1。概要
AVOD (Aggregate View Object Detection) は MV3D に似ています。3D 点群とカメラの RGB 画像を融合する 3D オブジェクト検出アルゴリズムです。違いは次のとおりです。MV3D はカメラの RGB 画像、点群 BEV マッピング、および FrontView マッピングを組み合わせますが、AVOD は AVOD のみを組み合わせます。カメラの RGB 画像と点群 BEV マップを融合します。
ネットワークの結果から、AVOD は 2 段階の検出ネットワークを使用しているため、同様に 2 段階の検出ネットワークの結果である Faster RCNN オブジェクト検出ネットワークを容易に考えることができます。は、検出フレーム レートが高くなく、検出精度が必要なシナリオにのみ適しています。
以下はAVODのネットワーク構造図です AVOD

2. ネットワーク構造
ネットワークはまず、特徴抽出、次元削減、トリミング後の入力データを融合してシーン内の前景を含む領域を取得し(予備回帰を実行)、次にシーン内の候補領域を鳥瞰図と RGB に投影します。画像 その後、トリミングする領域を取得し、トリミングして均一なサイズに調整し、シーン内のさまざまなオブジェクトの検出カテゴリと 3D オブジェクト検出フレームを融合によって取得します。
2.1 レーザー点群データの前処理
AVOD は、MV3D と比較して、レーザー点群処理をいくつか簡素化しました。強度マップが削除され、点群の高さマップが M 層に分割されます。つまり、z は (0, 2.5) の範囲にあり、0.5 の間隔で 5 つの層が取得され、それぞれのグリッドが取得されます。レイヤーは、最も高い高さの点群を取得します。
密度マップの処理は次のとおりです。

2.2 特徴抽出
ネットワークのフロントエンドにある特徴抽出器は、入力データを抽出して特徴マップを取得します。MV3D (改良型 VGG-16) の特徴抽出器と比較して、AVOD の特徴抽出器は FPN を使用してレーザー点群の特徴を抽出し、 RGB 画像: マルチスケール検出 (最下位層と上位層の情報を含む) の機能があり、小さなオブジェクトの検出において MV3D と比較して特定の利点があります。
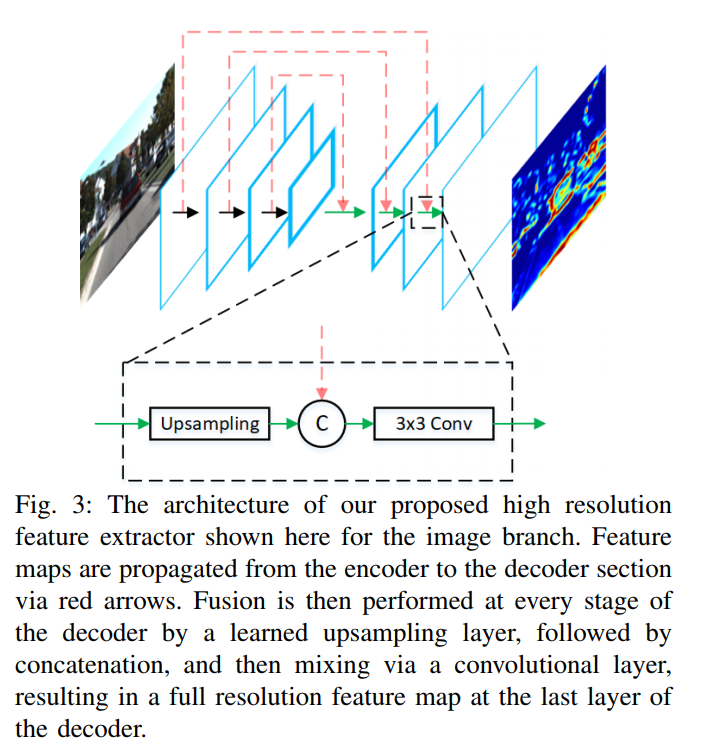
2.3 データ量の削減
それぞれの特徴抽出後、1*1 畳み込み演算を通過することでチャネル数が削減されます。元の論文から引用:
一部のシナリオでは、100K アンカーのフィーチャ クロップを GPU メモリに保存するには、領域提案ネットワークが必要です。高次元特徴マップから特徴クロップを直接抽出しようとすると、
入力ビューごとに大きなメモリ オーバーヘッドが生じます。たとえば、256 次元の特徴
マップから 100K アンカーの 7 × 7 の特徴クロップを抽出するには、32 ビット浮動小数点表現を仮定すると、約 5 GB1 のメモリが必要です。さらに、このような高次元の特徴クロップを RPN で処理すると、計算要件が大幅に増加します。
2 段階の AOVD は、ターゲット フレームの検出、データ レベルと特徴レベルの 2 段階の融合という 2 つの側面に反映されており、基本的なプロセスは次のとおりです。
1. AVOD は、RGB 画像と点群 BEV を 2 つのパスに分割し、特徴抽出に FPN ネットワーク (FPN の詳細については説明しません) を使用して、2 つの入力フル解像度特徴マップ (画像特徴マップと BEV 特徴マップ) を取得します。高さマップと密度プロット)。
2. 2 つの特徴マップについて、それらを融合するには、一貫したサイズに調整する必要があり、それぞれ 1x1 の畳み込み、さらに特徴抽出を行い、同じサイズに調整した後、融合が実行されます。最初のフュージョンと 2 番目のフュージョンはデータレベルのフュージョンに相当します。
3. 最初の融合後の特徴は、Faster RCNN と同様の RPN ネットワークに送信され、完全に接続された層と NMS の後、最初の分類と 3DBBox 回帰の後、一連のエリア提案ボックス (候補ボックス) が生成されます。
4. 生成された提案フレームは、最初のステップで生成された双方向特徴マップと結合され、サイズ変更後に 2 回目の融合 (領域提案フレームの融合) が実行されます。
5. 完全接続層の 2 番目の分類と 3DBBox 回帰操作の後、融合された特徴は NMS によって後処理され、最終的にターゲット検出フレームが生成されます。
2.5 検出フレームの符号化
AVOD では、アルゴリズムは高さマップと密度マップという 2 つの方法を使用して BEV データを表現します。
ハイトマップ: BEV 視点領域から、MxN のような一定サイズのグリッドに分割され、各グリッド内で高さ 0 ~ 2.5 の垂直空間が高さ方向から K 層に分割され、BEV透視点群空間をM×N×Kの三次元格子(Voxel)に分割し、同時に各三次元格子における最大高さH_maxを求めます。このようにして、高さマップを形成するための M x N x K H_max が存在します。
密度マップ: 前のステップの M x N x K の 3 次元格子 (ボクセル) に基づいて、各 3 次元格子の点群点密度を計算します。計算式は、M x N x K の密度値です。密度マップを構成します。
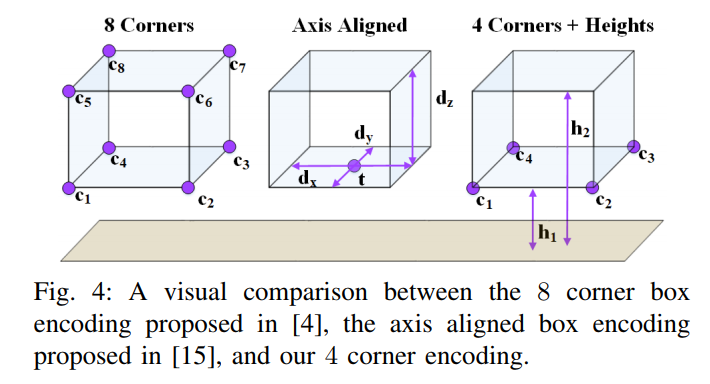
革新的な 3D バウンディング ボックスのベクトル表現:
一般的な方法は次のとおりです。2 次元の検出フレームの場合、4x2(x, y) の合計 8 つの値を使用するか、中心点 + サイズ表記: 1 (長さ) + 1 (幅) + 2 (x, y) の合計を使用します。 4 つの値の値 Value. 3D 検出フレームの場合、8x3(x, y, z) の合計 24 個の値が使用されます。
AVODは、底面フレームの形状+上下側面の地面からの高さ、すなわち4×2(x,y)+高さ2×計10値を革新的に採用しており、詳細は下図、左図を参照してください。図の側は MV3D メソッドの 24 値表現で、右側は AVOD の 10 値表現です。
2.6 方位推定
MV3Dでは物体の向きの推定は物体の長辺に基づいて大まかに物体の向きを決定しますが、この方法では±180°の違いを区別することができず、この方法は現実的ではありません。歩行者の検知。
そこで、AVOD ではこの種の問題に対して、姿勢推定で導入され、
で限定された手法が使用されています
。このように、向きが 180°異なる場合には発散はなく、それぞれが固有の値を持ちます。
