この論文は「AN ISAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE」と呼ばれています。画像は 16x16 のワードに相当します。名前が示すように、ViT は画像を 16x16 のパッチに分割し、これらのパッチを入力と見なします。変圧器の。一緒に論文を勉強しましょう。
論文アドレス: https://arxiv.org/pdf/2010.11929.pdf
pytorch ソース コード: rwightman によって書かれ、公式に含まれています
tf ソースコード: https://github.com/google-research/vision_transformer
目次
概要
実際、この要約では 1 つのことを述べています。ビジュアル分野では、CNN よりも優れた結果を達成するためにトランスフォーマーを使用します。
Transformer アーキテクチャは自然言語処理タスクの事実上の標準になっていますが、コンピューター ビジョンでの応用は依然として限られています。ビジョンでは、アテンションは畳み込みネットワークと組み合わせて使用されるか、全体の構造を変更せずに畳み込みネットワークの一部のコンポーネントを置き換えるために使用されます。我々は、CNN へのこの依存は不要であり、画像パッチのシーケンスに直接適用された純粋な変換器が画像分類タスクで非常にうまく機能できることを示します。大量のデータで事前トレーニングされ、いくつかの中小規模の画像認識ベンチマーク (ImageNet、CIFAR-100、VTAB など) に転送されると、Vision Transformer (ViT) は最先端の畳み込みニューラルと比較して優れたパフォーマンスを達成します。その結果、同時にトレーニングに必要な計算リソースが少なくなります。
⚠️ 注: 論文内で IN が中小規模のデータセットであることを見た場合は、それに注意を払う必要があります。Google の人にとっては、主観的に置き換えないようにしましょう。また、ここでの少ないトレーニング リソースは、 2500 日間の TPUv3 トレーニング。
1 はじめに
導入では主に次の点が説明されます。
- Transformer は、NLP 分野で大規模なアプリケーションを実現しており、優れた計算効率とスケーラビリティを備えており、モデルが増加してもパフォーマンスが飽和しません (これが、Transformer をビジュアル分野に導入したい理由の 1 つです)
- 著者は、視覚的にわかりやすいメソッドの導入によるものではなく、トランスフォーマー自体が視覚的なタスクを実行し、良好な結果を達成できることを証明できるように、トランスフォーマーをできる限り変更していません。
- 実際、小規模および中規模のデータセットでのトレーニングは、ResNet や他のネットワークほど効果的ではありません。これは、従来の CNN には 2 つの事前知識 (帰納的パラノイア) があるためです: 変換の等分散性、畳み込みまたは変換が最初に行われるかどうか、効果は同じです。重要なことは、画像の隣接するピクセルが特定の関係を持っていることです。より大きなデータセットでトレーニングする場合、このような帰納的なパラノイアは必要ありません。したがって、より大きなデータセットでトレーニングすると、CNN よりも優れた結果が得られます。
セルフアテンション ベースのアーキテクチャ、特に Transformers は、自然言語処理 (NLP) の最適なモデルとなっています。主なアプローチは、大規模なテキスト コーパスで事前トレーニングを行ってから、タスク固有の小さなデータセットで微調整することです。Transformer の計算効率とスケーラビリティにより、100B を超えるパラメーターを使用して前例のないモデルをトレーニングすることが可能です。モデルとデータセットが増加してもパフォーマンスが飽和する兆候はまだありません。
ただし、コンピューター ビジョンでは、依然として畳み込みアーキテクチャが主流です。NLP の成功に触発されて、多くの作品が CNN のようなアーキテクチャと自己注意を組み合わせようとしていますが、その中には畳み込みを完全に置き換えるものもあります。一部のモデルは、理論的には効率的ですが、特殊なアテンション パターンを使用しているため、最新のハードウェア アクセラレータではまだ効率的に拡張できません。したがって、大規模な画像認識では、古典的な ResNet アーキテクチャが依然として最先端です。
NLP のトランスフォーマーのスケーラビリティにインスピレーションを受け、私たちは、できるだけ変更を少なくして、標準のトランスフォーマーを画像に直接適用することを試みています。これを行うには、画像をブロックに分割し、これらのブロックの線形埋め込みのシーケンスを Transformer への入力として提供します。イメージ パッチは、NLP アプリケーションのトークン (単語) と同じように扱われます。教師ありの方法で画像セグメンテーションのモデルをトレーニングします。
強力な正則化を行わずに ImageNet などの中規模のデータセットでトレーニングした場合、これらのモデルの精度は、同じサイズの ResNet よりも数パーセント低くなります。この一見悲惨な結果は予想されるかもしれません: トランスフォーマーには、変換の等分散性や局所性など、CNN に固有の帰納的バイアスの一部が欠けているため、不十分な量のデータでトレーニングされた場合には適切なパフォーマンスが得られません。
ただし、モデルがより大きなデータセット (1,400 万~3 億画像) でトレーニングされる場合は状況が変わります。大規模なトレーニングは帰納的バイアスよりも優れたパフォーマンスを発揮することがわかりました。当社の Vision Transformer (ViT) は、十分な規模で事前トレーニングし、より少ないデータ ポイントのタスクに転送すると、優れた結果を達成します。ImageNet-21k データセットまたは JFT-300M データセットで事前トレーニングすると、ViT は複数の画像認識ベンチマークで最先端に近づくか、それを超えます。特に、最良のモデルは、19 タスクの ImageNet で 88.55%、ImageNet-ReaL で 90.72%、CIFAR-100 で 94.55%、VTAB で 77.63% を達成しています。
2 関連作品
画像をベクトルに直接プルすると、変換器にとってシーケンスの長さが長すぎ、計算の複雑さが高くなりすぎます。したがって、コルドニエらのモデルは次のようになります。、入力画像からサイズ 2 × 2 のパッチを抽出します。実際、ここではトランスフォーマーがすでに使用されていますが、Google の方が豊富なので、224 枚の画像を処理できる 16 x 16 パッチを入手するだけで、大規模なデータ セットで非常に良い結果が得られます。
Transformer は、機械翻訳のために Vaswani らによって提案され、多くの NLP タスクにおける最先端の手法となっています。大規模な Transformer ベースのモデルは、多くの場合、大規模なコーパスで事前トレーニングされてから、当面のタスクに合わせて微調整されます。BERT はノイズ除去自己教師あり事前トレーニング タスクを使用しますが、GPT の一連の作業では事前トレーニング タスクとして言語モデリングが使用されます。
画像に自己注意を適用するだけでは、すべてのピクセルが他のすべてのピクセルに注意を払う必要があります。これは、ピクセル数の二次コストにより、実際の入力サイズに合わせて調整されません。したがって、画像処理のコンテキストでトランスフォーマーを適用するために、これまでにいくつかの近似が試みられてきました。Parmar らは、グローバルではなく、各クエリ ピクセルのローカルな近傍にのみセルフ アテンションを適用します。このローカル マルチヘッド ドット積セルフ アテンション ブロックは、畳み込みを完全に置き換えることができます。別の研究では、Sparse Transformers (Child et al., 2019) が画像に対して機能するように、グローバルな自己注意に対するスケーラブルな近似を採用しています。注意を拡大するもう 1 つの方法は、異なるサイズのパッチに適用することです (極端な場合は 1 つの軸に沿ってのみ)。これらの特化されたアテンション アーキテクチャの多くは、コンピュータ ビジョン タスクで有望な結果を示していますが、ハードウェア アクセラレータが必要であり、非常に複雑です。
私たちにとって最も関連性があるのは、Cordonnier らのモデルです。、入力画像からサイズ 2 × 2 のパッチを抽出し、その上に完全な自己注意を適用します。このモデルは ViT に非常に似ていますが、私たちの研究はさらに、大規模な事前トレーニングにより、バニラ Transformer が最先端の CNN と競合 (またはそれを上回る) ことができることを示しています。さらに、Cordonnier らは 2 × 2 ピクセルのパッチ サイズを使用しているため、このモデルは低解像度の画像にのみ適していますが、私たちは中解像度の画像も扱います。
また、畳み込みニューラル ネットワーク (CNN) とセルフ アテンションの組み合わせにも多くの関心が寄せられています。たとえば、画像分類用の特徴マップを拡張したり、物体検出などのためにセルフ アテンションを使用して CNN の出力をさらに処理したりすることです。 (Hu et al., 2018; Carion et al., 2020)、ビデオ処理 (Wang et al., 2018; Sun et al., 2019)、画像分類 (Wu et al., 2020)、教師なし物体発見 (Locatello) et al., 2020)または統合テキストビジョンタスク(Chen et al., 2020c; Lu et al., 2019; Li et al., 2019)。
もう 1 つの最近の関連モデルは、画像 GPT (iGPT) (Chen et al.、2020a) です。これは、画像解像度と色空間を削減した後、画像ピクセルに Transformer を適用します。モデルは生成モデルとして教師なしの方法でトレーニングされ、結果の表現を微調整または線形探索して分類パフォーマンスを向上させることができ、ImageNet で最大 72% の精度を達成します。
私たちの研究は、標準の ImageNet データセットよりも大規模な画像認識を調査する論文の増加に加えられています。追加のデータソースを使用する標準ベンチマークで最先端の結果を達成できます (Mahajan et al., 2018; Touvron et al., 2019; Xie et al., 2020)。さらに、Sun ら。(2017) CNN のパフォーマンスがデータセットのサイズに応じてどのようにスケールされるかを研究しています。(2020);ジョロンガら。(2020) ImageNet-21k や JFT-300M などの大規模データセットに対する CNN 転移学習の実証的調査を実施しました。後者の 2 つのデータセットにも焦点を当てますが、以前の研究で使用された ResNet ベースのモデルの代わりに Transformer をトレーニングします。
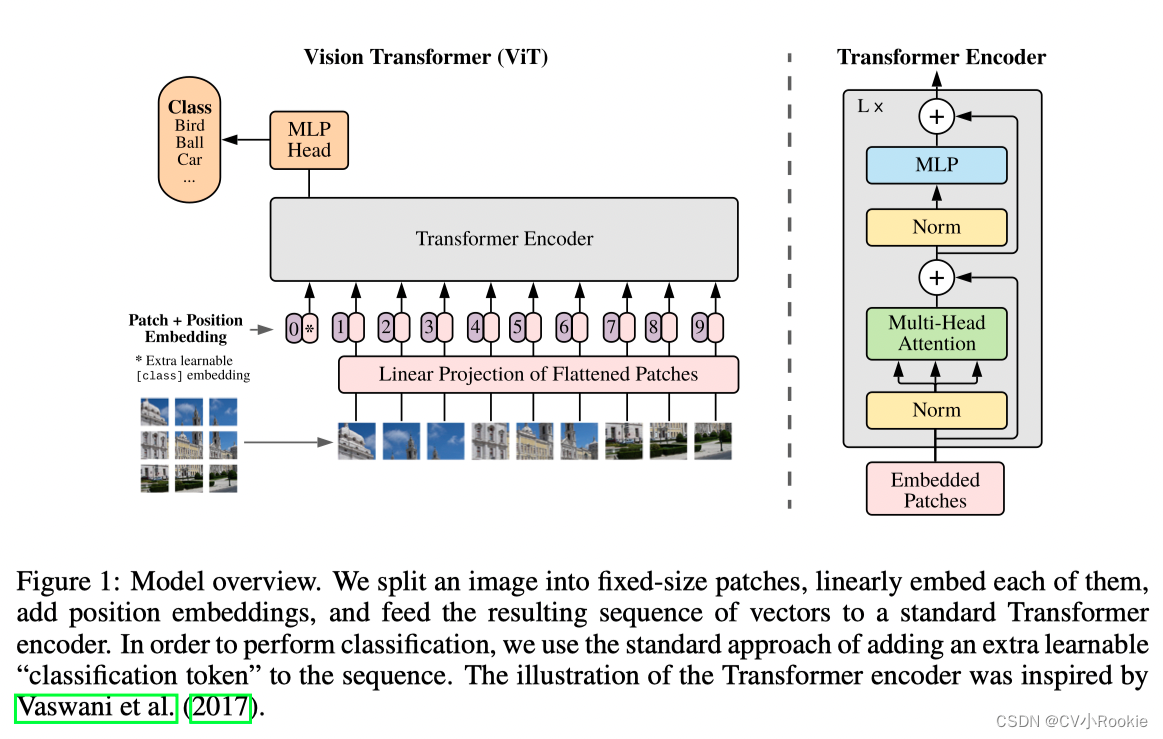
3 方法
モデル設計では、オリジナルの Transformer (Vaswani et al., 2017) を可能な限り踏襲しています。この意図的にシンプルなセットアップの利点は、スケーラブルな NLP Transformer アーキテクチャとその効率的な実装がほぼそのまま使用できることです。
3.1 ビジョントランスフォーマー (VIT)
モデルの概要を図 1 に示します。標準の Transformer は、トークン埋め込みの 1 次元シーケンスを入力として受け入れます。2D 画像を処理するには、
画像を一連の平坦化された 2D パッチに再整形します。
ここで、(H, W) は元の画像の解像度、C はチャネル数、(P, P) は各画像の解像度ですpatch は
生成されるブロックの数であり、Transformer の有効な入力シーケンス長としても機能します。Transformer はすべてのレイヤーにわたって一定の潜在ベクトル サイズ D を使用するため、パッチを平坦化し、トレーニング可能な線形投影 (式 1) を使用して D 次元にマッピングします。この投影の出力をパッチ埋め込みと呼びます。
BERT の [class] タグと同様に、学習可能な埋め込みを 一連の埋め込みパッチ ( ) に追加し、
Transformer エンコーダー ( ) の出力における状態が画像表現
(式 4) として使用されます。チューニングの場合、カテゴリヘッダーが に追加されます
位置情報を保存するために、位置エンベディングがパッチ エンベディングに追加されます。より高度な 2D 対応の位置埋め込みを使用しても大幅なパフォーマンスの向上が観察されないため、標準の学習可能な 1D 位置埋め込みを使用します (付録 D.4)。結果として得られる埋め込みベクトルのシーケンスは、エンコーダーへの入力として使用されます。
Transformer エンコーダは、マルチヘッド セルフ アテンション ブロックと MLP ブロックの交互のレイヤーで構成されます。各ブロックの前に適用される
Layernorm (LN)。各ブロックの後に残りの接続を適用します。
誘導バイアス: Vision Transformer は、CNN と比較して画像固有の誘導バイアスがはるかに小さいことに注目します。CNN では、局所性、2D 近傍構造、および並進等価性がモデル全体のすべての層に実装されます。ViT では、MLP レイヤーのみがローカライズされトランスレーショナルであり、セルフアテンション レイヤーはグローバルです。2D 近傍構造は、モデルの開始時に画像をブロックに分割し、微調整中に異なる解像度の画像の位置的な埋め込みを調整することで、非常に控えめに使用されます (後述)。それに加えて、初期化時の位置埋め込みにはパッチの 2D 位置に関する情報が含まれていないため、パッチ間のすべての空間的関係を最初から学習する必要があります。
ハイブリッド アーキテクチャ 生の画像パッチの代わりに、CNN の特徴マップから入力シーケンスを形成できます (LeCun et al., 1989)。このハイブリッド モデルでは、パッチ埋め込み射影 E (式 1) が CNN 特徴マップから抽出されたパッチに適用されます。特殊なケースとして、パッチは 1x1 の空間サイズを持つことができます。これは、入力シーケンスが、特徴マップの空間次元を単純に平坦化し、Transformer 次元に投影することによって取得されることを意味します。上記のように、カテゴリ入力埋め込みと場所埋め込みを追加します。

この部分で ViT が一気に分かりやすくなりますが、その構造は新しい Embedding 層 + トランスフォーマー内のエンコーダー層 + MLP 層という非常にシンプルではないでしょうか!
埋め込み層
原文では埋め込み層の処理が非常にわかりやすく説明されていますが、ここではViT-B/16 (ViT_base_patch16) を例にして説明します。 最初に 224 x 224 を入力し、画像を 16 x 16 のパッチに分割すると、パッチが作成されます 。次に、これら 196 個のパッチがマッピングされるベクトルについて説明します
。各パッチの形状は [16, 16, 3] (縦横 16、チャンネル数 3) です。コードのこのステップは畳み込みによって実装されます。
Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)コンボリューション カーネル サイズは 16、ステップ サイズは 16、入力次元は 3、出力次元は 768 です。素晴らしい!!
このようにして画像を[224, 224, 3]から[14, 14, 768]に変更し、Flattenすると[196, 768]が得られます。
分類専用のトークンを追加します。ここでの加算方法はBERTと同様で、学習によって得られる[class]トークンを加算するという記事にありますが、次元の一貫性を保つために[class]トークンの次元は[1,768]となります。 ]。Concat 操作により、[196, 768] と [1, 768] が連結されて [197, 768] が得られます。
次に、これらのトークンに位置情報を追加します。つまり、位置埋め込みです。これはトランスフォーマーと一致しており、すべてのトークンに追加する
トランスエンコーダ
この部分はトランスのエンコーダと全く同じで、以前に書いたトランスの詳しい説明を読んでください。
簡単に言えば、N x ブロック (マルチヘッド アテンション + MLP) です。
ViT-B/16 では、入力は [197, 768] で、出力も [197, 768] です。
その後、MLP ヘッドに接続され、最終的な分類結果が出力されます。
MLP 責任者
Transformer との唯一の違いは、Transformer はすべての出力トークンを使用しますが、ViT は分類のみを行い、[class] トークンの対応する位置を出力するだけでよいことです。
出力方法も非常にシンプルで、全結合ニューラルネットワークです!それはとても簡単です!
3.2 微調整と高解像度
通常、大規模なデータセットで ViT を事前トレーニングし、(小規模な) 下流タスクで微調整します。この目的を達成するために、事前トレーニングされた予測ヘッドを削除し、ゼロで初期化された D × K フィードフォワード層を追加します。ここで、K はダウンストリーム クラスの数です。より高い解像度での微調整は、事前トレーニングと比較して有益であることがよくあります (Touvron et al., 2019; Kolesnikov et al., 2020)。より高解像度の画像が提供される場合、パッチ サイズは同じに保たれるため、有効シーケンス長が長くなります。Vision Transformer は任意のシーケンス長 (メモリ制限まで) を処理できますが、事前にトレーニングされた位置情報は意味を持ちません。したがって、元の画像内の位置に従って、事前にトレーニングされた位置埋め込みを 2D 補間します。この解像度調整とパッチ抽出は、画像の 2D 構造に関する誘導バイアスが視覚変換器に手動で注入される唯一のポイントであることに注意してください。
4 実験

このパラメータの量は依然として非常に誇張されていることがわかります。そのため、独自のトランスフォーマーをトレーニングするときは、事前にトレーニングされた重みファイルを使用する必要があります。
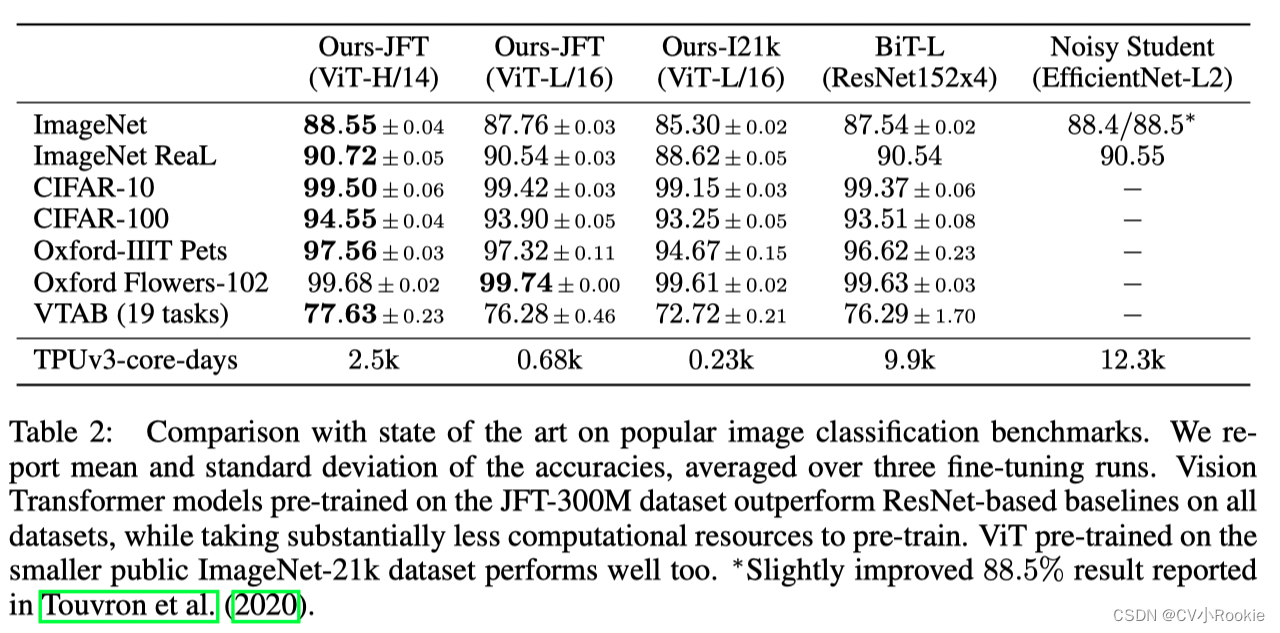
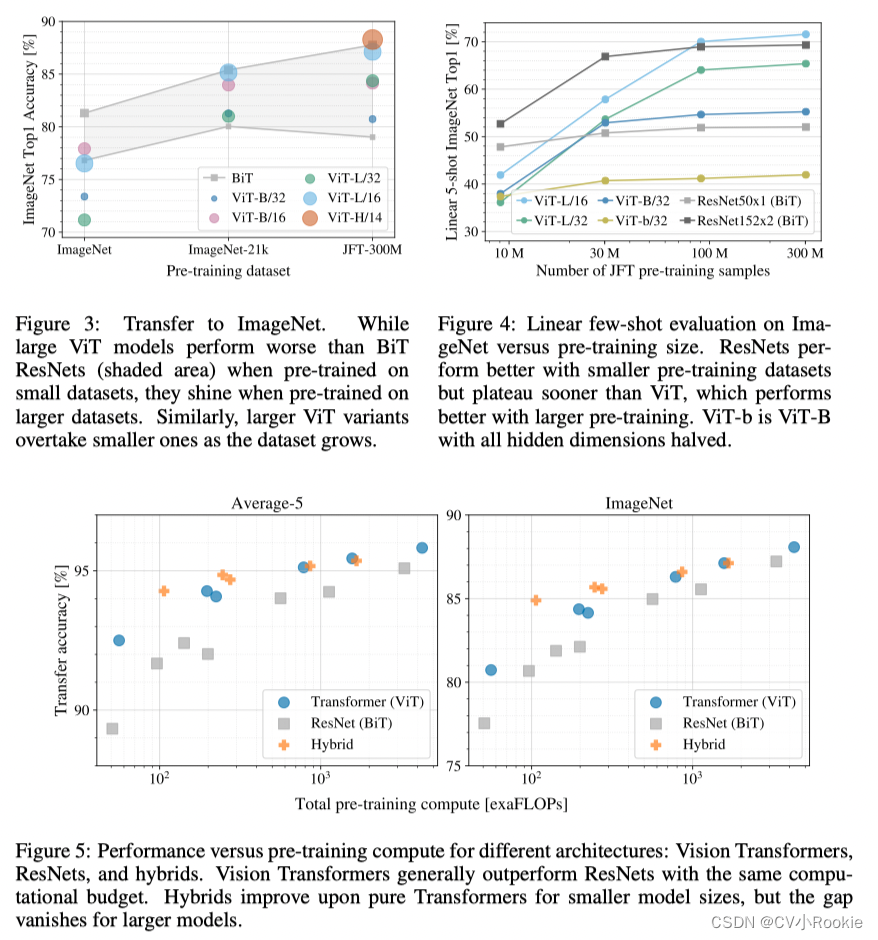
5。結論
私たちは画像認識におけるトランスフォーマーの直接応用を検討してきました。コンピューター ビジョンでセルフ アテンションを使用した以前の研究とは異なり、最初のパッチ抽出ステップを超えて画像固有の誘導バイアスをアーキテクチャに導入しません。代わりに、画像を一連のパッチとして解釈し、NLP の標準の Transformer エンコーダーを使用して処理します。このシンプルだがスケーラブルな戦略は、大規模なデータセットでの事前トレーニングと組み合わせると、驚くほどうまく機能します。その結果、Vision Transformer は、多くの画像分類データセットにおいて最先端のものと同等かそれを上回っており、事前トレーニングが比較的安価です。
これらの初期結果は心強いものではありますが、多くの課題が残されています。1 つは、ViT を検出やセグメンテーションなどの他のコンピューター ビジョン タスクに適用することです。私たちの結果は、Carion らの結果と合わせて、このアプローチの有望性を示しています。もう 1 つの課題は、自己監視型の事前トレーニング方法を探求し続けることです。私たちの最初の実験では、自己教師あり事前トレーニングの改善が示されましたが、自己教師ありと大規模な教師あり事前トレーニングの間には依然として大きなギャップがあります。最後に、ViT をさらに拡張すると、パフォーマンスが向上する可能性があります。