エンジンは構成を通じて MapReduce から Spark に置き換えることができ、上位層のアプリケーションを変更する必要はありません。
短所:
バージョンの互換性が低い: Spark 2.3 以下のみがサポートされており、Spark 3.x 以降の新機能は使用できないため、将来のアップグレード要件を満たしていません。
満足できないパフォーマンス: Hive on Spark は依然として Hive Calcite を使用して SQL を解析して MapReduce プリミティブを生成しますが、これらのプリミティブの実行には MapReduce エンジンの代わりに Spark エンジンを使用するため、パフォーマンスはあまり理想的ではありません。
コミュニティが活発ではない: プログラムが業界で実装されることはほとんどなく、コミュニティも活発ではありません。
柔軟性のないリソース アプリケーション: Hive on Spark ソリューションで Spark タスクを送信する場合、リソースは固定的にしか設定できないため、マルチテナントおよびマルチキューのシナリオに適用するのは困難です。
スパークSQL
Spark SQL は構造化データ用の Spark ソリューションであり、Hive と互換性のある SQL 構文を提供し、Hive Metastore メタデータの使用をサポートし、完全な SQL クエリ関数を提供できます。したがって、Hive ベースのデータ ウェアハウスは引き続き Spark SQL シナリオで使用でき、既存の Hive SQL タスクのほとんどを Spark SQL にスムーズに切り替えることができます。
Spark SQL は、SQL ステートメントを Spark タスクに変換して実行し、メモリベースのモデルを使用してデータ計算とキャッシュを編成します。中間データをディスク上に配置する Hive on MapReduce ソリューションと比較して、ディスク IO オーバーヘッドが低く、実行効率が高くなります。
選定概要
次の表は、Hive on MapReduce、Hive on Tez、Hive on Spark、および Spark SQL の詳細な比較を示しており、Spark SQL がこのシナリオに最も適していることがわかります。
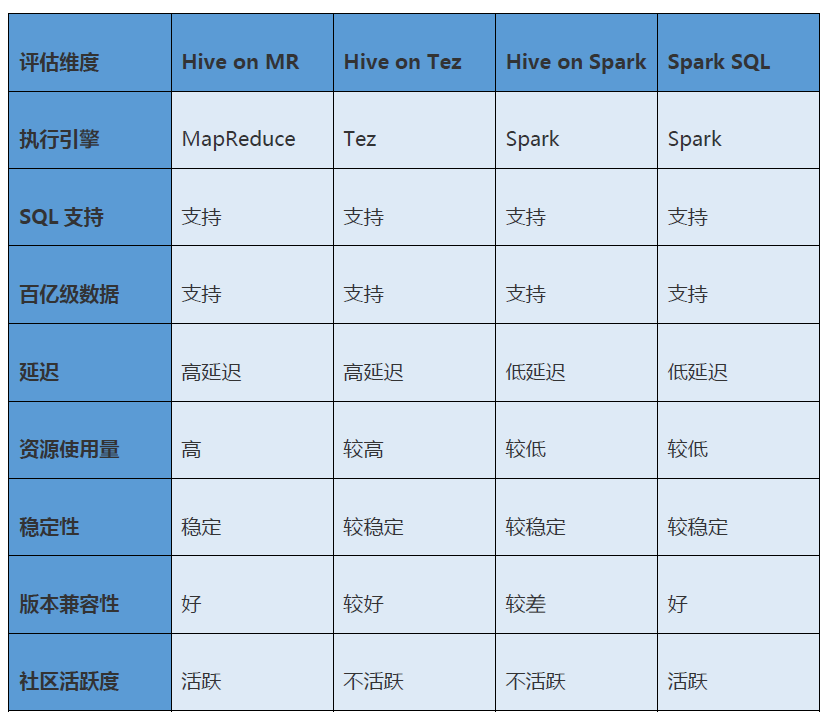
04
技術変革
Hive から Spark SQL への移行は、Spark の互換性変換とパフォーマンスの最適化、SQL タスク構文の調整、データ一貫性の保証、システム統合と依存関係の変換など、多くの課題と変換作業に直面しています。
Spark互換性の変換
Spark SQL と Hive SQL の間には文法的な違いがあり、移行プロセス中に多くの互換性の問題が見つかりましたが、Spark Extension メソッドを通じて SQL の各段階の実行計画をインターセプトして書き換え、構文、実行ロジック、メソッド関数を実現しました。など。互換性により移行の成功率が向上します。
主な違いをいくつか示します。
UDF マルチスレッドのサポート:以前は、Hive 上の UDF は、SimpleDateFormat 型の日付を処理するときに例外をスローしませんでしたが、Spark エンジンはそのような関数の実行にマルチスレッド メソッドを使用するため、Spark で実行するとエラーが報告されます。この問題は、UDF のコードを変更し、SimpleDateFormat を ThreadLocal に設定することで解決できます。
グループ化 ID のサポート: Spark は Hive の grouping_id をサポートしておらず、代わりに独自の grouping_id() を使用しますが、これにより互換性の問題が発生します。Spark を変更することで、SQL の解析時に grouping_id が grouping_id() に自動的に変換されることがわかりました。
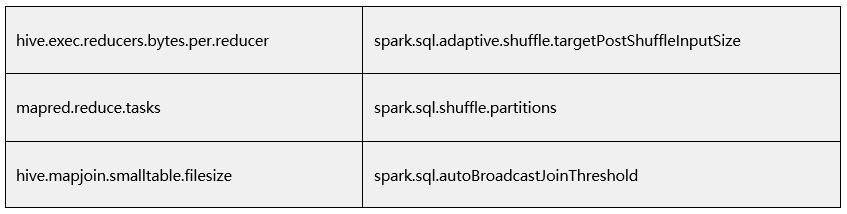
パラメーターの互換性: Hive 固有のパラメーターは、Spark の対応するパラメーターにマップする必要があります。
複雑な関数はエイリアス化できない: Hive では、計算列にエイリアスを付けないと、Hive はデフォルトで _c で始まる列名を付けますが、Spark は付けません。コンマを返す関数 (get_json_object など) を呼び出すとき、列の数が一致しないという問題が報告されます。この質問に対する回避策は、すべての列にエイリアスを付け、_c0 などのエイリアスを拒否することです。
永続的な関数をサポートしない: Spark が永続的な関数をサポートしない理由は、jar パッケージがコード内で HDFS からダウンロードされないためです。また、一時関数はライブラリ名の指定が必要ありませんが、永続関数は必須です。永続関数を促進するために、現在のライブラリに対応する関数が見つからない場合に特別な関数が追加されます。デフォルトのライブラリで永続関数を検索します。
リセット パラメーターはサポートされていません:オンライン タスクにリセット コマンドが使用されるシナリオがあります。Spark SQL がリセット コマンドをサポートできるように Spark を変更しました。
Spark の新機能の有効化と構成の最適化
動的リソース割り当て戦略 (DRA) を有効にする:タスクは、現在のプログラムのニーズに応じてエグゼキュータを自動的に適用または解放して、動的リソース調整を実現し、不合理なリソース割り当ての問題を解決します。アイドル状態のリソースの自動回復により、クラスター リソースの無駄が大幅に削減され、さらに、Executor の最大数を制限することで、大規模なクエリによる過度のリソース占有によるキューのブロックを回避できます。
Adaptive Query Optimization (AQE) を有効にする:タスクの実行フェーズで関連する統計指標を記録し、統計指標に基づいて後続の実行フェーズで実行計画を最適化します。たとえば、小さなシャッフル パーティションの動的マージ、適切な結合戦略の動的選択、偏ったパーティショニングなどを動的に最適化することで、データ処理効率を向上させます。
小さなファイルを自動的にマージする:書き込み前に Rebalance オペレーターを挿入し、Spark の AQE 最適化と組み合わせて、小さなパーティションを自動的にマージし、大きなパーティションを分割することで、多数の小さなファイルの問題を解決します。
Spark アーキテクチャの改善
このシナリオでは、アプリケーションは JDBC 経由で SQL タスクを Spark ThriftServer に送信し、Spark クラスターにアクセスします。ただし、Spark ThriftServer は単一ユーザーのみをサポートするため、複数のテナントが Spark にアクセスする能力が制限され、リソース使用率の低下や UDF の相互干渉などの問題があります。
これらの問題を解決するために、Apache Kokubi を導入しました。Ryubi は、SQL リクエストを処理するための独立した SparkSession の使用をサポートし、Spark Thrift Server と同じ機能を備えたオープン ソースの Spark ThriftServer ソリューションです。Spark ThriftServer と比較して、Apache Kokubi はユーザー、キュー、リソースの分離をサポートし、サービス指向およびプラットフォーム ベースの機能を備えています。
Apache Kokubi については、運用シナリオにより適したサービスを提供するために、いくつかのパーソナライズされた変更も加えました。
タグベースの構成:さまざまなコンピューティング シナリオまたはプラットフォームに対して、特定の構成をバインドするためにいくつかのタグが事前定義されています。タスクの実行時には、対応するタグを持ってくるだけでよく、プリセット構成は構成センターで自動的に補足されます。例: アドホック クエリ タスク、共有エンジンや大きなクエリ制限などの構成、ETL タスク、独立したエンジンの構成、小規模なファイル マージ構成など。
同時実行制限:異常な状況では、クライアントが大量のリクエストを送信し、Kyubi Service Worker スレッドが完全に占有される可能性があります。Kyubi では、ユーザーまたはクライアントが大量のリクエストを送信してサービスが満杯になることを防ぐために、ユーザー レベルと IP レベルで同時実行制限を実装しており、この機能はコミュニティにも提供されています。
イベント収集: Kyubi は SQL 実行の各段階でさまざまなイベントを公開し、これらのイベントを通じて SQL 監査と例外分析を簡単に実行でき、小さなファイルの最適化と SQL の最適化に優れたデータ サポートを提供します。
05
自動移行ツール
Hive から Spark SQL に移行する場合、上記の既知の互換性問題の解決に加えて、いくつかの未知の問題も発生する可能性があります。切り替え後にエンジンが正常に実行できること、切り替えによってデータの不整合が発生しないことを確認する必要があります。 、オンライン データへの影響を避けるために、元のソリューションに自動的にダウングレードする機能を提供します。一般的に使用される方法は、通常、2 セットのエンジンを一定期間対数的に実行し、対数結果が一致した後に切り替えるというものです。
切り替え前は、ビッグ データ プラットフォーム上で 20,000 を超える Hive タスクが実行されており、手動で 1 つずつ Spark SQL に切り替えるのは明らかに非現実的でした。移行効率を向上させるために、パイロットベースの自動スイッチング エンジン、デュアル実行、および対数移行ツールのセットを設計および開発しました。
Pilot は、iQIYI のビッグデータ チームと BI マジック ミラー チームが共同開発したインテリジェントな SQL エンジンで、OLAP データ分析の統合入口を提供し、Hive、Spark SQL、Impala、Trino、ClickHouse、Kylin などのさまざまな OLAP 分析エンジンを統合します。自動ルーティング、自動ダウングレード、電流制限、インターセプト、インテリジェントな分析と診断、異なるクラスター/異なるエンジン間の監査などの機能をサポートします。現在、Pilot は、Babel データ開発プラットフォーム、ギア タイミング ワークフロー エンジン、広告データ プラットフォーム、BI ポータル レポーティング システム、マジック ミラー、パオディンジャン、ヴィーナス ログ サービス センターなどのデータ開発および分析プラットフォームに接続されています。
Pilot を通じて SQL エンジンを自動的に切り替えることで、ユーザーが意識することなく Hive SQL を Spark SQL に切り替えることができ、データの一貫性を確保し、ロールバックする機能を備えています。
Pilot を通じて Hive タスクに関する情報を収集し、SQL ステートメント、キュー、ワークフロー名などの情報を取得します。
SQL 解析: SparkParser を使用して Hive タスクの SQL ステートメントを分析し、入力と出力に対応するデータベース、データ テーブル、その他の情報を見つけます。
出力マッピング テーブルを作成する: デュアル実行タスクの出力データのマッピング テーブルを作成し、オンライン データ テーブルと区別し、オンライン データへの影響を回避します。
エンジンの置き換え: デュアル実行タスクの実行エンジンを Spark SQL に置き換えます。
シミュレーションの実行: Hive エンジンと Spark エンジンを使用して対応する SQL タスクを実行し、対数検証のためにタスクの実行結果を上記のマッピング テーブルに出力します。
整合性チェック: 2 つのテーブルの行数と巡回冗長コード (CRC32 アルゴリズムに基づく) を比較することにより、データの整合性チェックを実行します。
その中でも、CRC32 アルゴリズムは、シンプルかつ高速なデータ検証アルゴリズムです。Spark には組み込み関数 CRC32 が用意されており、この関数の値は Long 型で、最大値は 10^19 を超えません。このアプリケーション シナリオでは、最初にテーブル内の各行の列データを concat_ws して CRC32 を計算し、CRC32 を Decimal(19, 0) に変換し、テーブルの各行で計算された CRC32 値を合計します。反映された内容を取得する テーブルの内容全体のチェックサム CRC32 値が一貫性の比較に使用されます。チェック SQL は具体的には次のとおりです。

マッピング テーブルの一部のフィールドはマップやリストなどのコレクション型であり、同じ実際のデータを持つ 2 つのテーブルが存在します。コレクション型フィールドの内部データの並べ替えの違いにより、CRC32 統計結果はオフセットされ、整合性チェックの結果に影響します。このような状況に対応して、コレクションの内部ソート後に一貫性チェックを実行する特別な UDF を開発しました。

マッピングテーブルの一部のフィールドがFloatやDoubleなどの浮動小数点型であるため、データ整合性検証の過程で統計精度の問題により、両テーブルのCRC32統計結果に差異が生じ、誤判定が発生する可能性があります。一貫性検証プロセスで。このため、検証アルゴリズムを最適化し、CRC32 統計値を計算する際に、小数点以下 4 桁が浮動小数点フィールド用に予約されています。

自動ダウングレード: Hive タスクが SparkSQL に切り替わって実行に失敗すると、パイロットを通じて自動的に Hive にダウングレードされ、実行のために再送信され、何が起こってもタスクがスムーズに実行されることが保証されます。
上記のプロセスを実行するためのプラットフォームベースの手段を提供します。ユーザーはプロジェクト名に応じて、自分が属するワークフローを見つけます。

プロジェクトの簡単な構成。タスク シミュレーションの実行時に使用されるパブリック パラメーターを入力します。
シミュレーション運用段階で運用状況のモニタリングをサポート

シミュレーションの実行が完了すると、移行条件を含む一連のタスクを取得できます。これにより、簡単な操作でワンクリック移行を実現できます。
06
伝達効果
一定の労力を費やした結果、Hive タスクの 90% を Spark SQL にスムーズに移行し、明らかなメリットを達成しました。タスクのパフォーマンスは 67% 向上し、CPU 使用率は 50% 削減され、メモリ使用量は 44% 削減されました。
ビジネス上の効果は次のとおりです。
広告: オフライン タスクの全体的なパフォーマンスが約 38% 向上し、コンピューティング リソースが 30% 節約され、コンピューティング効率が 20% 向上し、広告データの出力が加速されて収益が増加します。
BI: 合計時間消費量が 79% 削減され、リソースが 43% 節約され、P0 タスクの出力適時性が保証され、コア レポートは 30 分から 1 時間早く生成されます。
ユーザーの増加: データの作成が 2 時間早まり、ユーザー増加のコア レポートが 10:00 までに作成されるようになり、UG の運用効率が向上します。
会員様:注文データの出力が8時間早くなり、データ分析速度が10倍以上向上し、会員様の業務分析効率の向上に貢献
iQiyi: 平均実行時間が 40% 短縮され、1 日あたりの実行時間が約 100 時間短縮されました
07
これからの計画
アップグレード移行ツール
スムーズな移行の条件を満たさない一部の Hive タスクについては、移行を続行する前に、Spark SQL 構文と互換性のある SQL に書き直す必要があります。失敗したタスクの主要なエラー情報の抽出と自動照合をサポートするように移行ツールを改善しています。根本原因タグの診断、最適化の提案、さらには移行の迅速化に役立つ自動書き換えを提供します。
エンジンの最適化
Spark エンジン レベルでは、フォローアップと最適化が必要な問題がまだいくつか残っています。
大規模なストレージの問題: 小さなファイルの最適化に再パーティションを導入したため、データが分割され、一部のタスクで書き込まれるデータ圧縮率が低下します。コミュニティによって提供される Z オーダー最適化に関する追跡調査は、データ分散を自動的に最適化します。
DPP により SQL 解析が遅すぎる: 移行中に、DPP の最適化により一部の複数テーブル結合の SQL 解析が非常に遅くなる可能性があることが判明しました。現在、この問題は DPP 最適化結合の数を制限することで回避されています。 Spark 3.2 以降のバージョンでは、Spark SQL の解析が高速化されており、関連するパッチもいくつかあり、分析されて現在のバージョンに適用される予定です。
完璧なミッションクリティカルなインジケーター: 入出力ファイルのサイズとファイル数、Spark SQL の各ステージの実行時間など、プラットフォーム側でいくつかの Spark SQL 実行インジケーターを収集しました。問題のあるタスクといくつかの最適化効果を直感的に確認できます。将来的には、データ量、データ スキュー、データ拡張、その他の指標をシャッフルし、Spark SQL の計算効率を向上させるためのさらなる最適化方法を検討するなど、これらの指標を改善する必要があります。
シミュレーションテストエンジン
サービス バージョンのアップグレード、SQL エンジン パラメーターの最適化、クラスターの移行などのシナリオでは、データ処理の精度と一貫性を確保するためにビジネス データに対してテストを再実行することが必要になることがよくあります。従来の再実行テスト方法は、ビジネス担当者が手動で設計および実装することに依存しており、多くの場合非効率的です。
Pilot のシミュレーション デュアル実行ツールは、上記の問題点を解決できます。当社では、このツールをサービスとして独立して提供し、より一般的なシミュレーション テスト エンジンに変換して、ユーザーがデュアル実行タスクを迅速に構築し、自動対数を実行できるようにする予定です。