(1) それは何ですか?
数十億個の最大値または最小値の中から最初の 1000 個を選択するなど、キーワードが多い状況に適したソート アルゴリズムです。従来の
ソート アルゴリズム (バブリング、挿入など) では、データ全体をターゲットにして、最初の 1000 個の最小または最大のデータをインターセプトします。
しかし、最初から目標が 1,000 のみであることは想像できるため、実際には、残りの 9 億 9,999 万 9,000 個のデータは、その並べ替え順序をまったく知る必要はなく、それらがすべて比較されるということだけを知る必要があります。 1000 個のターゲット データは大きくなければなりません。
これはヒープ ソートです。
そのアイデアは全体的に非常に明確かつシンプルであり、その構造は完全な二分木です。
ルート ノードが左右の子ノードよりも大きい場合、それはビッグ ルート パイルと呼ばれます。このうち、左右の子のルート ノードは、左右の子よりも大きくなります。
ルート ノードが左右の子ノードよりも小さい場合、それは小さなルート パイルと呼ばれます。このうち、左右の子のルート ノードは、左右の子よりも小さくなります。
もっと簡単に言うと、すべての中間ノードはその子よりも大きくなければならない (大きなルート パイル)、またはその子よりも小さくなければなりません (小さなルート パイル)。
(2) 大きなルートヒープを構築する方法
初期化:
1: 指定された配列に従って、まずレベル優先度に従ってバイナリ ツリーを構築します (レイヤーごとに配置)
2: バイナリ ソート ツリーの最後のリーフ ノードのルート ノードから開始して、バイナリ ソート ツリーの左右の子を比較します。ノード、ルート ノードへの最大の順列を選択します
3: 最後から 2 番目の非リーフ ノードを配置し、ルート ノードと比較して最大の順列を選択します...
4: など、完全なツリーがソートされるまで続きます。ツリーのルート ノード 大きなルート ヒープの最大値 5 である必要があります
。大きな数値を押し上げるプロセスでは、交換位置の数値が左右の子よりも大きいかどうかにも依存します。そうでない場合は、 、次に、子ルート ノードに変更する最大のものを選択します。
例: 大きなルート ヒープの確立を必要とする配列 [1、3、5、7、9、2、4、6、8、10] があるとします。
1: まず、階層優先順位の原則に従ってバイナリ ツリーを構築します (ツリーが生成された後、デフォルトでは行トラバーサルに従って 1 次元配列に格納され、配列の添字は 1 から始まります)。添字 1 はルート ノード 1 を格納し、添字 2 は左の子 2 を格納し、添字 3 は右の子 5 を格納する、など)
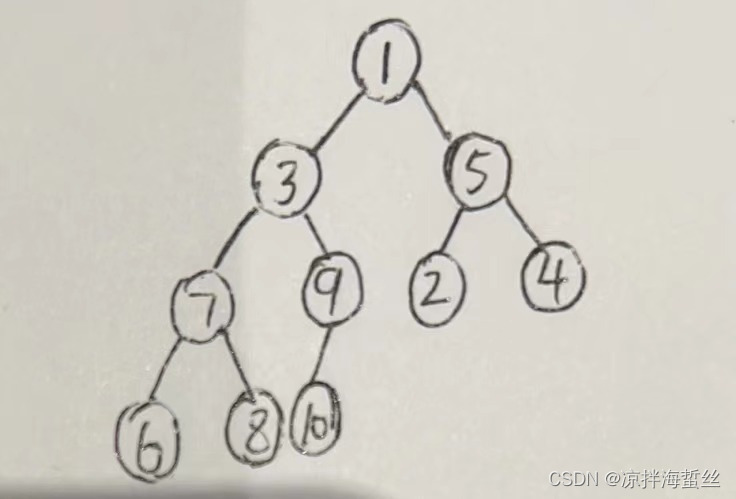
2: バイナリ ツリーの最後の非リーフ ノードから開始し、ノードの左右の子を比較し、ルート ノードまでの最大の順列を選択します。バイナリ ツリーの最後の非リーフ ノードを見つける方法: n/ 2 この例の 10 要素を切り捨てると
、10/2 = 5 になります。つまり、葉以外の最後のノードの添字は 5、つまりルート ノード値が 9 であるサブツリーになります。
9 と 10 を比較すると、10 が最大であることがわかり、10 と 9 の位置が入れ替わります。
3: 最後から 2 番目の非リーフ ノードを配置し、ルート ノードと比較して最大の代替ノードを選択します...
最後から 2 番目の非リーフ ノードを見つける方法: n/2 - 1 = 4
は添字 4、ルート ノード値 7 のサブツリーは
6、7、8 を比較するため、7 と 8 の位置が交換され、8 がルート ノードになります。
4: 同様に、完全なツリーがソートされるまで、ツリーのルートノードは、現時点では大きなルート パイルの最大値である必要があります。
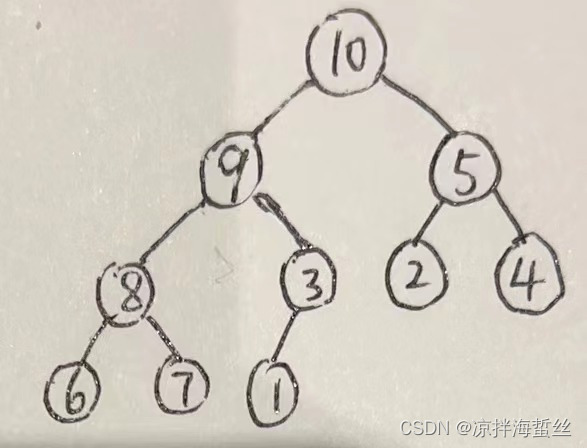
この時点で、大きなルート ヒープの構築が完了します。
スタックの最上位要素を出力します。
スタックの先頭で 10 を出力した後、[最後のリーフ ノード] 1 で修正すると、1 は大きなルート ヒープの性質を破壊するため、ルート ノードから下方に調整する必要があることがわかります。 1, 9, 5; 9 ルートノードを置きます。
1 は左側のサブツリーのルート ノードに沈みますが、まだ大きなルート パイルの性質を満たしていないため、1、8、3 を比較し、8 を左側のサブツリーのルート ノードに置き、1 は左側のサブツリーに沈みます左サブツリーのルート ノードの 1、6、7 を再度比較し、7 を
左サブツリーの左サブツリーのルート ノードに置き換えて、再び 1 をシンクします。
これまでのところ、再調整されたバイナリ ツリーは、大きなルート ヒープの性質に再び準拠しています。
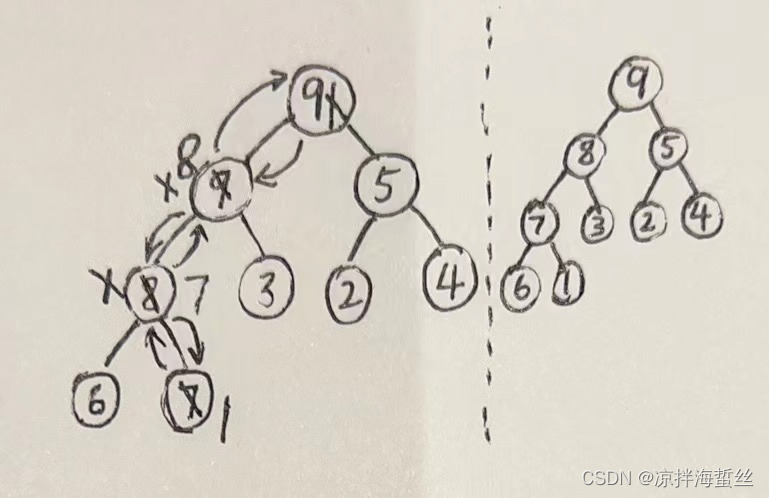
要素の追加/挿入操作:
新しく追加/挿入される要素は、新しく生成された最後のリーフ ノードに新しいノードを配置し、新しいリーフ ノードのデータの値とその親ノードの値を比較して、位置を変更する必要があるかどうかを確認します。 、調整を開始します。これは初期化と同じ操作です。
⚠️ 初期化と要素の追加は下から上に調整され、スタックの最上位の要素の削除は上から下に調整されることに注意してください。
コード:
#include <stdio.h>
void HeapSort(int a[], int i, int lenght){
/*用以保存子树的根结点*/
a[0] = a[i];
/* 按照二叉树性质,不断i*2是不断深入找到下一层的左孩子结点 */
for(int j=i*2; j<=lenght; j=j*2){
/* k是对应子树的右孩子结点,先比较右孩子 */
int k = j+1;
/* 左右孩子比较出一个大值 */
if(k<lenght && a[k]>a[j]){
j = k;
}
/* 判断根结点与左右孩子的最大值谁更大 */
if(a[0]<a[j]){
a[i] = a[j];
i = j;
}
}
/* 循环退出后,j一定是最适合temp值的地方 */
a[i] = a[0];
}
int main()
{
int a[]={
0,1,3,5,7,9,2,4,6,8,10};
int lenght = 11;
/* 从下往上逐个非叶子结点调整 */
for(int i=lenght/2; i>0; i--) {
HeapSort(a,i,lenght);
}
return 0;
}