この記事では、簡単なデータ拡張、利点、および一般的な拡張方法を紹介し、データ拡張に関するいくつかの取り組みも紹介します。
CutMix(ICCV2019)、ContrastMask(CVPR2022)、BCP(CVPR2023)。
データ拡張の概要と利点
データ拡張とは何ですか?
データ拡張は、既存のデータから新しいトレーニング データを生成することによって元のデータセットを拡張する深層学習の手法です。データ拡張ツールは、既存のデータのパラメーターを操作することによって、データを新しい固有のサンプルに変換します。データ拡張は、画像、テキスト、オーディオ、ビデオ入力に対して実行できます。データ拡張には 2 つのタイプがあります。オフライン (拡張画像はドライブに保存され、モデルをトレーニングする前に実際のデータと結合されます) とオンライン (データ拡張はランダムに選択された画像に適用され、元のデータのトレーニングに使用されます)。
データ拡張の利点は何ですか?
データ拡張を適切に使用すると、次のような利点が得られます。
- データの取得とデータのラベル付けのコストを削減します。
- モデルに多様性と柔軟性を与えることで、モデルの一般化が向上します。
- モデルのトレーニングに使用するデータが増えるため、モデルの予測精度が向上します。
- データの過剰適合を軽減します。
- 少数派クラスのサンプル数を増やすことで、データセットの不均衡に対処します。
一般的なデータ拡張方法:

データ拡張方法の詳細については、次のブログを参照してください。
深層学習におけるさまざまなデータの機能強化_m0_61899108 のブログ - CSDN ブログ
自動データ強化方法(コード付き)_データ強化コード_m0_61899108のブログ - CSDNブログ
データ強化には多くの手法があり、アルゴリズムは難しくありませんが、難しいのはその理解方法、その理由と目的(動機)、その手法がシンプルで効果的であるか、タスクとの関連付け、および良い物語を語る方法。
CutMix: ローカライズ可能な特徴を備えた強力な分類子をトレーニングするための正則化戦略、ICCV 2019
論文: https://arxiv.org/abs/1905.04899
コード: https://github.com/clovaai/CutMix-PyTorch
いくつかの一般的なデータ拡張機能の比較:
- Mixup : 2 つのランダムなサンプルを比例的に混合し、分類結果を比例的に分配します。
- カットアウト: サンプル内の一部の領域をランダムに切り取り、0 ピクセル値を埋めます。分類結果は変わりません。
- CutMix : 領域の一部を切り出しますが、0ピクセルを埋めるのではなく、トレーニングセット内の他のデータの領域ピクセル値をランダムに埋め、分類結果を一定の割合で分配するものです。


上記 3 つのデータ拡張の違いは次のとおりです。
- Cutout と Cutmix は、塗りつぶされた領域のピクセル値の差です。
- mixup と Cutmix は、2 つのサンプルを混合する方法の違いです。
- mixup はミックスサンプルに比例して 2 つの画像を補間すること、cutmix は画像混合後に不自然な状況が生じないように、カット部分とパッチの形で画像を混合することです。
カットミックスの利点:
- トレーニング プロセス中に非有益なピクセルが表示されないため、トレーニング効率が向上します。
- 地域ドロップアウトの利点を維持し、ターゲットの非差別的な部分に焦点を当てることができます。
- 部分的なビューからオブジェクトを認識することをモデルに要求し、カット領域に他のサンプルの情報を追加することにより、モデルの位置決め能力をさらに強化できます。
- 画像混合後に不自然な状況がなくなるため、モデル分類のパフォーマンスが向上します。
- トレーニングと推論のコストは変わりません。
アルゴリズム:


疑似コード:

実験:


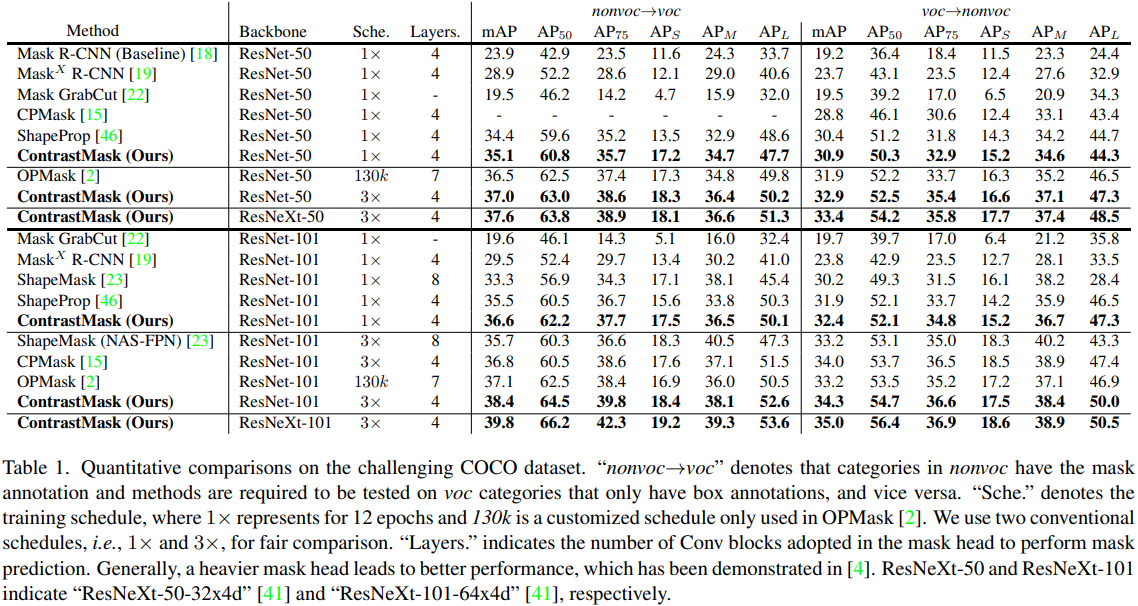
ContrastMask: あらゆるものをセグメント化するための対照学習、CVPR2022
論文: https://arxiv.org/abs/2203.09775
コード: https://github.com/huiserwang/ContrastMask
部分教師ありインスタンスのセグメンテーションは、アノテーション マスクを使用して限られた基本カテゴリのセットで学習することにより、新しいカテゴリからオブジェクトをセグメント化する必要があるタスクです。これにより、アノテーションの重い負担が軽減されます。このタスクを解決する鍵は、効率的なクラスに依存しないマスク セグメンテーション モデルを構築することです。このようなモデルを基本カテゴリでのみ学習する以前の方法とは異なり、この論文では、統合されたピクセルレベルの対照学習フレームワークContrastMaskと呼ばれる新しい方法を提案しますモデルを分割します。このフレームワークでは、基本クラスのアノテーション マスクと新規クラスの擬似マスクが対比学習の事前分布として使用され、マスクされた領域 (前景) の特徴がまとめられ、背景の特徴と対比されます (逆も同様)。(インスタンスの前景と背景のピクセル間でクエリとキーをサンプリングし、前景と背景の間の距離を短縮し、前景と前景または背景と背景の間の距離を短縮します) このフレームワークを通じて、前景と背景の特徴の区別が大幅に改善され、クラスに依存しないマスク セグメンテーション モデルの学習が容易になります。COCO データセットで良好な結果を達成しました。

この論文では、統一されたピクセル単位の対比学習フレームワークの下で、ベース カテゴリと新規カテゴリの両方でクラスに依存しないマスク セグメンテーション モデルを学習する、新しい部分教師ありインスタンス セグメンテーション アプローチである ContrastMask を提案します。このフレームワークでは、新しいクエリ共有ピクセル レベルのコントラスト損失が、すべてのカテゴリのデータを完全に活用するように設計されています。この目的を達成するために、基本カテゴリのアノテーション マスク、またはクラス アクティベーション マッピング (CAM) によって計算された新しいカテゴリの擬似マスクが、前景と背景の分離だけでなく、共有クエリ、正の秘密と負の秘密も示す領域事前分布として使用されます。 。代わりに、ベース カテゴリと新規カテゴリの両方を含むトレーニング画像のバッチを指定すると、前景クエリと背景クエリという 2 つの共有クエリが確立されます。これらは、アノテーション マスクとダミー マスクを含む、マスクされた領域の内側と外側の特徴を平均することによって取得されます。次に、特別なサンプリング戦略が実装されて、適切なキーが選択されます。提案された損失を導入することにより、マスクされた領域の内側/外側のキーをフォアグラウンド/バックグラウンドの共有クエリに向けてプルし、それをマスクされた領域の外側/内側のキーと対比することが期待されます。最後に、ピクセルレベルの対比学習フレームワークによって学習された特徴は、クラスに依存しないマスク ヘッドに融合されて、マスク セグメンテーションが実行されます。
以前の方法と比較して、ContrastMask にはいくつかの利点があります。
- トレーニング データを最大限に活用するため、新しいカテゴリのトレーニング データもセグメンテーション モデルの最適化プロセスに貢献します。
- さらに重要なことは、統一されたピクセルレベルの対照学習フレームワーク、特に基本カテゴリと新しいカテゴリの共有クエリを通じて、基本カテゴリのセグメンテーション能力を新しいカテゴリに移行するための橋渡しを構築し、基本カテゴリのセグメンテーション能力を継続的に改善することです。カテゴリと小説カテゴリ カテゴリの前景と背景の特徴的な区別。
フレームワーク: ContrastMask は、 CL ヘッドと呼ばれる追加の「対照学習」ヘッドを備えた古典的な 2 段階マスク R-CNN アーキテクチャに基づいて構築されており、ベース カテゴリと新しいカテゴリの両方で統一されたピクセル レベルの対照学習を実行します。CL Head は、RoI 特徴マップと Box Head によって生成された CAM を入力として受け取ります。これは、ピクセル単位のコントラスト損失によって監視され、マスク ヘッドの拡張された特徴マップを出力します。最後に、マスク ヘッドは、融合された特徴マップを入力に依存しないセグメンテーション マップとして取得することでクラスを予測します。

対照学習ヘッド (CL ヘッド): CL ヘッドの目標は、前景と背景の間の特徴の区別を増やし、ベース カテゴリと新しいカテゴリの各領域 (背景または前景) 内の特徴の違いを減らし、マスクに貢献することです。頭の勉強。これは、新しいピクセルレベルのコントラスト損失を学習することで実現されます。
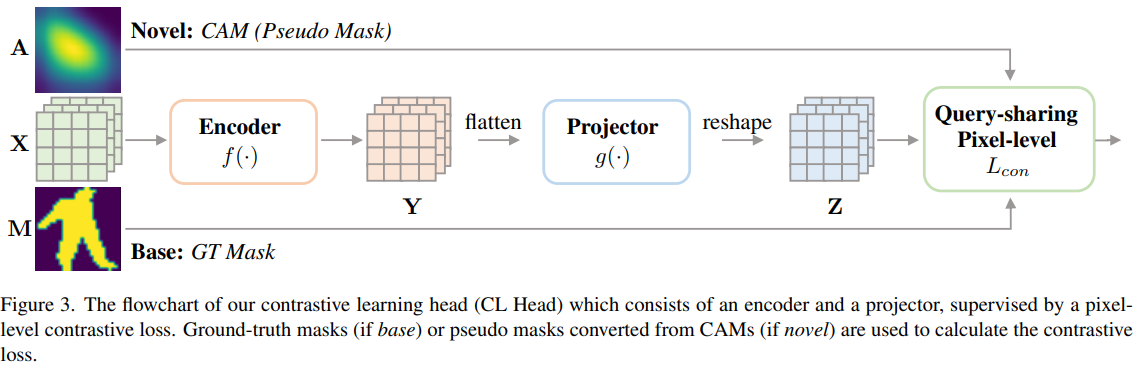
クエリ共有ピクセル レベルのコントラスト ロス: 統合されたコントラスト学習フレームワークの下で、基本カテゴリと新しいカテゴリのマスク セグメンテーション モデルを学習できる新しいピクセル レベルのロス。この損失関数の核となる設計思想は、基本カテゴリと新しいカテゴリが 2 つのカテゴリに依存しないクエリ (1 つはフロント q+ 用、もう 1 つは背景 q- 用) を共有し、基本カテゴリを細分化するためのブリッジを形成するというものです。新しいカテゴリに転送されます。


クラスに依存しないマスク ヘッド: マスク ヘッドのアーキテクチャと対応する損失関数は、次の 3 つの変更を除いてマスク R-CNN のものと同じです。 1) 最後の畳み込み層の出力チャネルを 80 から 1 に変更します。クラスに依存しないマスクヘッダー。2)CLヘッドの出力特徴マップをマスクヘッドの入力特徴マップと連結することにより、マスクヘッドの入力特徴がよりユニークになり、その学習が容易になる。3) CAM を使用して、どの領域に焦点を当てるかをマスク ヘッドに指示します。これは、入力特徴マップに CAM を追加することで簡単に実現できます。

実験:

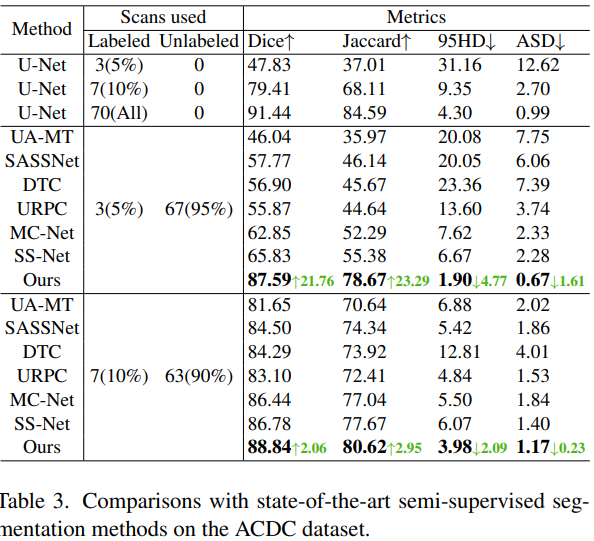
半教師あり医用画像セグメンテーションのための双方向コピー&ペースト、CVPR2023
論文: https://arxiv.org/abs/2305.00673
コード: https://github.com/DeepMed-Lab-ECNU/BCP
半教師あり医療画像セグメンテーションでは、ラベル付きデータ分布とラベルなしデータ分布の間に経験的な不一致の問題があります。ラベル付きデータとラベルなしデータが別々に扱われるか、一貫性のない方法で扱われる場合、ラベル付きデータから学習した知識はほとんど破棄される可能性があります。
この論文では、この問題を軽減する簡単なアプローチ、つまり、単純な Mean Teacher アーキテクチャでのラベル付きデータとラベルなしデータの双方向コピー&ペーストを提案します。この方法は、ラベルなしデータがラベル付きデータから内向きおよび外向きの包括的な一般意味論を学習することを促進します。さらに重要なことは、ラベル付きデータとラベルなしデータの一貫した学習プロセスにより、経験的な分布ギャップを大幅に狭めることができるということです。
詳細には、ランダムな作物がラベル付き画像 (前景) からラベルなし画像 (背景) およびラベルなし画像にそれぞれコピー&ペーストされます。これら 2 つのブレンドされた画像は学生ネットワークに入力され、擬似ラベルと実際のラベルのブレンドされた監視信号によって監視されます。この論文では、ラベル付きデータとラベルなしデータ間の双方向コピー&ペーストの単純なメカニズムが十分に機能することを発見し、さまざまな半教師付き医用画像セグメンテーション データセットに対する他の最先端技術と比較して実験的に大きな成果が得られたことを示しています。
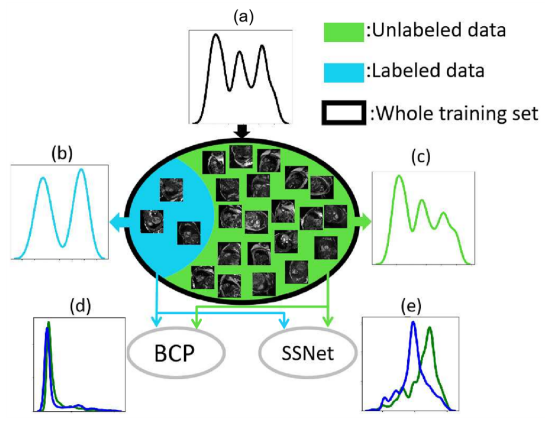

半教師あり医用画像セグメンテーションでは、ラベル付きデータとラベルなしデータは同じ分布から得られます (図 1(a))。しかし現実の世界では、ラベル付きデータの数が少ないため、ラベル付きデータから正確な分布を推定することは困難です。したがって、大量のラベルなしデータと非常に少量のラベル付きデータの間には、経験的な分布の不一致が常に存在します (図 1(b) および (c))。半教師ありセグメンテーション手法は常に、一貫した方法でラベル付きデータとラベルなしデータを対称的にトレーニングしようとします。しかし、既存の半教師あり手法のほとんどは、異なる学習パラダイムの下でラベル付きデータとラベルなしデータを使用します。そのため、ラベル付きデータとラベルなしデータの間の経験的分布の不一致だけでなく、ラベル付きデータから学習した大量の知識が破棄されることがよくあります (図 1(e))。
ラベル付きデータとラベルなしデータの間の経験的な不一致の問題を軽減するために、成功する設計は、ラベルなしデータがラベル付きデータから包括的な共通点を学習することを奨励しながら、ラベル付きデータとラベルなしデータの一貫した学習戦略を通じて分布をさらに実現することです。このペーパーでは、Mean Teacher フレームワークでインスタンス化された、シンプルでありながら非常に効果的な双方向コピー&ペースト (BCP) 方法を提案することでこれを実現します。具体的には、学生ネットワークをトレーニングするために、ラベル付き画像 (前景) からラベルなし画像 (背景) にランダムなクロップをコピーアンドペーストすることによって、またその逆に、ラベルなし画像 (前景) からラベル付き画像にランダムなクロップをコピーアンドペーストすることによって入力が強化されます (バックグラウンド)。生徒ネットワークは、教師ネットワークからのラベルなし画像の疑似ラベルとラベル画像のラベル マップ間の双方向コピーアンドペーストを介して、生成された監視信号によって監視されます。これら 2 つのブレンドされたイメージは、ネットワークがラベル付きデータとラベルなしデータの間の共通のセマンティクスを双方向かつ対称的に学習するのに役立ちます。
フレーム:


過程説明:


アルゴリズム:





実験: