5. Analysis of a treasure store (e-commerce model)
SQL180 The number of SPUs in a treasure store
select style_id,
count(item_id) as SPU_num
from product_tb
group by style_id
order by SPU_num desc
SQL181 Actual sales and customer unit price of a treasure store
select
sum(sales_price) as sales_total,
round(sum(sales_price)/count(distinct user_id),2) as per_trans
from sales_tb
SQL182 Discount rate of a treasure store
- In the title, sales_price is the settlement amount, don’t treat it as the sales amount of a single product like me, and multiply it by sales_num again)
select
round(sum(sales_price)/sum(tag_price*sales_num)*100,2) as discount_rate
from product_tb
join sales_tb using(item_id)
SQL183 Dynamic sales rate and sell-out rate of a treasure store
- This is the first time I wrote it, but the results are too small. The reason is: after the inventory table is connected with the sales table, the corresponding inventory record of each sku is not unique, inventory will have repeated calculations, and the direct calculation results are too small. For example, if there are two A003s in sales_tb, the inventory corresponding to the two A003s will be returned, so it needs to be deduplicated.
select style_id,
round(sum(sales_num)/(sum(inventory)-sum(sales_num))*100,2) as pin_rate,
round(sum(sales_price)/sum(tag_price*inventory)*100,2) as sell_through_rate
from product_tb
left join sales_tb using(item_id)
group by style_id
order by style_id
- The following is the correct way of writing. First, group by item_id to find the number of products sold under each item_id and GMV, and then group by style_id to find the dynamic sales rate and short-selling rate of products under each style_id
select style_id,
round(sum(num)/(sum(inventory)-sum(num))*100,2) as pin_rate,
round(sum(GMV)/sum(tag_price*inventory)*100,2) as sell_through_rate
from product_tb as a
join (
select item_id,
sum(sales_num) as num,
sum(sales_price) as GMV
from sales_tb
group by item_id
) as b
on a.item_id=b.item_id
group by style_id
order by style_id
- The correct answer can also be obtained by deduplicating the inventory. But when there are multiple products with the same inventory quantity in the product_tb table, the result will be wrong.
select style_id,
round(sum(sales_num)/(sum(distinct inventory)-sum(sales_num))*100,2),
round(sum(sales_price)/sum(distinct((tag_price*inventory)))*100,2)
from product_tb
join sales_tb using(item_id)
group by style_id
SQL184 Users who shop for 2 or more consecutive days in a treasure store and their corresponding days
-
This question is similar to the algorithm of question 167. The difficulty lies in calculating the number of consecutive days.
-
Problem-solving idea: first sort the dates, then judge the consecutive dates, and query the users with the number of consecutive days >= 2
-
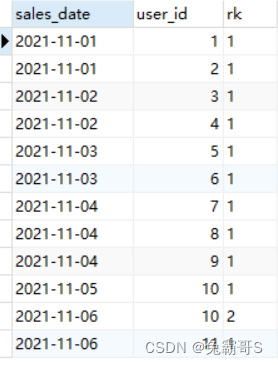
The method of judging consecutive dates:
the first step is to sort the dates after deduplication (or directly use dense_rank to sort, because the dense_rank is the same for repeated dates, if it is the same day, so don’t think about it again The effect of repeated dates);
in the second step, if the date minus the number of days corresponding to the sorting number is the same value, it means that these dates are continuous.
The third step is to sort the consecutive dates again to get the largest continuous sequence.
-
The method of judging consecutive dates and querying and counting users with consecutive days >= 2:
use the date_sub() function and aggregate to judge that the dates are continuous
If sales_date minus rk (days) is the same date, it means that they are all consecutive days Date (so use dense_rank() and deduplicate the date, otherwise the repeated date will be counted as consecutive days).
-
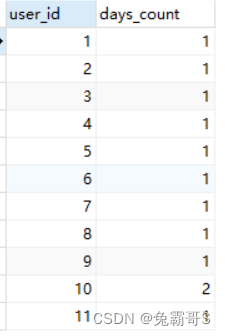
There is no difference between count(1) and count( ), because neither count( ) nor count(1) will filter out null values. But count(1) is more efficient than count(*)
select user_id,
count(1) as days_count
from (
select distinct sales_date,
user_id,
dense_rank()over(partition by user_id order by sales_date)rk
FROM sales_tb
)t1
group by user_id,
date_sub(sales_date,interval rk day)
HAVING count(1)>=2;