CV - コンピューター ビジョン | ML - 機械学習 | RL - 強化学習 | NLP 自然言語処理
件名: cs.CV
1.DreamPose: 安定拡散によるファッション画像からビデオへの合成

タイトル: DreamPose: 安定化拡散によるスタイリッシュな画像からビデオへの合成
作说:ヨハンナ・カラス、アレクサンダー・ホリンスキー、ティン=チュン・ワン、アイラ・ケメルマッハー=シュライザーマン
記事リンク: https://arxiv.org/abs/2304.06025
プロジェクト コード: https://grail.cs.washington.edu/projects/dreampose/
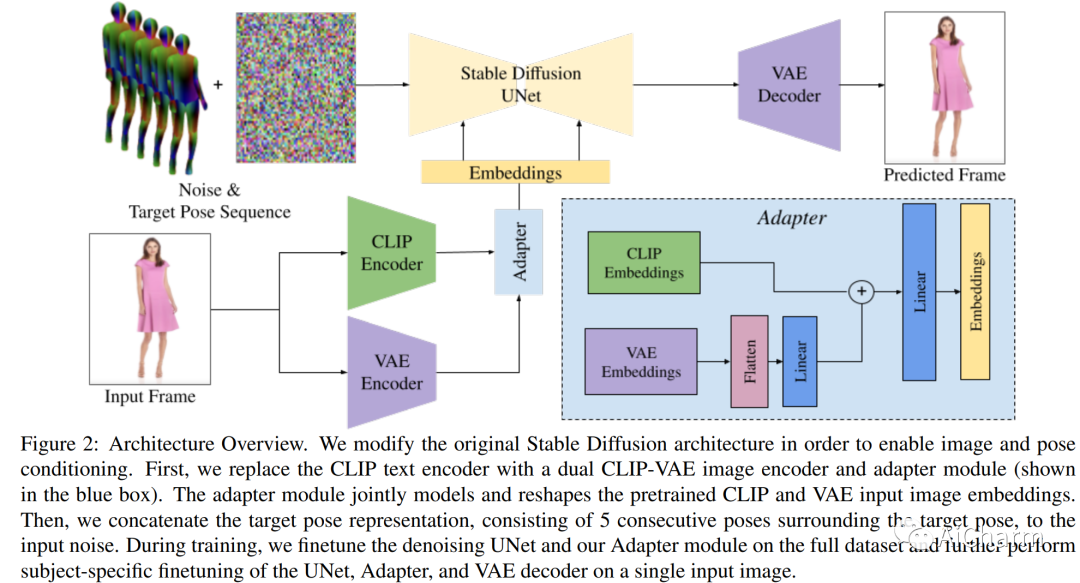
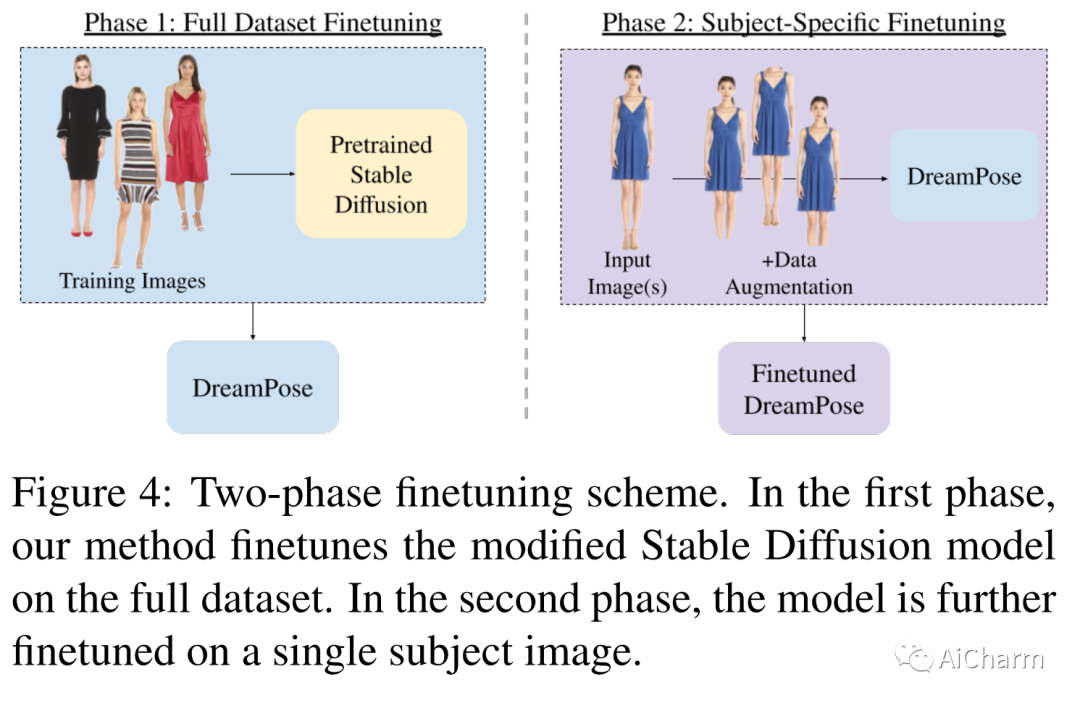


まとめ:
静止画像からアニメーション化されたファッション ビデオを生成するための拡散ベースの方法である DreamPose を紹介します。画像と一連の人間のポーズが与えられると、私たちの方法は、人間と布地の両方の動きを含むビデオを合成します。これを実現するために、事前トレーニング済みのテキストから画像へのモデル (安定した拡散) を、新しい微調整戦略、追加されたコンディショニング信号をサポートするための一連のアーキテクチャ変更を使用して、ポーズおよび画像ガイド付きのビデオ合成モデルに変換します。一時的な一貫性を促進する手法。UBC Fashion データセットからのファッション ビデオのコレクションを微調整します。さまざまな服装スタイルとポーズでこの方法を評価し、この方法がファッション ビデオ アニメーションで最先端の結果を生み出すことを示します。動画の結果は、プロジェクト ページでご覧いただけます。
2.レイアウトガイド画像生成のための診断ベンチマークと反復修復
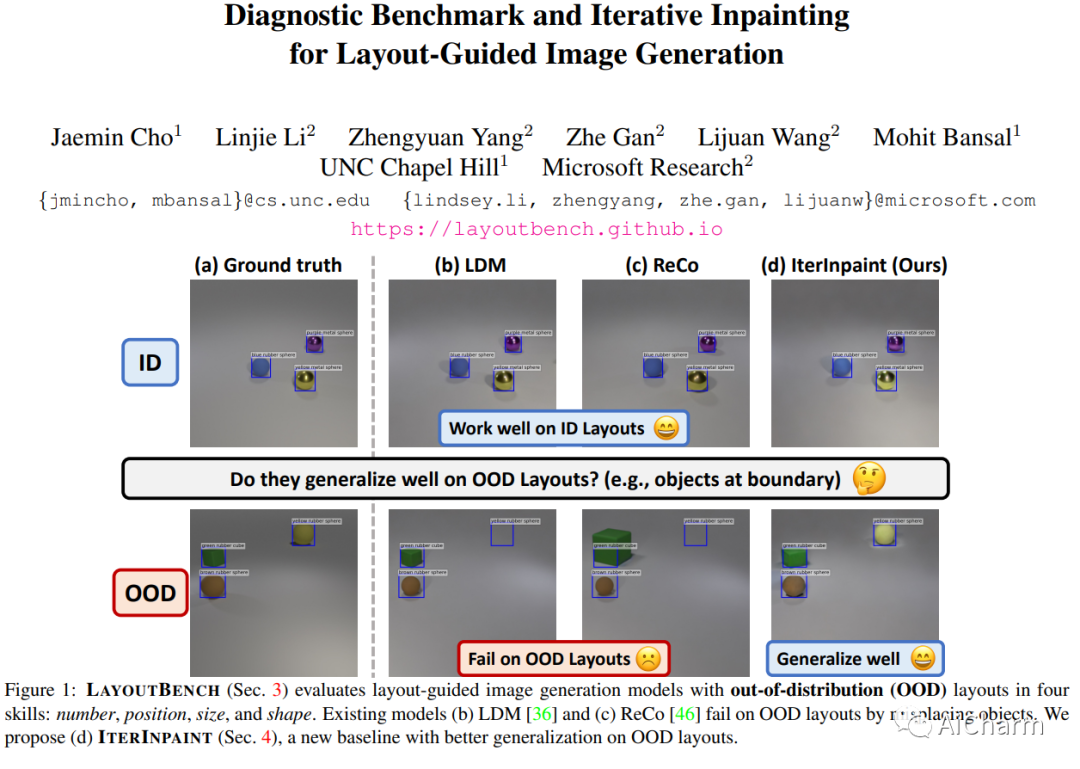
タイトル: レイアウト ガイド付き画像生成のための診断ベンチマークと反復修復
著者: Jaemin Cho, Linjie Li, Zhengyuan Yang, Zhe Gan, Lijuan Wang, Mohit Bansal
記事リンク: https://arxiv.org/abs/2304.06671
プロジェクトコード: https://layoutbench.github.io/
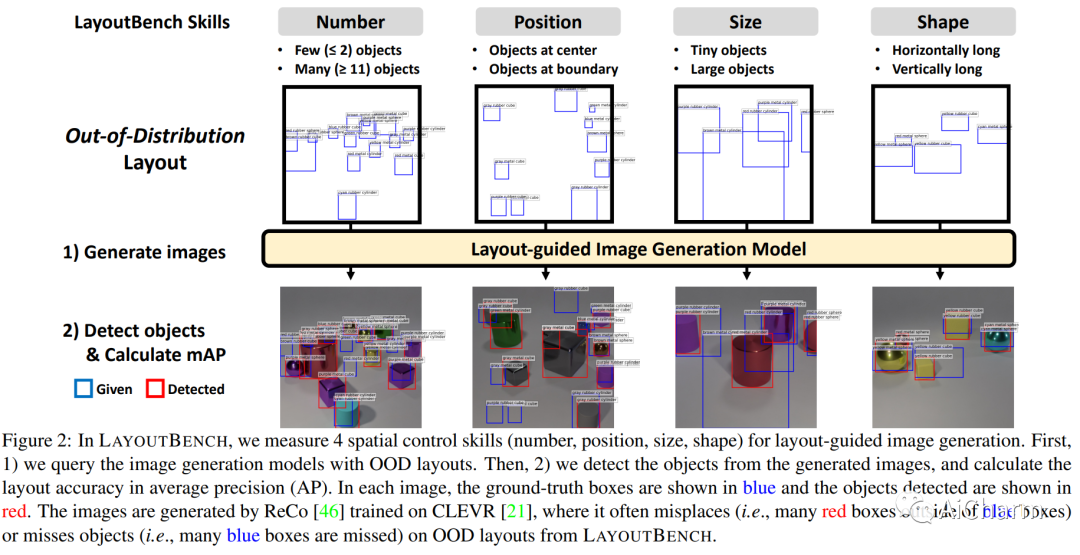

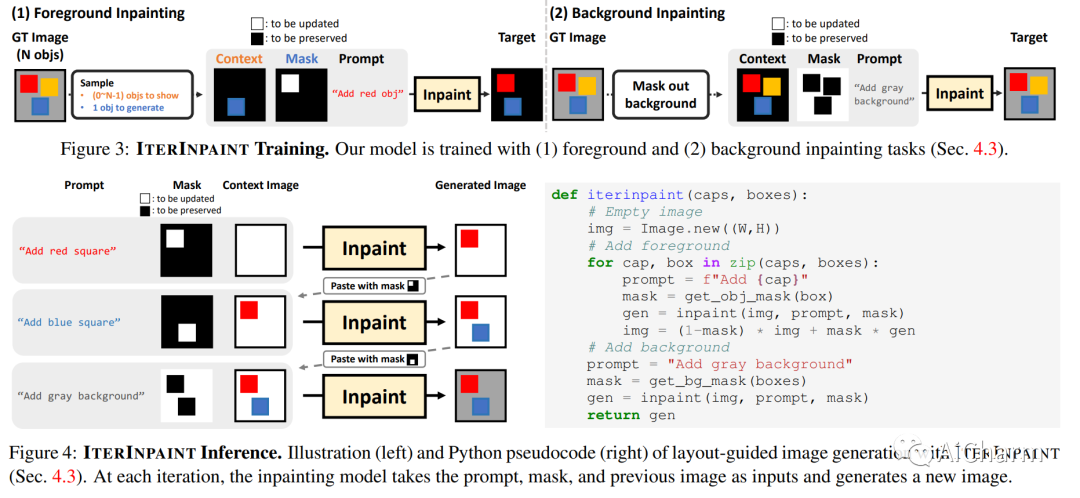
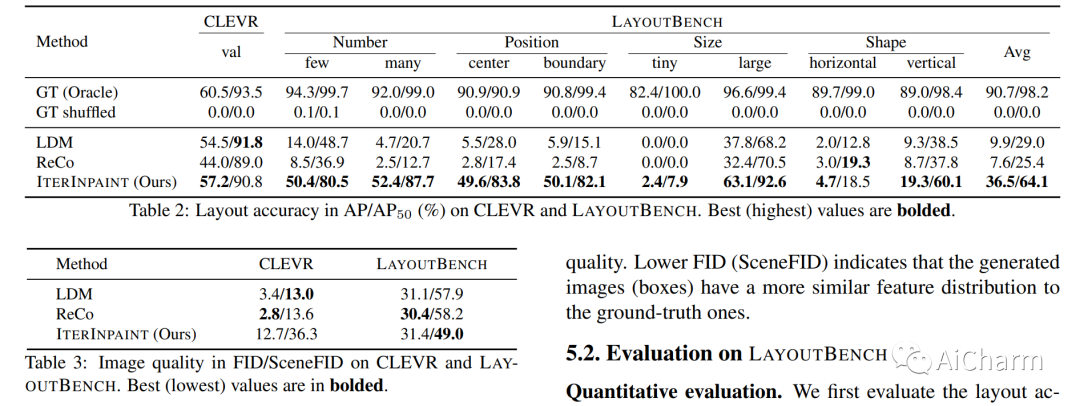
まとめ:
空間制御は、制御可能な画像生成のコア機能です。レイアウトガイド付き画像生成の進歩により、同様の空間構成を持つ分布内 (ID) データセットで有望な結果が示されました。ただし、任意の目に見えないレイアウトを持つ分布外 (OOD) サンプルに直面したときに、これらのモデルがどのように機能するかは不明です。このホワイト ペーパーでは、数、位置、サイズ、形状の 4 つの空間制御スキルのカテゴリを調べるレイアウト ガイド付き画像生成の診断ベンチマークである LayoutBench を紹介します。最近の 2 つの代表的なレイアウト ガイド付き画像生成方法のベンチマークを行い、優れた ID レイアウト コントロールが実際の任意のレイアウト (境界にあるオブジェクトなど) にうまく一般化できない可能性があることを観察しました。次に、修復によって前景領域と背景領域を段階的に生成する新しいベースラインである IterInpaint を提案し、LayoutBench の OOD レイアウトで既存のモデルよりも強力な一般性を示します。LayoutBenchの4つのスキルを定量的・定性的に評価し、きめ細かな分析を行い、既存モデルの弱点を洗い出します。最後に、トレーニング タスクの比率、切り取りと貼り付けと再描画、生成順序など、IterInpaint に関する包括的なアブレーション研究を紹介します。プロジェクトのウェブサイト: この https URL
3.DiffFit: シンプルなパラメータ効率の微調整による大拡散モデルの転送可能性のロック解除

タイトル: DiffFit: シンプルなパラメーターの効率的な微調整による大規模な拡散モデルの転送可能性のロック解除
著者: 謝恩沢、八尾楽偉、漢師、劉智利、周大泉、劉昭強、李佳威、李振国
記事リンク: https://arxiv.org/abs/2304.06648
プロジェクトコード: https://github.com/mkshing/DiffFit-pytorch


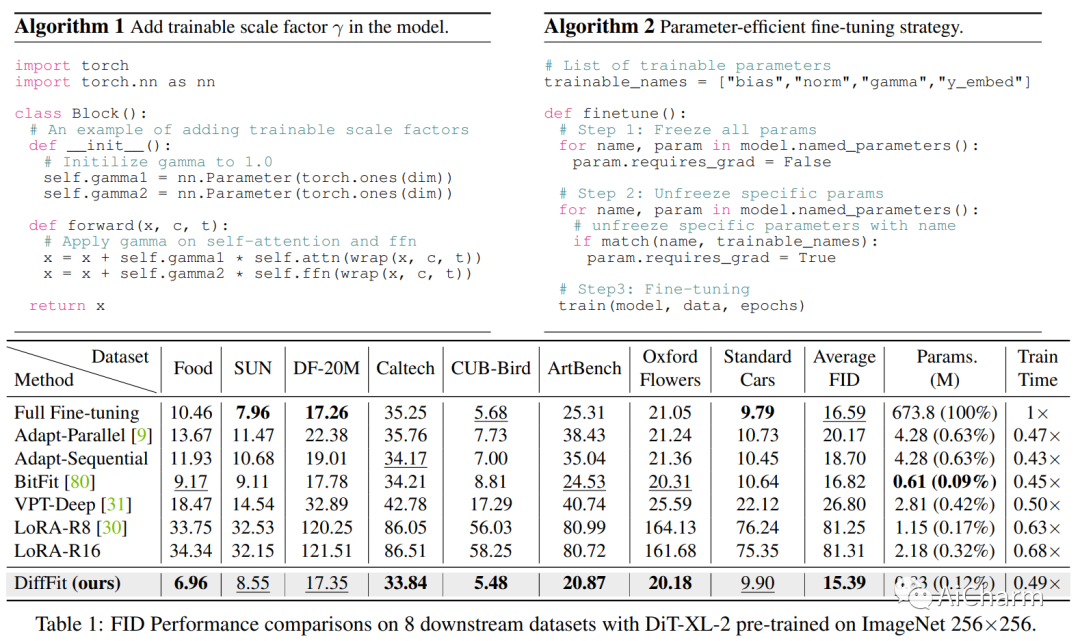
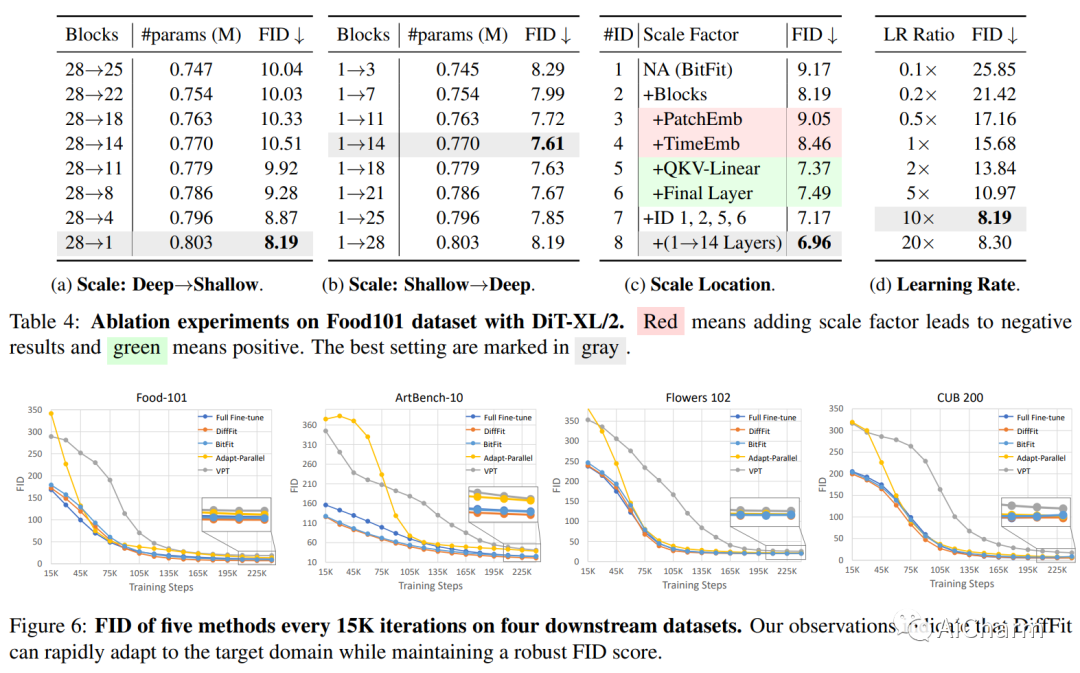
まとめ:
拡散モデルは、高品質の画像を生成するのに非常に効果的であることが示されています。ただし、大規模な事前トレーニング済み拡散モデルを新しいドメインに適応させることは未解決の課題のままであり、これは実用的なアプリケーションにとって非常に重要です。この論文では、事前訓練された大規模な拡散モデルを微調整するためのパラメーター効率の高い戦略である DiffFit を提案し、新しいドメインへの迅速な適応を可能にします。DiffFit は非常に単純で、特定のレイヤーのバイアス項と新しく追加されたスケーリング ファクターを微調整するだけですが、トレーニング速度が大幅に向上し、モデルのストレージ コストが削減されます。完全な微調整と比較して、DiffFit は 2 倍のトレーニング速度向上を実現し、モデル パラメーター全体の約 0.12% を保存するだけで済みます。迅速な適応のためのスケーリング係数の有効性を実証するために、直感的な理論的分析が提供されています。8 つのダウンストリーム データセットで、DiffFit は完全な微調整と比較して優れた、または競争力のあるパフォーマンスを実現しながら、より効率的です。特に、最小コストを追加することで、DiffFit が事前トレーニング済みの低解像度生成モデルを高解像度生成モデルに適応できることを示します。拡散ベースの方法の中で、DiffFit は、パブリックの事前トレーニング済み ImageNet 256@ から 25 エポックのみを微調整することにより、ImageNet 512 × 512 ベンチマークで新しい最先端の FID 3.02 を設定します。5# 256 チェックポイントながら 30 × 最も近い競合他社よりも高いトレーニング効率。
Ai の詳細情報:プリンセス AiCharm