ランダム フォレストの入門
デシジョン ツリーについては、「デシジョン ツリーの概要」、「sklearn の実装」、「原理の解釈とアルゴリズム分析」で詳しく説明されていますが、考慮されるデシジョン ツリーは 1 つだけです。諺にあるように、三人の靴屋の中で最も優れているのは諸葛孔明です。この記事では、複数の決定木、つまりランダム フォレストを組み合わせることにより、モデルの効果をさらに向上させる方法を検討します。
ランダム フォレスト アルゴリズムの背後にある原理を理解するために、まず、非常に単純ですが非常に興味深い例を見てみましょう。被告が有罪かどうかを判断する必要がある裁判官は 3 人おり、最終的な判決結果は、判決に従う少数者によって決定されます。多数。
各ジャッジが正しい確率をppと仮定します。p、裁判官が 1 人だけの場合、その裁判官が正しい確率はppうp。
裁判官の数が 3 人に増えると、最終的な判決が正しい状況は 2 つあります。1 つは 3 人の裁判官全員が正しい場合、もう 1 つは 1 人の裁判官だけが間違っており、他の 2 人が正しい場合です。その合計確率は
p 3 + 3 p 2 ( 1 − p ) p^3+3p^2(1-p)です。p3+3P _2 (1−p )
3 人のジャッジが正解する確率が 1 人のジャッジが正解する確率よりも高い場合にのみ、ジャッジの数を増やす意味があります このとき、 p 3 + 3 p 2 ( 1 − p
) > pp^3+3p ^2( 1-p)>pp3+3P _2 (1−p )>p
を単純化して
p ( p − 1 ) ( p − 0.5 ) < 0 p(p-1)(p-0.5)<0 をp ( p−1 ) ( p−0.5 )<pp
なので0pの基本的な制約は0 ≤ p ≤ 1 0≤p≤10≤p≤1を上記の式と組み合わせると、制約を
0.5 < p < 1 0.5 < p < 1に変更できます。0.5<p<1
つまり、単位判定員の正判定確率が0.5を超える限り、判定員の数を増やせばさらに正判定確率を高めることができる。
上記の導出プロセスでは、確率制約に加えて、他の 2 つの制約が暗示されます: (1) 裁判官は互いに独立して独立した判断を行い、これは 3 人の裁判官の正しい判断の確率を計算するための基本前提です。裁判官が意図的に犯罪者をかばうと、意図的に間違った判決を下す可能性があるため、オブジェクトには共通の目的があります。
実際、この状況を説明する定理がすでに存在します。コンドルセの陪審定理です。奇数の人々 (モデル) が、未知の世界状態を真または偽として分類します。各人 (モデル) が正しく分類される確率はp > 0.5 p>0.5p>0.5であり、1 人 (モデル) が正しく分類される確率は、他の人 (モデル) の分類の正しさとは統計的に独立しています。この定理は、「多数決が正しい確率は、どの人 (モデル) よりも高い。人数 (モデル番号) が十分に大きくなると、多数決の正解率は に近くなる」と説明できます。 100%。
ランダムフォレストの構築
コンドルセの陪審定理をランダム フォレスト アルゴリズムに適用します。複数のツリーが互いに独立しており、各ツリーが正しく予測する確率が 0.5 を超える限り、ランダム フォレスト アルゴリズムの効果は単一の決定ツリーの効果よりも優れている可能性があります。 。
ランダムな推測の正解確率がすでに 0.5 であるため、単一の決定木の予測の正解確率は 0.5 を超えます。トレーニング セットを学習した後は、正しい判断の確率が 0.5 を超えることが期待できます。
複数のツリーを互いに独立させる方法は次のとおりです。
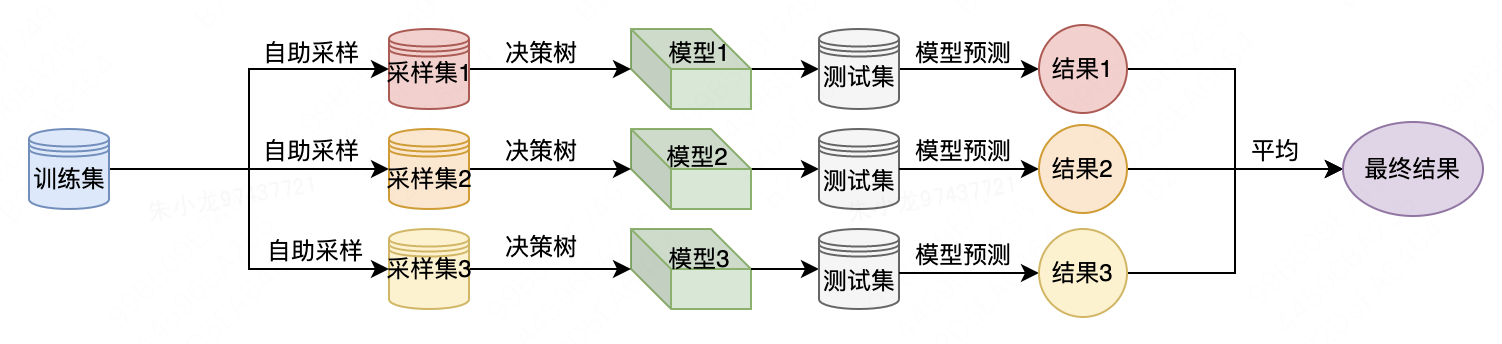
(1) ブートストラップ サンプル戦略を通じて、異なる独立したデータ セットを生成します。具体的なプロセスは次のとおりです。元のデータ セットからサンプルを置換してランダムにサンプリングすることを繰り返します (つまり、同じサンプルを複数回抽出できます)。抽出の数は元のデータ セットの数と同じです。元のデータ セットと同じサイズのデータ セットが作成されますが、一部のデータ ポイント (約 37%) が欠落し、一部は繰り返されます。
(2) 新しく作成したデータセットに基づいてデシジョン ツリーを構築しますが、デシジョン ツリーの概要で説明したアルゴリズムをわずかに変更します。各ノードで、アルゴリズムは、すべてのノードに対して最適なテストを見つけるのではなく、機能のサブセットをランダムに選択し、機能の 1 つに対して最適なテストを見つけます。選択される特徴の数は、max_features パラメーターによって制御されます。各ノードでの特徴のサブセットの選択は相互に独立しているため、ツリーの各ノードは決定を行うために特徴の異なるサブセットを使用できます。
ブートストラップ サンプリングを使用しているため、ランダム フォレスト内の各デシジョン ツリーはわずかに異なるデータセットから構築されます。各ノードでの特徴選択により、各ツリー内の各分割は特徴の異なるサブセットに基づきます。これら 2 つの手順を組み合わせることで、ランダム フォレスト内のすべてのツリーが一意であり、互いに独立していることが保証されます。
ランダム フォレストを使用して予測を行うには、まずフォレスト内の各ツリーに対して予測を行う必要があります。その後、回帰問題については、これらの結果を最終予測として平均化します。分類問題の場合、「ソフト投票」戦略が使用されます。つまり、各アルゴリズムは、考えられる各出力ラベルの確率を考慮して「ソフト」予測を行い、すべてのツリーにわたる予測確率を平均し、最も高い確率を持つクラスを予測として採用します。
以下は、ランダム フォレストを使用して予測問題を解決する場合のフローチャートです。
ランダムフォレストのパフォーマンス
まずはランダムフォレストと各決定木の結果を可視化して見てみましょう。以下はsklearnパッケージを使用した実装コードです。
import mglearn.plots
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from data import two_moons
if __name__ == '__main__':
X, y = two_moons.two_moons()
# 数据集拆分
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 创建一个随机森林分类器,包含 5 棵树,随机种子为 2
forest = RandomForestClassifier(n_estimators=5, random_state=2)
# 使用训练数据拟合模型
forest.fit(X_train, y_train)
# 创建一个 2x3 的图像,用于显示每棵树的分割情况
fig, axes = plt.subplots(2, 3, figsize=(20, 10))
# 遍历每棵树,显示其分割情况
for i, (ax, tree) in enumerate(zip(axes.ravel(), forest.estimators_)):
ax.set_title('Tree {}, score {:.2f}'.format(i, forest.estimators_[i].score(X_train, y_train)))
# 绘制决策树
mglearn.plots.plot_tree_partition(X_train, y_train, tree, ax=ax)
# 在最后一个子图中显示整个随机森林的决策边界
mglearn.plots.plot_2d_separator(forest, X_train, fill=True, ax=axes[-1, -1], alpha=0.4)
axes[-1, -1].set_title('Random Forest, , score {:.2f}'.format(forest.score(X_train, y_train)))
# 在前两个子图中显示训练数据的散点图
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
コードを実行すると、次の図が得られます。ランダム フォレスト モデルの結果は、個々のデシジョン ツリーよりも視覚的に優れています。スコアの観点から見ると、5 つのデシジョン ツリーの値はそれぞれ 0.88、0.93、0.93、0.95、0.84 ですが、ランダム フォレストではスコアがさらに 0.96 に向上します。

機能の重要性の計算は非常に簡単で、コードは 1 行だけです。
forest.feature_importances_
以下は出力です
array([0.38822127, 0.61177873])
単一の決定木を使用して解決する場合、重要度の値はそれぞれ 0.1478 と 0.2138 であると当時述べました。
かなり差があるように見えますが、実は当時重要度の値が正規化されていなかったためです。正規化後の最初の特徴の重要度値は次のようになります:
0.1478 / ( 0.1478 + 0.2138 ) = 0.4087 0.1478 / (0.1478 + 0.2138)= 0.40870.1478/ ( 0.1478+0.2138 )=0.4087
2 番目の特徴の重要度の値は次のとおりです:
0.2138 / ( 0.1478 + 0.2138 ) = 0.5913 0.2138 / (0.1478 + 0.2138) = 0.59130.2138/ ( 0.1478+0.2138 )=0.5913
現在、2 つの方法の差はそれほど大きくないようです。
ランダムフォレストの特徴
本質的に、ランダム フォレストにはデシジョン ツリーの利点がすべて備わっています。また、モデルの学習処理において、各決定木の学習を並行して実行できるため、学習効率が向上します。
調整する必要がある重要なパラメータは、n_estimators と max_features です。n_estimators はデシジョン ツリーの数を指しますが、常に良いほうです。より多くのツリーを平均すると過剰適合が減少し、より堅牢な予測モデルが得られます。ただし、利益は減少しており、ツリーの数が増えると、より多くのメモリとより長いトレーニング時間が必要になります。一般的な経験則は、「時間/メモリが許す限り」です。
max_features は、各デシジョン ツリーで使用される特徴の数を指します。max_features を小さくすると、過剰適合を減らすことができます。一般に、デフォルトを使用するのが良い経験則です。分類の場合、デフォルトは max_features=sqrt(n_features) であり、回帰の場合、デフォルトは max_features=n_features です。