記事ディレクトリ
1. トレースの概要
前回の記事は、サービスのボトルネック点を見つけて最適化したpprofパフォーマンス分析でした。Golang の pprof パフォーマンス分析pprof
通常、pprofこれはprofileサービスのパフォーマンス、主にCPU時間のかかる側面と呼び出しリンクを分析するために使用されます。しかし、それだけに頼るだけでprofileは十分ではなく、詳細に関しては、同時実行性やブロックイベント、スケジュール、条件traceの分析を使用する必要があります。goroutineGC
それに比べてprofile、traceそれを通して何が見えるでしょうか?
1、程序运行中的goroutine数量分布
2、GC的频率和Heap的占比
3、goroutine的调度和运行,阻塞情况
2. トレースの使い方
コード内のトレース収集
import (
"os"
"runtime/trace"
)
func main() {
trace.Start(os.Stderr)
defer trace.Stop()
}
// 生成trace
go run main.go 2> trace.out
によって収集されました
// trace采样
浏览器下载: http://127.0.0.1:6060/debug/pprof/trace?seconds=20
命令行采样: curl http://127.0.0.1:6060/debug/pprof/trace\?seconds\=20 > trace.out
// 运行采样的trace文件,会自动打开浏览器页面
go tool trace trace.out
3、トレース分析の詳細
Webインターフェイスをトレースする
参考:Goキラーの追跡解析トレース
https://eddycjy.gitbook.io/golang/di-9-ke-gong-ju/go-tool-trace
View trace:查看跟踪
Goroutine analysis:Goroutine 分析
Network blocking profile:网络阻塞概况
Synchronization blocking profile:同步阻塞概况
Syscall blocking profile:系统调用阻塞概况
Scheduler latency profile:调度延迟概况
User defined tasks:用户自定义任务
User defined regions:用户自定义区域
Minimum mutator utilization:最低 Mutator 利用率
トレースで注意が必要なこと
GCの頻度に注意する
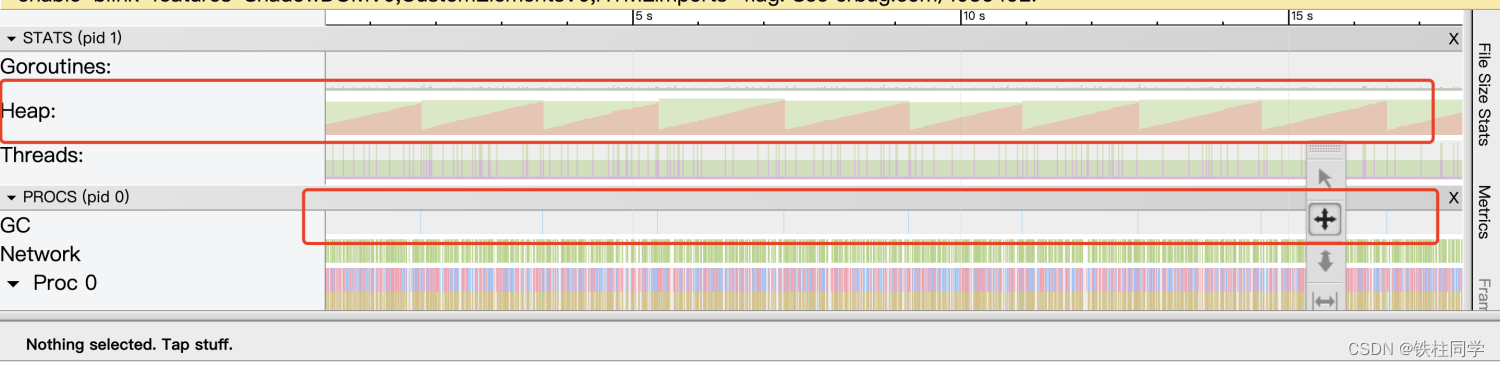
GCGC頻度が高すぎると、ステージに大量のリソースが使用され、プログラムのパフォーマンスに影響します。また、Heapリリース状況にも注意が必要で、をHeap経てリリースしないとGCメモリリークの問題にも注意が必要です。メモリ リークのほとんどは、goroutineリリースとサービスのメモリ使用量を確認するために行われます。Golangの pprof パフォーマンス分析を参照できます。
goroutineのスケジューリングに注意する
マウスが動かないと、wズームインまたはsズームアウトされます。常にズームインして、特定のgoroutine実行の詳細を確認します。

ゴルーチンの数に注意してください
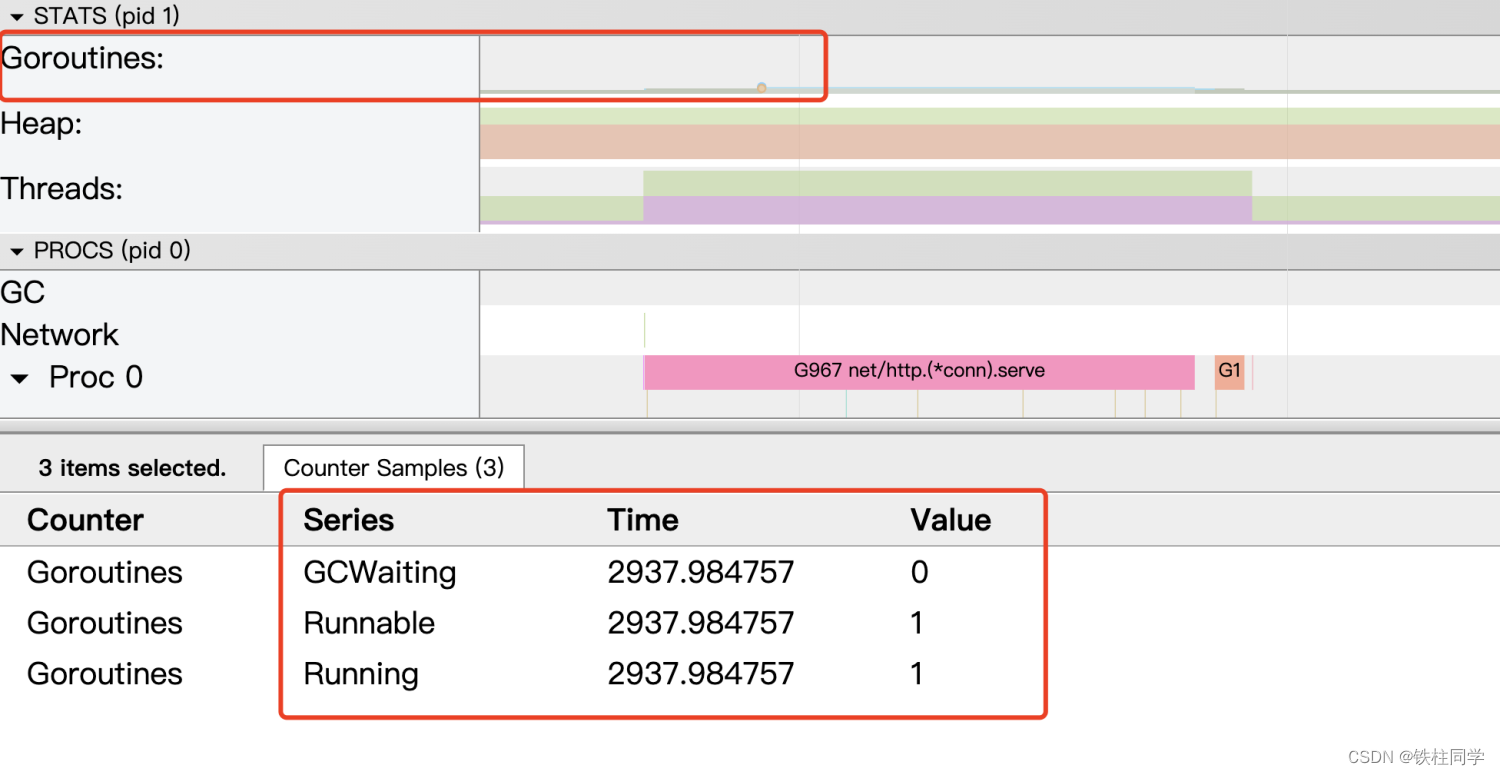
理想的な状況
1、GC次数适中,要多或者太小都不行
2、goutinue数量不会突增或者持续增加
3、goroutine的调度密集且有规律
以下は、GCあまりにも頻繁に起こる例です。goroutineスケジュールが適切で、定期的かつ集中的である
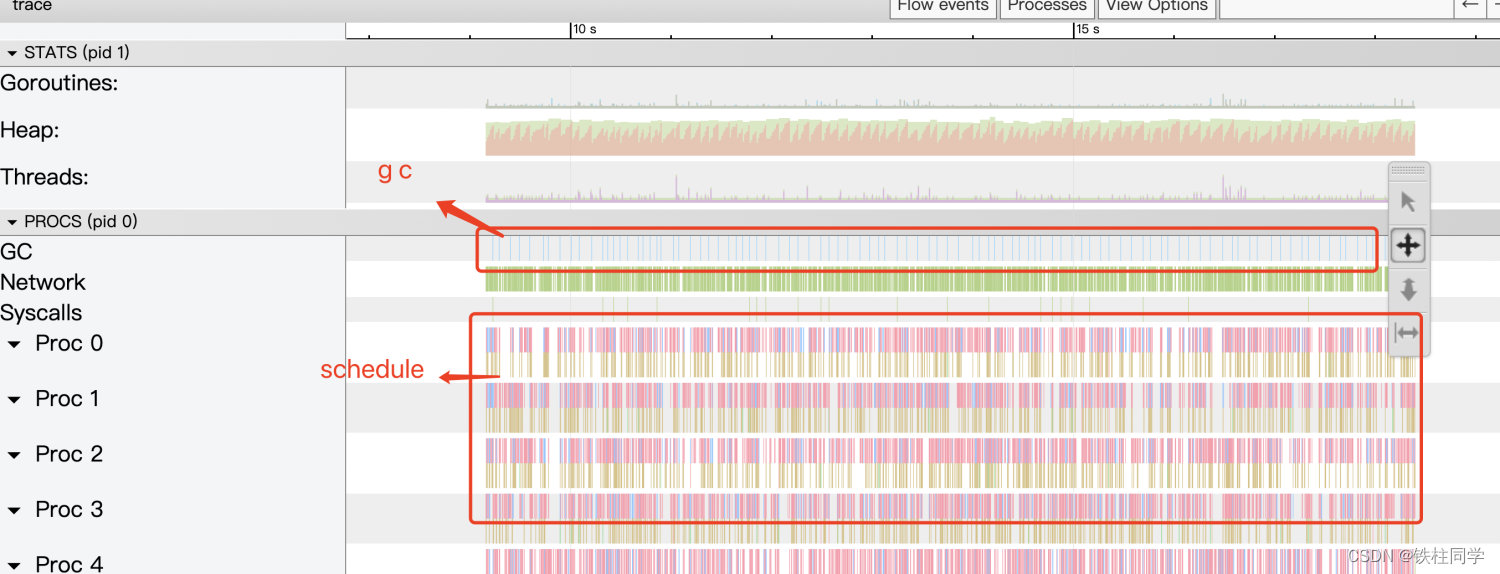
4. GC分析
現在のサービス GC の状況

非常に頻繁に見られますGC。モニタリングを確認すると、サービス メモリが数十 M しか使用していないことがわかります。

GCこの場合、しきい値は手動でのみ変更できます。
GOGC 变量设置初始垃圾收集目标百分比。当新分配的数据与上次收集后剩余
的实时数据的比率达到此百分比时,将触发收集。
默认值为 GOGC=100。
比如上次gc之后剩余10M,那么下次GC的阈值就是10M+10*100% = 20M
GOGCをセットアップする
// 调整gc阈值的源码
func readGOGC() int32 {
p := gogetenv("GOGC")
if p == "off" {
return -1
}
if n, ok := atoi32(p); ok {
return n
}
return 100
}
環境変数を設定しGOGC、以下を確認しますtrace。

GOMEMLIMIT を設定する
GOGCこれはプログラムで設定されています3000が、実際にはメモリ使用率は依然として非常に低く、200Mサービスによって提供されるリソースのみが使用されます4G。

GOMEMLIMIT : 设置GC的阈值(go 1.19提供),设置为服务限定资源的一半
GOGC=off : 关闭自动GC。
効果は次のとおりです。

GC しきい値の議論
参考:GCの公式詳細説明
GCの特徴
1、当 GC 在标记和清除阶段之间转换时,短暂的 stop-the-world 暂停,
2、调度延迟,因为在标记阶段GC占用了25%的CPU资源,
3、用户 goroutines 协助 GC 响应高分配率,
4、当 GC 处于标记阶段时,指针写入需要额外的工作,并且
5、运行的 goroutines 必须暂停以扫描它们的根。
多すぎるとリソースがGC取られてしまいます。ただし、少なすぎると、マークしてクリアするメモリが多すぎるため、毎回の時間が長くなります。したがって、しきい値をどの程度の大きさに設定するかも選択式の質問になります。CPUgoroutineGCGCstwGC
5、ゴルーチン解析
ゴルーチンの概要
拡大すると、はいgoroutine、はい、の様子が わかります。マーキングされた状態のものもあります。DedicatedIdlemarksweep

GC3 つの主なフェーズ: mark(マーク)、sweep(スイープ)、scan(スキャン)。まあ、それはステレオタイプのエッセイと完全に一致します。
赤枠の中にも有名人がいますSTW。
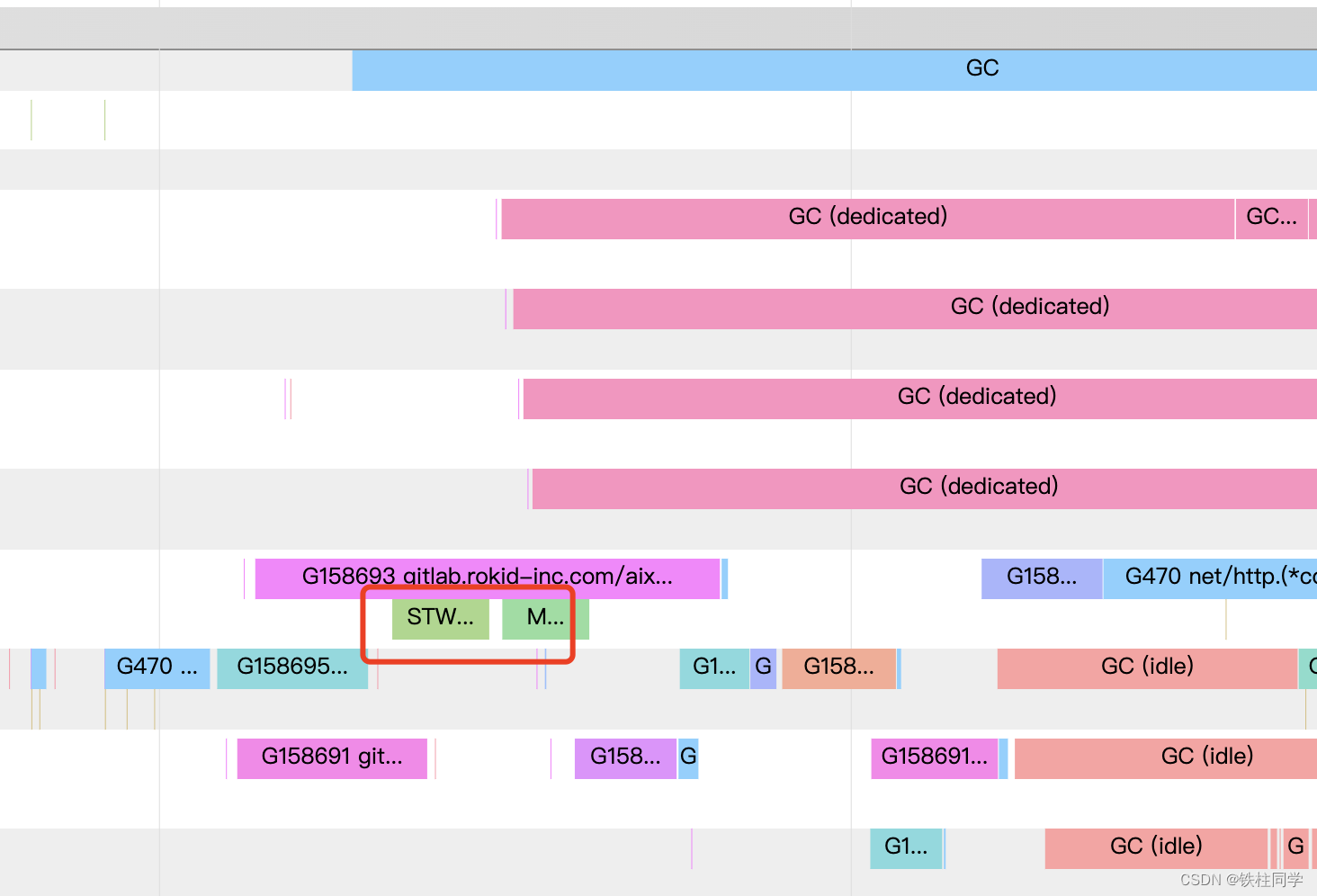
标记阶段会将大概25%(gcBackgroundUtilization)的P用于标记对象,
逐个扫描所有G的堆栈,执行三色标记,在这个过程中,所有新分配的对象
都是黑色,被扫描的G会被暂停,扫描完成后恢复,这部分工作叫
后台标记(gcBgMarkWorker)。
这会降低系统大概25%的吞吐量,比如MAXPROCS=6,那么GC
P期望使用率为6*0.25=1.5,这150%P会通过专职(Dedicated)/
兼职(Fractional)/懒散(Idle)三种工作模式的Worker共同来完成。
同期ブロックの時間のかかる分析
クリックするtraceとメインリストが表示されます。goroutine analysisgoroutine

クリックすると、特定のgoroutine実装が表示されます。

クリックして表示しgoroutine、trace次の情報を見つけます。
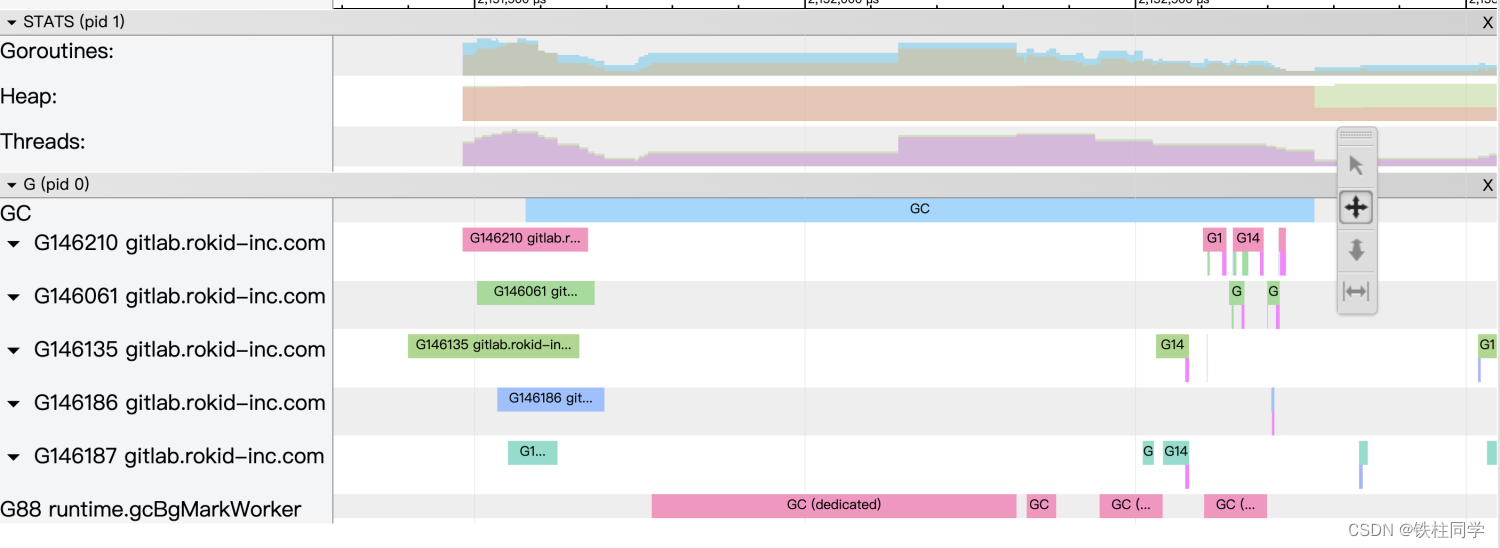
フルタイムのGC 処理作業モードに146210入っている ようです。時間がかかっているものをいくつか確認すると、すべてその時点で処理を開始し、業務処理を中断し、終了後も業務を実行し続けます。最適化後は、消費時間が大幅に短縮されます。goroutineDedicatedSync blockGCgoroutineGCGCGCSync block
スケジューラー待機時間の分析
多数あるのはScheduler wait次のとおりです。
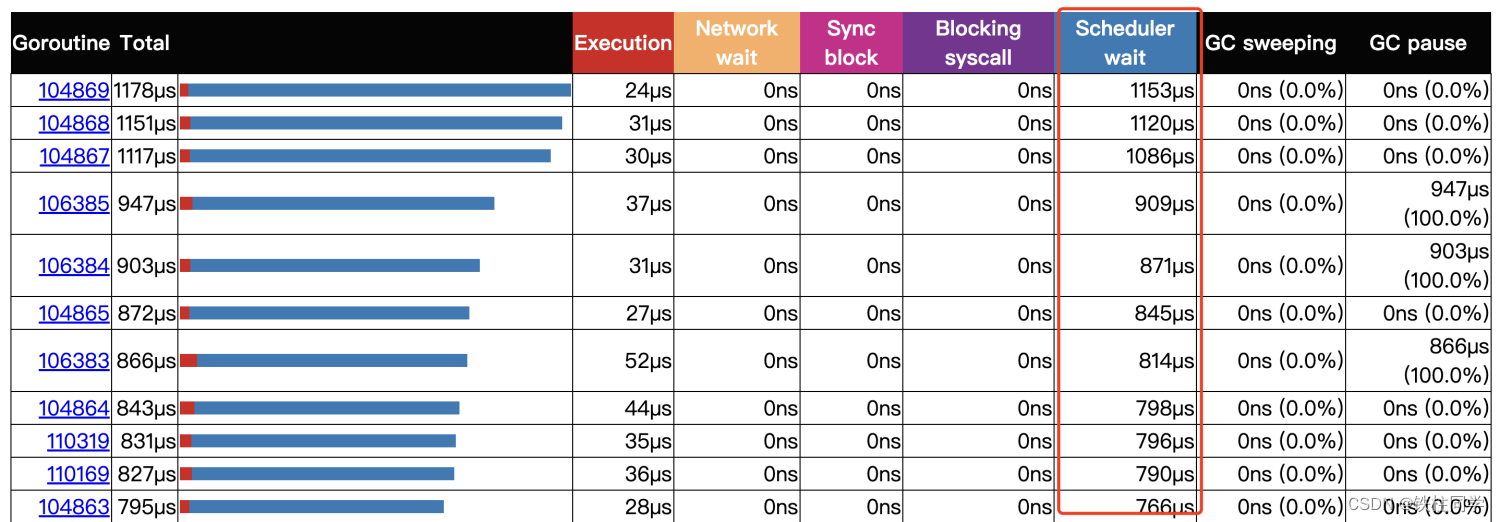
スケジューリングに関しては、モデルのスケジューリングGoであるため、パラメーターのサイズと量がスケジューリングのパフォーマンスに影響することは 誰もが知っています。自動セットアップに推奨されるライブラリ。maxprocs を自動的に設定するための Uber のオープンソース ライブラリ注:サービス割り当て用のコアが不十分な場合、使用率は改善されません。代わりに、マルチコアの場合は、このライブラリを使用して最適な設定を行う必要があります。GMPPgoroutineuberGOMAXPROCS
CPU1automaxprocsGOMAXPROCS
終わり