InstructGPT 原文: https://arxiv.org/pdf/2203.02155.pdf
chatCPT トライアル接続: https://chat.openai.com/auth/login
chatGPT は登場以来爆発的に増加し、現在 1 億人の登録ユーザーがいます。ChatGPTの撤退により大手企業がAIGCを次々と導入しており、ChatGPTがもたらす変化はGoogleの既存の検索製品やビジネスモデルを根底から覆すだろうと予測する人も多い。この投稿のわずか 1 時間前に、Google は ChatGPT に対してBardを立ち上げ、防衛戦を開始すると発表しました。Bard は数週間以内に一般公開される予定です。人工知能の分野で大きな反響を呼ぶchatGPTはどのように機能するのでしょうか?以下に、インターネット上の chatGPT の原理に関するリソースを要約します。
全体的な技術的ルートの観点から見ると、ChatGPT は GPT-3.5大規模言語モデル ( LLM 、Large Language Model )を使用し、このモデルに基づいて強化学習を導入して、事前トレーニングされた言語モデルを微調整します。ここでの強化学習には、RLHF ( Reinforcement Learning from Human Feedback )、つまり手動ラベル付けの手法が使用されます。その目的は、LLM モデルにさまざまな NLP タスクを理解させ、報酬と罰のメカニズム (報酬) を通じてどのような回答が高品質 (有用性、正直さ、無害性の 3 つの側面) であるかを判断できるようにすることです。ここでは、chatGPT に関する基礎知識と原理について説明します。
1、GPT
GPT の正式名称は Generative Pre-Trained Transformer で、その名前が示すように、GPT の目的は、Transformer を基本モデルとして使用し、事前学習技術を使用して一般的なテキスト モデルを取得することです。
(1) GPT-1 は BERT より数か月早く誕生しました。これらはすべて、コア構造として Transformer を使用します。違いは、GPT-1 が事前トレーニング タスクを左から右に構築し、一般的な事前トレーニング モデルを取得することです。このモデルは、BERT と同様に下流タスクに使用できます。チューニング。GPT-1 は、当時 9 つの NLP タスクで SOTA の結果を達成しました。
(2) GPT-1 と比較して、GPT-2 はモデル構造については大騒ぎせず、より多くのパラメータとより多くの訓練データを持つモデルを使用しただけです (表 1 を参照)。GPT-2の最も重要な考え方は、「すべての教師あり学習は教師なし言語モデルのサブセットである」という考え方であり、これはプロンプト学習の前身でもあります。GPT-2 も誕生当初は大きなセンセーションを巻き起こしましたが、GPT-2 が生み出すニュースはほとんどの人間を欺き、虚偽の効果をもたらすのに十分です。当時は「AI界で最も危険な兵器」としても知られ、多くのポータルがGPT-2によって生成されたニュースの使用禁止を命じた。
(3) GPT-3 が提案されたとき、GPT-2 のはるかに優れた効果に加えて、さらに議論を引き起こしたのは、その 1,750 億のパラメータ量でした。研究者らは、GPT-3 が一般的な NLP タスクを完了できることに加えて、SQL、JavaScript、その他の言語コードの記述や単純な数学演算の実行においても GPT-3 が優れたパフォーマンスを発揮することを予期せず発見しました。GPT-3 のトレーニングでは、メタ学習 ( Meta-learning )の一種である状況学習 ( In-context Learning )が使用されます。メタ学習の中心的な考え方は、少量のデータから適切な初期化範囲を見つけることです。これにより、モデルは限られたデータセットに高速に適合し、良好な結果が得られます。
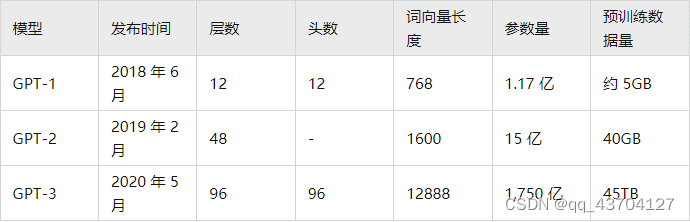
表1 GPTシリーズ
2. 学習の指導と学習の促進
命令学習は、2021 年に「Finetuned Language Models Are Zero-Shot Learners」というタイトルの記事で Google Deepmind の Quoc V.Le チームによって提案されたアイデアです。この記事では、FLAN (Finetuned Language Models Are) と呼ばれる命令チューニング ベースの手法が提案されています。 Zero-Shot Learners).Net)、命令チューニング- 命令によって記述されたタスクのコレクション (60 を超える NLP タスク) に関する言語モデルを微調整します。
プロンプト学習とは、入力されたテキスト情報を特定のテンプレートに従って処理し、事前にトレーニングされた言語モデルを最大限に活用できる形式にタスクを再構築することを指します。次の図は、ファインチューニングとプロンプト学習の違いを示しています:ファインチューニングでは、事前トレーニングされた言語モデルがさまざまな下流タスクに「対応」します。プロンプトでは、さまざまな下流タスクが事前トレーニングされた言語モデルに「対応」します。
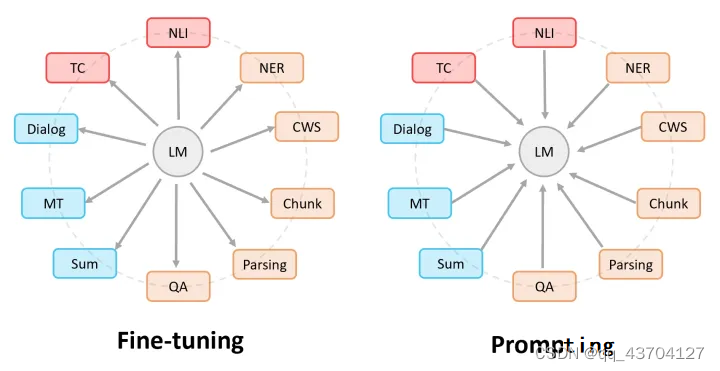
指示は、言語モデルの理解能力 を刺激し、より明確な指示を与えることでモデルが正しいアクションを実行できるようにします。プロンプトは、文の前半に基づいて文の後半を生成したり、クローズしたりするなど、言語モデルの完成能力を刺激することです。例は次のとおりです。
(1) 学習のヒント: このネックレスをガールフレンドのために購入しました。彼女はとても気に入っています。このネックレスは____すぎるです。
(2) 指示学習: この文の感情を判断する: 私はガールフレンドのためにこのネックレスを買いました、そして彼女はとても気に入っています。オプション: A= 良好、B= 良好、C= 不良。
命令学習の利点は、ヒント学習がすべて 1 つのタスクに対して行われるのに対し、マルチタスクの微調整後に他のタスクでもゼロショットを実行できることです。一般化は指導による学習ほど優れていません。微調整、ヒント学習、および指示学習は、次の図で理解できます。

3. 強化学習
強化学習の最も基本的な 2 つの要素は、状態や報酬関数などの観察です。教師あり学習の 2 つの最も基本的な要素は、トレーニング データとラベルです。観測値はトレーニング データとして使用でき、報酬関数は損失関数として使用でき、ラベルも利用できるため、これら 2 つは完全にシームレスにリンクされています。このようにして、エージェントが環境内で実行されている間、トレーニング データとラベルを継続的に取得することができ、本質的に、エージェントの動作は徐々に報酬関数に適合します。強化学習ではデータに手動でラベルを付ける必要はありませんが、機械が自動的にラベルを学習することができます。教師あり学習では多くの場合、人工的にラベル付けされた多数のデータセットが必要ですが、強化学習では、環境と対話できるエージェント(エージェント)が自ら目標を達成する方法を学習できるように、環境と目標を人工的に作成する必要があります。
強化学習は、従来のモデル トレーニングメカニズムの損失関数とみなすことができる報酬 ( Reward ) メカニズムを通じてモデル トレーニングをガイドします。報酬の計算は損失関数よりも柔軟かつ多様です (AlphaGO の報酬はゲームの結果です)。その代償として、報酬の計算は導出できないため、バックプロパゲーションに直接使用することはできません。強化学習の考え方は、モデルのトレーニングを実現するために、多数の報酬をサンプリングすることで損失関数を適合させることです。同様に、人間のフィードバックは導出できないため、人間のフィードバックを強化学習の報酬として使用することもでき、人間のフィードバックに基づく強化学習が誕生しました。
InstructGPT/ChatGPT で使用される RLHF は、2017 年に Google によって公開された「Deep Reinforcement Learning from Human Preferences」に遡ることができます。これは、手動のアノテーションをフィードバックとして使用し、シミュレートされたロボットや Atari ゲームでの強化学習のパフォーマンスを向上させます。
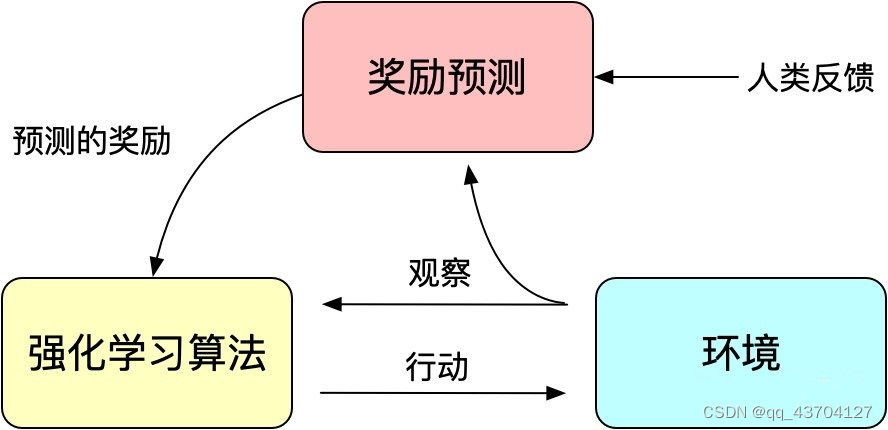
図: 人間のフィードバックによる強化学習の基本原理
InstructGPT/ChatGPT は、強化学習に別のアルゴリズムである近接ポリシー最適化 (PPO) も使用します。PPO アルゴリズムは、新しいタイプのポリシー勾配アルゴリズムです。ポリシー勾配アルゴリズムはステップ サイズに非常に敏感ですが、適切なステップ サイズを選択するのは困難です。 1. トレーニング プロセス中に新しい戦略と古い戦略のステップ サイズが大きすぎる場合、学習には役に立ちません。PPO は、複数のトレーニング ステップで小さなバッチを更新できる新しい目的関数を提案します。これにより、ポリシー勾配アルゴリズムでステップ サイズを決定するのが難しいという問題が解決されます。
4. InstructGPT/ChatGPT原則の解釈
(1) InstructGPT処理
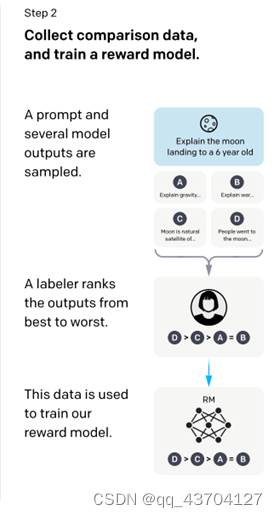
InstructGPT/ChatGPTはいずれもGPT-3のネットワーク構造を採用しており、命令学習を通じてトレーニングサンプルを構築することでコンテンツ予測の効果を反映した報酬モデル(RM)をトレーニングし、最終的にスコアリングを通じて強化学習モデルのトレーニングを誘導します。この報酬モデル。プロセスは次のとおりです。
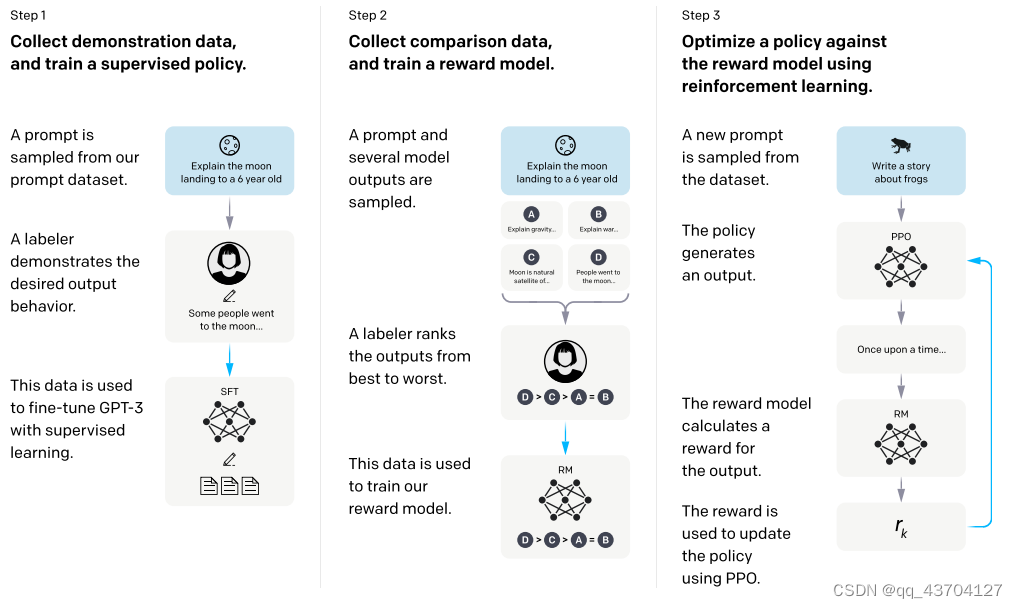
InstructGPT の計算プロセス: (1) 教師あり微調整 (SFT); (2) 報酬モデル (RM) トレーニング; (2)
(3) PPO による報酬モデルに従って強化学習が行われます。
具体的な手順は次のように説明されます。
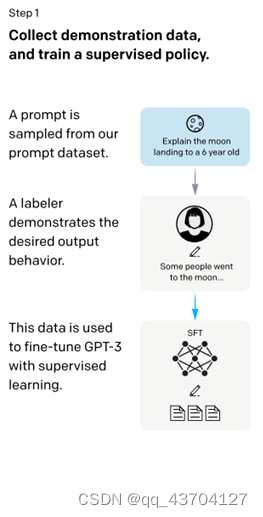
ステップ 1.) GPT-3 入力文データセットから入力の一部をサンプリングします。これらの入力に基づいて、手動アノテーションを使用して期待される出力結果と動作を完成させ、これらのアノテーション データを GPT-3 教師ありトレーニングに使用します。このモデルは、命令型 GPT のコールド スタート モデルとして機能します。
ステップ 2.) サンプリングされた入力文で、前向き推論を実行して複数のモデル出力結果を取得し、手動の注釈によってこれらの出力結果を並べ替えてマークします。最後に、これらのラベル付きデータは、報酬フィードバック モデルのトレーニングに使用されます。
ステップ 3.) 新しい入力文をサンプリングすると、政策戦略ネットワークは出力結果を生成し、報酬フィードバック モデルを通じてフィードバックを計算します。フィードバックは政策戦略ネットワークに順番に作用します。これを繰り返して、標準的な強化学習トレーニング フレームワークを示します。
要約すると、ChatGPT (対話 GPT) は実際にはInstructGPT (指導GPT )の相同モデルであり、指導 GPT はGPT-3に基づいています。まず、強化学習のコールド スタート モデルと報酬フィードバック モデルは、手動ラベル付け、そして最後に、強化学習を通じて対話型のChatGPTモデルを学習します。
(2) InstructGPTで使用するデータセット
InstructGPT は、SFT データセット、RM データセット、PPO データセットという 3 つのデータセットを使用します。
SFT データセットは、最初のステップで教師ありモデルをトレーニングするために使用されます。つまり、収集された新しいデータを使用して GPT-3 のトレーニング方法に従って GPT-3 を微調整します。GPT-3 はプロンプト学習に基づく生成モデルであるため、SFT データセットはプロンプトと回答のペアで構成されるサンプルでもあります。RM データセットは、ステップ 2 で報酬モデルをトレーニングするために使用されます。
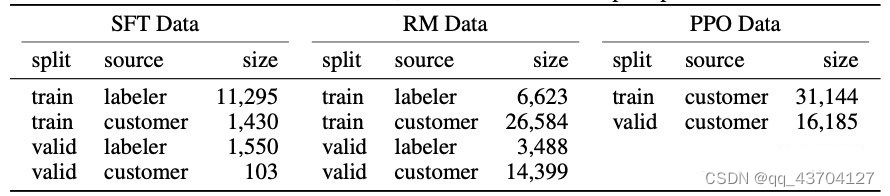
表 2: InstructGPT のデータ分布
(3) InstructGPTの3段階の詳細説明
InstructGPT の要約: RLHF は第 1 段階と第 2 段階で使用されます。まず、gpt モデルを手動でラベル付けして微調整することによって SFT モデルが取得されます。SFT モデルは手動ランキング用の k 個の回答を生成するために使用されます。RM モデルは訓練された。第 3 段階では、SFT モデルのパラメーターが取得され、RM モデルによって得られた報酬がトレーニングに使用され、pro モデルと pro-ptx モデルが取得されます。
- 教師あり微調整 (SFT)
このステージの入力は、テスト ユーザーが送信したプロンプト (指示または質問) からランダムに抽出されたデータのバッチ (SFT データ セット) であり、主に 2 つのステップに分かれています。
- 抽出されたプロンプト データに対して高品質の回答を手動で提供し、<プロンプト、回答> データ ペアを取得します。
- 高品質の回答を使用して gpt-3.5 (InstructGPT) モデルを微調整し、モデルが最初の段階で入力命令をよりよく理解できるようにします。
このようにして、ここでは基本的な GPT-3.5 言語モデルを SFT モデルとして学習します。
- 報酬モデル (RM)
RM 構造は、SFT トレーニング済みモデルの最後の埋め込み層を削除した後のモデルです。入力はプロンプトと応答であり、出力は報酬値です。大きく分けて次の2つのステップに分かれます。
 プロンプトごとに、InstructGPT/ChatGPT は K 個の出力 (4<=K<=9) をランダムに生成し、出力結果をペアで各ラベラー (ラベル作成者) に表示します。つまり、各プロンプトは結果の合計を表示します。ユーザーは、よりパフォーマンスの高い出力を選択します。つまり、ランキング順序に手動で注釈を付けます。
プロンプトごとに、InstructGPT/ChatGPT は K 個の出力 (4<=K<=9) をランダムに生成し、出力結果をペアで各ラベラー (ラベル作成者) に表示します。つまり、各プロンプトは結果の合計を表示します。ユーザーは、よりパフォーマンスの高い出力を選択します。つまり、ランキング順序に手動で注釈を付けます。- 並べ替えの結果を使用して、データ ペア <プロンプト、回答> をトレーニングします。トレーニング中、InstructGPT/ChatGPT は
 各プロンプトの応答ペアをバッチとみなします。プロンプトに基づくこのバッチ トレーニング方法は、サンプルに基づく従来のバッチ方法よりも優れています。この方法では、各プロンプトがモデルに 1 回だけ入力されるため、オーバーフィットになる可能性が低くなります。
各プロンプトの応答ペアをバッチとみなします。プロンプトに基づくこのバッチ トレーニング方法は、サンプルに基づく従来のバッチ方法よりも優れています。この方法では、各プロンプトがモデルに 1 回だけ入力されるため、オーバーフィットになる可能性が低くなります。
報酬モデルの損失関数は、ラベラーの好ましい応答と嫌いな応答の間の差を最大化することです。式は次のとおりです。

ここで、r θ(x,y)はパラメータ θ をもつ報酬モデルに基づくプロンプト x と応答 y の報酬値、yw はラベラーが好む応答結果、yl はラベラーが好まない応答結果です。D はトレーニング データセット全体です。
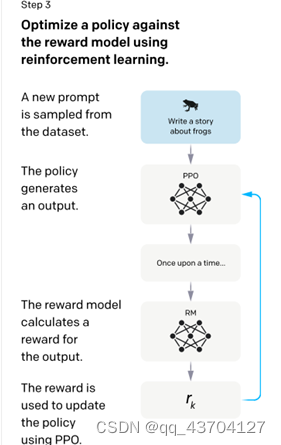
- 強化学習モデル (PPO)
このステップのデータセットは第 1 段階や第 2 段階とは異なり、より大きく、手動作業は必要ありません。その方法は次の 4 つの部分に要約できます。
- PRO モデルのパラメータは、第 1 段階の教師ありモデルによって初期化されます。
- PRO モデル生成の回答
- 応答は第 2 段階の RM モデルを使用して評価され、スコア付けされます。
- スコアリングによるトレーニング PRO モデルのパラメーターの更新
InstructGPT/ChatGPT はトレーニング プロセス中に 2 つの問題に遭遇しました。
問題 1: モデルが更新されると、強化学習モデルによって生成されたデータと報酬モデルのトレーニングに使用されたデータの差がますます大きくなります。著者の解決策は、KL ペナルティ項 βlog( π φ RL y x / π SFT(y|x))を損失関数に追加して、 PPOモデルの出力とSFTの出力が大きく変わらないようにすることです。。
問題 2: PPO モデルのみをトレーニングに使用すると、一般的なNLPタスクでのモデルのパフォーマンスが大幅に低下します。著者の解決策は、一般的な言語モデルの目標 γ E X~ D pretrain [ log ( π φ RL(x))]、この変数は論文では PPO-ptx と呼ばれます。
要約すると、PPO のトレーニング目標は次のとおりです。

5. 実験とモデルの測定
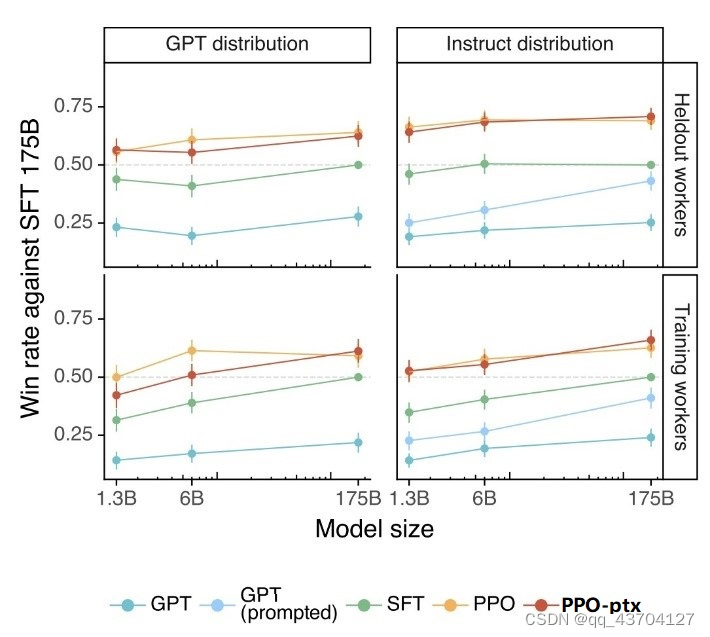
- 役立つ - ユーザーの意図を推測できるかどうか
テスト方法は、アノテーターがテスト対象モデルの出力とSFTモデルの出力のうち、より良い方を選択するというものです。スコア 0.5 は、モデルが SFT とほぼ同じパフォーマンスを発揮することを意味します。下図の左側は GPT が提供するプロンプト、右側は instructGPT が提供するプロンプト テストの結果です。pro および pro-ptx モデルが他のモデルよりも優れた結果を達成していることがわかります。
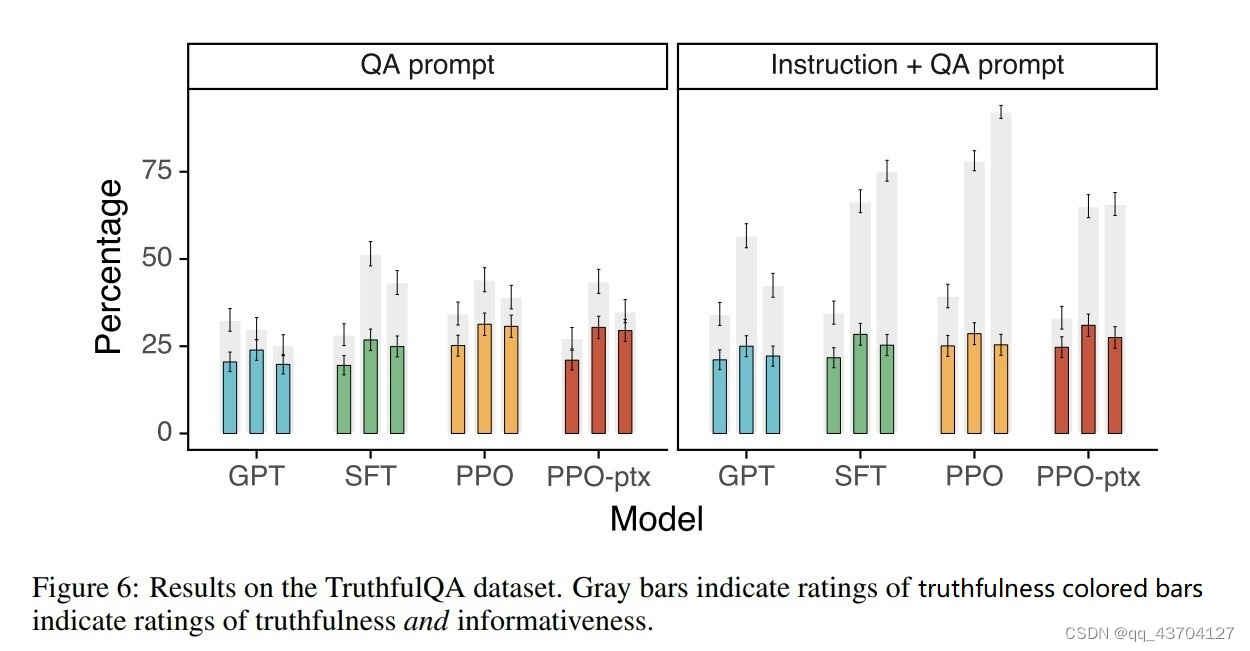
- 本音
方法としては、モデルの前に次のような指示プロンプトを追加して、注意すべき質問とその回答方法をモデルに思い出させます。

結果は以下の通りで、右の図が命令を追加した結果です。このうち、灰色は信頼性を表し、色付きは信頼性と情報内容の両方の比率を表します。
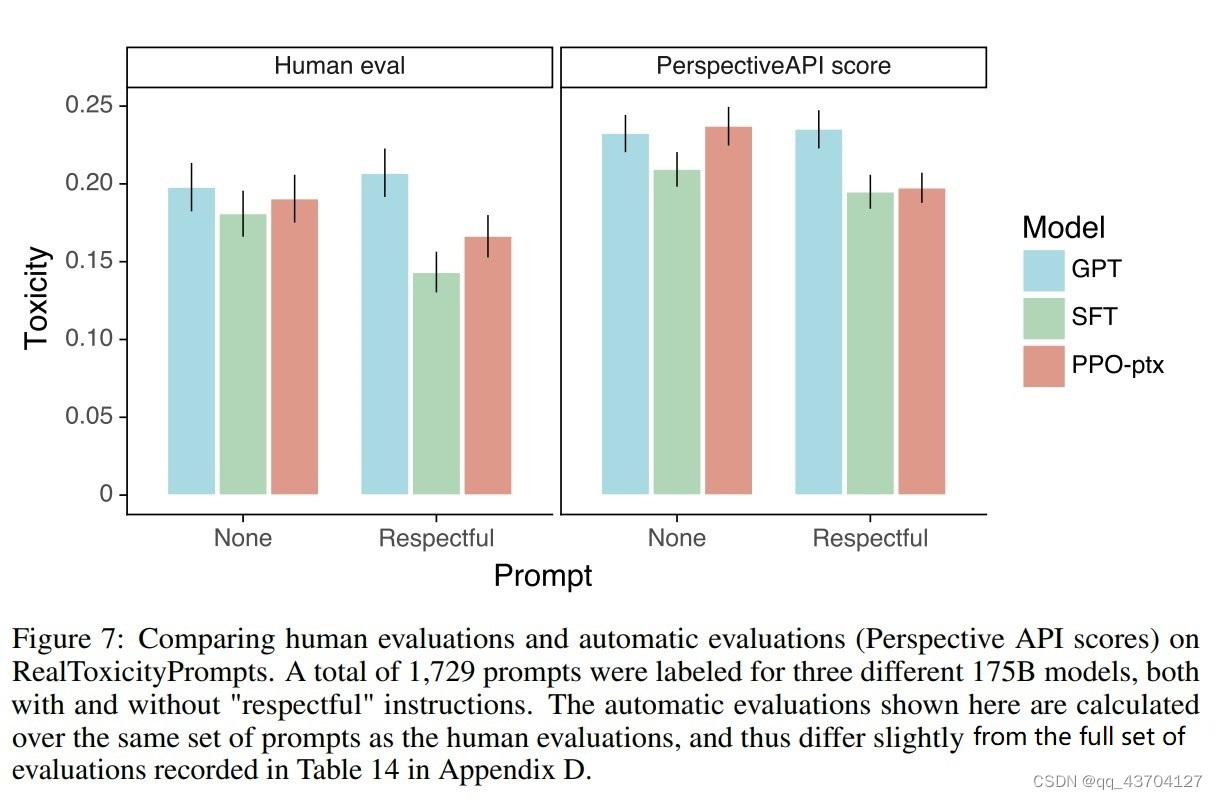
- 無害な
この方法では、有害/失礼/偏った回答を生成するモデルを減らすために指示を追加することもできます。その効果は次のとおりです。
参考リンク: