1. Contributions to this article
A fully convolutional masked autoencoder framework and a new Global Response Normalization (GRN) layer are proposed
1.1 Ideas
The idea of this article is to use MAE in ConvNeXt , but the design architecture of MAE is based on vision transformer, which is not compatible with standard ConvNets using dense sliding windows, so the author's suggestion is to jointly design the network architecture and masking automatically under the same framework. Encoder
1.1.1 Operation essentials
Treat the masked input as a set of sparse patches and use sparse convolutions to process only the visible parts. In practice, we can implement ConvNeXt with sparse convolutions, and when fine-tuning, the weights are converted back to standard dense layers without special handling.
When training ConvNeXt directly on masked inputs, we uncover a potential problem with feature collapse at MLP layers. To address this issue, we propose to add a global response normalization layer to enhance feature competition between channels
2. FCMA( Fully Convolutional Masked Autoencoder)

2.1 mask
2.1.1 Mask of MAE
Before officially entering the mask design of ConvNeXt V2, I think it is necessary to take a look at how the MAE mask is implemented.
(1) mask
def random_masking(self, x, mask_ratio):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D], sequence
"""
N, L, D = x.shape # batch, length, dim
len_keep = int(L * (1 - mask_ratio))#保留量
#拉一条同样长度的噪声,在大噪声处上掩码
noise = torch.rand(N, L, device=x.device)
# sort noise for each sample
ids_shuffle = torch.argsort(noise, dim=1) #升序排列
ids_restore = torch.argsort(ids_shuffle, dim=1)
ids_keep = ids_shuffle[:, :len_keep]
x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
#从原tensor中获取指定dim和指定index的数据
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([N, L], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return x_masked, mask, ids_restore
#x_masked:图像上掩码的仍然保留的数据
#mask:在原始图像中的掩码,0:保留,1:掩码
#ids_restore:noise从打乱ids_shuffle到恢复的序号
Referring to the following code, it is more intuitive to see that the two argsorts are actually obtaining the serial numbers of the noise and the original coordinates from small to large
import torch
len_keep=2#保留两个
x=torch.rand((1,4,1))#对应 N,L,D
print("x",x)
noise = torch.rand(1, 4)
print("noise",noise)
ids_shuffle = torch.argsort(noise, dim=1)#noise从小到大的序号
print("ids_shuffle",ids_shuffle)
ids_restore = torch.argsort(ids_shuffle, dim=1)#noise从打乱ids_shuffle到恢复的序号
print("ids_restore",ids_restore)
N, L, D = x.shape
# keep the first subset
ids_keep = ids_shuffle[:, :len_keep]
print("ids_keep",ids_keep)
x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
print("x_masked",x_masked)
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([N, L], device=x.device)
mask[:, :len_keep] = 0
print("mask",mask)
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
print("mask",mask)#在原始图像中的掩码位置(2) Use of masks
After patch_embed in the encoder
2.1.2 Mask of ConvNeXt V2
Since convolutional models have a layered design where features are downsampled at different stages, a mask is generated at the final stage and upsampled recursively until an optimal resolution is reached.
(1) mask
def gen_random_mask(self, x, mask_ratio):
N = x.shape[0]
L = (x.shape[2] // self.patch_size) ** 2
len_keep = int(L * (1 - mask_ratio))
noise = torch.randn(N, L, device=x.device)
# sort noise for each sample
ids_shuffle = torch.argsort(noise, dim=1)
ids_restore = torch.argsort(ids_shuffle, dim=1)
# generate the binary mask: 0 is keep 1 is remove
mask = torch.ones([N, L], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return maskbasically the same
(2) Use of mask: encoder encoder design
Two challenges:
- Prevents the model from learning shortcuts that allow it to copy and paste information from masked regions.
- Preserve 2D image structure
In MAE, the picture is stretched into strips (N, L, D), so using Mask is actually very handy, but in ConvNeXt V2 it is always a four-dimensional (N, C, H, W), that is, the 2d one is retained. image structure
Solution:
Incorporating sparse convolutions into the framework to facilitate pre-training of masked autoencoders
The specific code directly refers to SparseConvNeXtV2
class Block(nn.Module):
""" Sparse ConvNeXtV2 Block.
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_path=0., D=3):
super().__init__()
self.dwconv = MinkowskiDepthwiseConvolution(dim, kernel_size=7, bias=True, dimension=D)
self.norm = MinkowskiLayerNorm(dim, 1e-6)
self.pwconv1 = MinkowskiLinear(dim, 4 * dim)
self.act = MinkowskiGELU()
self.pwconv2 = MinkowskiLinear(4 * dim, dim)
self.grn = MinkowskiGRN(4 * dim)
self.drop_path = MinkowskiDropPath(drop_path)
def forward(self, x):
input = x
x = self.dwconv(x)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.grn(x)
x = self.pwconv2(x)
x = input + self.drop_path(x)
return x2.2 Decoder and loss function
Decoder: use a lightweight, normal ConvNeXt block as the decoder
Loss function: MSE reconstruction loss
3. Global response normalization
3.1 The reason for introducing global response normalization: the phenomenon of "feature collapse"
"Feature collapse" phenomenon: there are many stagnant or saturated feature maps, and activations become redundant across channels.
3.2 Global Response Normalization
In this work, we introduce a new response normalization layer called Global Response Normalization (GRN) , which aims to improve channel contrast and selectivity. The proposed GRN unit consists of three steps:
1) Global feature aggregation
The global function G( ) aggregates the spatial feature map into a vector gx. The experimental result is that the L2 norm works best
2) Feature normalization
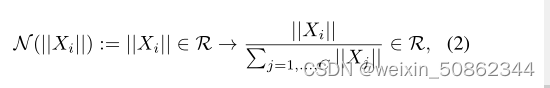
3) Feature Calibration
Use the computed feature normalization scores to calibrate the raw input responses
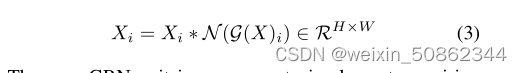

3.3 Implementation
Implementation without using sparse convolution:
class GRN(nn.Module):
""" GRN (Global Response Normalization) layer
"""
def __init__(self, dim):
super().__init__()
self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))
self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))
def forward(self, x):
Gx = torch.norm(x, p=2, dim=(1,2), keepdim=True)
Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)
return self.gamma * (x * Nx) + self.beta + x