01 クロスバリデーション
データをトレーニング セットとテスト セットに分割し、トレーニング セットを使用してモデルを構築し、テスト セットを使用してモデルを評価して変更を提案することは、クロス検証と呼ばれます。
02 分類問題 - 混同行列
例としてのバイナリ分類の混同行列
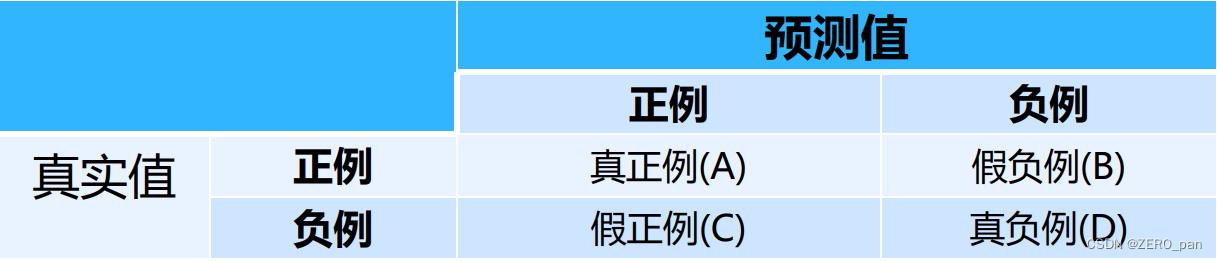
正確さ
予測はすべてのデータよりも正確です。
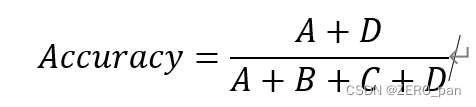
再現率
予測ペアのポジティブ サンプルの数は、上位サンプルのポジティブ サンプルの数よりも多くなっています。
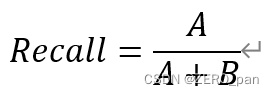
意義:ポジティブな例をできるだけ見つける
正確さ
予測されたペアの陽性サンプルの数と、予測されたすべての陽性サンプルの数の比率
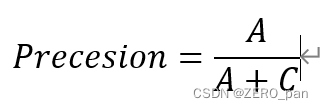
意味: 予測が陽性である場合の精度。
F値
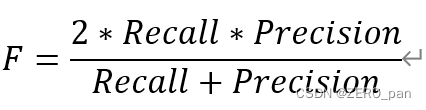
まとめQ&A
Q: モデルの正解率は 90% ですが、このモデルのパフォーマンスは必ずしも優れているのでしょうか?
- 不確実
- 特定の病気の確率が 10% であると仮定すると、すべてのサンプルが病気にかかっていないと予測され、モデルの精度は 90% に達する可能性があります。でもこのモデルはダメ
- このとき、再現率と正解率を考慮する必要があります。陽性例は病気であると仮定します。A=0 であるため、そのようなモデルの再現率と適合率は 0 に等しくなります。
- したがって、正解率だけではモデルのパフォーマンスを判断するのに十分ではありません。特に遭遇したデータの不均衡いつ。
Q: 再現率と適合率の関係は?
- 病気の人を特定するときは、できるだけ病気の人を見つけるようにしてください。現時点では、再現率をできるだけ高くしたいと考えています。
- 100% のリコール率を達成するための 1 つの方法は、すべてのケースを病気であると予測することです。放っておくよりは誤殺したほうがいいのですが、この機種は性能がいいと思いますか?
- そのため、命中率も考慮して、できるだけ誤射を少なくする必要があります。
- 適合率と再現率は相反する指標ではなく、強調する点が異なります。
Q: 正解率を優先し、再現率を考慮するのはどのようなシナリオですか?
- シナリオ:真の正例を見つけて加点し、非正例を正例と判断して減点する。
ROC曲線
FPR と TPR の 2 つの量の間の相対的な変化。
TPR真陽性率:再現率、1に近いほど良好
FPR偽陽性率:C/(C+D)、
ROC では、いくつかの特別なポイントの意味
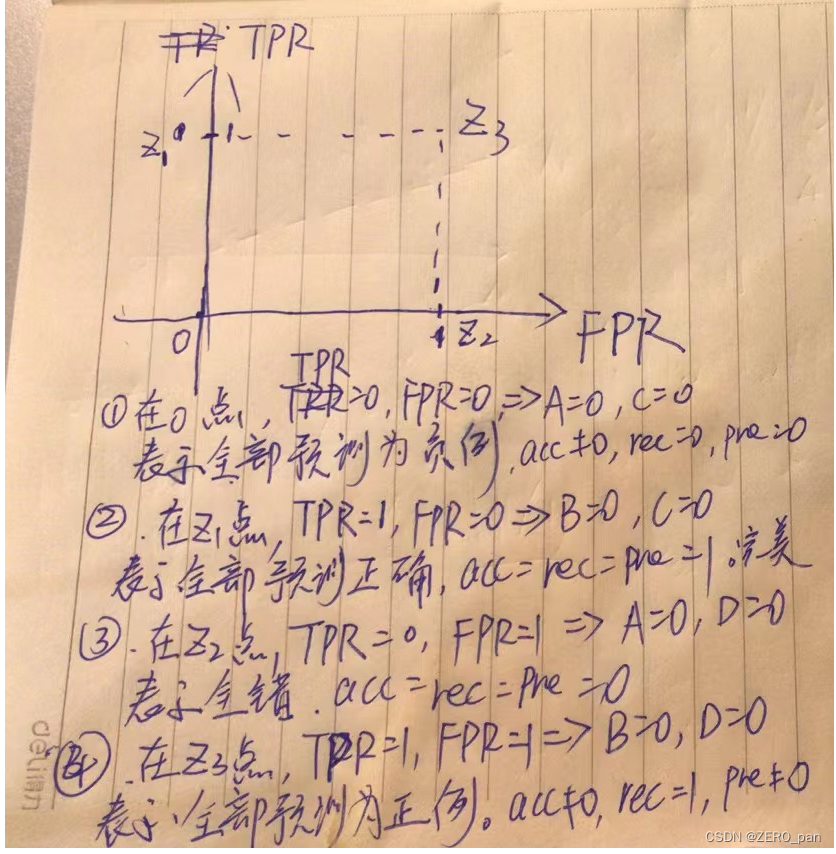
モデルが z1 に近いほど良い。
ROC 曲線は、モデルの TPR と FPR です。判定閾値曲線の変化。
AUC
通常、ROC 曲線の下の右下隅の領域を使用して評価します.領域の値の範囲が 0-1
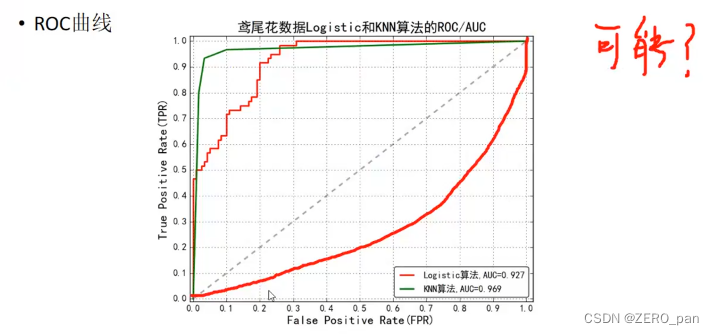
ではなく 0.5-1 である理由は? 二項分類問題の場合、正解率が 0 のモデルがは 1 の正解率です。モデル。
下の図は、面積 AUC (Area under couver) が 1、つまり点 z1 であることを示しています。
scikit-learn コード
| 索引 | scikit 学習 |
|---|---|
| 精度 | sklearn.metricsからprecision_scoreをインポート |
| 想起 | sklearn.metricsインポートrecall_scoreから |
| F1 | sklearn.metrics インポート f1_score から |
| 混同行列 | sklearn.metricsインポートから混乱_マトリックス |
| ROC | sklearn.metricsインポートroc_curveから |
| AUC | sklearn.metrics インポート auc から |
03 回帰問題
回帰問題では、誤差をできるだけ小さくする必要があります。ただし、エラーを直接追加することはできません。正負の誤差があるから、通常は誤差の絶対値または二乗を取ります。
平均絶対誤差
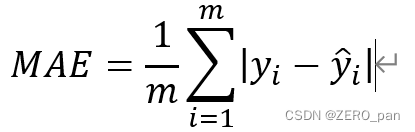
値の範囲: 0 ~正の無限大
平均二乗誤差
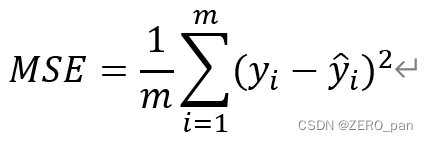
値の範囲: 0 ~正の無限大
R2
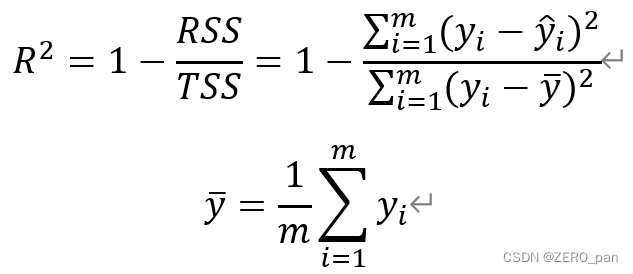
TSS は、すべてが平均を予測するモデルの mse です (1/m はオプションです)。R2 が意味することは、モデルが少なくとも単純なモデル (すべての予測が平均であるモデル) よりも優れている必要があるということです。
R2 値の範囲 (負の無限大 ~ 1)
いくつかの特別なポイントを以下に説明します
- R2=0、モデルのパフォーマンス (RSS) は、平均のみを予測するモデル (TSS) と同等です
- R2=1 の場合、モデルは完全に予測します。1に近いほど良い。
- R2<0、あなたのモデルは非常に貧弱で、平均を予測するモデルほど良くありません。
- R2=負の無限大。モデルが振動しており、収束していない可能性があります。
scikit-learn コード
| 索引 | scikit 学習 |
|---|---|
| MSE,RMSE | sklearn.metrics インポート mean_squared_error から |
| 前 | sklearn.metrics インポート mean_absolute_error から |
| R2 | sklearn.metrics インポート r2_score から |