Rust RPC フレームワークの場合、IDL に基づいたコード生成は、ユーザーがフレームワークを使いやすくすることを目的としています。生成されたコードと周辺機能の品質は、ユーザーの開発エクスペリエンスに非常に直接的な影響を与えます。
したがって、Bytedance CloudWeGo は、ユーザー向けに優れたコードを生成するために Pilota のようなフレームワークを開発しました。
2023年5月28日に開催された「GOTC Global Open Source Technology Summit - Rust Forum」にて、ByteDanceサービスフレームワークの研究開発エンジニアLiu Yifei氏がコード生成ツールPilotaを紹介しましたので、今日はその内容を紹介します。

コード生成ツールが必要な理由
まず、なぜコード生成ツールが必要なのでしょうか?
RPC の世界では、ユーザーはサービス インターフェイスを IDL 形式で記述するためです。
例えば、ここにサービスがあり、そのサービスはいくつかのメソッドも提供していますが、このメソッドの入力パラメータの型と返される構造体の型を記述する必要があり、ユーザーはこの IDL で記述します。

実際のコードではこのような IDL を直接使用することはできないため、IDL を Rust コードに変換してユーザー フレームワークに渡して使用する必要があります。

このような変換プロセスは、コード生成ツールが実行する必要があるものです。つまり、IDL を Rust コードに変換します。
同時に、エンコードおよびデコードのロジック生成を行う必要があります。
たとえば、定義された Message trait に対して encode decode メソッドを提供する必要があります。この encode は、自身の構造化データをバイナリ データにエンコードすることであり、decode は、バイナリ データから構造化データを取得することです。これらのコード デコード ロジックには、特定の生成を実行するためのコード ツールも必要です。

当社のコード生成ツールを使用すると、RPC を呼び出すのに非常に便利です。build.rs ファイルにどの IDL ファイルが依存するかを記述するだけで済みます。当社のコード生成ツールは、そのためのコードを生成します。その後、必要なのは次のことだけです。ビジネス ロジックの include! マクロを使用して生成されたコードをインポートすると、通常の関数呼び出しを完了して RPC 呼び出しを完了するのと同じように、非常に簡単にクライアントを構築できます。

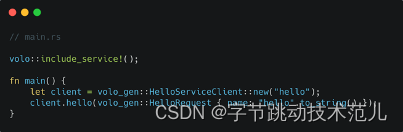
このアプローチにより、RPC 呼び出しが非常に簡単になります。
Rustコード生成の課題
では、コードを生成する際の課題は何でしょうか?
実際には、IDL を AST に変換し、それを 1 行ずつ翻訳するだけで済み、パーサーを実装するだけで十分です。実際、私たちも最初はそう考えていて、コード生成ツールの最初のバージョンはこの考えに基づいて作られましたが、非常にシンプルです。
しかしその後、多くの問題に遭遇しました。
たとえば、IDL には循環依存関係の問題があり、構造体 b に依存する構造体 a があります。次に、構造体 b は構造体 a に依存します。


Rust コードに直接変換してコンパイルすると、コンパイラは、これら 2 つの構造体のサイズを計算できないことを示すエラーを報告します。
Rust の世界では、この方法で循環依存関係を記述することは許可されていないため、このサイズの問題を解決するには何らかの手段を使用する必要があります。
たとえば、ここでこれらのフィールドに Box を追加します。Box は実際にはポインターであり、この構造体のサイズはポインターのサイズであるため、サイズ計算の循環依存性は解決されます。

では、この問題をどうやって解決すればよいでしょうか?
実際、これは非常に単純です。つまり、グラフを生成し、各タイプの IDL がグラフ内のノードになり、ノード間のエッジが参照フィールドになります。たとえば、構造体 a が使用される場合、構造体 b ~ ab が使用され、タイプ b は構造体 a ~ ba が使用されます。
次に、新しいグラフを作成できます。このグラフにはリングがあることがわかりました。このグラフのリングを検出し、このリング内のすべてのものにボックスを追加する必要があります。これで、この問題を解決できます。

この時点で、ユーザーは新しい要件を提案し、Rust で一般的に使用される Hash や Eq などの派生マクロの生成を手伝ってくれないかと尋ねました。
しかし、ハッシュの派生マクロをすべての型に追加できるでしょうか?
いいえ、Rust の世界では、float と同様に、ハッシュ トレイトが実際には実装されていないためです。
このような構造体を実装して派生ハッシュを追加すると、コンパイラからエラーが発生します。これは、float64 型がハッシュを実装していないためです。そのため、構造体のすべてのフィールドが If であるかどうかをルールを設定する必要があります。ハッシュが実装されている場合、この構造はハッシュを導出できる必要があります。

たとえば、3つの構造体a、b、cがあり、構造体aは構造体bと構造体cに依存しています。構造体bには依存する構造体aがあります。そして、構造体cにはdouble型のフィールドがあり、対応するRust型はfloat64です。 。


したがって、この時点で、どの構造がハッシュ化できるかを計算し始めます。まず構造 a のタイプを見てみましょう。Hash(A) の確立は 2 つの命題 Hash(B) と Hash(C) の同時の確立に依存していることがわかります。次にフィールド b を見てみましょう。その後、Hash(B) の確立 Hash(A) の確立に依存します。Hash(C) の確立は Hash(double) の確立に依存します。

これら 3 つの論理命題を得た後、これらの論理命題が真であるかどうかを判断する必要があります。
まず最初の質問 Hash(A) を見てください。Hash(A) の確立は Hash(B) と Hash(C) の確立に依存し、次に Hash(B) の確立は Hash( A)。
再帰を通じてこれを非常に単純かつ率直に扱うと、a が b に依存し、次に b が a に依存し、再帰から逃れることはできないことがわかります。
このとき、何らかの手段が必要となります。Hash(A)の処理 Hash(B)とHash(C)を計算するには、Hash(B)を計算する際、Hash(A)に依存しており、Hash(A)が計算に入っているため、Hash( B) ) 遅延依存関係を作成します。これは、それに関係なく後で計算されます。
この時点で、Hash(B) を Hash(A) に置き換えて、Hash(A) の計算に戻ると、Hash(A) が Hash(C) と Hash(A) の成立に依存していることがわかります。もう一度 Hash(C) を扱いますが、Hash(A) の確立は実際には Hash(double) の確立に依存します。しかし、実際には、double 型に対応する float32 は Hash を実装していないため、最終的に問題が発生します。Hash(A) の確立です。この命題は false & hash(A) と同等です。したがって、この命題は無効になり、命題 Hash(A) は無効になります。
この時点で、別の質問があります。Hash(A) が計算されたので、Hash(B) はどうなるでしょうか。先ほど Hash(B) の計算が半分終わっており、遅延依存の中間状態にあるため、Hash(B) を再計算する必要があります。Hash(A) が無効であることが判明したため、Hash(B) が無効であることが正常に計算されます。
したがって、3 つの命題 Hash(A)、Hash(B)、および Hash(C) は無効です。

しかし、場面を変えて、c 構造体のフィールドが double ではなく int32 であると仮定し、先ほどの方法に従って計算し、Hash(C) が成立することを確認すると、次のようになります。ハッシュ(A)の確立はハッシュ(A)の自己確立に依存するということ。この状況にどう対処すればよいでしょうか?
Rust の世界では、構造体にフィールドが 1 つだけあり、このフィールドの型がそれ自体である場合、この構造体のハッシュを導出できます。したがって、この場合、次の規則を定式化できます。命題がそれ自体の確立にのみ依存する場合、この命題は確立されます。次に、Hash(A) も確立されます。
次に、Hash(B) の計算に戻ります。Hash(B) は遅延依存関係 Hash(A) の前にあり、その後 Hash(A) が確立されるためです。次に、Hash(B) を計算すると、同様に有効な結果が得られます。この時点では、Hash(A)、Hash(B)、Hash(C) はすべて有効です。

IDL を扱うプロセスでは、定数に遭遇することもあります。これは、すべての節約において const を通じて定数を定義できるためです。

この定数はどのように生成すればよいのでしょうか?
たとえば、thrift string の定数型は &'static str 型の定数を生成し、Rust コンパイラは定数に対していくつかの最適化を実行します。そのため、コード生成ツールがユーザーに対して &'static str 型を生成する方が間違いなく優れています。

しかし、節約により、ユーザーは非常に自由な型を書くことができます。たとえば、const を使用してマップ タイプを指定すると、マップ内にリストのようなタイプが存在します。
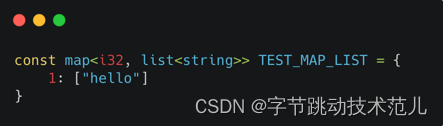
しかし、Rustでは、Hashmap、vector、その他の型はすべてメモリ割り当てを伴うため、constで表現することはできません。したがって、遅延静的によって処理する必要があります。まず静的参照を作成します。これにより、そのような構造、このハッシュマップ、およびこのベクトルを構築するための構築ロジックが生成されます。

それでは、どのような問題が発生するのでしょうか?現在の設計には 2 種類の表現があり、1 つは const で、もう 1 つは struct です。

これで、const 内の文字列型に対して &'static str が生成されました。
しかし、構造体の文字列を扱う場合はどうなるでしょうか? 構造体の文字列型フィールドは、実際にはユーザーがリクエストを作成するために使用するか、サーバーによって応答として出力される可能性がありますが、ユーザーはそのようなフィールドを非常に簡単に作成する必要があります。
ただし、ここでの文字列が &'static str として扱われる場合、&'static str 構築の条件が高すぎるため、ユーザーは基本的にそれを構築できません。
したがって、このときルールを定義する必要があるのですが、structのスコープ内ではstringで定義した文字列型とRust型の文字列が対応することになり、2種類の表現が問題となります。
たとえば、「hello world」は現在リテラルですが、const スコープ内にある場合、対応する型は &'static str となり、この式を直接使用できます。ただし、const 形式以外の場合は文字列に変換する必要があるため、to_owned() メソッドを使用して文字列に変換する必要があります。しかし、状況がより複雑になり、ここでリテラルではなくシンボルが使用される場合は、コード生成ツールに、異なる型間の変換方法を処理する独自の型システムが必要になります。
一部の実践では、過剰なコード生成の問題にも遭遇しました。
私たちのビジネス コードには、ビジネス IDL ファイル用の thrift idl ファイルが数十存在する可能性があり、生成ツールは 150 万行の Rust コードを生成し、貨物チェックの実行には 10 分かかります。当時のコード生成ツールのロジックは、IDLで生成したRustのコードをすべて1つのファイルにまとめてしまうため、ユーザーの動作確認処理が非常に遅かったのです。
しかし、その過程で問題が見つかります。たとえば、エントリ ファイル a があり、その中にサービスがあります。これはユーザーが本当に使いたいサービスですが、このファイルは統計である必要があります。この 2 つ ファイルには、service、a、aa、b、bb という 5 つの構造があります。
しかし実際には、ユーザーは入り口のサービスだけを気にしており、そのサービスが依存する構造についてはユーザーは気にしていません。
したがって、現時点では、最適化メソッドを作成し、このサービスをエントリ ノードとして使用し、どの構造が依存しているか、どの構造を生成する必要があるかをスキャンして、生成する必要がある構造を減らすことができます。この最適化により、以前の 150 万行のコードのうち 10 万行だけが残り、コンパイル効率が大幅に向上しました。
CloudWeGo には RPC フレームワーク Volo があり、ユーザーに RPC を呼び出す機能を提供します。Volo では IDL がどのように使用されるのでしょうか?
IDL と RPC フレームワークの間のブリッジとしてコード生成ツールが必要です。このツールは Pilota であり、オープンソースのコード生成ツールです。
Pilota の設計アーキテクチャ
Pilota の構造は非常に単純に見えます。そのエントリはパーサー、パーサーの入力は IDL、出力は AST です。Naming Resolve シンボル解析の後、中間表現 IR が生成され、この中間表現に基づいて、循環依存関係、型変換、依存関係の収集などの問題に対処します。最後に、ユーザー定義のプラグインの実行を続行し、最終結果をバックエンドの運用コードに渡します。
まず、パーサー部分を見てみましょう。現在、パーサーは Thrift と Protobuf の両方をサポートしており、その出力は AST です。
IDL 形式を Pilota の AST 表現に変換できれば、Pilota システムに接続でき、上記の複雑な問題は簡単に解決できます。
AST を取得したら、名前解決ステージに入る必要があります。
実際、Pilota の AST は既に Rust の表現に非常に近づいていますが、Mod Test や Struct Test などの同じ名前のシンボルがいくつかあるため、ここにはいくつかの特別な機能がある可能性があります。
Pilota の AST では同じ名前のシンボルが許可されていますが、これによりシンボルの解決にいくつかの課題が生じます。なぜそのようなデザインが許されるのでしょうか?
Protobuf には Nested Items という非常に特殊な設計があるため、メッセージ内でメッセージを定義できますが、Rust で Struct 内に Struct を定義することはできません。そのため、Protobuf のこの機能をサポートするには、Pilota の AST が必要です。この形で表現されます。このフォームの場合、Pilota が Struct を生成すると、関連するネストされた項目に対して同じ名前の Mod も生成されます。
したがって、同じ名前のシンボルが表示されると、Rust と同様に名前解決プロセスで異なる名前空間が使用されます。これは、Rust には名前解決プロセスで 2 つの名前空間があり、1 つは Type で、もう 1 つは Value Pilota にあるためです。同様の設計ですが、タイプ、値、Mod という 3 つの異なる名前空間に分割されます。
まず AST 構造図を見てみましょう。これらのファイル内のすべての項目が一度走査され、シンボルに ID が割り当てられます。
ID を割り当てた後、各構造体の各フィールドのパスがどの ID を指しているかを計算する必要があります。
ただし、同じ名前のシンボルはあいまいさの問題を引き起こす可能性があるため、名前空間に応じて異なる解析結果をフィルタリングする必要があります。
Rust には、serde などの一般的に使用されるサードパーティ ライブラリの派生マクロがいくつかあります。次に、Pilota は、ユーザーが生成されたコード内の属性をカスタマイズできる柔軟な機能を提供する必要があります。
Pilota では、各項目フィールドの varaint には、対応する調整フィールドがあります。ユーザーは、調整のこの構造にアクセスするプラグインを作成し、内部の属性を変更して生成されたコードの属性をカスタマイズし、nested_item フィールドを使用して追加生成された Rust を制御できます。 Impl ブロックなどのコード。
ピロタの未来
これらの問題を解決すると、Pilota はほとんどのシナリオで使用できるようになります。しかし、Pilota はコードを生成するいくつかの異なる方法も模索しています。
一部の開発者は、生成されるコードの量が依然として非常に多いと述べ、これらの最適化後でもコードの量はまだ 5W ~ 10W 程度であり、一部のビジネス関係者は IDL の存在を認識したくないと考えていますが、現在のシステム ユーザーは IDL を通じてコードを生成する必要があります。しかし、ユーザーはその使い方を変えることができるでしょうか?
たとえば、ユーザーが 3 つの IDL に基づいて対応するサービス コードを生成したい場合、ユーザーの便宜のために 3 つのクレートを生成できます。
ただし、これら 3 つのクレートで同時に使用されるいくつかの構造が存在する可能性があり、そのような構造を保管するにはクーモン クレートが必要です。この生成方法はどのようなメリットをもたらしますか?
まず、Rust でコンパイルされるキャッシュは実際にはクレートレベルなので、コンパイラのキャッシュを最大限に活用することができます。ビジネスで窮地に立たされている。複数のクレートが生成されるようになったため、数十万行のコードが 6 つのクレートに完全に入れられた可能性があります。各クレートは数万行のコードのみを共有し、キャッシュの粒度はより細かくなります。クレートのコードが更新されるとき必要なのは、これらの数万行のコードを再コンパイルするだけです。
これらのクレートを生成した後、開発者はカーゴ ワークスペースを使用してクレートを管理し、これらのクレートを git または他の場所に公開できます。その後、他の開発者は、生成されたコードを直接使用して RPC 呼び出しを完了でき、IDL の存在を気にする必要がなくなります。
さて、今日の共有はこれで終わりです、皆さんありがとうございました。
GitHub アドレス:
https://github.com/cloudwego/pilota