SpringCloud マイクロサービス テクノロジー スタック ダーク ホースのフォローアップ 6
今日の目標
昨日の検討では大量のデータをelasticsearchに取り込み、elasticsearchのデータ保存機能を実現しました。しかし、elasticsearch が最も得意とするのは、検索とデータ分析です。
というわけで、今日はelasticsearchのデータ検索機能について勉強しましょう。DSLとRestClient をそれぞれ使用して検索を実装します。
1. DSL クエリ ドキュメント
Elasticsearch クエリは、JSON スタイルの DSL に基づいて引き続き実装されます。
1.1. DSL クエリの分類
Elasticsearch は、クエリを定義するための JSON ベースの DSL (ドメイン固有言語) を提供します。一般的なクエリの種類は次のとおりです。
- Query all : 一般的なテストのために、すべてのデータを照会します。例:
- 全文検索 (全文) クエリ: 単語セグメンターを使用してユーザー入力コンテンツをセグメント化し、転置インデックス データベースで照合します。例えば:
- match_query
- multi_match_query
- 正確なクエリ: 正確な入力値に基づいてデータを検索します。通常、キーワード、数値、日付、ブール値、およびその他の種類のフィールドを検索します。例えば:
- ID
- 範囲
- 学期
- 地理 (geo) クエリ: 緯度と経度に基づくクエリ。例えば:
- geo_distance
- geo_bounding_box
- 複合 (compound) クエリ: 複合クエリは、上記のさまざまなクエリ条件を組み合わせて、クエリ条件を結合することができます。例えば:
- ブール
- function_score
クエリ構文は基本的に同じです。
GET /indexName/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}
例としてすべてのクエリを見てみましょう。
- クエリ タイプは match_all です
- クエリ条件なし
// 查询所有
GET /indexName/_search
{
"query": {
"match_all": {
}
}
}
その他のクエリは、クエリの種類とクエリ条件の変更にすぎません。
例えば:
# 查询所有
GET /hotel/_search
{
"query": {
"match_all": {
}
}
}
クエリ結果:

注: ここではすべてをクエリしますが、基本的にはデフォルトで 10 項目が表示され、すべてがクエリされるわけではありません。
要約:
クエリ DSL の基本的な構文は?
● GET /index ライブラリ名/_ 検索
● { "query": { "query type": { "FIELD": "TEXT"}}}
1.2. 全文検索クエリ
1.2.1. 使用シナリオ
全文検索クエリの基本的なプロセスは次のとおりです。
- ユーザーの検索内容をセグメント化し、エントリを取得する
- 転置索引ライブラリで照合するエントリに従って、ドキュメント ID を取得します。
- ドキュメント ID に従ってドキュメントを検索し、ユーザーに返します
より一般的なシナリオは次のとおりです。
- モールの入力ボックス検索
- バイドゥ入力ボックス検索
例: JD.com:

用語との一致であるため、検索に参加するフィールドもセグメント化できるテキスト タイプのフィールドである必要があります。
1.2.2. 基本構文
一般的な全文検索クエリには、次のものがあります。
- 一致クエリ: 単一フィールド クエリ
- multi_match クエリ: 複数フィールド クエリ、任意のフィールドが条件を満たしている場合でも、クエリ条件に一致する
クエリの構文は次のとおりです: 一般的なクエリは TEXT 型のフィールドです
GET /indexName/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
}
}
multi_match 構文は次のとおりです。
GET /indexName/_search
{
"query": {
"multi_match": {
"query": "TEXT",
"fields": ["FIELD1", " FIELD12"]
}
}
}
1.2.3. 例
一致クエリの例:
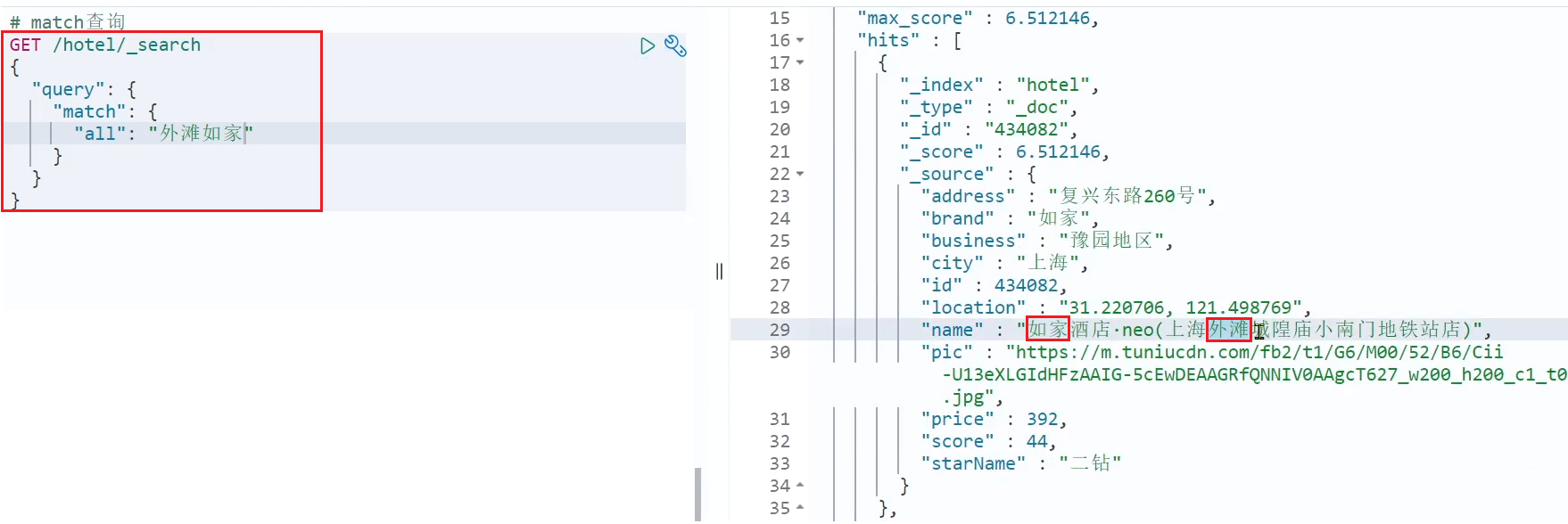
# match查询
GET /hotel/_search
{
"query": {
"match": {
"all": "外滩如家"
}
}
}
multi_match クエリの例:
# multi_match查询查询
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "外滩如家",
"fields": ["brand","name","business"]
}
}
}
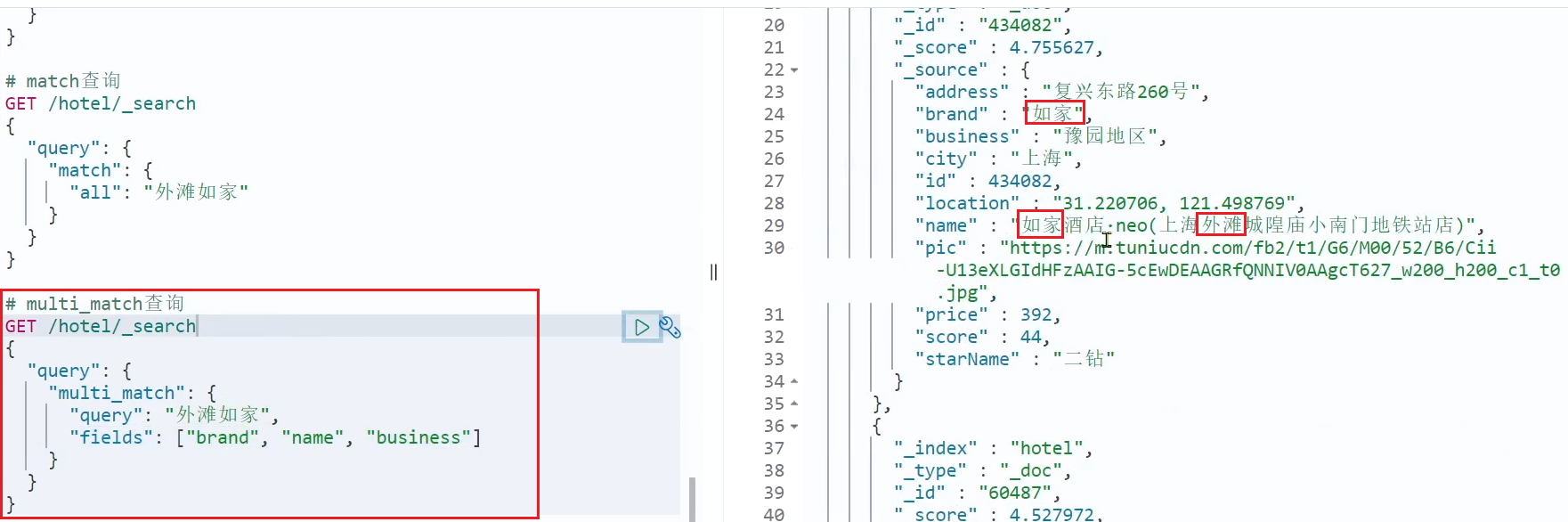
2 つのクエリの結果が同じであることがわかりますが、なぜでしょうか?
copy_to を使用して、ブランド、名前、ビジネスの値をすべてのフィールドにコピーしたためです。したがって、3 つのフィールドに基づいて検索します。もちろん、すべてのフィールドに基づいて検索するのと同じ効果があります。
ただし、検索フィールドが多いほど、クエリのパフォーマンスへの影響が大きくなるため、copy_to を使用してから単一フィールド クエリを使用することをお勧めします。
1.2.4. まとめ
match と multi_match の違いは何ですか?
- match: フィールドに基づくクエリ
- multi_match: 複数のフィールドに基づくクエリ。クエリに含まれるフィールドが多いほど、クエリのパフォーマンスが低下します。
1.3. 正確なクエリ
正確なクエリは、通常、キーワード、値、日付、ブール値、およびその他の種類のフィールドを検索することです。そのため、検索条件の単語区切りは行いません。さらに、検索結果とクエリ結果は完全に一致する必要があります。
- term: 用語の正確な値に基づくクエリ
- range: 値の範囲に基づくクエリ
1.3.1. タームクエリ
完全一致クエリのフィールド検索は単語区切りのないフィールドであるため、クエリ条件も単語区切りのないエントリである必要があります。クエリを実行すると、ユーザーが入力した内容が自動値と正確に一致する場合にのみ、条件を満たしていると見なされます。ユーザーが入力する内容が多すぎると、データを検索できません。
文法の説明:
// term查询
GET /indexName/_search
{
"query": {
"term": {
"FIELD": {
"value": "VALUE"
}
}
}
}
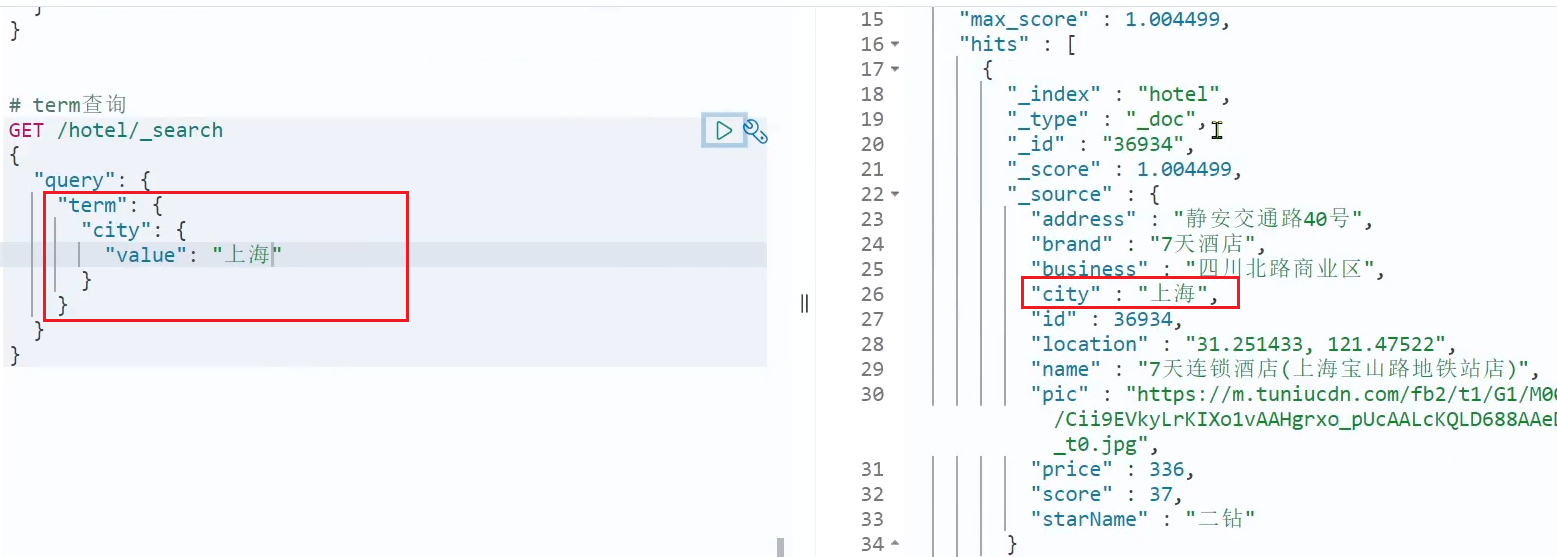
例:
正確な用語を検索すると、結果を正しくクエリできます。
# 精确查询
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "上海"
}
}
}
}
クエリ結果
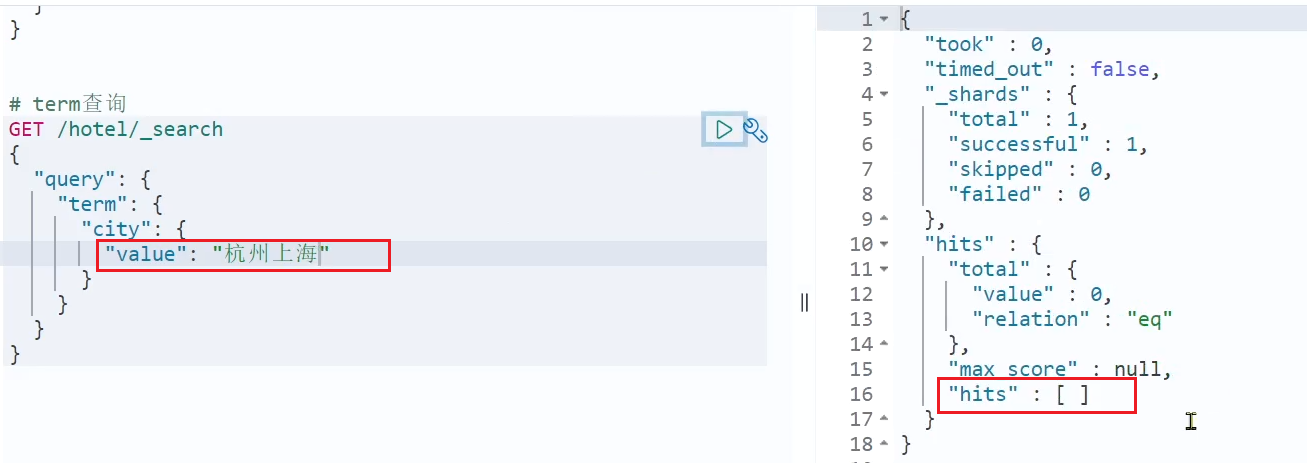
ただし、検索内容がエントリではなく、複数の単語からなるフレーズの場合、検索できません。
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "杭州上海"
}
}
}
}
検索結果:
1.3.2. 範囲クエリ
範囲クエリは、通常、数値型で範囲フィルタリングを実行するときに使用されます。たとえば、価格帯のフィルタリングを行います。
基本的な構文:
// range查询
GET /indexName/_search
{
"query": {
"range": {
"FIELD": {
"gte": 10, // 这里的gte代表大于等于,gt则代表大于
"lte": 20 // lte代表小于等于,lt则代表小于
}
}
}
}
例:
# 精确查询 range
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 1000,
"lte": 3000
}
}
}
}
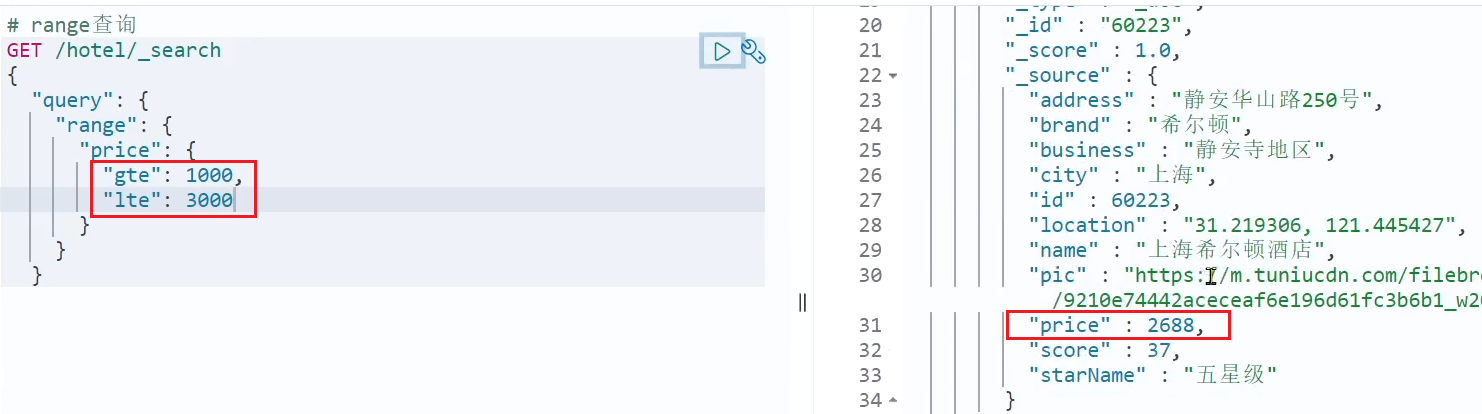
gte: 以上
lte: 以下
gt: 以上
lt: 未満
1.3.3. まとめ
正確なクエリの一般的な種類は何ですか?
- 用語クエリ: 用語に基づく完全一致、一般的な検索キーワード タイプ、数値型、ブール型、日付型フィールド
- 範囲クエリ: 値と日付の範囲である値の範囲に基づくクエリ
1.4. 地理座標クエリ
いわゆる地理座標クエリは、実際には経度と緯度のクエリに基づいています。公式ドキュメント:経度と緯度に基づくクエリ (公式ドキュメント)
一般的な使用シナリオは次のとおりです。
- Ctrip: 近くのホテルを検索
- Didi: 近くのタクシーを探す
- WeChat: 近くの人を検索
近くのホテル:
近くの車:
1.4.1. 矩形範囲クエリ
矩形範囲クエリ、つまり geo_bounding_box クエリは、座標が特定の矩形範囲内にあるすべてのドキュメントをクエリします。
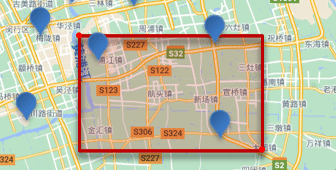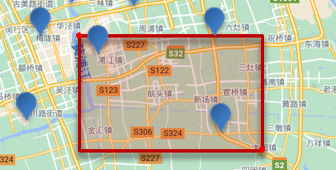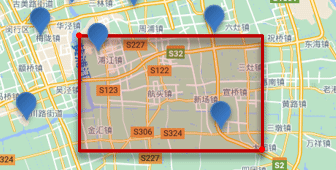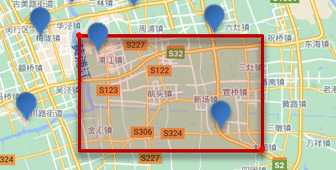
クエリを実行するときは、四角形の左上と右下の点の座標を指定してから四角形を描画する必要があり、四角形内に収まるすべての点が対象となります。
構文は次のとおりです。
// geo_bounding_box查询
GET /indexName/_search
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": {
// 左上点
"lat": 31.1,
"lon": 121.5
},
"bottom_right": {
// 右下点
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
これは「近くの人」のニーズに合わないので、やらない。
1.4.2. Nearby クエリ
距離クエリとも呼ばれる近隣クエリ (geo_distance): 指定された中心点が特定の距離値より小さいすべてのドキュメントをクエリします。
つまり、円の中心としてマップ上のポイントを見つけ、指定された距離を半径として円を描き、円内に収まる座標が適格と見なされます: 文法の説明
:
// geo_distance 查询
GET /indexName/_search
{
"query": {
"geo_distance": {
"distance": "15km", // 半径
"FIELD": "31.21,121.5" // 圆心
}
}
}
例:
# 附近的
GET /hotel/_search
{
"query": {
"geo_distance":{
"distance" : "15km",
"location" : "31.21,121.5"
}
}
}
陸家嘴周辺 15 km 以内のホテルを検索しましょう:
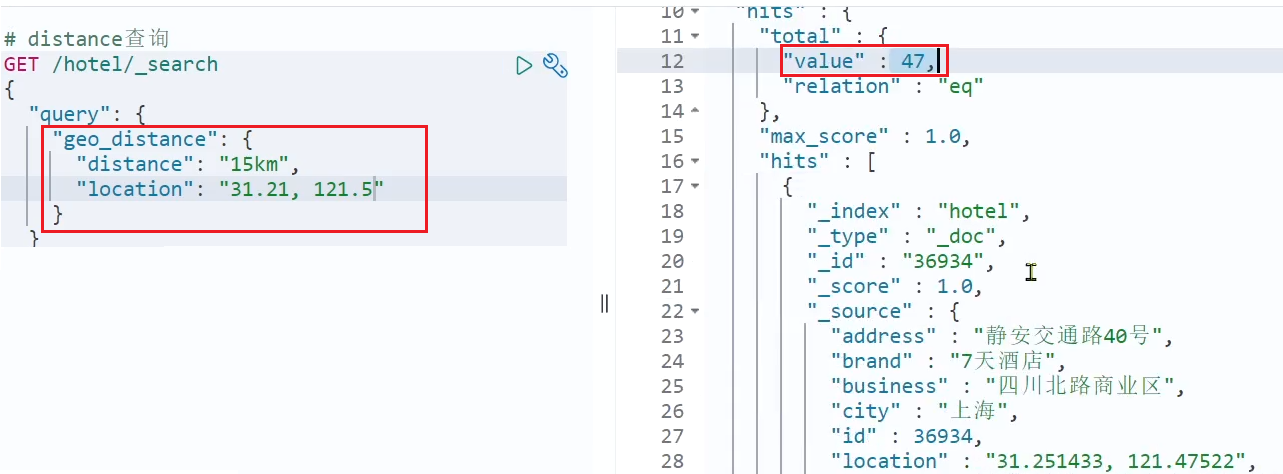
全部で 47 件のホテルが見つかりました。
次に、半径を 3 km に短縮します。
# 附近的
GET /hotel/_search
{
"query": {
"geo_distance":{
"distance" : "3km",
"location" : "31.21,121.5"
}
}
}
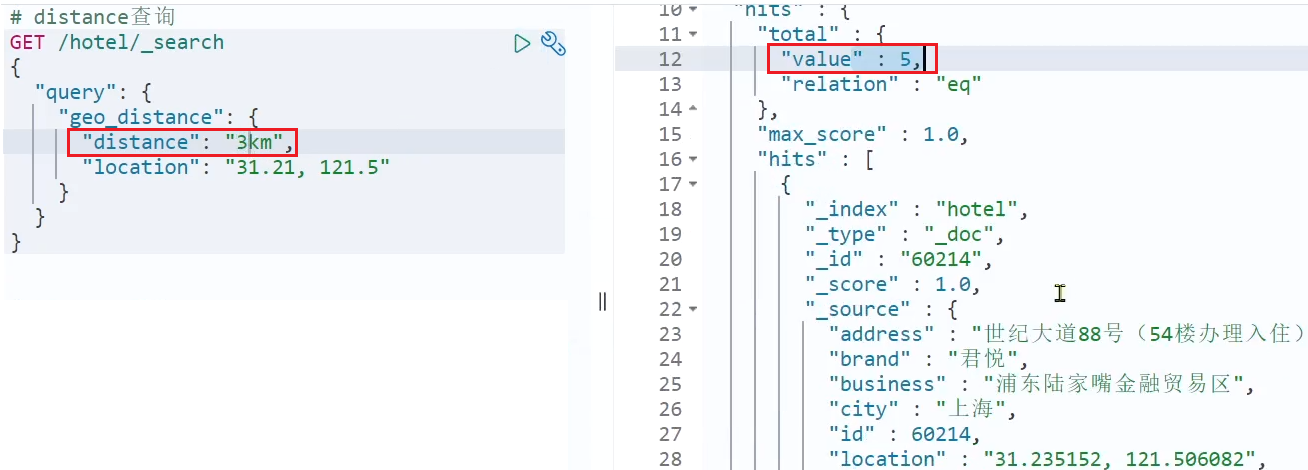
検索されたホテルの数が 5 に減ったことがわかります。
1.5. 複合クエリ
複合クエリ: 複合クエリでは、他の単純なクエリを組み合わせて、より複雑な検索ロジックを実装できます。一般的なものは 2 つあります。
- 関数スコア: ドキュメントの関連性の計算を制御し、ドキュメントのランキングを制御できる計算関数クエリ
- bool query: 論理関係を使用して他の複数のクエリを組み合わせて複雑な検索を実現するブールクエリ。
1.5.1. 相関スコア
一致クエリを使用すると、ドキュメントの結果は検索語との関連性に応じてスコア (_score) が付けられ、返される結果はスコアの降順で並べ替えられます。
たとえば、「Hongqiao Home Inn」を検索すると、結果は次のようになります。
[
{
"_score" : 17.850193,
"_source" : {
"name" : "虹桥如家酒店真不错",
}
},
{
"_score" : 12.259849,
"_source" : {
"name" : "外滩如家酒店真不错",
}
},
{
"_score" : 11.91091,
"_source" : {
"name" : "迪士尼如家酒店真不错",
}
}
]
Elasticsearch では、初期のスコアリング アルゴリズムは TF-IDF アルゴリズムであり、式は次のとおりです。

後のバージョン 5.1 アップグレードでは、elasticsearch はアルゴリズムを BM25 アルゴリズムに改善しました。式は次のとおりです。

TF-IDF アルゴリズムには欠陥があります。つまり、用語の頻度が高いほど、ドキュメント スコアが高くなり、単一の用語がドキュメントに与える影響が大きくなります。ただし、BM25 には 1 回のエントリのスコアに上限があり、曲線はより滑らかになります。
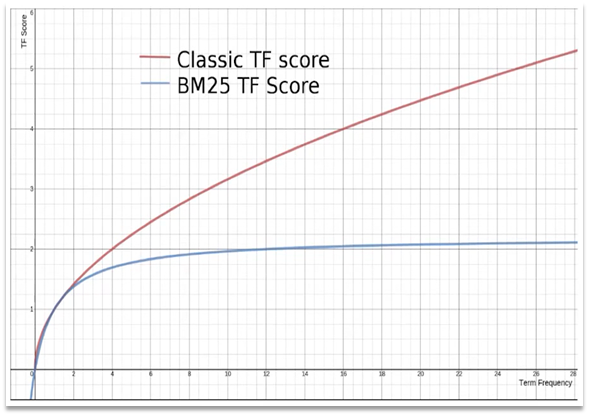
要約: elasticsearch は、用語とドキュメントの関連性に従ってスコアを付けます. 2 つのアルゴリズムがあります:
- TF-IDF アルゴリズム
- BM25 アルゴリズム、elasticsearch のバージョン 5.1 以降に採用されたアルゴリズム
1.5.2. スコア関数クエリ
関連性に基づいたスコアリングは合理的な要件ですが、合理的なものは必ずしもプロダクト マネージャーが必要とするものではありません。
Baidu を例にとると、検索結果では、関連性が高いほどランキングが高くなるわけではなく、ランキングが高いほど、誰がより多く支払うかがわかります。写真に示すように:
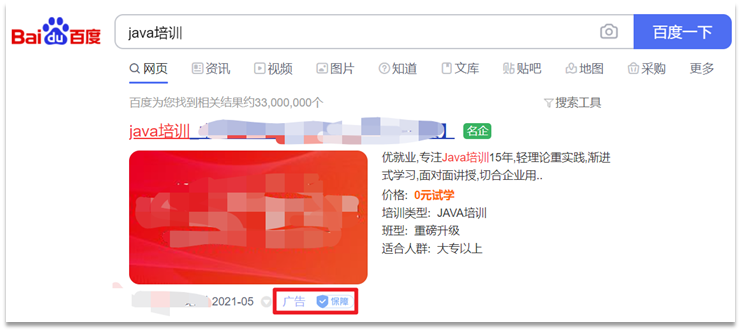
相関スコアを制御する場合は、 elasticsearch でスコア関数クエリを使用する必要があります。
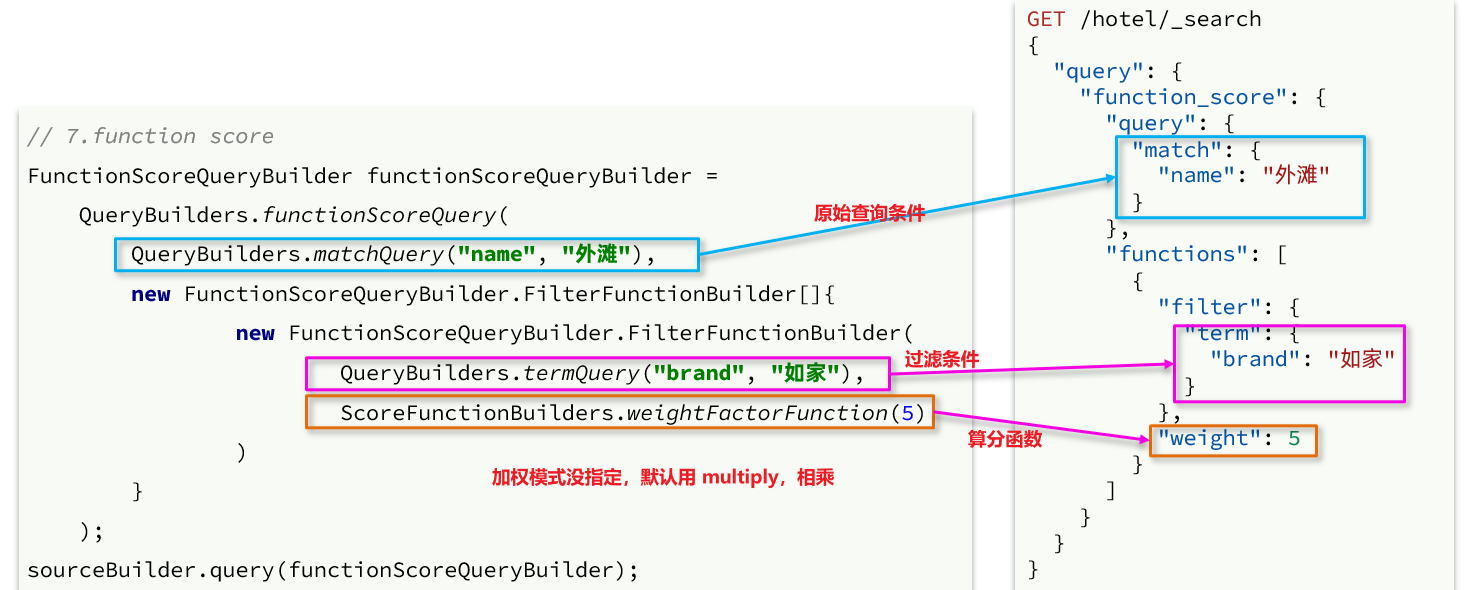
1) 文法説明
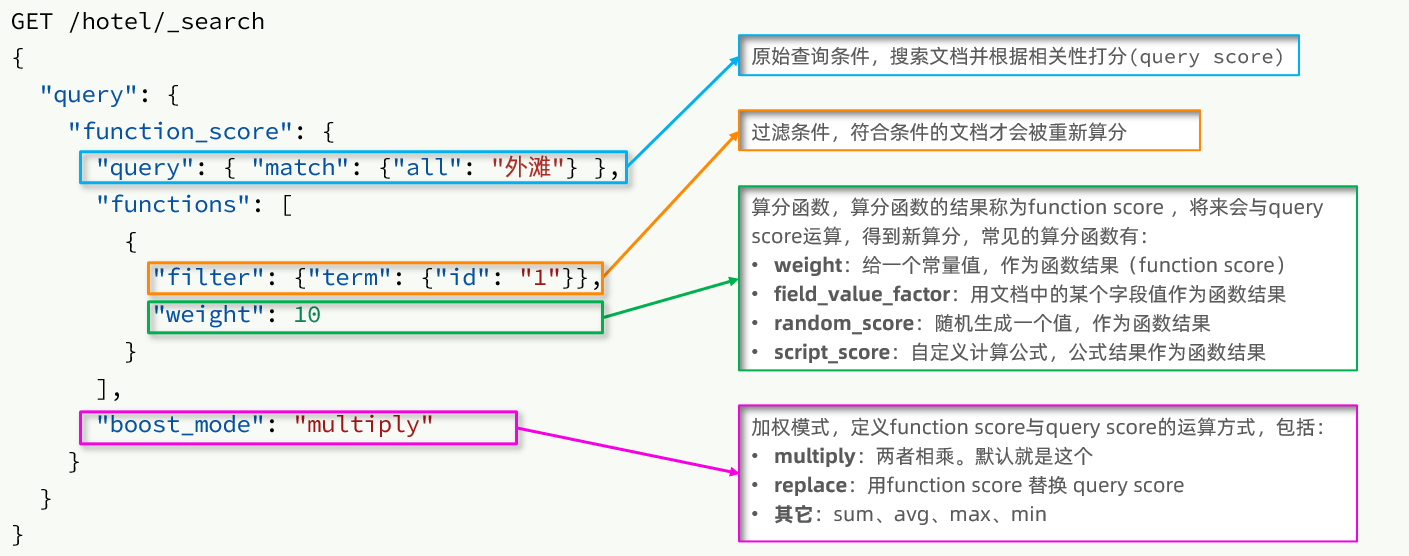
関数スコア クエリには、次の 4 つの部分が含まれます。
- 元のクエリ条件: クエリ部分、この条件に基づいてドキュメントを検索し、BM25 アルゴリズムに基づいてドキュメントをスコア付けする、元のスコア(クエリ スコア)
- フィルター条件: フィルター部分、この条件を満たすドキュメントは再計算されます
- 計算機能: フィルター条件を満たすドキュメントは、この関数に従って計算する必要があり、取得された関数スコア(関数スコア) には、4 つの関数があります。
- 重み: 関数の結果は定数です
- field_value_factor: ドキュメント内のフィールド値を関数の結果として使用します
- random_score: 関数の結果として乱数を使用します
- script_score: カスタム スコアリング関数アルゴリズム
- 計算モード: 計算関数の結果、元のクエリの相関計算スコア、および 2 つの間の計算方法。
- 乗算: 乗算
- replace: クエリ スコアを関数スコアに置き換えます
- その他: sum、avg、max、min など
関数スコアの操作プロセスは次のとおりです。
- 1)元の条件に従ってドキュメントをクエリおよび検索し、元のスコア(クエリ スコア)と呼ばれる関連性スコアを計算します。
- 2)フィルター条件に従って、ドキュメントをフィルター処理します
- 3)フィルタ条件を満たすドキュメントについては、スコア関数の計算に基づいて関数スコアが取得されます。
- 4)動作モードに基づいて、元のスコア(クエリ スコア) と関数スコア(機能スコア)が計算され、最終的な結果が相関スコアとして取得されます。
したがって、ここでの重要なポイントは次のとおりです。
- フィルター条件: スコアが変更されたドキュメントを特定する
- スコアリング関数: 関数のスコアを決定するアルゴリズム
- 計算モード: 最終的な計算結果を決定します
2) 例
条件:「ホームイン」ブランドのホテルを上位ランク
この要件を前述の 4 つのポイントに変換します。
- 元の状態:不明、勝手に変更可能
- フィルタ条件: ブランド = 「ホーム イン」
- 計算機能:単純で失礼なことができ、固定の計算結果、重みを直接与えることができます
- 演算モード:加算など
まず、最も独創的なクエリを使用して、外灘近くのホテルを検索してみましょう
# 把如家酒店排名靠前
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "外滩"
}
}
}
}
}
クエリ結果は次のとおりです。 グランド ハイアット ホテルがフロント付近にあることを示します。

関数を追加して、
最終的な DSL ステートメントを次のようにします。
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
.... }, // 原始查询,可以是任意条件
"functions": [ // 算分函数
{
"filter": {
// 满足的条件,品牌必须是如家
"term": {
"brand": "如家"
}
},
"weight": 2 // 算分权重为2
}
],
"boost_mode": "sum" // 加权模式,求和
}
}
}
テスト、スコアリング機能が追加されていない場合のホーム インのスコアは次のとおりです:
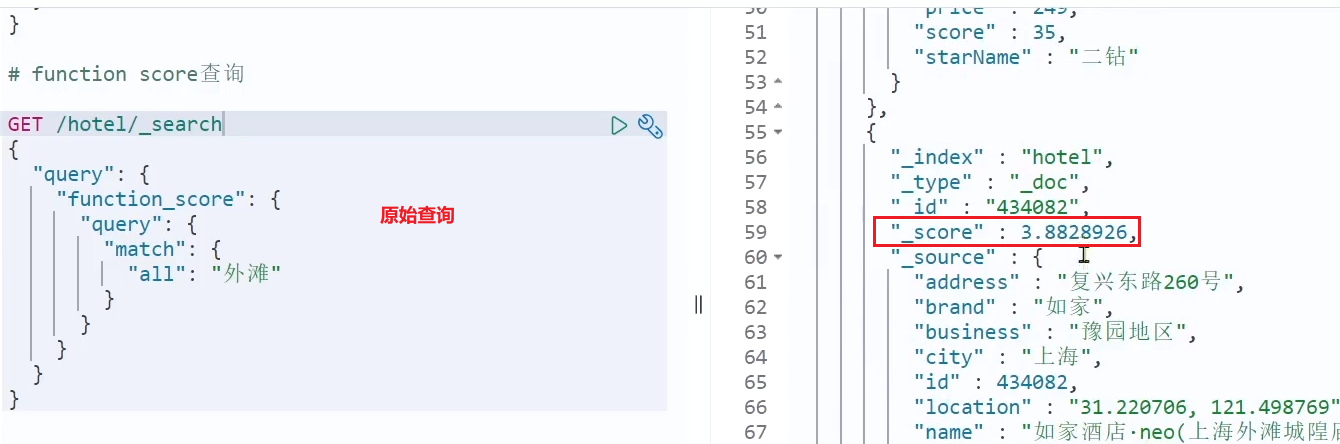
スコアリング機能を追加した後、ホーム インのスコアは改善されます。
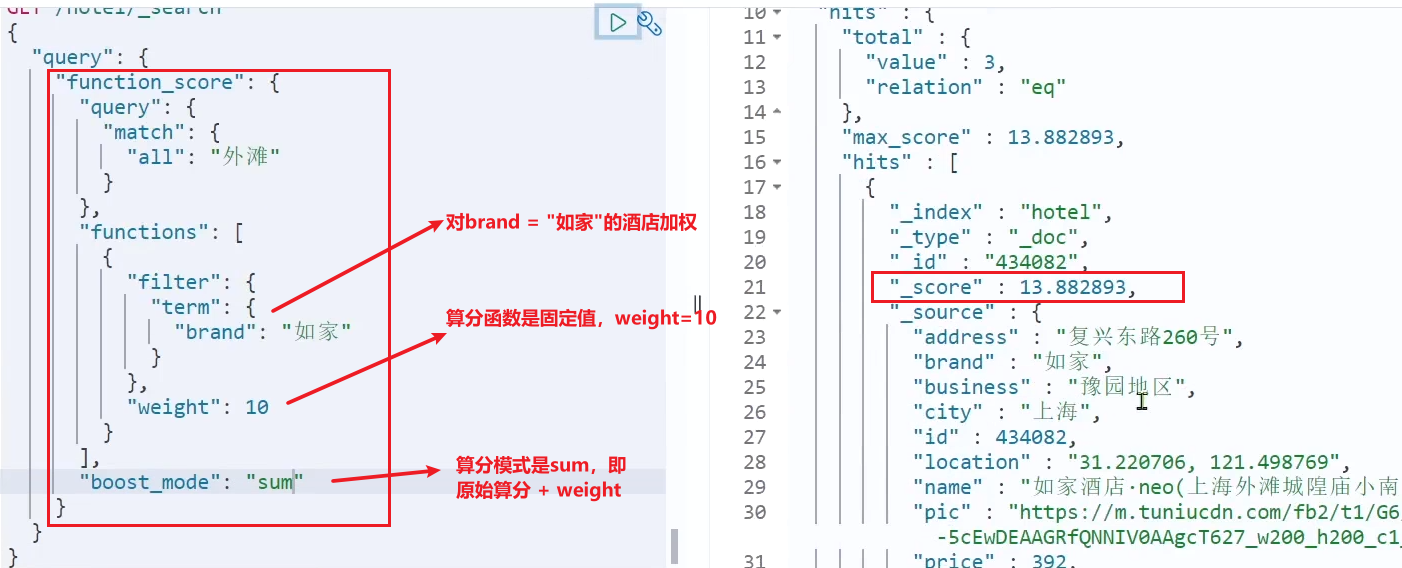
3) まとめ
関数スコア クエリで定義される 3 つの要素は何ですか?
- フィルター条件: どのドキュメントにポイントを追加するか
- 計算機能:機能スコアの計算方法
- 重み付け方法: 関数スコアとクエリ スコアの計算方法
1.5.3. 複合クエリ – ブールクエリ
ブールクエリは、1 つ以上のクエリ句の組み合わせであり、それぞれがサブクエリです。サブクエリは、次の方法で組み合わせることができます。
- must: 「and」と同様に、各サブクエリに一致する必要があります
- should: 「or」に似た選択的マッチング サブクエリ
- must_not: 一致してはならない、スコアリングに参加しない、「not」と同様
- フィルター: 一致する必要があります。スコアリングには参加しません
たとえば、ホテルを検索する場合、キーワード検索に加えて、ブランド、価格、都市などのフィールドに基づいてフィルタリングすることもあります。
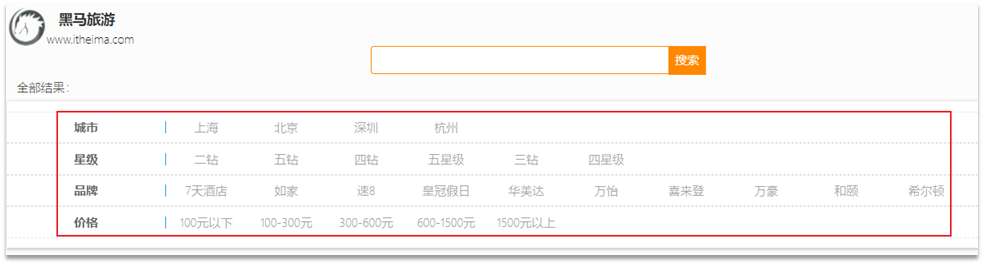
各フィールドには異なるクエリ条件とメソッドがあり、複数の異なるクエリである必要があります.これらのクエリを組み合わせるには、ブールクエリを使用する必要があります.
検索の際、スコアリングに関与するフィールドが多いほど、クエリのパフォーマンスが低下することに注意してください。したがって、複数の条件でクエリを実行する場合は、次のようにすることをお勧めします。
- 検索ボックスのキーワード検索は全文検索クエリであり、must クエリを使用し、スコアリングに参加します
- その他のフィルター条件については、フィルター クエリを使用します。採点に参加しない
1) 文法の例:
クエリ:
都市: 上海
ブランド: クラウン プラザまたはラマダ
価格: 500 以上、スコアリングには関与しない
スコア: 45 以上、ポイントの計算には関与しない
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"city": "上海" }}
],
"should": [
{
"term": {
"brand": "皇冠假日" }},
{
"term": {
"brand": "华美达" }}
],
"must_not": [
{
"range": {
"price": {
"lte": 500 } }}
],
"filter": [
{
"range": {
"score": {
"gte": 45 } }}
]
}
}
}
2) 例
要件: 名前に「Home Inn」が含まれ、価格が 400 以下で、座標 31.21, 121.5 を中心に 10 km 以内のホテルを検索します。
分析:
- 名前検索は全文検索クエリであり、スコアリングに関与する必要があります。入れなければならない
- 価格が 400 を超えない場合は、フィルター条件に属し、ポイントの計算に参加しない範囲をクエリに使用します。must_not に入れる
- 10km の範囲内で、geo_distance を使用してクエリを実行します。これはフィルター条件に属し、ポイントの計算には関与しません。フィルターに入れる
# 复合搜索--布尔查询
# 搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店。
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "如家"
}
}
],
"must_not": [
{
"range": {
"price": {
"gt": 400
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "10km",
"location": {
"lat": 31.21,
"lon": 121.5
}
}
}
]
}
}
}
クエリ結果は次のとおりです。
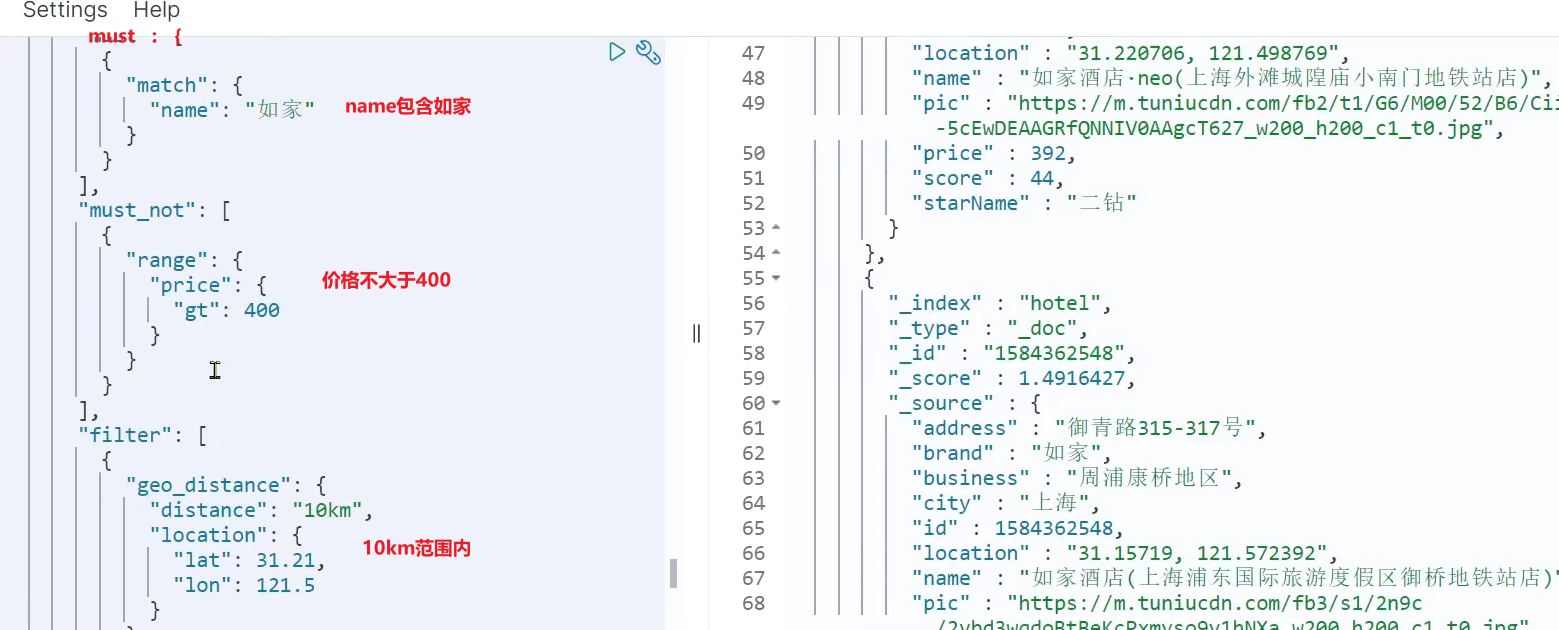
3) まとめ
bool クエリにはいくつの論理関係がありますか?
- must: 一致しなければならない条件で、「and」として理解できます。
- should: 「または」として理解できる、選択的マッチングの条件。
- must_not: 一致してはならない条件、スコアリングに参加しない
- フィルター: 一致する必要がある条件、スコアリングに参加しない
2. 検索結果の処理
検索結果は、ユーザーが指定した方法で処理または表示できます。
2.1. ソート
デフォルトでは、Elasticsearch は相関スコア (_score) に従って並べ替えますが、検索結果を並べ替えるカスタムの方法もサポートしています。並べ替え可能なフィールド タイプには、キーワード タイプ、数値タイプ、地理座標タイプ、日付タイプなどがあります。
2.1.1. 通常のフィールドのソート
キーワード、値、および日付によるソートの構文は、基本的に同じです。
文法:
GET /indexName/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"FIELD": "desc" // 排序字段、排序方式ASC、DESC
}
]
}
ソート条件は配列です。つまり、複数のソート条件を記述できます。宣言の順序に従って、最初の条件が等しい場合は、2 番目の条件に従って並べ替えます。
例:
要件の説明: ホテルのデータをユーザーの評価 (score) の降順で並べ替え、同じ評価を価格 (price) の昇順で並べ替える
コードは次のとおりです。
# 需求描述:酒店数据按照用户评价(score)降序排序,评价相同的按照价格(price)升序排序
GET /hotel/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"score": {
"order": "desc"
},
"price": {
"order": "asc"
}
}
]
}
検索結果:

2.1.2. 地理座標ソート
地理座標の順序はわずかに異なります。
文法説明:
GET /indexName/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"_geo_distance" : {
"FIELD" : "纬度,经度", // 文档中geo_point类型的字段名、目标坐标点
"order" : "asc", // 排序方式
"unit" : "km" // 排序的距离单位
}
}
]
}
このクエリの意味は次のとおりです。
- 目標点として座標を指定
- 指定されたフィールド (geo_point タイプである必要があります) の座標から各ドキュメントのターゲット ポイントまでの距離を計算します
- 距離順
例:
要件の説明: 位置座標までの距離に応じて、ホテル データを昇順にソートすることを実現する
ヒント: 現在地の緯度と経度を取得する方法:緯度と経度を取得するガウド マップ
私の場所が 31.034661, 121.612282 であると仮定し、私の近くの最も近いホテルを探します。
# 假设我的位置是:31.034661,121.612282,寻找我周围距离最近的酒店。
GET /hotel/_search
{
"query": {
"match_all": {
}
}
, "sort": [
{
"_geo_distance": {
"location": {
"lat": 31.034661,
"lon": 121.612282
},
"order": "asc",
"unit": "km"
}
}
]
}
検索結果:
2.2. ページネーション
デフォルトでは、Elasticsearch は上位 10 件のデータのみを返します。さらに多くのデータを照会する場合は、ページング パラメーターを変更する必要があります。elasticsearch で、from パラメーターと size パラメーターを変更して、返されるページング結果を制御します。
- from: 最初のいくつかのドキュメントから開始
- size: 合計でクエリするドキュメントの数
mysqlに似ているlimit ?, ?
2.2.1. 基本的なページネーション
ページネーションの基本的な構文は次のとおりです。
GET /hotel/_search
{
"query": {
"match_all": {
}
},
"from": 0, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{
"price": "asc"}
]
}
例: 0 ~ 20 ページのホテル情報を価格の降順でクエリする
# 示例:查询0 ~ 20页的酒店信息,按照价格降序
GET /hotel/_search
{
"query": {
"match_all": {
}
}
, "sort": [
{
"price": {
"order": "desc"
}
}
],
"from": 0,
"size": 20
}
検索結果:

2.2.2. 深いページネーションの問題
今、990~1000のデータをクエリしたいのですが、クエリロジックは次のように書く必要があります:
GET /hotel/_search
{
"query": {
"match_all": {
}
},
"from": 990, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{
"price": "asc"}
]
}
これは、クエリ 990 から始まるデータ、つまり 990 番目から 1000 番目のデータです。
ただし、elasticsearch 内でページングする場合は、最初に 0 ~ 1000 エントリをクエリし、次に 990 ~ 1000 の 10 エントリをインターセプトする必要があります。
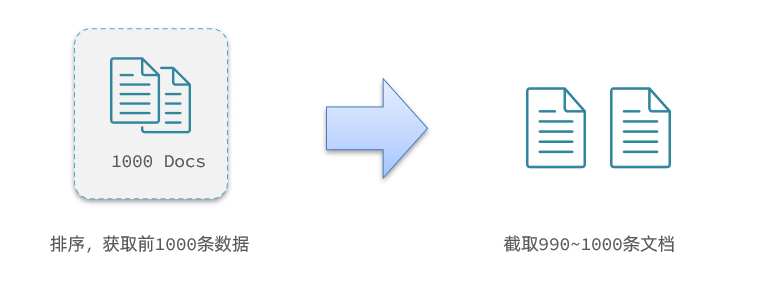
TOP1000 をクエリします。es がシングルポイント モードの場合、これはあまり影響しません。
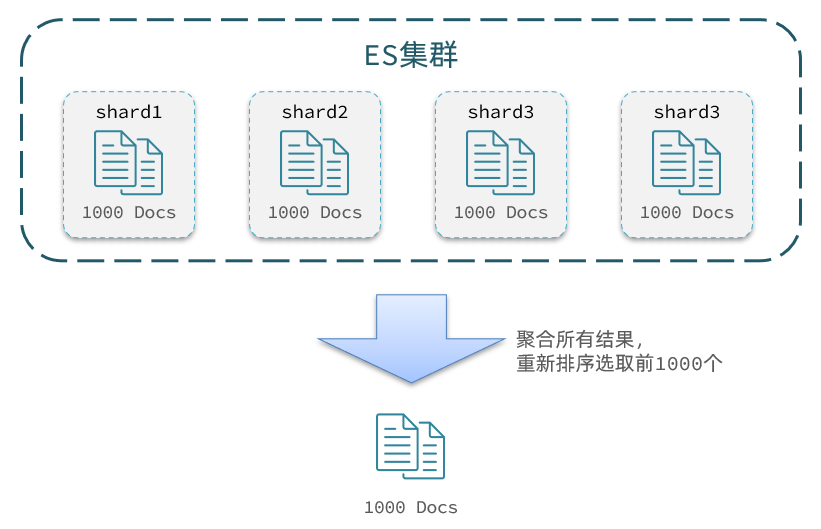
しかし、elasticsearch は将来クラスターになる必要があります. たとえば、私のクラスターには 5 つのノードがあり、TOP1000 のデータをクエリしたいのですが、ノードごとに 200 アイテムをクエリするには十分ではありません.
ノード A の TOP200 が、別のノードで 10,000 を超えてランク付けされる可能性があるためです。
したがって、クラスター全体の TOP1000 を取得する場合は、最初に各ノードの TOP1000 をクエリし、結果を集計した後、TOP1000 を再ランク付けして再インターセプトする必要があります。
では、9900~10000 のデータをクエリしたい場合はどうすればよいでしょうか? 最初に TOP10000 を照会する必要がありますか? 次に、各ノードは 10,000 エントリを照会する必要がありますか? メモリに集約?
クエリのページング深度が大きい場合、集計データが多すぎて、メモリと CPU に大きな負担がかかるため、elasticsearch は from+ サイズが 10,000 を超えるリクエストを禁止します。
ディープ ページングの場合、ES は 2 つのソリューション、公式ドキュメントを提供します。
- 検索後: ページングの際にソートが必要です。原則として、最後のソート値から始まるデータの次のページを照会します。公式おすすめの使い方。
- scroll: 原理は、ソートされたドキュメント ID のスナップショットを作成し、それらをメモリに保存することです。これは公式に非推奨です。
2.2.3. まとめ
ページネーション クエリの一般的な実装スキームと長所と短所:
from + size:- 利点: ランダムなページめくりをサポート
- 短所: ディープ ページングの問題、デフォルトのクエリ上限 (+ サイズから) は 10000 です
- シナリオ: Baidu、JD.com、Google、Taobao などのランダムなページめくり検索
after search:- 利点: クエリの上限がない (1 つのクエリのサイズが 10000 を超えない)
- 短所: ページごとに逆方向にクエリすることしかできず、ランダムなページめくりはサポートされていません
- シナリオ: 携帯電話を下にスクロールしてページをめくるなど、ランダムにページをめくる必要のない検索
scroll:- 利点: クエリの上限がない (1 つのクエリのサイズが 10000 を超えない)
- 短所: 追加のメモリ消費があり、検索結果はリアルタイムではありません
- シナリオ: 大量のデータの取得と移行。ES7.1 から開始することはお勧めしません。検索後のソリューションを使用することをお勧めします。
2.3. ハイライト
2.3.1. ハイライトの原則
ハイライトとは?
Baidu と JD.com で検索すると、キーワードが赤くなり、より人目を引きます. これは強調表示と呼ばれます:

強調表示の実装は 2 つのステップに分けられます。
<em>1) labelなど、ドキュメント内のすべてのキーワードにラベルを追加します- 2) ページは
<em>タグの CSS スタイルを書き込みます
2.3.2. ハイライトを実現する
強調表示された構文:
GET /hotel/_search
{
"query": {
"match": {
"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询
}
},
"highlight": {
"fields": {
// 指定要高亮的字段
"FIELD": {
"pre_tags": "<em>", // 用来标记高亮字段的前置标签
"post_tags": "</em>" // 用来标记高亮字段的后置标签
}
}
}
}
例: たとえば、Home Inn を強調表示したい場合
# 示例:如家显示高亮
GET /hotel/_search
{
"query": {
"match": {
"all": "如家"
}
},
"highlight": {
"fields": {
"name": {
"pre_tags": "<em>"
, "post_tags": "</em>"
}
}
}
}
結果は次のとおりです。

知らせ:
- 強調表示はキーワード用であるため、検索条件には範囲クエリではなくキーワードを含める必要があります。
- デフォルトでは、強調表示されたフィールドは検索で指定されたフィールドと同じである必要があり、そうでない場合は強調表示できません
- 非検索フィールドを強調表示する場合は、次の属性を追加する必要があります: required_field_match=false
例:
# 示例:如家显示高亮
GET /hotel/_search
{
"query": {
"match": {
"all": "如家"
}
},
"highlight": {
"fields": {
"name": {
"pre_tags": "<em>",
"post_tags": "</em>",
"require_field_match": "false"
}
}
}
}
2.4. まとめ
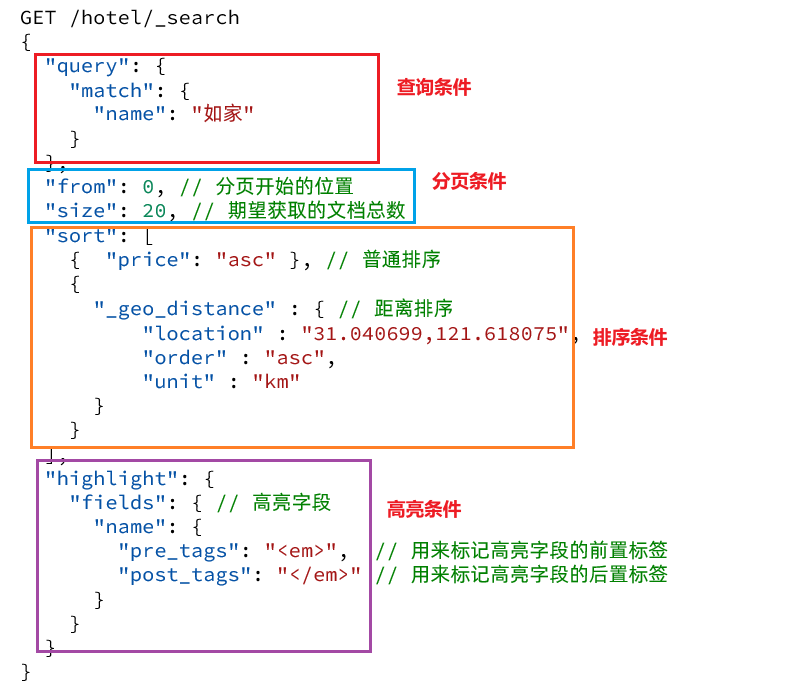
クエリ DSL は、次のプロパティを持つ大きな JSON オブジェクトです。
- クエリ: クエリ条件
- from と size: ページング条件
- sort: ソート条件
- ハイライト:ハイライト状態
例:
3. RestClient クエリ ドキュメント
ドキュメント クエリは、昨日学習した RestHighLevelClient オブジェクトにも適用できます。基本的な手順は次のとおりです。
- 1) Request オブジェクトを用意する
- 2) リクエストパラメータの準備
- 3) リクエストを開始する
- 4) 応答を解析する
3.1. クイックスタート
例として match_all クエリを見てみましょう
3.1.1. クエリリクエストの開始
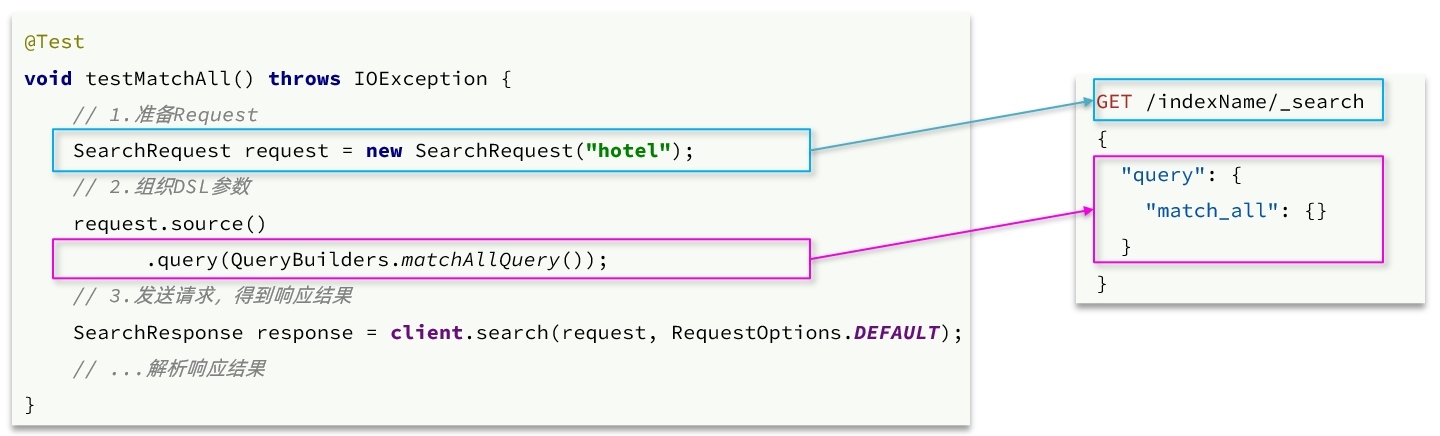
コードの解釈:
- 最初のステップは、
SearchRequestオブジェクトを作成し、索引ライブラリー名を指定することです - 2 番目のステップは、
request.source()クエリ、ページング、並べ替え、強調表示などを含むことができる DSL の構築を 使用することです。query()QueryBuilders.matchAllQuery(): DSLを使用して match_all クエリを作成し、クエリ条件を表します
- 3 番目のステップは、 client.search() を使用してリクエストを送信し、レスポンスを取得することです。
ここには 2 つの重要な API があります. 1 つは、request.source()クエリ、並べ替え、ページング、強調表示などのすべての機能が含まれていることです。
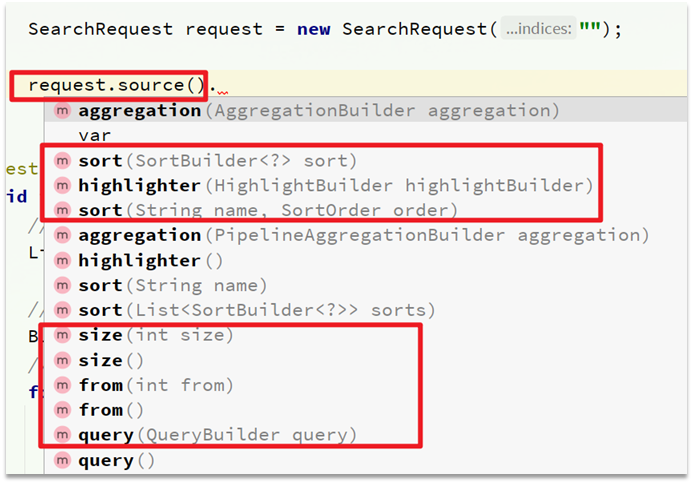
もう 1 つは、QueryBuildersmatch、term、function_score、bool などのさまざまなクエリが含まれていることです。

コードは次のとおりです:
HotelSearchTest.java
/**
* DSL查询所有索引matchall
*
* @throws IOException
*/
@Test
void testMatchAll() throws IOException {
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().query(QueryBuilders.matchAllQuery());
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("结果是:" + response);
}
実行後に結果を確認します。

3.1.2. レスポンスの解析
応答結果の分析:
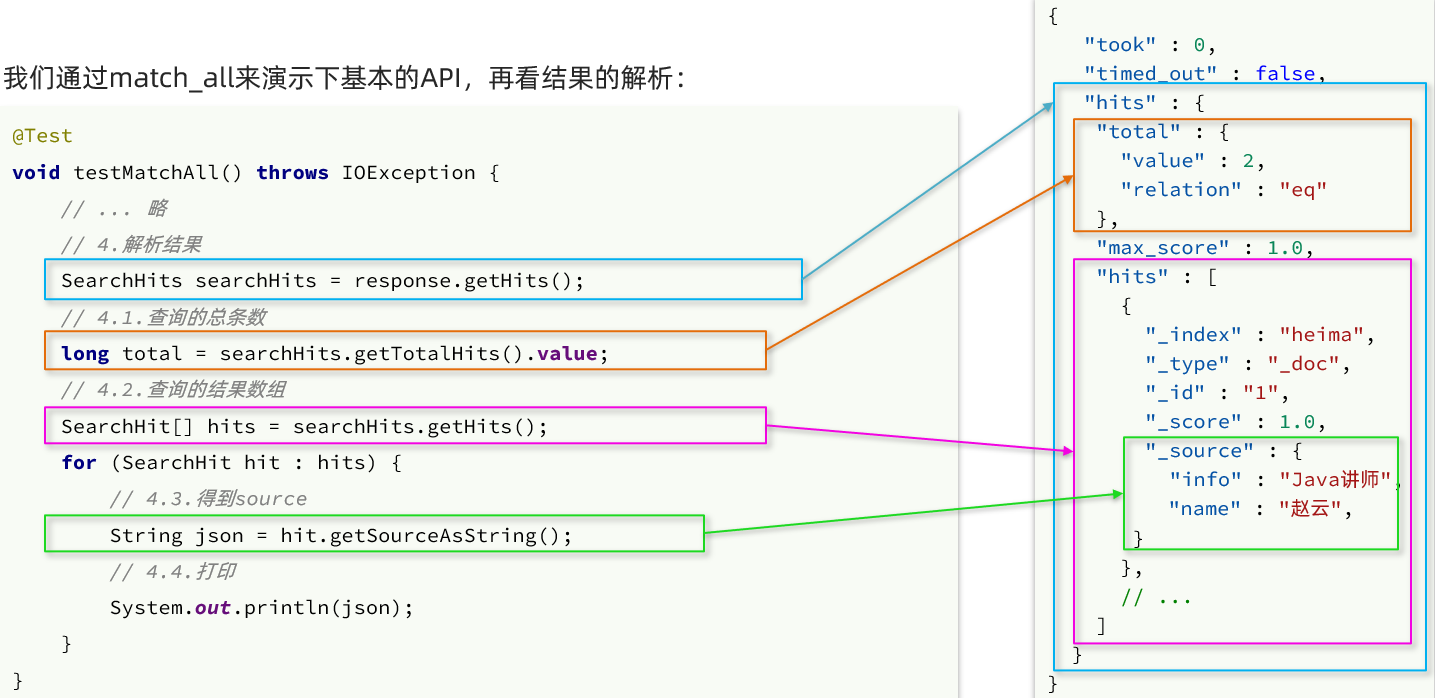
elasticsearch によって返される結果は JSON 文字列であり、構造には以下が含まれます。
hits: ヒットの結果total: エントリの合計数。値は特定の合計エントリ値ですmax_score: すべての結果で最もスコアが高いドキュメントの関連性スコアhits: 検索結果のドキュメントの配列で、それぞれが json オブジェクトです_source: ドキュメント内の元のデータ、これも json オブジェクト
したがって、JSON 文字列をレイヤーごとに解析することである応答結果を解析します。
SearchHits: JSON の最も外側のヒットである response.getHits() を介して取得され、ヒットの結果を表しますSearchHits#getTotalHits().value: 情報の総数を取得するSearchHits#getHits(): ドキュメント配列である SearchHit 配列を取得します。SearchHit#getSourceAsString(): ドキュメント結果の _source を取得します。これは、元の json ドキュメント データです。
3.1.3. 完全なコード
完全なコードは次のとおりです。
@Test
void testMatchAll() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source()
.query(QueryBuilders.matchAllQuery());
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
private void handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
}
操作結果:

3.1.4. まとめ
クエリの基本的な手順は次のとおりです。
-
SearchRequest オブジェクトを作成する
-
DSL である Request.source() を用意します。
①クエリ条件を構築するQueryBuilders
②Request.source()のquery()メソッドに渡す
-
リクエストを送信し、結果を取得
-
結果の解析 (JSON の結果を参照、外側から内側へ、レイヤーごとに解析)
3.2. マッチクエリ
全文検索の match クエリと multi_match クエリは、基本的に match_all の API と同じです。違いは、クエリ部分であるクエリ条件です。

したがって、Java コードの違いは主に request.source().query() のパラメーターです。QueryBuilders が提供するメソッドも使用します。

結果の解析コードは完全に一貫しており、抽出して共有できます。
完全なコードは次のとおりです。
@Test
void testMatch() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source()
.query(QueryBuilders.matchQuery("all", "如家"));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
クエリ結果は次のとおりです。 multimatch HotelSearchTest.java

を見てみましょう。
@Test
public void testMultiMatch() throws IOException {
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().query(QueryBuilders.multiMatchQuery("如家", "brand", "name", "business"));
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
long total = hits.getTotalHits().value;
System.out.println("总共有:" + total + "条");
SearchHit[] searchHits = hits.getHits();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);
System.out.println(hotelDoc);
}
}
結果は次のとおりです。

3.3. 正確なクエリ
正確なクエリは主に 2 つあります。
- term: 用語完全一致
- 範囲: 範囲クエリ
前のクエリと比較すると、違いはクエリ条件にもあり、それ以外はすべて同じです。
検索条件構築用のAPIは以下の通りです。

用語例:
HotelSearchTest.java
@Test
public void testTerm() throws IOException {
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().query(QueryBuilders.termQuery("city", "深圳"));
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
long total = hits.getTotalHits().value;
System.out.println("总共有:" + total + "条");
SearchHit[] searchHits = hits.getHits();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);
System.out.println(hotelDoc);
}
}
クエリ結果:

range 例:
HotelSearchTest.java
@Test
public void testRange() throws IOException {
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().query(QueryBuilders.rangeQuery("price").gte(300));
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
long total = hits.getTotalHits().value;
System.out.println("总共有:" + total + "条");
SearchHit[] searchHits = hits.getHits();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);
System.out.println(hotelDoc);
}
}
検索結果:

3.4. ブールクエリ
ブールクエリは、must、must_not、filter などと他のクエリを組み合わせたものです。コード例は次のとおりです。
API と他のクエリの違いは、クエリ条件の構築、QueryBuilders、結果の解析、およびその他のコードがまったく変更されていないことです。
完全なコードは次のとおりです。
@Test
void testBool() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.准备BooleanQuery
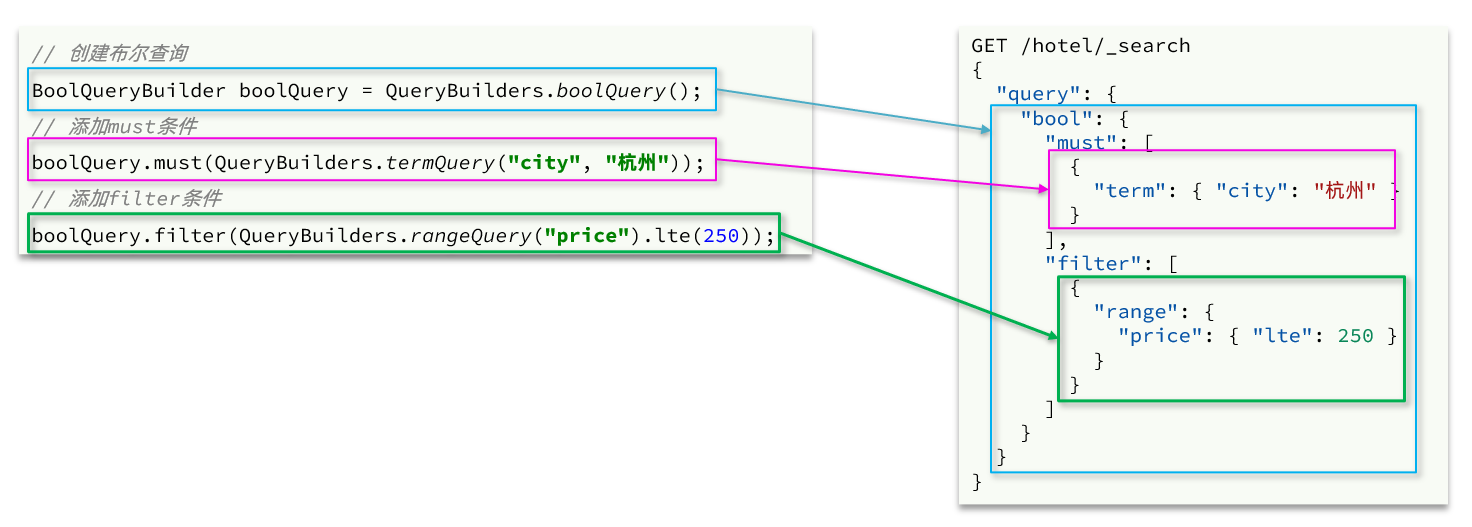
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 2.2.添加term
boolQuery.must(QueryBuilders.termQuery("city", "上海"));
// 2.3.添加range
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(350));
request.source().query(boolQuery);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
検索結果:

3.5. ソート、ページング
検索結果の並べ替えやページングはクエリと同レベルのパラメータなので、request.source()でも設定します。
対応する API は次のとおりです。

完全なコード例:
@Test
void testPageAndSort() throws IOException {
// 页码,每页大小
int page = 1, size = 5;
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
request.source().query(QueryBuilders.matchAllQuery());
// 2.2.排序 sort
request.source().sort("price", SortOrder.DESC);
// 2.3.分页 from、size
request.source().from((page - 1) * size).size(5);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
クエリ結果:価格降順

3.6. ハイライト
強調表示されたコードは、前のコードとはかなり異なります。次の 2 つの点があります。
- クエリ DSL: クエリ条件に加えて、ハイライト条件も追加する必要があります。これもクエリと同じレベルです。
- 結果の解析: _source ドキュメント データの解析に加えて、結果は強調表示された結果も解析する必要があります。
3.6.1. ハイライトリクエストビルド
ハイライト リクエストの構築 API は次のとおりです。
上記のコードではクエリ条件部分が省略されていますが、忘れないでください: 今後キーワードを強調表示できるように、強調表示クエリでは全文検索と検索キーワードを使用する必要があります。
完全なコードは次のとおりです。
@Test
void testHighlight() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
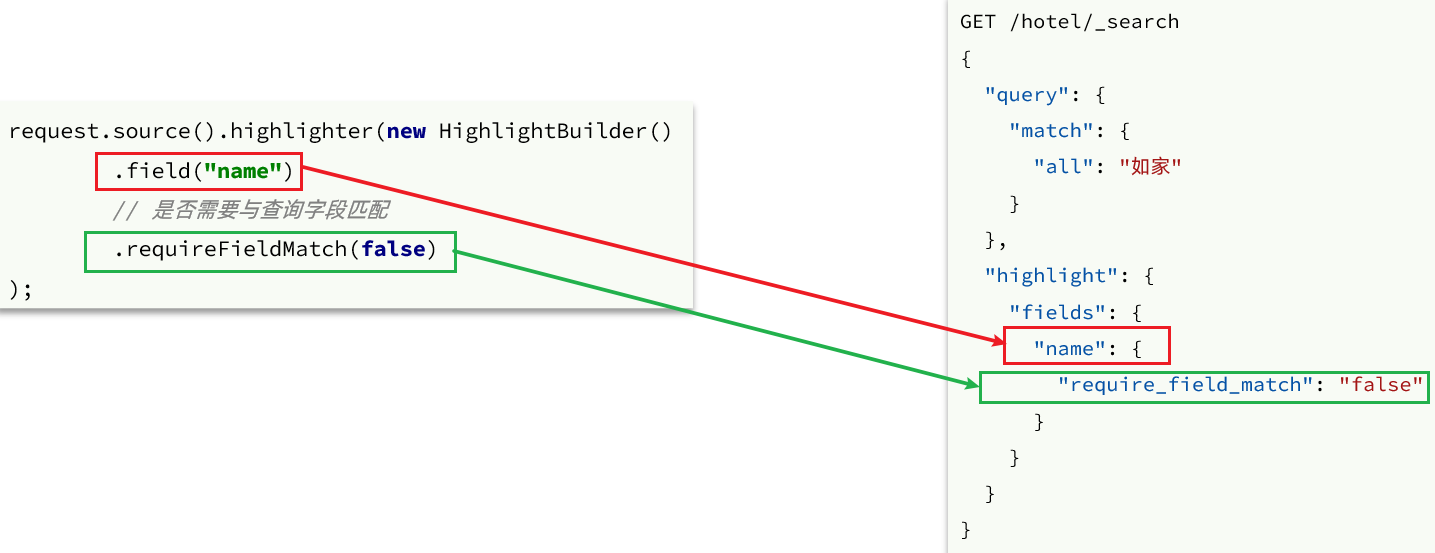
request.source().query(QueryBuilders.matchQuery("all", "如家"));
// 2.2.高亮
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
3.6.2. ハイライトされた結果の分析
強調表示された結果とクエリ ドキュメントの結果は、既定では分離されており、一緒には表示されません。
したがって、強調表示されたコードを解析するには、追加の処理が必要です。
コードの解釈:
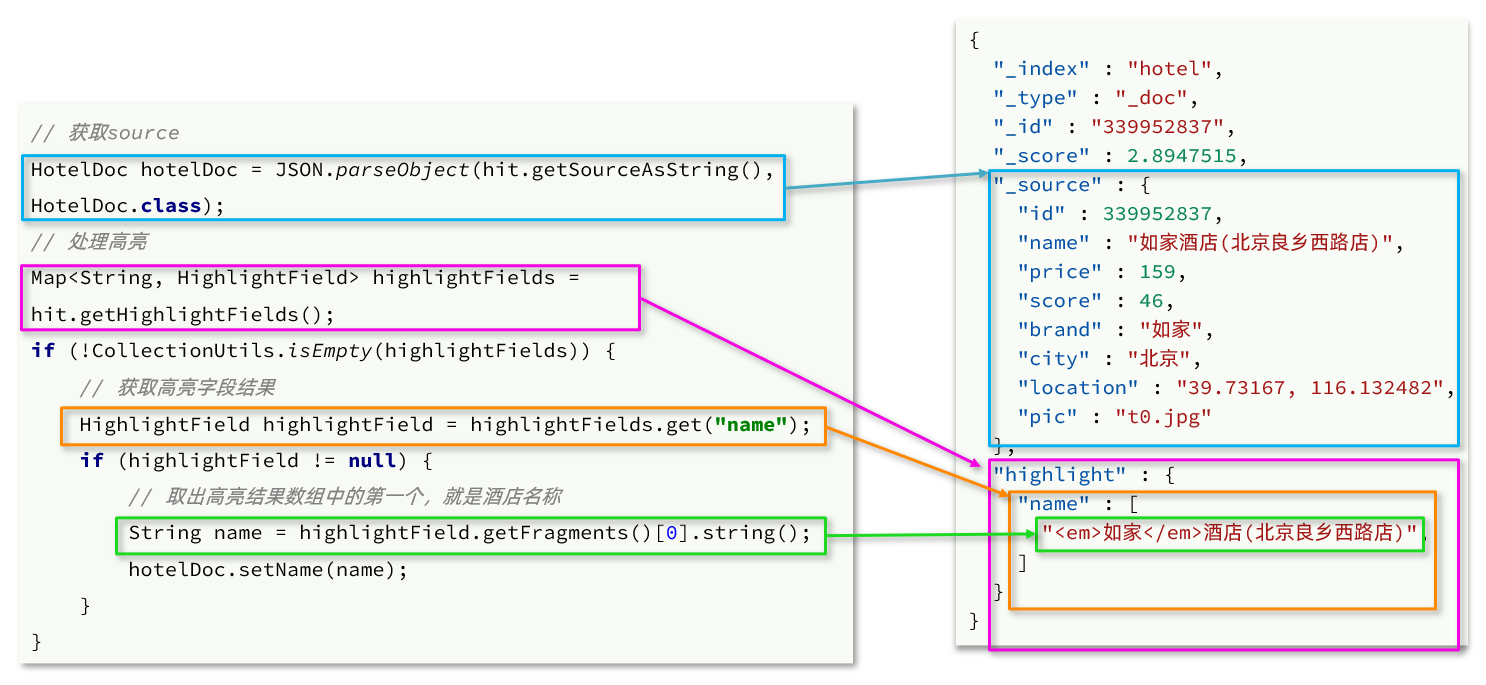
- ステップ 1: 結果からソースを取得します。hit.getSourceAsString()、この部分は強調表示されていない結果、json 文字列です。また、HotelDoc オブジェクトに逆シリアル化する必要があります。
- ステップ 2: 強調表示された結果を取得します。hit.getHighlightFields()、戻り値はマップ、キーはハイライト フィールド名、値はハイライト値を表す HighlightField オブジェクトです。
- ステップ 3: 強調表示されたフィールド名に従って、強調表示されたフィールド値オブジェクト HighlightField をマップから取得する
- ステップ 4: HighlightField から Fragments を取得し、文字列に変換します。この部分が本当のハイライトされた文字列です
- ステップ 5: HotelDoc の強調表示されていない結果を強調表示された結果に置き換える
完全なコードは次のとおりです。
private void handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
// 获取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (!CollectionUtils.isEmpty(highlightFields)) {
// 根据字段名获取高亮结果
HighlightField highlightField = highlightFields.get("name");
if (highlightField != null) {
// 获取高亮值
String name = highlightField.getFragments()[0].string();
// 覆盖非高亮结果
hotelDoc.setName(name);
}
}
System.out.println("hotelDoc = " + hotelDoc);
}
}
注: CollectionUtils.isEmpty は、このパッケージのクエリ結果を使用します

。

4. ダークホース観光事件
以下では、ダーク ホース ツーリズムのケースを使用して、以前に学んだ知識を実践します。
次の 4 つの機能を実装します。
- ホテル検索とページネーション
- ホテルの結果フィルター
- 近くのホテル
- ホテル PPC
提供されている hotel-demo プロジェクトを開始します。デフォルトのポートは 8089 です。http://localhost:8090 にアクセスすると、プロジェクト ページが表示されます。
F12 でコンソールを開き、エラーが報告されていることを確認します。リスト リクエスト コードが完成していないためです。

4.1. ホテル検索とページネーション
ケースの要件: Heima Tourism のホテル検索機能を実現し、完全なキーワード検索とページネーションを実現する
4.1.1. 需要分析
プロジェクトのホームページには、大きな検索ボックスとページネーション ボタンがあります。
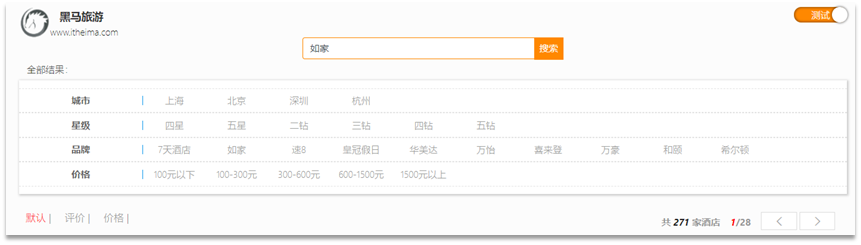
検索ボタンをクリックすると、ブラウザ コンソールがリクエストを行ったことがわかります。
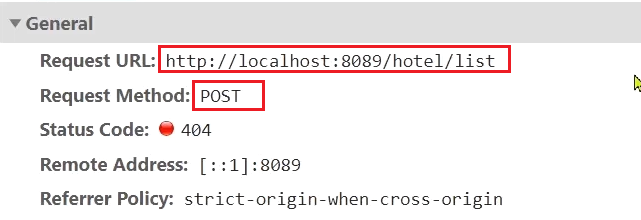
リクエストのパラメータは次のとおりです。

このことから、リクエストの情報は次のとおりであることがわかります。
- リクエスト方法:POST
- リクエストパス: /hotel/list
- リクエスト パラメータ: JSON オブジェクト、4 つのフィールドを含む:
- キー: 検索キーワード
- ページ: ページ番号
- size: 各ページのサイズ
- sortBy: ソート、現在実装されていません
- 戻り値: 2 つの属性を含むページネーション結果 PageResult を返す必要があるページネーション クエリ。
total:総数List<HotelDoc>:現在のページのデータ
したがって、当社のビジネスプロセスは次のとおりです。
- ステップ 1: エンティティ クラスを定義し、リクエスト パラメータの JSON オブジェクトを受け取る
- ステップ 2: ページ要求を受け取るコントローラーを作成する
- ステップ 3: ビジネス実装を作成し、RestHighLevelClient を使用して検索とページングを実現する
4.1.2. エンティティークラスの定義
2 つのエンティティ クラスがあり、1 つはフロントエンド リクエスト パラメータ エンティティで、もう 1 つはサーバーが返す応答結果エンティティです。
1) リクエスト パラメータ
フロントエンド リクエストの json 構造は次のとおりです。
{
"key": "搜索关键字",
"page": 1,
"size": 3,
"sortBy": "default"
}
したがって、cn.itcast.hotel.pojoパッケージの下にエンティティ クラスを定義します。
package cn.itcast.hotel.pojo;
import lombok.Data;
@Data
public class RequestParams {
private String key;
private Integer page;
private Integer size;
private String sortBy;
}
2) 戻り値
ページ化されたクエリは、次の 2 つの属性を含むページ化された結果 PageResult を返す必要があります。
total:総数List<HotelDoc>:現在のページのデータ
したがって、cn.itcast.hotel.pojo返される結果を次のように定義します。
package cn.itcast.hotel.pojo;
import lombok.Data;
import java.util.List;
@Data
public class PageResult {
private Long total;
private List<HotelDoc> hotels;
public PageResult() {
}
public PageResult(Long total, List<HotelDoc> hotels) {
this.total = total;
this.hotels = hotels;
}
}
4.1.3. コントローラーの定義
HotelController を定義し、クエリ インターフェイスを宣言して、次の要件を満たします。
- 依頼方法:郵送
- リクエストパス: /hotel/list
- リクエスト パラメータ: RequestParam タイプのオブジェクト
- 戻り値: 2 つの属性を含む PageResult
Long total:総数List<HotelDoc> hotels: ホテルデータ
したがって、次のようcn.itcast.hotel.webに HotelController を定義します。
@RestController
@RequestMapping("/hotel")
public class HotelController {
@Autowired
private IHotelService hotelService;
// 搜索酒店数据
@PostMapping("/list")
public PageResult search(@RequestBody RequestParams params){
return hotelService.search(params);
}
}
4.1.4. 検索サービスの実現
コントローラーで IHotelService を呼び出しましたが、このメソッドを実装していませんでした。そのため、IHotelService でメソッドを定義し、ビジネス ロジックを実装します。
1)cn.itcast.hotel.serviceのIHotelServiceインターフェースでメソッドを定義します。
/**
* 根据关键字搜索酒店信息
* @param params 请求参数对象,包含用户输入的关键字
* @return 酒店文档列表
*/
PageResult search(RequestParams params);
2) 検索業務を実現するためにRestHighLevelClientは不可分であり、SpringにBeanとして登録する必要があります。でこの Bean を宣言しますcn.itcast.hotel。HotelDemoApplication
@Bean
public RestHighLevelClient client(){
return new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));
}
3)検索メソッドを次のように実装しますcn.itcast.hotel.service.impl。HotelService
@Override
public PageResult search(RequestParams params) {
try {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
String key = params.getKey();
if (key == null || "".equals(key)) {
boolQuery.must(QueryBuilders.matchAllQuery());
} else {
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
// 2.2.分页
int page = params.getPage();
int size = params.getSize();
request.source().from((page - 1) * size).size(size);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
// 结果解析
private PageResult handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
List<HotelDoc> hotels = new ArrayList<>();
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
// 放入集合
hotels.add(hotelDoc);
}
// 4.4.封装返回
return new PageResult(total, hotels);
}
SpringBoot の再起動後に結果を表示する

4.2. ホテルの検索結果のフィルタリング
要件: ブランド、都市、星評価、価格などのフィルター機能を追加します。
4.2.1. 需要分析
ページ検索ボックスの下に、いくつかのフィルター項目があります。
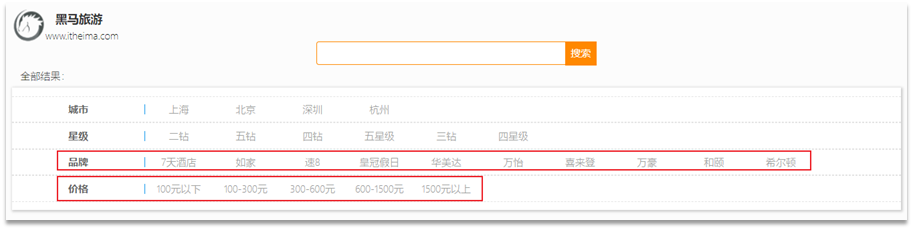
渡されたパラメーターは図に示されています。
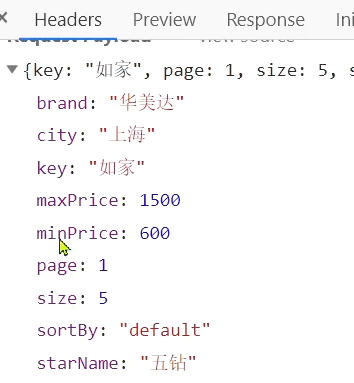
含まれるフィルター条件は次のとおりです。
- ブランド: ブランド価値
- 都市: 都市
- minPrice~maxPrice: 価格帯
- starName: 星
次の 2 つのことを行う必要があります。
- 上記のパラメータを受け取るように、リクエスト パラメータのオブジェクト RequestParams を変更します。
- ビジネス ロジックを変更し、検索条件に加えていくつかのフィルター条件を追加します。
4.2.2. エンティティークラスの変更
cn.itcast.hotel.pojoパッケージの下のエンティティ クラス RequestParamsを変更します。
@Data
public class RequestParams {
private String key;
private Integer page;
private Integer size;
private String sortBy;
// 下面是新增的过滤条件参数
private String city;
private String brand;
private String starName;
private Integer minPrice;
private Integer maxPrice;
}
4.2.3. 検索サービスの変更
HotelService の検索メソッドで、変更する必要があるのは 1 か所だけです。requet.source().query( ... ) のクエリ条件です。
これまでの業務はマッチクエリのみで、キーワードで検索していましたが、以下のような条件フィルタリングを追加する必要があります。
- ブランド フィルタリング: キーワード タイプ、用語によるクエリ
- スター フィルター: キーワード タイプ、用語クエリを使用
- 価格フィルタリング: 数値型で、範囲のあるクエリです
- 都市フィルター: キーワード タイプ、用語を使用したクエリ
複数のクエリ条件の組み合わせは、ブール クエリと組み合わせる必要があります。
- キーワード検索をマストに入れ、スコア計算に参加する
- 他のフィルター条件はフィルターに配置され、ポイントの計算には関与しません
条件付き構築のロジックはより複雑であるため、最初に関数としてカプセル化されます。
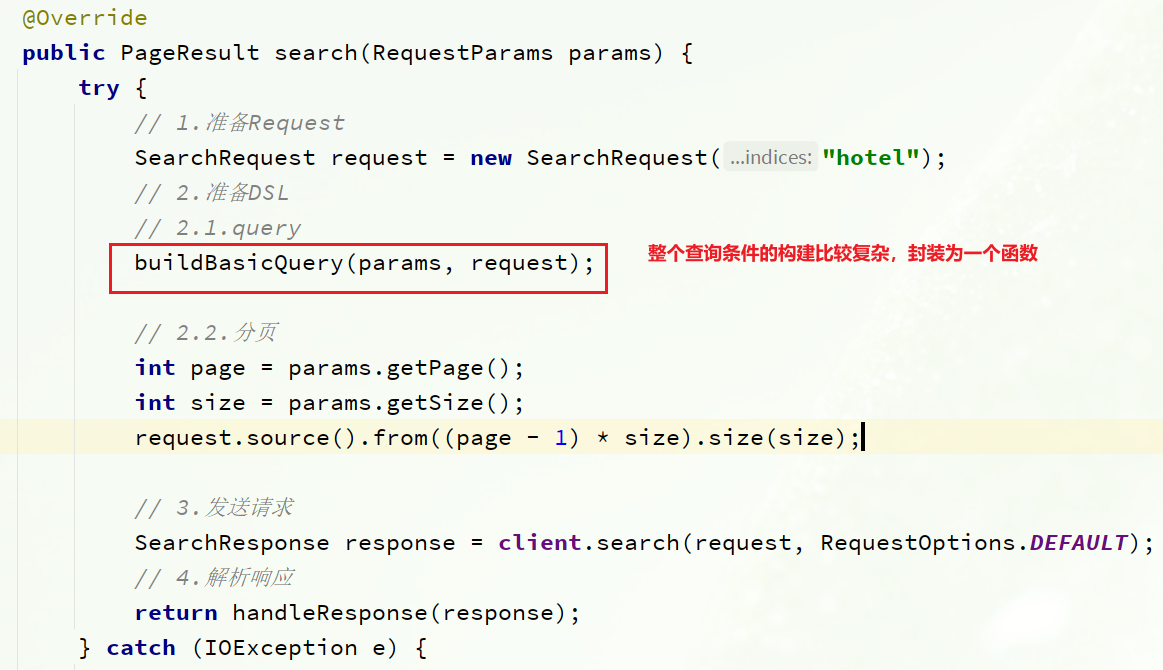
buildBasicQuery のコードは次のとおりです。
private void buildBasicQuery(RequestParams params, SearchRequest request) {
// 1.构建BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 2.关键字搜索
String key = params.getKey();
if (key == null || "".equals(key)) {
boolQuery.must(QueryBuilders.matchAllQuery());
} else {
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
// 3.城市条件
if (params.getCity() != null && !params.getCity().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));
}
// 4.品牌条件
if (params.getBrand() != null && !params.getBrand().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));
}
// 5.星级条件
if (params.getStarName() != null && !params.getStarName().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("starName", params.getStarName()));
}
// 6.价格
if (params.getMinPrice() != null && params.getMaxPrice() != null) {
boolQuery.filter(QueryBuilders
.rangeQuery("price")
.gte(params.getMinPrice())
.lte(params.getMaxPrice())
);
}
// 7.放入source
request.source().query(boolQuery);
}
検索結果:

4.3. 周辺のホテル
需要: 近くのホテル
4.3.1. 需要分析
ホテルリストページの右側に小さな地図があり、地図の場所ボタンをクリックすると、地図があなたの場所を見つけます:
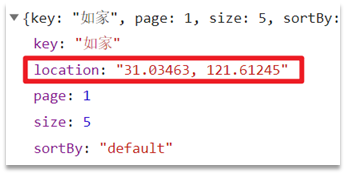
また、フロント エンドでクエリ リクエストが開始され、座標がサーバーに送信されます。
私たちがしなければならないことは、位置座標に基づいて距離に従って周辺のホテルをソートすることです。実装のアイデアは次のとおりです。
- Location フィールドを受け取るように RequestParams パラメータを変更します。
- 検索メソッドのビジネス ロジックを変更します。場所に値がある場合は、geo_distance に従って並べ替える機能を追加します
4.3.2. エンティティークラスの変更
cn.itcast.hotel.pojoパッケージの下のエンティティ クラス RequestParamsを変更します。
package cn.itcast.hotel.pojo;
import lombok.Data;
@Data
public class RequestParams {
private String key;
private Integer page;
private Integer size;
private String sortBy;
private String city;
private String brand;
private String starName;
private Integer minPrice;
private Integer maxPrice;
// 我当前的地理坐标
private String location;
}
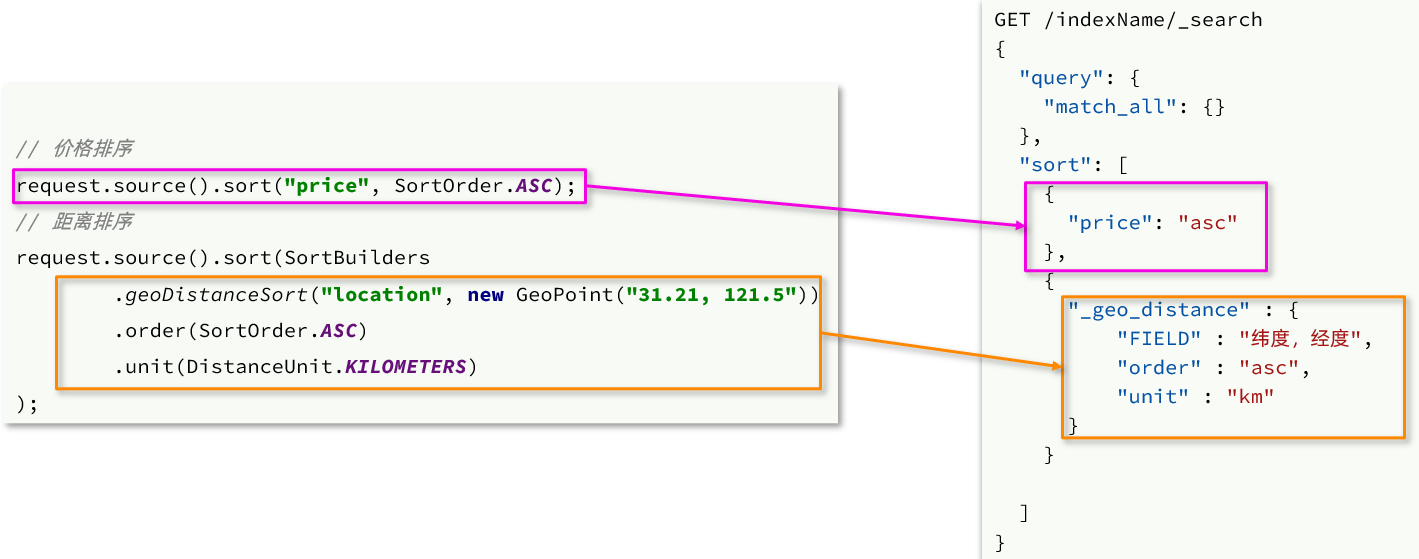
4.3.3. 距離ソート API
以前に、次の 2 つのタイプを含む並べ替え関数について学習しました。
- 通常のフィールドの並べ替え
- 地理座標で並べ替え
通常のフィールドソートに対応した Java の記述方法についてのみ説明しました。地理座標の並べ替えは、次のように DSL 構文のみを学習しています。
GET /indexName/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"price": "asc"
},
{
"_geo_distance" : {
"FIELD" : "纬度,经度",
"order" : "asc",
"unit" : "km"
}
}
]
}
対応する Java コードの例:
4.3.4. 距離ソートの追加
のメソッドでcn.itcast.hotel.service.impl、並べ替え関数を追加します。HotelServicesearch
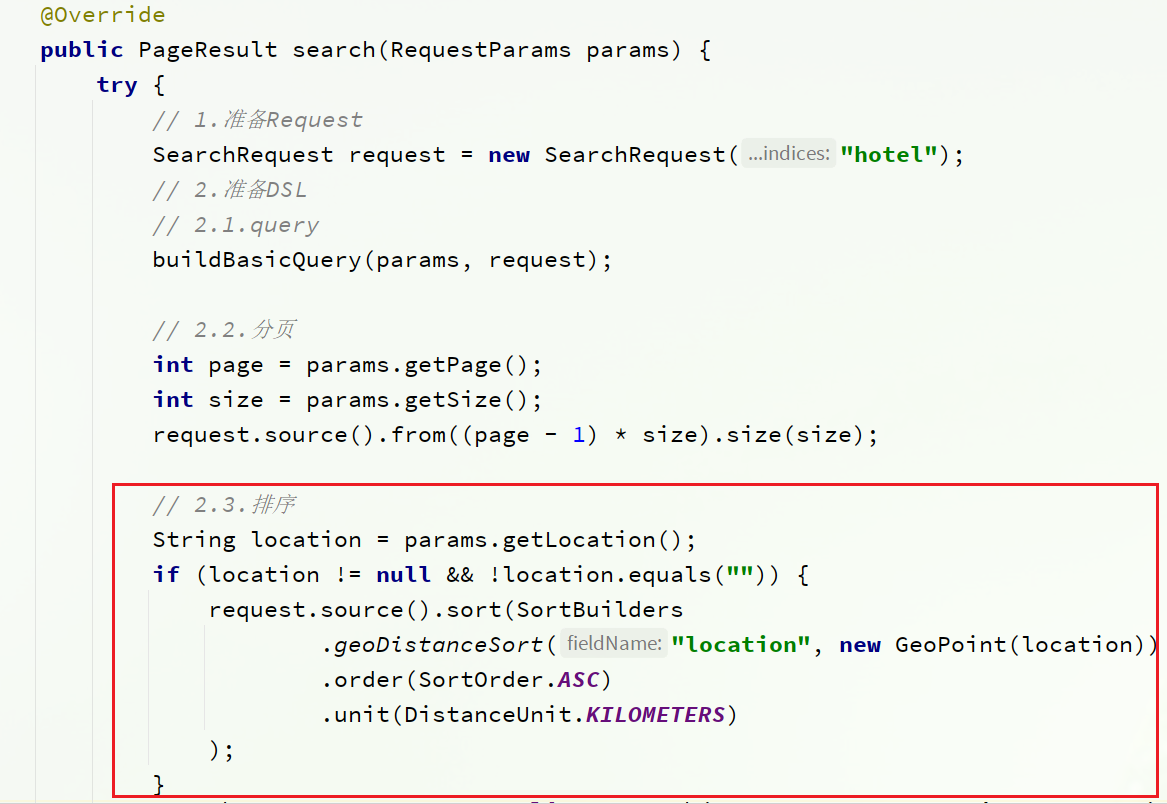
完全なコード:
@Override
public PageResult search(RequestParams params) {
try {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
buildBasicQuery(params, request);
// 2.2.分页
int page = params.getPage();
int size = params.getSize();
request.source().from((page - 1) * size).size(size);
// 2.3.排序
String location = params.getLocation();
if (location != null && !location.equals("")) {
request.source().sort(SortBuilders
.geoDistanceSort("location", new GeoPoint(location))
.order(SortOrder.ASC)
.unit(DistanceUnit.KILOMETERS)
);
}
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
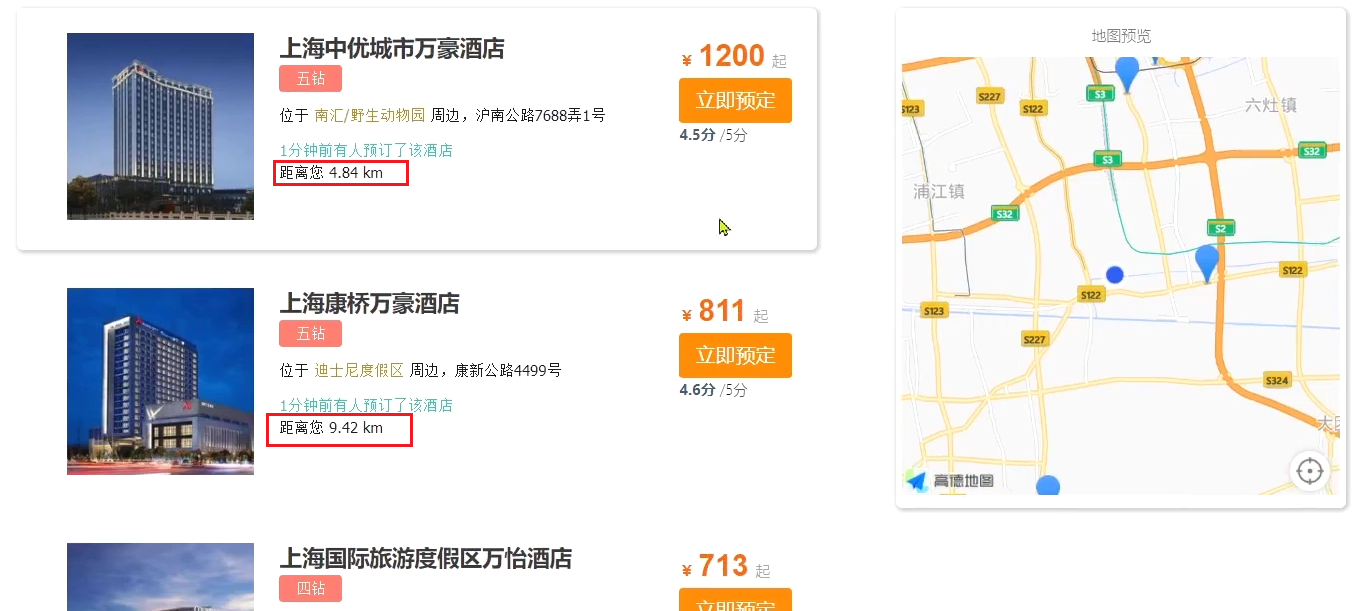
4.3.5. ソート距離表示
サービスを再開した後、ホテル機能をテストしました:
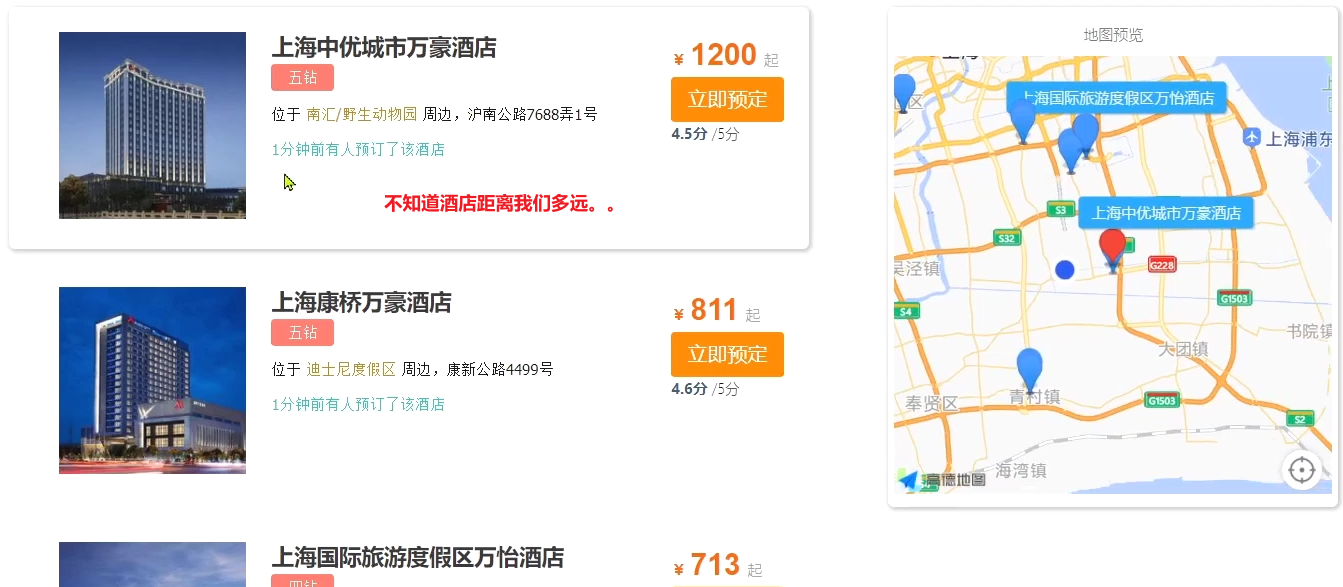
近くのホテルをソートすることは確かに可能であることがわかりましたが、ホテルが自分からどれくらい離れているかはわかりませんでした.どうすればよいですか?
並べ替えが完了した後、ページは近くの各ホテルの特定の距離値も取得する必要があります。これは、応答結果で独立しています。
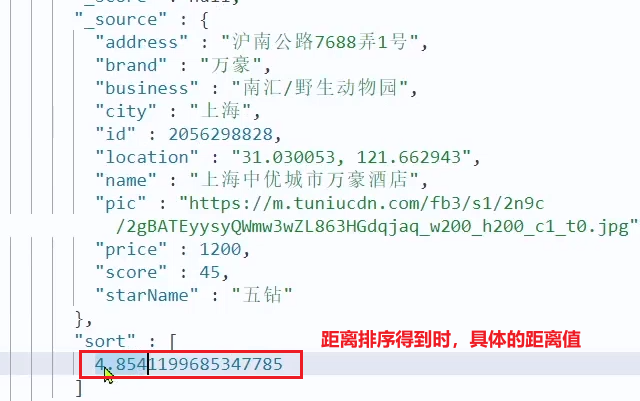
したがって、結果の解析段階では、ソース部分の解析に加えて、ソート部分を取得します。つまり、ソートされた距離が応答結果に入れられます。
次の 2 つのことを行います。
- HotelDoc を変更し、ページ表示用のソート距離フィールドを追加します
- HotelServiceクラスのhandleResponseメソッドを修正し、ソート値の取得を追加
1) HotelDoc クラスを変更し、距離フィールドを追加します。
package cn.itcast.hotel.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class HotelDoc {
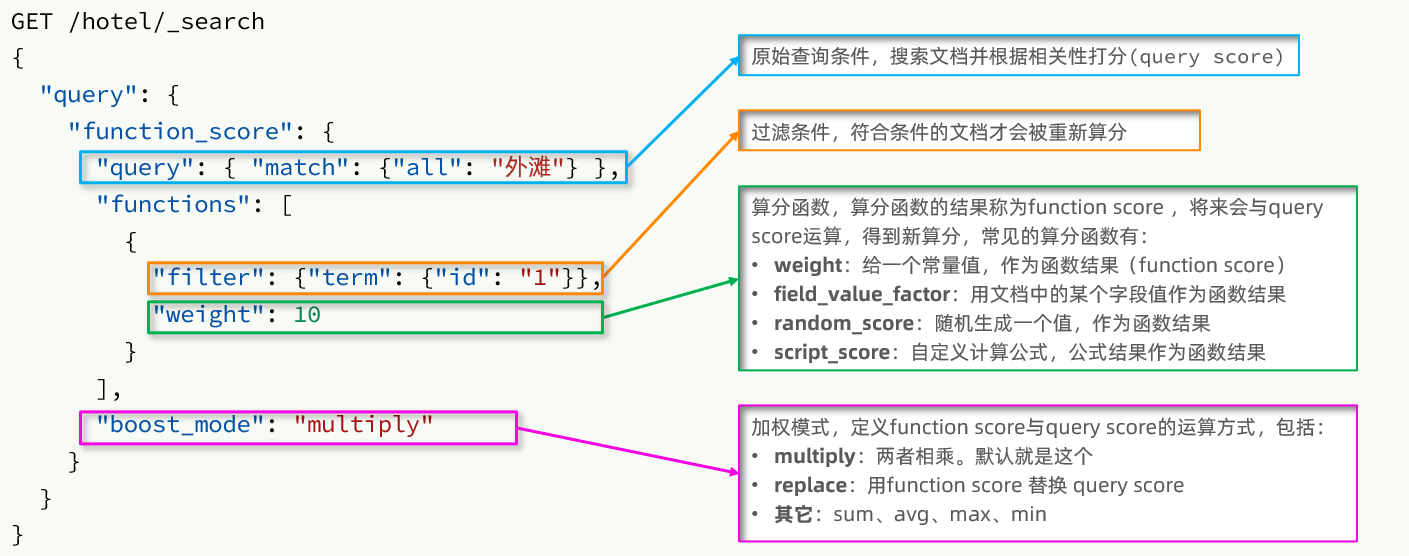
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
// 排序时的 距离值
private Object distance;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}
2) HotelService の handleResponse メソッドを変更する
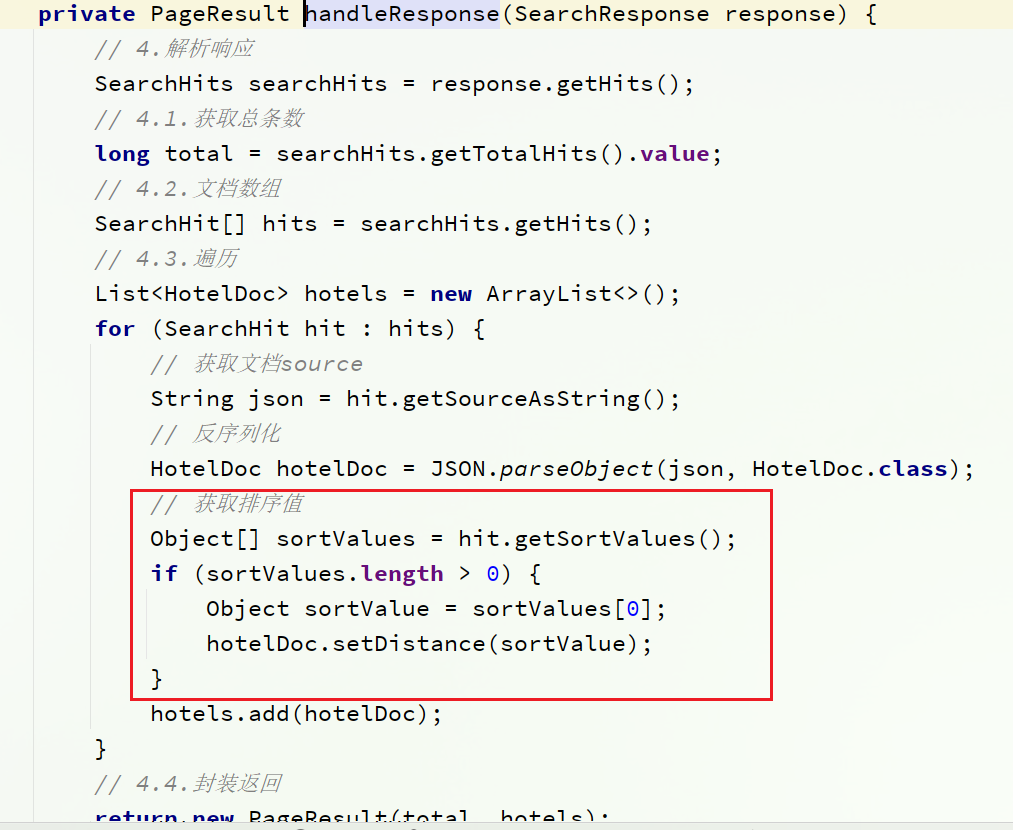
テストを再開した後、ページが距離を正常に表示できることがわかりました。
4.4. ホテル入札ランキング
条件: 指定したホテルが検索結果の上位に表示されるようにする
4.4.1. 需要分析
指定したホテルを検索結果の上位にランク付けする場合の効果は、次の図のようになります。
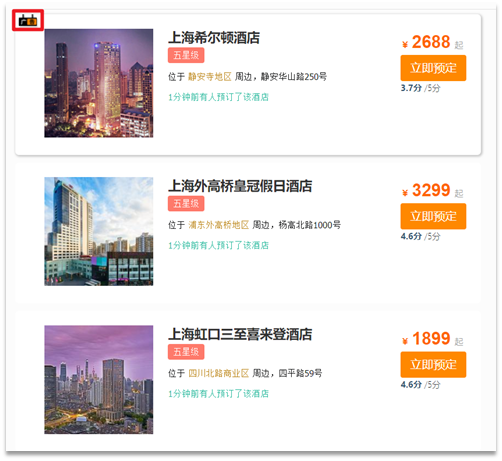
このページは、指定されたホテルに広告タグを追加します。
では、どうすれば指定ホテルランクをトップにできるのでしょうか。
前に学習した function_score クエリはスコアに影響を与える可能性があり、スコアが高いほど、自然なランキングが高くなります。function_score には 3 つの要素が含まれます。
- フィルター条件: どのドキュメントにポイントを追加するか
- 計算機能:機能スコアの計算方法
- 重み付け方法: 関数スコアとクエリ スコアの計算方法
ここで求められるのは、指定ホテルのランクを高くしたいということです。したがって、これらのホテルにマークを追加して、フィルター条件で、このマークに応じてスコアを上げるかどうかを判断できるようにする必要があります。
たとえば、フィールドをホテルに追加します: isAD、ブール型:
- true: 広告です
- false: 広告ではありません
このように、function_score には 3 つの要素が含まれており、簡単に判断できます。
- フィルター条件: isAD が true かどうかを判断する
- 計算機能: 最も単純な暴力的な重み、固定重み付け値を使用できます
- 重み付け方法: デフォルトの乗算方法を使用して、計算スコアを大幅に改善できます
したがって、ビジネスの実装手順には次のものが含まれます。
- isAD フィールドを HotelDoc クラスに追加、ブール型
- 好きなホテルをいくつか選び、そのドキュメント データに isAD フィールドを追加すると、値が true になります
- 検索方法を修正し、関数スコア関数を追加し、isAD 値が true であるホテルに重みを追加します
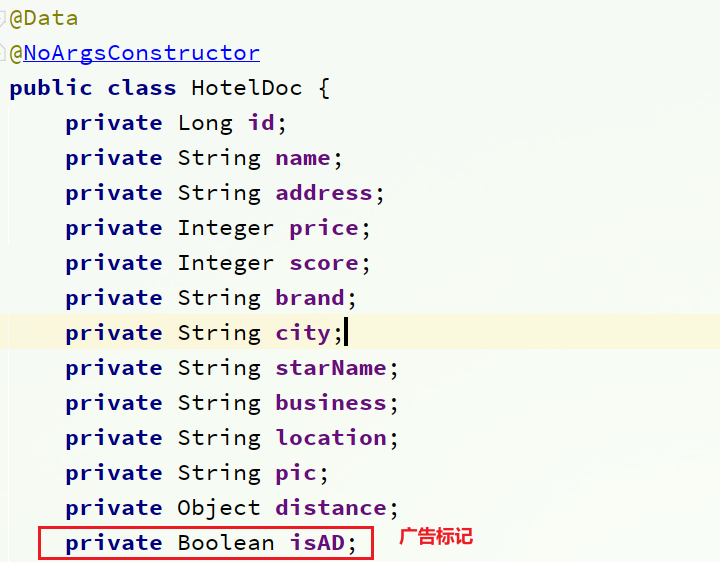
4.4.2. HotelDoc エンティティの変更
cn.itcast.hotel.pojoパッケージの下の HotelDoc クラスにisAD フィールドを追加します。
4.4.3. 広告マークの追加
次に、いくつかのホテルを選択し、isAD フィールドを追加して true に設定します。
# 增加广告
POST /hotel/_update/36934
{
"doc": {
"isAD" : true
}
}
POST /hotel/_update/38609
{
"doc": {
"isAD" : true
}
}
POST /hotel/_update/38665
{
"doc": {
"isAD" : true
}
}
POST /hotel/_update/47478
{
"doc": {
"isAD" : true
}
}
4.4.4. 計算関数クエリの追加
次に、クエリ条件を変更します。以前は boolean クエリが使用されていましたが、今は function_socre クエリに変更する必要があります。
function_score クエリ構造は次のとおりです。
対応する Java API は次のとおりです。以前に作成したブール クエリを元のクエリ条件としてクエリに
入れることができます。次のステップは、フィルター条件、スコアリング関数、重み付けモードを追加することです。したがって、元のコードは引き続き使用できます。
cn.itcast.hotel.service.implパッケージの下のHotelServiceクラスのメソッドを変更しbuildBasicQuery、計算関数クエリを追加します。
private void buildBasicQuery(RequestParams params, SearchRequest request) {
// 1.构建BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 关键字搜索
String key = params.getKey();
if (key == null || "".equals(key)) {
boolQuery.must(QueryBuilders.matchAllQuery());
} else {
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
// 城市条件
if (params.getCity() != null && !params.getCity().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));
}
// 品牌条件
if (params.getBrand() != null && !params.getBrand().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));
}
// 星级条件
if (params.getStarName() != null && !params.getStarName().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("starName", params.getStarName()));
}
// 价格
if (params.getMinPrice() != null && params.getMaxPrice() != null) {
boolQuery.filter(QueryBuilders
.rangeQuery("price")
.gte(params.getMinPrice())
.lte(params.getMaxPrice())
);
}
// 2.算分控制
FunctionScoreQueryBuilder functionScoreQuery =
QueryBuilders.functionScoreQuery(
// 原始查询,相关性算分的查询
boolQuery,
// function score的数组
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
// 其中的一个function score 元素
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
// 过滤条件
QueryBuilders.termQuery("isAD", true),
// 算分函数
ScoreFunctionBuilders.weightFactorFunction(10)
)
});
request.source().query(functionScoreQuery);
}
検索結果
