CV - コンピューター ビジョン | ML - 機械学習 | RL - 強化学習 | NLP 自然言語処理
科目: 履歴書
1.視覚言語の事前トレーニングのベースラインの改善

タイトル: 視覚言語の事前トレーニングのベースラインの改善
エンリコ・フィニ、ピエトロ・アストルフィ、アドリアナ・ロメロ=ソリアーノ、ヤコブ・フェルベーク、ミハル・ドロズツァル
記事リンク: https://arxiv.org/abs/2305.08675
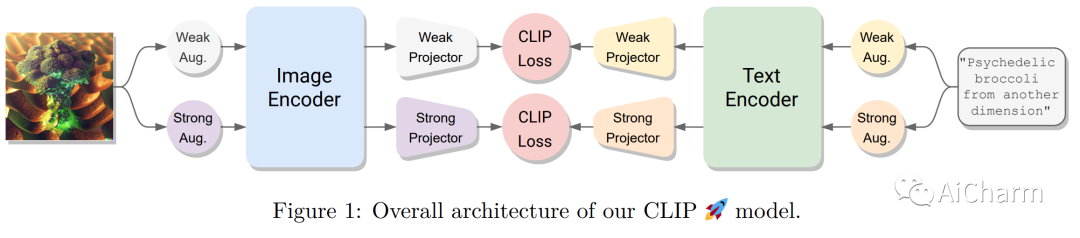

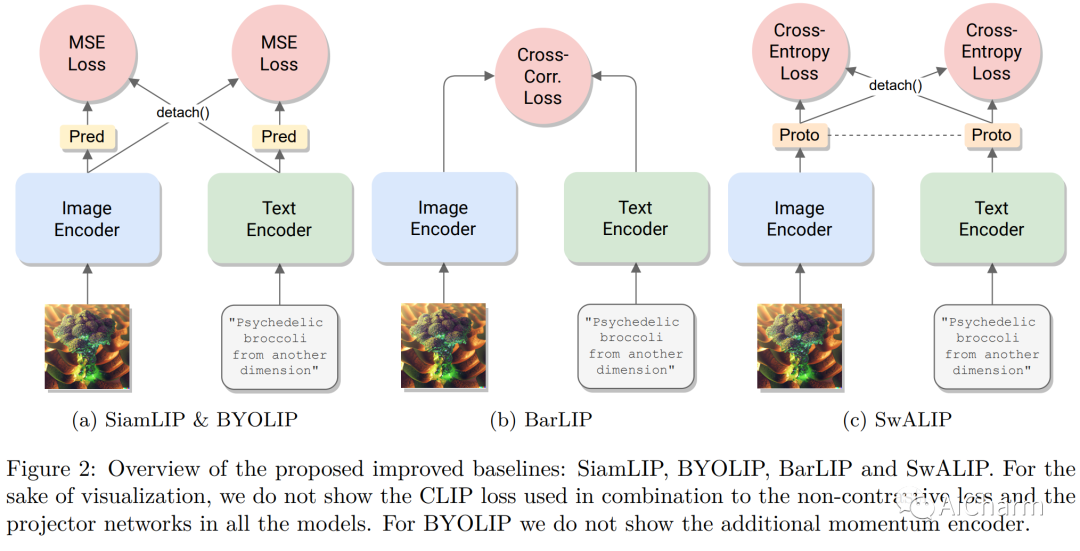

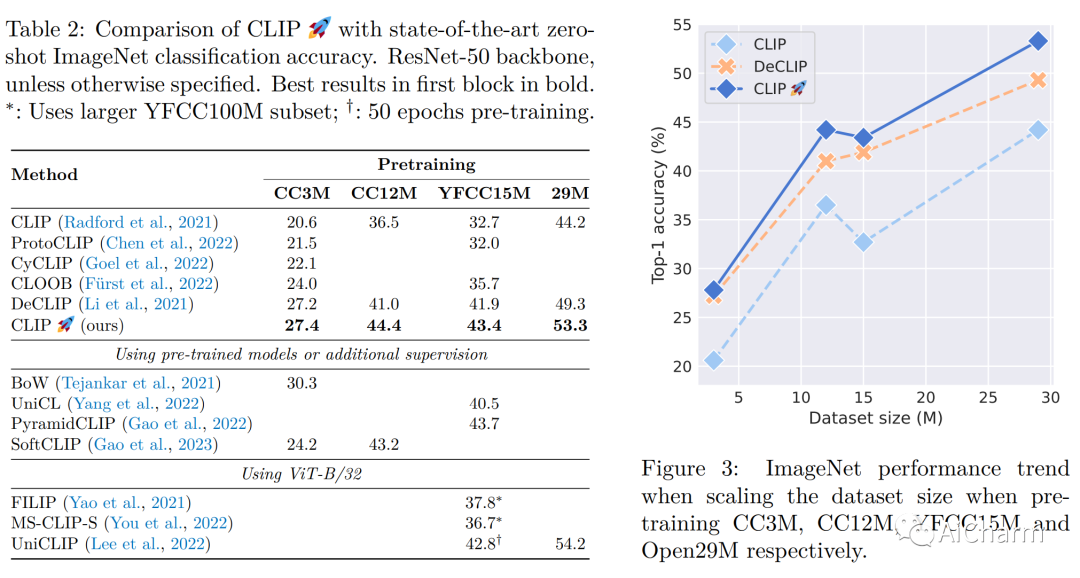
まとめ:
対照学習は、マルチモーダル表現を学習するための効果的なフレームワークとして登場しました。CLIP は、この分野で独創的な作品であり、コントラスト損失を使用して画像とテキストのペアのデータをトレーニングすることで印象的な結果を達成しました。最近の研究では、自己教師あり学習に触発された非対照的な損失を追加して CLIP を改善すると主張しています。ただし、これらの追加損失の寄与を、モデルのトレーニングに使用される他の実装の詳細 (データ拡張や正則化手法など) から分離することが難しい場合があります。この疑問を明らかにするために、この論文ではまず、対照学習と最近の自己教師あり学習の進歩を組み合わせることによって得られるいくつかのベースラインを提案、実装、評価します。特に、視覚的な自己教師あり学習で成功していることが証明されている損失関数を使用して、画像とテキストのモダリティを調整します。これらのベースラインは CLIP の基本的な実装よりも優れたパフォーマンスを発揮することがわかりました。ただし、より強力なトレーニング方法を使用すると、この利点は失われます。実際、他のサブフィールドで普及しているよく知られたトレーニング手法を使用すると、単純な CLIP ベースラインも大幅に改善でき、ダウンストリームのゼロショット タスクでは相対的に最大 25% 改善できることがわかりました。さらに、画像とテキストの拡張を適用するだけで、以前の研究で得られた改善のほとんどを十分に補うことができることがわかりました。改良された CLIP トレーニング方法により、4 つの標準データセットで最先端のパフォーマンスを達成し、以前の作業を一貫して上回り (最大のデータセットで最大 +4%)、よりシンプルになりました。
件名: cs.CL
2.ArtGPT-4: アダプター強化 MiniGPT-4 による芸術的視覚言語理解

タイトル: ArtGPT-4: アダプター強化 MiniGPT-4 を使用した芸術的視覚言語理解
著者: Zhengqing Yuan、Huiwen Xue、Xinyi Wang、Yongming Liu、Zhuanzhe Zhao、Kun Wang
記事リンク: https://arxiv.org/abs/2305.07490
プロジェクトコード: https://huggingface.co/Tyrannosaurus/ArtGPT-4
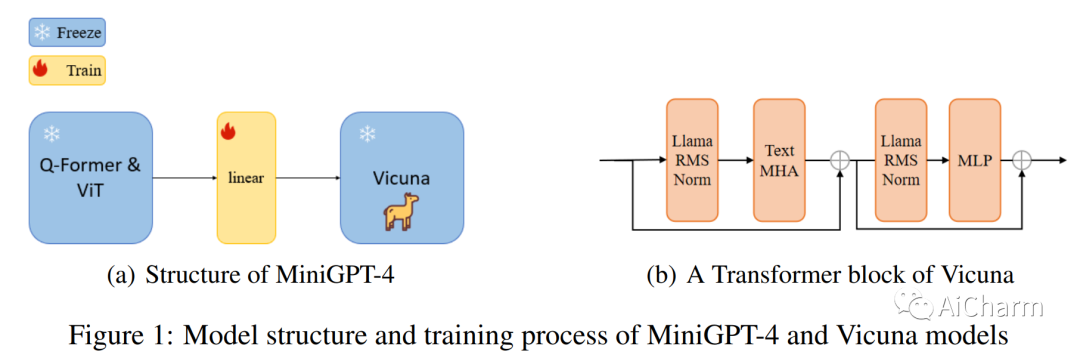
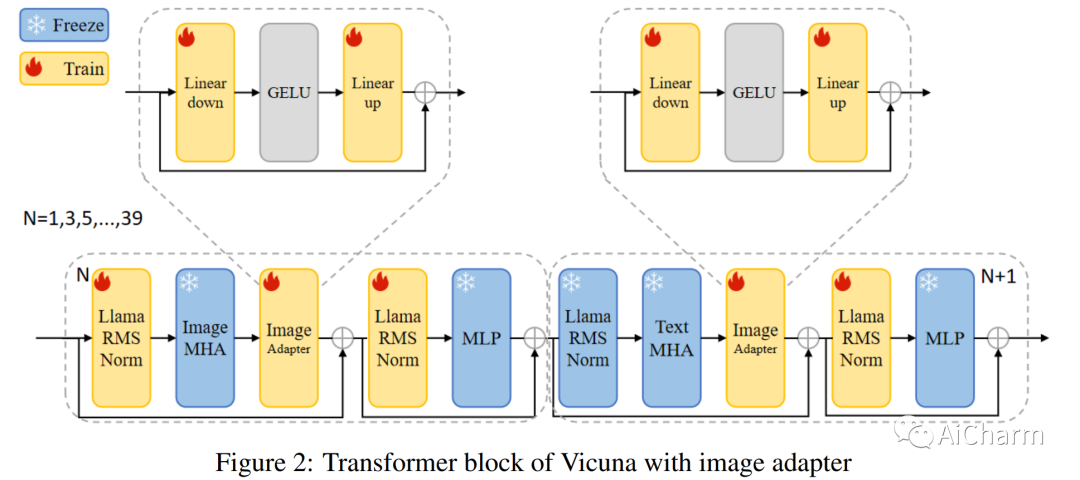



まとめ:
近年、大規模言語モデル (LLM) は自然言語処理 (NLP) において大幅な進歩を遂げており、ChatGPT や GPT-4 などのモデルはさまざまな言語タスクにおいて優れた機能を実現しています。ただし、このような大規模なモデルのトレーニングは困難であり、モデルのサイズに一致するデータセットを見つけるのが困難なことがよくあります。新しい方法を使用して、より少ないパラメータでモデルを微調整およびトレーニングすることは、これらの課題を克服するための有望なアプローチとして浮上しています。MiniGPT-4 は、新しい事前トレーニング済みモデルと革新的なトレーニング戦略を利用することで、GPT-4 に匹敵する視覚言語理解を達成するモデルの 1 つです。ただし、このモデルは、特に芸術的な画像の場合、画像の理解において依然としていくつかの課題に直面しています。これらの制限に対処するために、ArtGPT-4 と呼ばれる新しいマルチモーダル モデルが提案されています。ArtGPT-4 は、Tesla A100 デバイスを使用し、わずか約 200 GB のデータを使用して、画像とテキストのペアでわずか 2 時間でトレーニングされました。このモデルは芸術的なイメージを表現し、美しい HTML/CSS Web ページを含むビジュアル コードを生成できます。さらに、この論文では、視覚言語モデルのパフォーマンスを評価するための新しいベンチマークを提案します。その後の評価方法では、ArtGPT-4 のスコアは、現在の \textbf{最先端} モデルより 1 ポイント以上高く、6 ポイント スケールで Artist よりわずか 0.25 ポイント低いだけです。
3.StructGPT: 構造化データを推論するための大規模言語モデルの一般的なフレームワーク

タイトル: StructGPT: 構造化データ上の大規模な言語モデルについて推論するための一般的なフレームワーク
著者: Jiazheng Xu、Xiao Liu、Yuchen Wu、Yuxuan Tong、Qinkai Li、Ming Ding、Jie Tang、Yuxiao Dong
記事リンク: https://arxiv.org/abs/2305.09645
プロジェクトコード: https://github.com/RUCAIBox/StructGPT
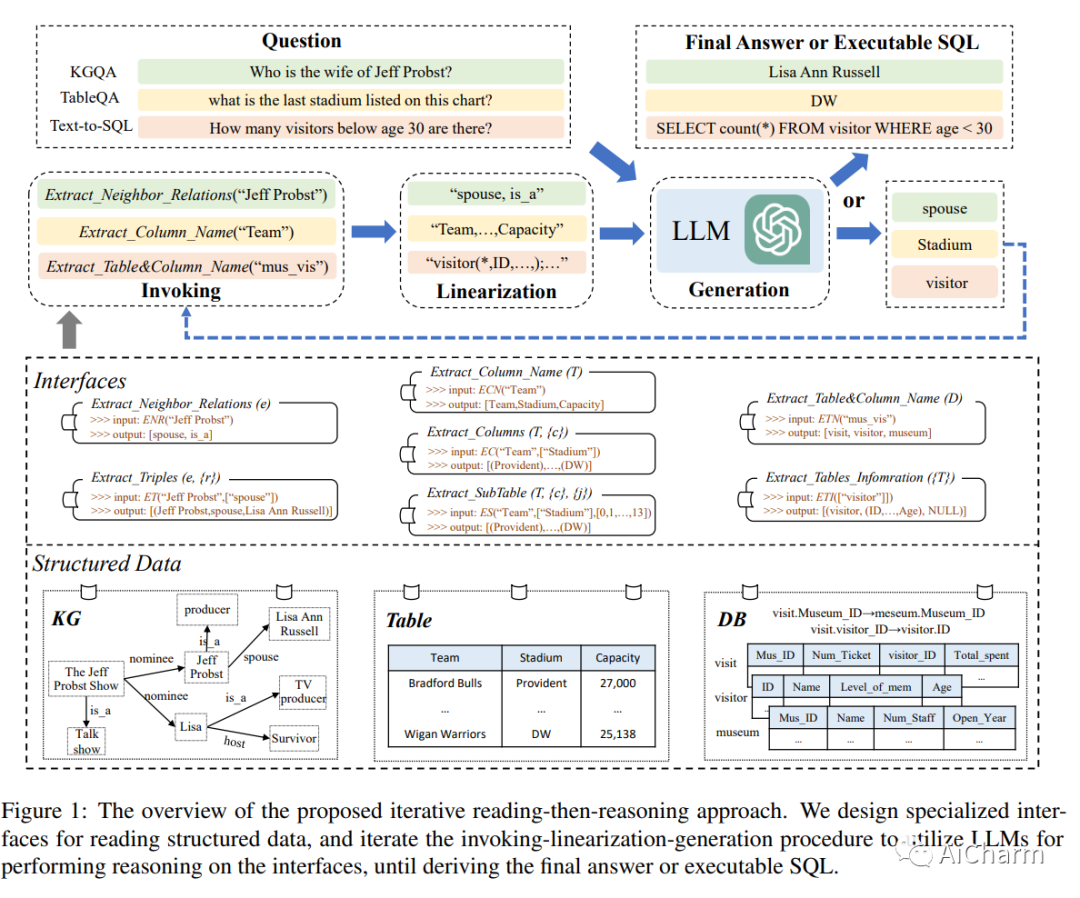

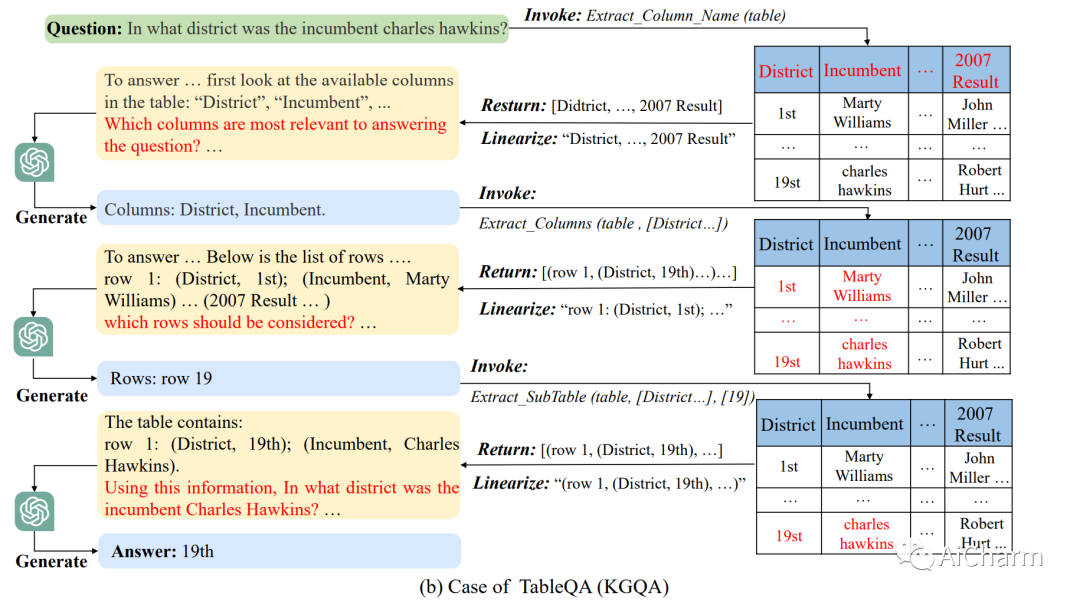

まとめ:
この論文では、構造化データ上の大規模言語モデル (LLM) のゼロショット推論機能を統合された方法で向上させる方法を調査します。LLM ツール拡張研究に触発され、StructGPT と呼ばれる、構造化データに基づいて質問応答タスクを解決するための Iterative Reading-then-Reasoning~ (IRR) メソッドを開発しました。私たちのアプローチでは、構造化データから関連する証拠を収集 (読み取り) するための特殊な機能を構築し、収集された情報 (推論) に基づいて LLM に推論タスクを集中させます。特に、外部インターフェイスの助けを借りて構造化データに対する LLM 推論をサポートする呼び出し線形化生成プロセスを提案します。提供されたインターフェイスを使用してこのプロセスを繰り返すことにより、このメソッドは特定のクエリに対する目標の答えに徐々に近づくことができます。3 種類の構造化データに関する広範な実験により、ChatGPT のパフォーマンスを大幅に向上させ、フルデータ監視チューニング ベースラインと同等のパフォーマンスを達成できるこの方法の有効性が実証されました。
Aiの詳細情報:Princess AiCharm