分散システムのコンセンサス メカニズム: コンセンサス アルゴリズムの設計アイデア
今回は私が学んだコンセンサスアルゴリズムをマクロな視点からまとめてみます。コンセンサス アルゴリズムの目標は、分散システム内のほとんどのノードとデータの一貫性を保つことです。
pow や pos などのブロックチェーンのコンセンサス アルゴリズムもこの範囲に属しますが、これらはブロックチェーン分野でのみ適用されます。以下で紹介するコンセンサス アルゴリズムは分散システムで広く使用されており、もちろんブロックチェーンでも間違いなく適用できます。そして最後に私は彼らのデザインアイデアを要約しました。実際には、特定のルーチンがあります。
Paxos アルゴリズム
1 つ目は paxos アルゴリズムで、多数のエンジニアリング実践でテストされており、多くの Google プロジェクトやビッグ データ コンポーネントの動物園キーパーで使用されています。実装は非常に複雑ですが、基本的な考え方を理解するのは難しくありません。
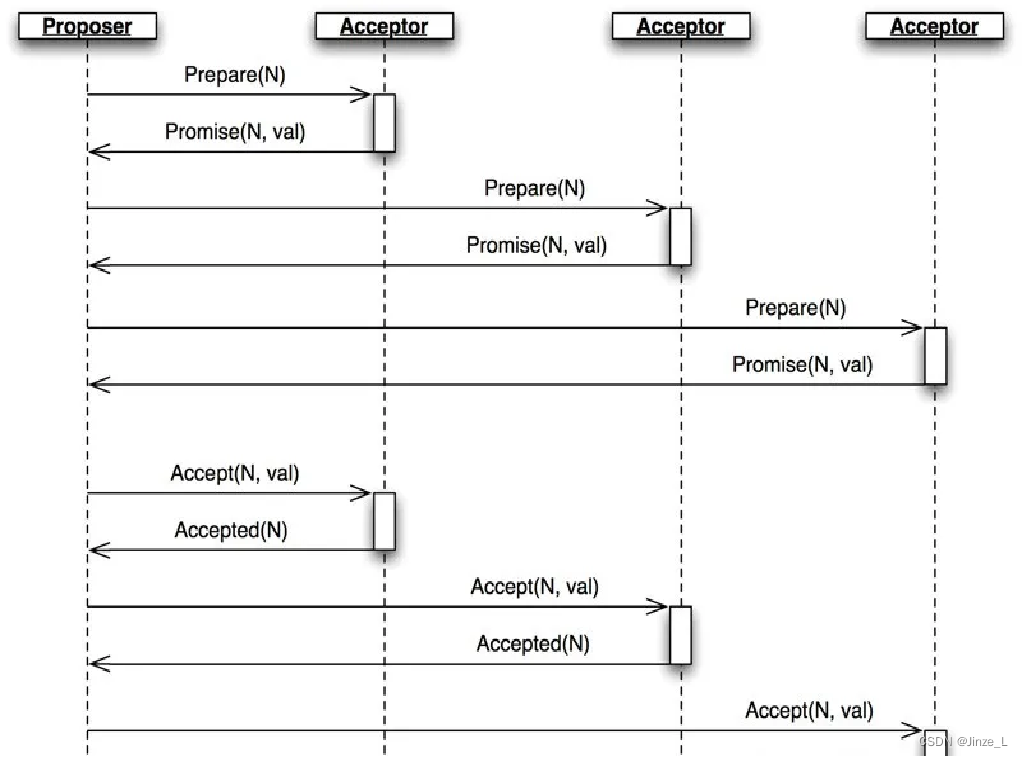
ノードの役割
Paxos ノードには 3 つの役割があります。つまり、次のとおりです。
最初のタイプは提案者であり、提案、つまり同期されるデータの提案を担当します。
2 番目のタイプの承認者は、提案者が提案した提案は承認者の半数以上によって承認される必要があります。
3 番目のタイプの学習者。プロポーザルには参加せず、確認されたプロポーザルを受信することのみを担当します。通常、外部読み取りサービスを提供するクラスターの能力を向上させるために使用されます。
アルゴリズム処理
アルゴリズムの具体的なプロセスには主に 3 つのステージがあります。
最初のステージは準備ステージです。提案者は提案番号 N を選択し、この番号の準備リクエストを承認者に送信します。承認者はリクエストを受け取った後、ローカルで応答したPrepareリクエストの数よりNが大きいかどうかを判断し、大きい場合はその数を提案者にフィードバックし、Nより小さい数の提案は承認しません。次に、承認フェーズ
があります。提案者が半数以上の承認者から応答を受け取った場合、[N,val] プロポーザルの承認リクエストを承認者に送信します (val はプロポーザルの値)。次に、承認者は対応する値を受け入れ、提案者に応答を返します。この時点までに、承認者と提案者の両方が合意に達しています。最後に、 「学習」ステージに入ります。このステージは、提案を選択するプロセスには属しません。提案者は、承認された提案をすべての学習者に同期します。最終的には、ほとんどのノードが合意に達します。
明らかに、このアルゴリズムはビザンチン ノードを備えた分散システムには適しておらず、通常の分散システムにのみ適しています。
Raftアルゴリズム
Paxos の原理は比較的理解しやすいですが、その工学的実装は非常に複雑であるため、Paxos アルゴリズムを簡略化した実装である Raft アルゴリズムが登場します。基本的な考え方は同様です。
ノードの役割
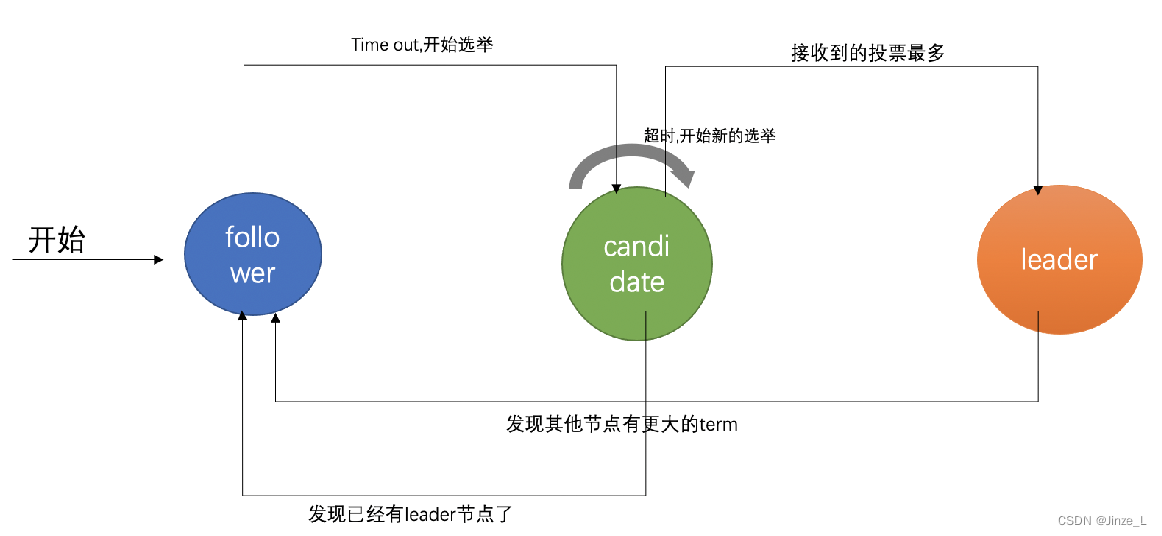
同様に、ノードにも 3 つの役割があり、
1 つはクラスターの初期状態であるフォロワーであり、ノードが参加すると、デフォルトでフォロワー、つまりスレーブ ノードになります。
次に、選挙中の有権者の称号である候補者です。これは中間的な役割であり、たとえば、フォロワー A がフォロワー B に投票した場合、フォロワー B の役割が候補となります。
最後に、リーダー マスター ノードは、ユーザー リクエストを受信し、データ同期を実行するために使用されます。
コアメカニズム
RAFT アルゴリズムは、リーダーの選択とログの複製の2 つのフェーズに分かれています。
まず、リーダーがどのように選ばれるかを見てみましょう。
リーダー選挙
アルゴリズムの開始時点では、すべてのノードはフォロワーであり、各ノードにはタイマーがあり、リーダーからメッセージを受信するとタイマーがリセットされます。タイマーが期限切れになると、一定期間内にリーダーからのメッセージが受信されなかったことを意味し、リーダーは不在とみなされ、ノードは候補に変換され、リーダーをめぐって競争する準備が整います。
候補者となったノードは他のノードに投票リクエストを送信し、リクエストを受け取った他のノードはその候補者に投票するかどうかを判断し、結果を返します。候補者は、投票の過半数を獲得した場合にリーダーになることができます。候補者になると、任期中に定期的にハートビート メッセージを送信して、任期中に他のノードに新しいリーダーの情報を通知します。これはタイマーをリセットするために使用されます。他のノードが候補になるのを防ぎます。
ログのレプリケーション
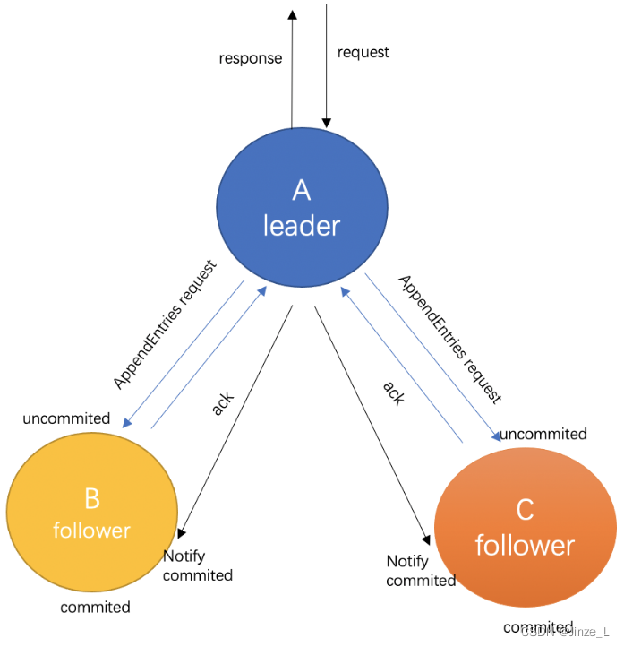
リーダーが選出されたら、データの同期を開始する必要があります。
リーダーがクライアントのリクエストを受信すると、そのリクエストをログ パッケージにパッケージ化して他のノードに送信します。このプロセスはログ レプリケーションと呼ばれます。他のノードはデータを受信後、マスターノードにACKを応答します。
リーダーは、クラスター内のノードの半分以上が応答するのを待ってから、データを受信したことをクライアントに応答します。この時点で、データが送信された状態に入ります。
最後に、リーダー ノードがデータのステータスが送信されたことを他のノードに通知し、他のノードが自身のデータのコミットを開始するこの時点で、クラスターはマスター ノードとスレーブ ノード間の整合性に達します。
ここで紹介した raft アルゴリズムと paxos アルゴリズムは両方とも、ビザンチンの一般的な問題がないことを前提としており、ノードのダウンタイム、ネットワークの分断、信頼性の低いメッセージなどの問題のみを考慮します。次のアルゴリズムは、ノードが悪さをしている状況を考慮しています。最も古典的で実用的なのは pbft で、このアルゴリズムの実装内容についてはこれまで何度も紹介してきましたが、今回は別の角度から解釈してみます。
PBFT
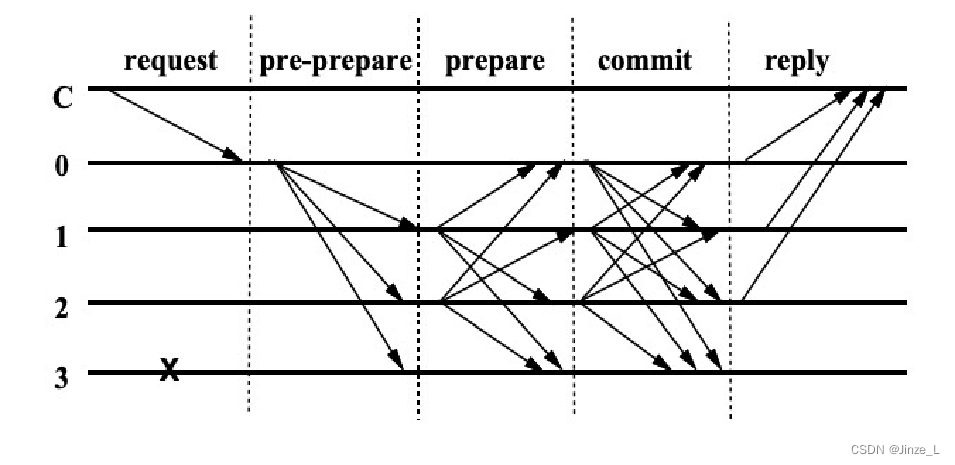
まず第一に、ストア ノードはさまざまなストア ノードの役割、つまり
トランザクションをブロックにパッケージ化する役割を担うマスター ノードにも分割されており、コンセンサス プロセスの各ラウンドで存在できるマスター ノードは 1 つだけです。
レプリカ ノードはコンセンサス投票を担当し、コンセンサスの各ラウンドには複数のレプリカ ノードが存在します。
プロセス:
クライアントはマスター ノードにリクエストを送信し、
マスター ノードはリクエストを他のノードにブロードキャストし、ノードは PBFT アルゴリズムの 3 段階のコンセンサス プロセスを実行します。
3 段階のプロセスの後、メッセージをクライアントに返します。
クライアントが f+1 個のノードから同じメッセージを受信すると、コンセンサスが正しく完了したことを意味します。
投票に基づくコンセンサス アルゴリズムは基本的にルーチンです。提案を行うリーダーを決定し、他のノードが投票を担当します。投票結果に応じて、提案が可決されるかどうかが決定されます。マスターノードが提案を提出すると、他のノードの投票と投票の収集は各ノードで独立して完了します。これは、ビザンチンノードの存在により、ノードは取得した投票情報のみを信じ、各ノードが決定するためです。収集した情報に基づいて、提案が合意に達したかどうか。
したがって、4 つの段階が設計されています。
まず、事前準備段階では、マスター ノードがレプリカ ノードに提案を送信し、レプリカ ノードが提案を受信して検証しますが、他のノードのステータスは知りません。
準備フェーズでは、各正当なノードが少なくとも 2/3 の投票を受け取ります。少なくとも 2/3 の投票を受け取るノードをイベント A と呼びます。明らかに、少なくとも 2/3 のノードがイベント A を持っています。各ノードはイベント A が発生したかどうかをお互いに知らない
ため、コミット フェーズがあり、各ノードはイベント A が発生したというメッセージを他のノードにブロードキャストし、イベント A に関する他のノードのブロードキャストも収集します。少なくとも 2/3 ノードへのイベントをイベントBと呼びます。この時点で、各ノードはイベント A が少なくとも 2/3 のノードで発生したことを認識しており、ほとんどのノードが合意に達しています。ただし、クライアントはまだ結果を知りません。
最後に応答フェーズでは、各ノードがイベント B をクライアントに返すが、このときクライアントは少なくとも f+1 ノードからイベント B のブロードキャストを収集できれば、システムが合意に達したと判断できる。少なくとも f+1 ノードを収集するイベント B のブロードキャストをイベントCと呼びます。
したがって、pbft は、これら 3 つのイベントを確実に発生させるために 4 つの段階を設定しました。
ホットスタッフ
先ほどの紹介によると、PBFT の重要な点は、各ノードが独立して投票を収集する作業を行うため、アルゴリズム全体におけるノードのワークロードが重複することになります。PBFT がこのようなことを行う理由は、ノードは自分が取得した投票情報のみを信頼するためであり、この信頼の問題が解決できれば、このような繰り返しの作業が省略されます。HotStuff によって実行される最適化はこれに基づいており、しきい値署名を使用して投票結果が偽造できないようにします。
しきい値署名
ノードの役割はPBFTと同じでマスターノードとレプリカノードに分かれます。
しきい値署名簡単に説明すると、(k, n) しきい値署名スキームは n メンバーで構成される署名グループを指し、すべてのメンバーが公開鍵を共有し、各メンバーが独自の秘密鍵を持ちます。k 人のメンバーの署名が収集され、完全な署名が生成される限り、この署名は公開鍵によって検証できます。
ここでは、しきい値署名の技術的な詳細については詳しく説明しませんが、主にアルゴリズムがどのように適用されるかに焦点を当てます。HotStuff では、リーダーは提案を行うことに加えて、他のノードから投票を収集し、投票結果を合法性の確認が容易で偽造できない証拠に統合する必要もあります。しきい値署名の特徴は、同じデータに対して十分なサブ署名がある場合にのみ署名を合成でき、他のサブ署名は最終署名を検証して署名構築プロセス全体が合法であることを確認するだけで済むことです。しきい値署名を使用すると、すべてのノードが投票情報を収集する作業をリーダーに委任できるようになり、リーダーが不正行為を行うことができなくなります。したがって、HotStuff の最終的なアルゴリズムの複雑さは直接的には 1 桁減少します。
コアメカニズム
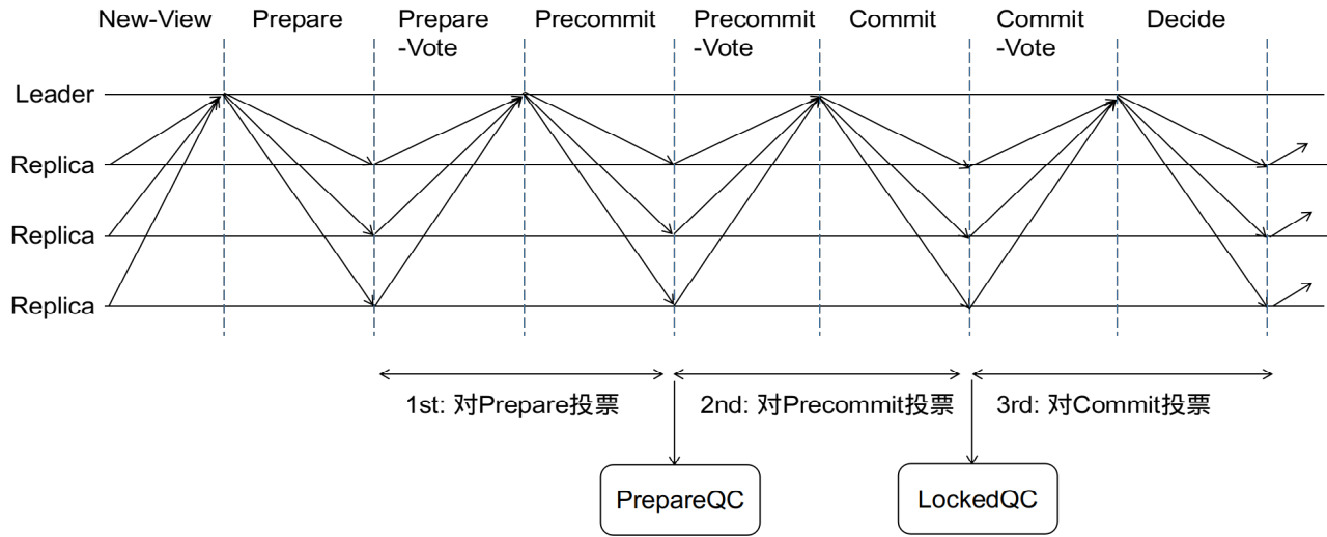
HotStuff は主に「リーダーが各ラウンドの投票情報を収集する責任がある」という考えを pbft に組み込みます。pbft には、全ノード ブロードキャストとコレクション投票の 2 ラウンド + クライアント コレクション投票の 1 ラウンドがあります。票を集めるためにリーダーに交代した場合、これら 3 つのイベントが確実に発生するまでに 3 ラウンドかかります。
第 1 段階では少なくとも 2/3 ノードからの投票が集まり、つまりリーダー ノードでイベント A が発生しますが、このときリーダー ノードはその時点での証拠を保持し、他のノードにブロードキャストします。他のノードはイベント A の発生に相当しますが、リーダーによってブロードキャストされたイベント A を他のノードが受信したかどうかは不明です (第 2段階)。そのため、イベント A を受信したノードはリーダー
にメッセージを送信します。これらの投票を収集します。つまり、リーダーはイベント B が発生しました。同様に、このイベント B は他のノードにブロードキャストされ、他のノードはそれを受信するとイベント B と同等になりますが、他のノードが受信したかどうかはまだわかりません。イベント B; 第三段階では、
ステップ 2 と同様に、イベント B を受信したノードもリーダーに投票を送信し、リーダーがそれを収集します。このとき、リーダーはイベント Cを持っています。他のノードがそれを受信すると、コンセンサスが達成されたことを確認します。
上記のコンセンサス アルゴリズムの設計思想を要約すると、 2 フェーズ コミット プロトコルと3 フェーズ コミット プロトコルに分けることができます。
フェーズ 2 コミットメント プロトコル
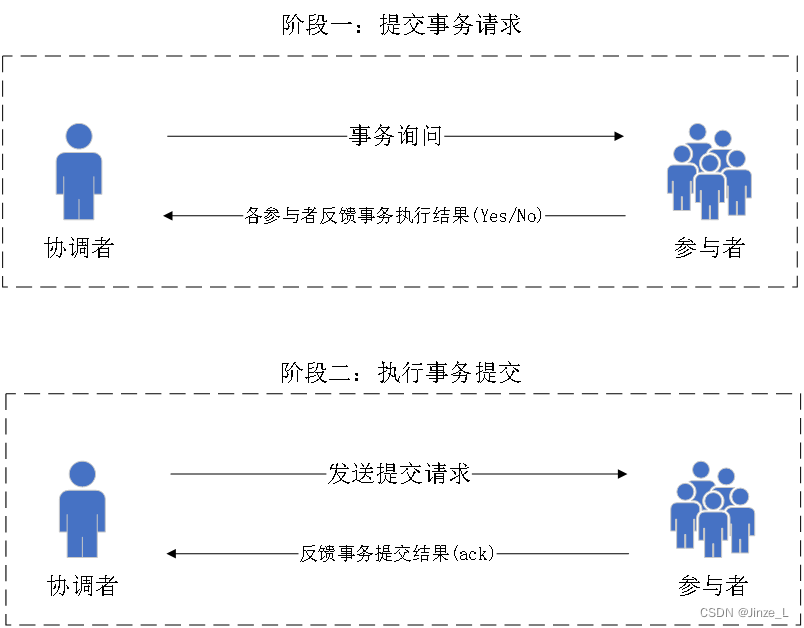
主に第 2 フェーズが採用されます。まず試してから送信します。
コーディネーターと参加者の 2 つの役割に分けることができます。
最初のフェーズは、トランザクション要求を送信することです。
コーディネーターはトランザクションの内容をパーティシパントに送信し、トランザクション送信操作を実行できるかどうかを尋ね、応答を待ちます。パーティシパントはトランザクション操作を実行してコーディネーターに応答し、実行が
成功した場合は Yes を返し、それ以外の場合は No を返します。
2 番目のフェーズでは、トランザクションのコミットを実行します。
参加者全員が「はい」と応答した場合、コーディネーターは参加者にコミット要求を送信します。そうでない場合は、ロールバック要求が送信されます。
パーティシパントは、コーディネータの要求に従ってトランザクションのコミットまたはロールバックを実行し、コーディネータにAckメッセージを送信します。
コーディネーターはすべての Ack メッセージを受信した後、分散システムのトランザクションの結果が完了したか失敗したかを判断します。
今紹介したpaxosもraftも2フェーズコミットの考え方に基づいて実装されています。
第 2 段階の利点:
- 原理は単純です。
- 分散トランザクションのアトミック性は、すべての実行が成功するか、すべての実行が失敗するかのいずれかが保証されます。
第 2 段階の欠点:
- 同期ブロック: 送信実行プロセス中、各参加者は他の参加者の応答を待機し、他の操作を実行できません。
- 単一点の問題: コーディネーターが 1 つしかなく、コーディネーターがハングアップし、2 フェーズのコミット プロセス全体が実行できません。さらに深刻なのは、フェーズ 2 でコーディネーターに問題がある場合、参加者は常にロックインされてしまうことです。トランザクション状態のため続行できません。トランザクション操作を完了してください。
- データの不整合: フェーズ 2 では、コーディネーターがコミット リクエストを送信した後、ネットワーク障害が発生すると、一部の参加者のみがコミット リクエストを受信してコミット操作を実行するため、データの不整合が発生します。
3 フェーズコミットプロトコル
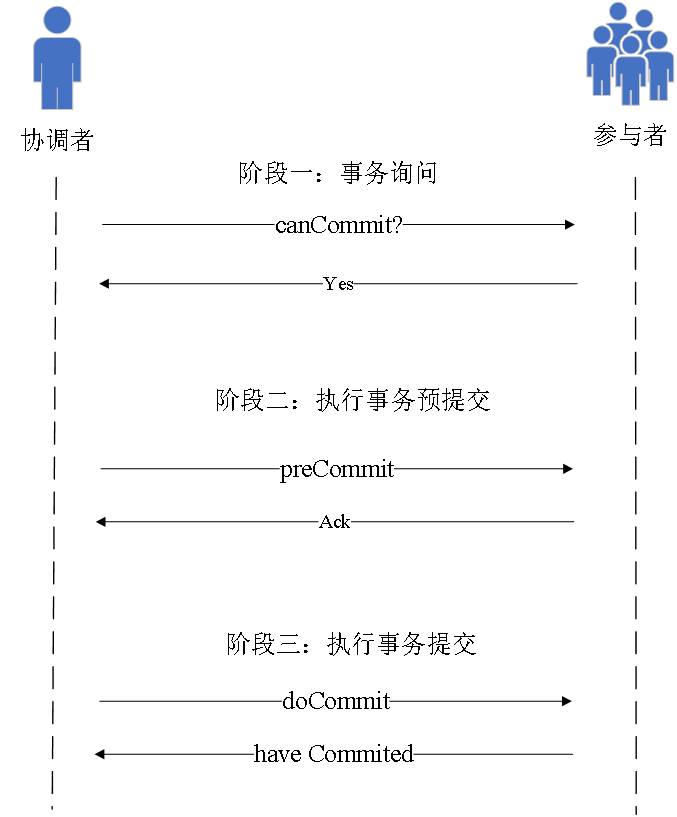
2 フェーズ コミットには多くの問題があるため、3 フェーズ コミットが存在します。
主な改善点は、最初のフェーズを 2 つのフェーズに分割。
同時に、コーディネーターと参加者にタイムアウト メカニズムが導入されます。
フェーズ 1取引
照会コーディネーターは取引内容を含む照会リクエストをパーティシパントに送信し、トランザクションを実行できるかどうかを尋ね、パーティシパントは
自身の状態に応じてYes/Noを判断し、応答します。
第 2 段階では、トランザクションのプリコミットを実行します
コーディネーターがほとんどのノードから「yes」を受け取った場合は、preCommit リクエストを送信し、それ以外の場合は、中止リクエストを発行します。
パーティシパントが preCommit を受け取った場合、トランザクションを実行して Ack を返します。アボートまたはタイムアウトを受信した場合、トランザクションは中断されます。
3 番目の段階は、トランザクションの送信を実行すること
。コーディネーターがほとんどのノードを Ack として受け取った場合、doCommit リクエストを送信します。パーティシパントはトランザクションを送信し、
doCommit を受信した後に応答を返します。
コーディネーターが応答を受信した後、判断します。トランザクションを完了するか、トランザクションを中断するか。
pbft や hotstuf などのアルゴリズムの基本的な考え方は、3 フェーズ コミット プロトコルです。
3 つの段階の利点:
- 第 2 フェーズでは同期ブロッキングの範囲が縮小され、第 2 フェーズでは参加者が preCommit リクエストを受信している限り、常にブロックすることなくトランザクションが実行されます。
- 単一点問題を解決します。第 3 段階では 2 つの状況が発生します: 1: コーディネーターに問題があります。2: コーディネーターと参加者の間にネットワーク障害があります。両方の原因により、参加者はメッセージの受信に失敗します。 doCommit リクエストを実行しますが、タイムアウト後に参加者は doCommit リクエストを受信しません。トランザクションはコミットされます。
3段階のデメリット
- データ パーティションの問題は依然として存在します。参加者は preCommit リクエストを受け取ります。この時点でネットワーク パーティションが発生すると、コーディネーターと参加者の間で通常のネットワーク通信は実行できません。参加者はタイムアウト後もトランザクションをコミットします。データの不整合が発生します。もちろん、これは分散システムに共通する問題であり、一貫性と可用性を維持するには、パーティションの耐障害性を犠牲にしなければなりませんが、これが分散システムの不可能な三角形、つまりキャップ理論です。したがって、2 フェーズ コミットであっても 3 フェーズ コミットであっても、データの分割は避けられません。
