この記事の内容
これは、分散データベースなどのステートフル サービスがシステムの高可用性をどのように確保するかについての予備的な研究です。間違いがある可能性があります。ご指導を歓迎します。
文章
分散データベースの高可用性について話すときは、主にダウンタイムやネットワーク分断時にシステムの高可用性を確保する方法について話しますが、これはオンライン アプリケーションの安定性管理で言及されている高可用性とは少し異なります。には、容量、依存性、オンライン変更の 3 つの次元でのシステム安定性ガバナンスが必要です。分散データベースの高可用性とは、オンライン アプリケーション安定性ガバナンスにおける依存関係の細分化を指します。つまり、ダウンタイムおよびネットワーク分割シナリオ下で高システム可用性を実現する方法、つまり、分散データベースで言及される高可用性は、オンライン アプリケーションの安定性管理の 1 つの側面です。
分散データベースの高可用性実装の一般的な考え方
ダウンタイムやネットワーク分割障害に対処するための分散データベースのアイデアは、データ コピー メカニズムです。データ コピー
メカニズムの一般的なアイデアは、マスター/スレーブ アーキテクチャです。
データの一貫性を確保するためのメカニズムです。マスター/スレーブ アーキテクチャはレプリケーション ステート マシンです。
以下は、マスター/スレーブ アーキテクチャの概略図です。
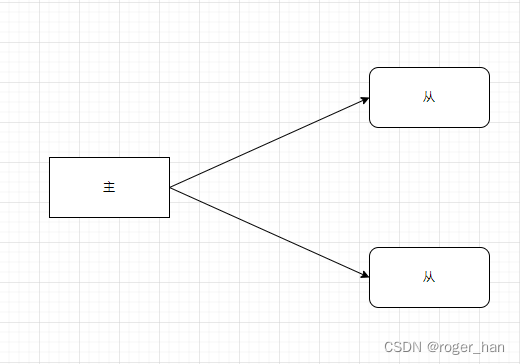
以下はraftアルゴリズムによるレプリケーションステートマシンの説明です。
复制状态机通常使用复制日志实现,每个服务器存储一个包含一系列命令的日志,其状态机按顺序执行日志中的命令。
每个日志中命令都相同并且顺序也一样,因此每个状态机处理相同的命令序列。 这样就能得到相同的状态和相同的输出序列。
レプリケーション ステート マシンは、通常の状況 (つまり、ダウンタイムがなく、ネットワークが分断されている状況) ではマスターとスレーブのデータの整合性を保証できますが、マスターのダウンタイムが発生した場合、クラスター データの整合性をどのように確保するかが新たな問題になります。これについては、レプリカ データの整合性に関する章で後述します。
ダウンタイム時の高可用性
ダウンタイムには 2 種類あり、1 つはマスター ノードのダウンタイム、もう 1 つはスレーブ ノードのダウンタイムです。
マスターノードがダウンしている
マスター/スレーブ アーキテクチャの場合、マスター ノードは単一ポイントになります。マスター ノードがハングアップすると、システム全体が実行できなくなります。このとき、マスター ノードをマスターからスレーブに切り替える必要があります。 。
マスタースレーブスイッチングにはディスカバリとスイッチングの2つの機能があり、初期段階ではこの2つの機能を実現するためにセンチネルを導入しました。
単一のセンチネルメカニズム
Sentinel サービスはデータベース クラスター全体を監視します。マスター ノードがハングアップすると、スレーブ ノードが選択されてマスター ノードに昇格し、サービスを提供し続けます。典型的な例として mysql の MHA があり、その全体構造を示します下の図のとおりです。
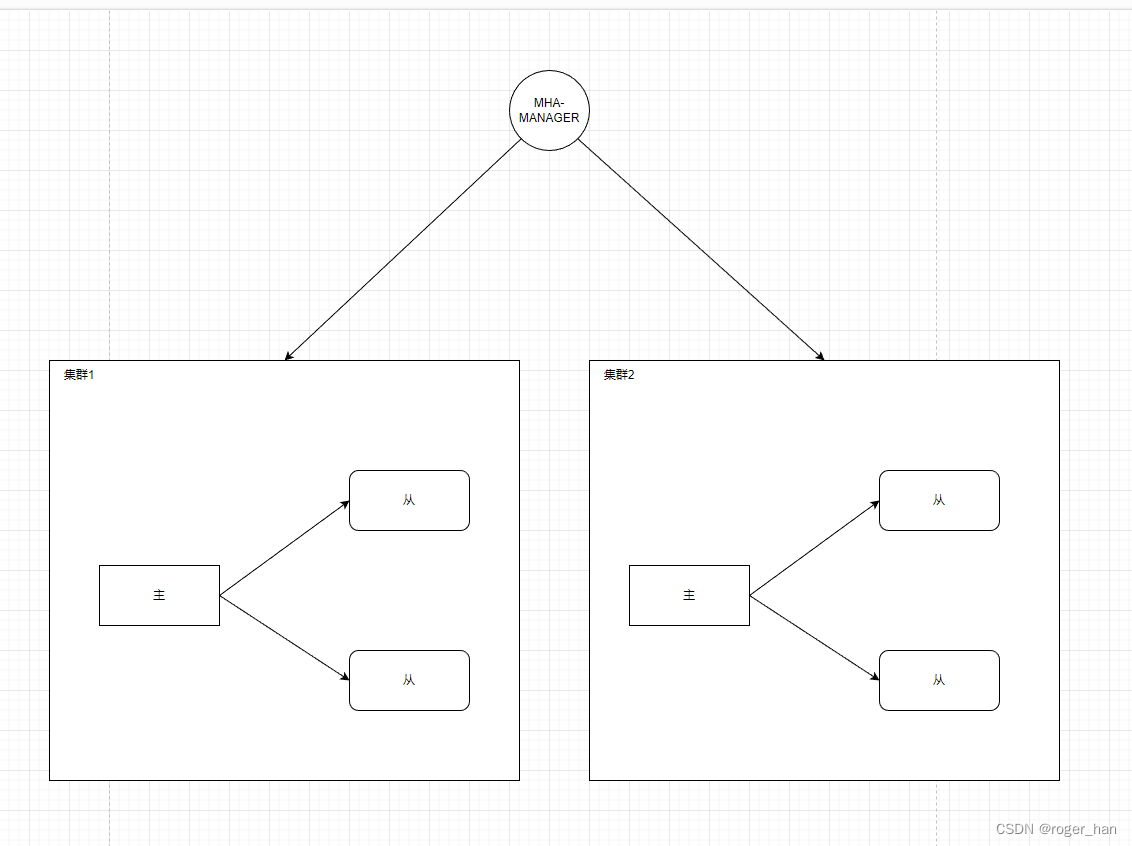
センチネルクラスター
しかし、これは別の問題を引き起こします。Sentinel がダウンしたときに何をすべきかということです。
解決策は、Sentinel にもマルチコピー メカニズムがあることです。意思決定は 1 つの Sentinel ノードによってのみ行われるため、このノードは Sentinel クラスターのマスター ノードと呼ばれ、他のノードは Sentinel クラスターのバックアップ ノードとなります。 Sentinel クラスターなので、Sentinel クラスター上でもマスター/スレーブの切り替えが可能です。Sentinel クラスターの高可用性を確保するには、このような一連のロジックが必要です。一周しても同じ場所に戻ります。
全体的なアーキテクチャ図は次のようになります。
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-ykvuFSBM-1680792798373) (/Users/hancongcong/Desktop/Work/Work Daily/Blog) /分散データベースの安定性 /スクリーンショット 2023-04-06 pm 10.52.45.png)]](https://img-blog.csdnimg.cn/a4c3ea879f4844ddbee255010fb30912.png)
Sentinel の高可用性
センチネル クラスターを個別に取り出して高可用性を実現すると、コンセンサス アルゴリズムを使用して、raft、gossip などのセンチネル クラスターのマスターを選択できます。このとき、センチネル クラスターは高可用性クラスターになります。 、下の図に示すように。
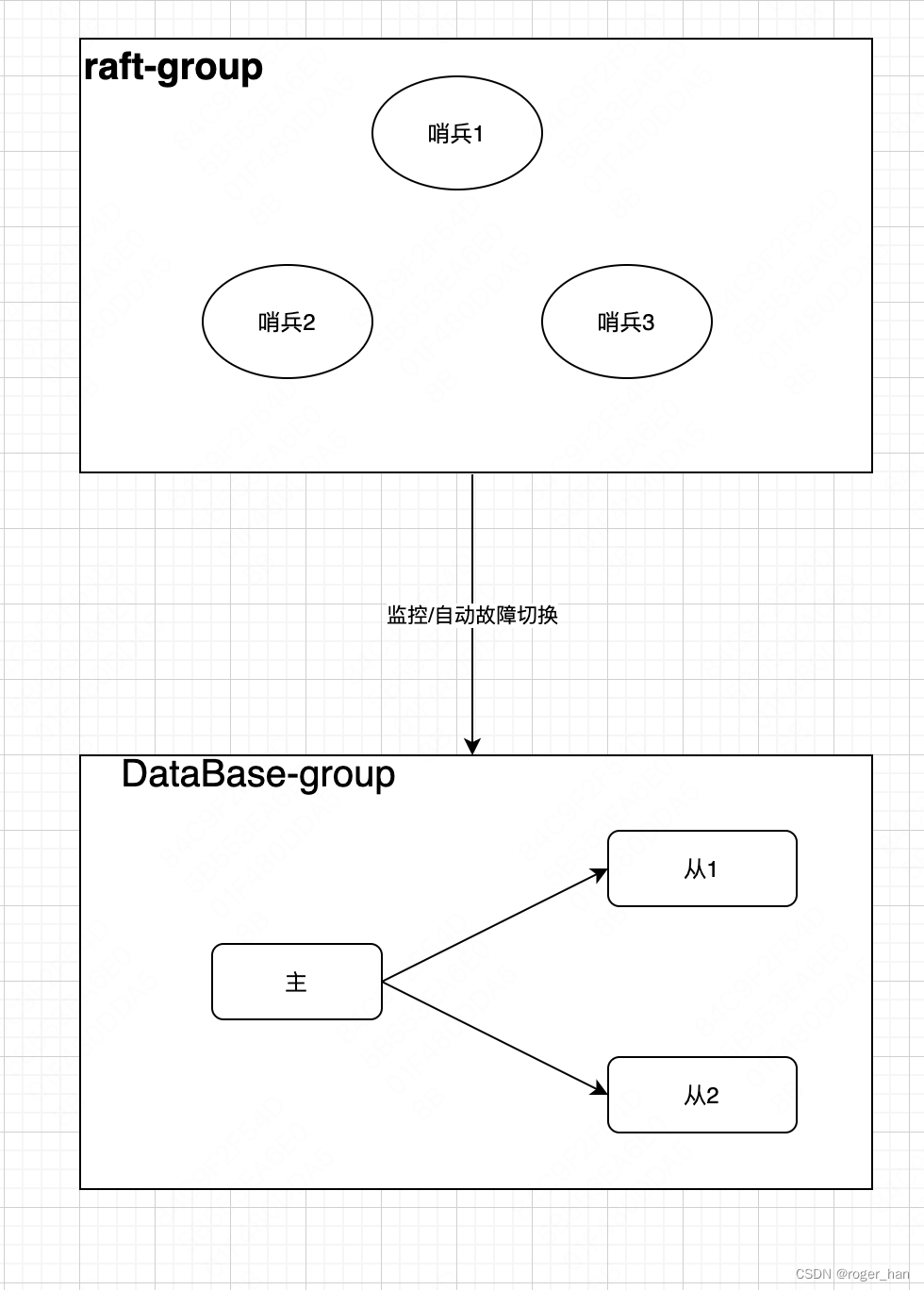
このとき、非常に興味深い状況が発生します。センチネルは分散コンセンサス アルゴリズムを通じて高可用性を実現しているため、センチネル ノードを展開せずに、データベースのマスター/スレーブ インスタンスと分散コンセンサス アルゴリズムを直接組み合わせて、分散コンセンサス アルゴリズムを直接実現する方がよいでしょう。データベース コピー:高可用性、そして現在では、マスター/スレーブの切り替えとデータ同期に Raft コンセンサス アルゴリズムを使用する TIDB の TIKV や、ゴシップ コンセンサスに基づく最新の redis-cluster watchdos メカニズムなど、これを実現するデータベースが多数あります。マスター/スレーブのダウンタイムを実現するためのプロトコルから切り替えます。
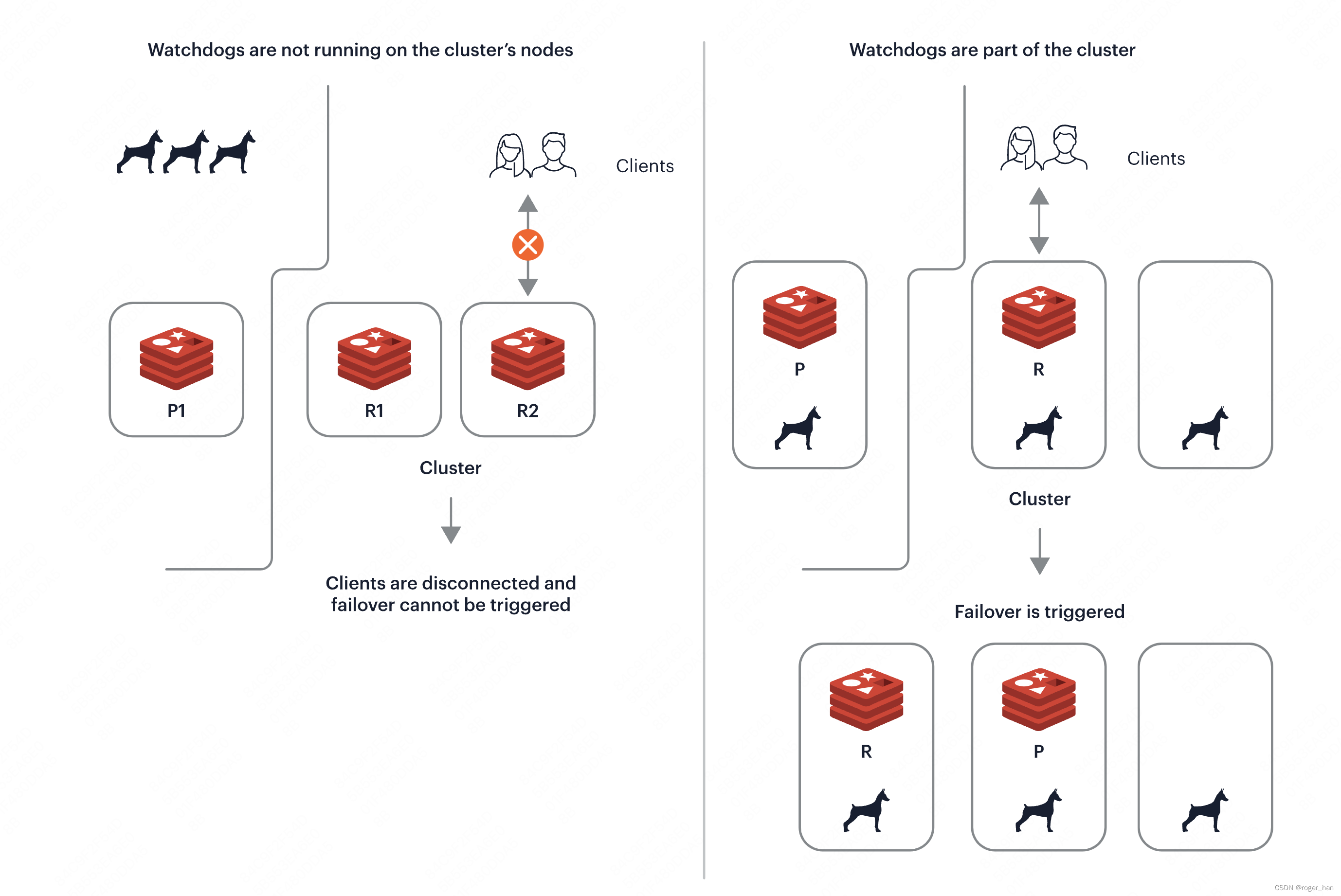
redis-cluster ウォッチドッグメカニズム
スレーブノードがダウンしている
スレーブ ノードのダウンタイムの検出は依然として Sentinel の責任であり、スレーブ ノードがダウンした後にアラームが送信されます。
スレーブ ノードはバックアップ ノードであるため、ダウンタイム後のクラスター全体への影響は大きくなく、ほとんどのスレーブ データベースがダウンした後、Sentinel がマシンをスレーブにするために再申請する必要はありません。その後の処理は、スレーブ データベースが指定された時間内にスレーブ ライブラリが再起動された場合 (メイン ライブラリのログが存在する場合)、スレーブ ライブラリはメイン ライブラリからのログの同期を継続します。指定された時間内に再起動しない場合は、新しいスレーブ ライブラリを再作成する必要があります。
ネットワークパーティション
ネットワークの分割は 2 つの問題を引き起こします。
1 つ目は、センチネルとデータベース内のすべてのマシンが分割された後の誤った判断の問題です。
2 つ目は、センチネルとマスター ノード間のネットワーク分割後の判断ミスで、クラスターのマスターとスレーブの切り替えが発生し、スプリット ブレイン問題が発生します。
Sentinel の高可用性の章では、Sentinel クラスターとデータベース クラスターが別々にデプロイされており、Sentinel クラスターとデータベース クラスター間のネットワークが分割されている場合、Sentinel クラスターはデータベース クラスターのステータスを検出できず、すべてのマシンが検出されます。現時点では、その判断は間違っており、メインのデータベースはまだ正常に動作している可能性があります。
このソリューションは、 Sentinel High Availabilityのこの章で説明されている方法とまったく同じですが、その 2 つが組み合わされている限り、スプリット ブレイン問題が発生しないようにしたい場合は、コンセンサス プロトコルを選択する必要があり、業界では一般にraft、zab、paxos などの分散コンセンサス アルゴリズムを選択します。2n+1 台のマシンのクラスタでは、コンセンサス アルゴリズムにより m (m <= n) 台のマシンがダウンしていることが保証され、スプリット ブレイン問題は発生しません。
レプリカデータの一貫性
通常のクラスター動作条件では、レプリケーション ステート マシンはマスター/スレーブ コピーのデータ整合性を満たすことができますが、マスター ライブラリに問題が発生してダウンし、クラスター内でマスター/スレーブの切り替えが発生すると、スレーブ ライブラリが昇格されます。 . 非同期レプリケーションではデータが失われます。
データを失いたくない場合、解決策の 1 つは、データ同期にゴングを使用することです。さまざまな分散コンセンサス アルゴリズムでは、書き込みが成功したとみなされる前に、2n+1 クラスターに n+1 台のマシンが書き込まれる必要があります。これは、データベースの回避 マスターダウンタイムの場合、マスター/スレーブ切り替え時にデータ損失が発生しますが、これはもちろんスプリットブレインを防ぐためでもあります。
ユニバーサルコンセンサスアルゴリズムと分散データベースの高可用性
コンセンサスアルゴリズムの長所と短所
上記の章から、分散コンセンサス アルゴリズムの頻度が非常に高く、分散データベースにおけるマスター/スレーブ切り替えの問題、マスター ノードとスレーブ ノード間のデータの一貫性の問題、および分散コンセンサス アルゴリズムによって引き起こされる問題が解決されることがわかります。スプリット ブレイン問題により、データ損失のない高可用性クラスターの最終形態 (著者の頭の中の在庫から推定された最終形態)、つまり、分散型コンセンサス アルゴリズムに基づく分散型データベースがわかります。業界の例には、TIDB、キセノンなどが含まれます。
ただし、raft、zab、paxos などの分散コンセンサス アルゴリズムのデータのため、書き込みが成功したとみなされる前にデータが n + 1 台のマシンに書き込まれる必要があるため、このようなアルゴリズムを高パフォーマンスで使用することは不可能です。 Redis クラスターなどのモデルの選択ではトレードオフが行われますが、スプリット ブレインとマスターがダウンしたときにデータが失われないことは保証できませんが、データベース自体の高いパフォーマンスは維持されます。クラスターのメタデータ管理とマスター データベース障害の自動災害復旧のためにのみゴシップ アルゴリズムが選択されます。
注: 実際、コンセンサス問題は分散システムの最も基本的な問題であり、この問題を解決すると、分散システムは 1 つのノードとして機能し、単一ノードのように動作できるようになります。
コンセンサス アルゴリズムの自動災害復旧は、メイン ライブラリ (raft、zab) がダウンしたときにデータが失われないことをどのように保証しますか?
ほとんどのコンセンサスアルゴリズムは、次の 2 点によって保証されています。
- 2n+1 クラスターでは、n+1 ノードへの書き込みは成功したとみなされます。
- 2n+1 クラスタでは、m ( m <= n ) 台のマシンがダウンした場合、残りの n+1 台のマシンのうち最新のログを持つマシンがマスター (raft) として選択されます (「残りの n + 1 台のマシンのうち」) 、最新のコミット ログを持つマシンが存在する必要があります。ログが最も大きいノード (最新のコミット ログが含まれている必要があります) を見つけるか、最新のログを持つマシンを選択して、そのログを同期します (zab)。
コンセンサス アルゴリズムは、ネットワーク分割 (raft、zab) の場合にスプリット ブレインをどのように回避しますか
マスターがダウンしている場合、2n + 1 クラスター内にマジョリティ クラスターが存在する必要があります。このクラスターには n + 1 クラスターのマシンが含まれています。このマジョリティ クラスターでは、すべてのマシンが新しいマスターになることに同意します。マスターは正常に選択できます。 2n + 1 クラスターが n クラスターと n + 1 クラスターに分割され、マスターが n クラスター内にある場合、書き込みアクションには n + 1 台のマシンが必要であるため、n クラスター内のマスターは現時点では書き込みアクションを完了できません。確認してください。現時点では、n 個のクラスターには n 台のマシンしかありません。また、n 個のクラスターでマスターを選択することは不可能であり、n+1 クラスターのみがマスターを選択できます。