八、木
これは主に、バイナリ ツリーのフロント、ミドル、バック、レイヤ順のトラバーサルの適用です
(これら 4 つのトラバーサルの詳細については、バイナリ ツリーの)。
8.1 二分木の最も近い共通の祖先
バイナリ ツリーが与えられた場合、ツリー内の指定された 2 つのノードの最も近い共通の祖先を見つけます。
たとえば、次の二分木があるとします: root = [3,5,1,6,2,0,8,null,null,7,4]
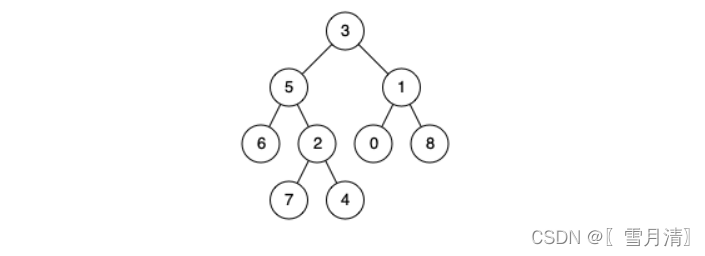
例 1:
- 入力: ルート = [3,5,1,6,2,0,8,null,null,7,4]、p = 5、q = 1
- 出力: 3
- 説明: ノード 5 とノード 1 の最も近い共通の祖先はノード 3 です。
説明します:
- すべてのノード値は一意です。
- p と q は異なるノードであり、どちらも指定されたバイナリ ツリーに存在します。
アイデア: 3 つの状況があります
-
p と q は左右のサブツリーに分散され、最も近い共通の祖先はルートです
-
p と q は同じ側に分布し、最も近い共通の祖先は空でない側 (左または右) です。
-
p と q の少なくとも 1 つがルートであるか、ルートが null であり、最も近い共通の祖先がルートである
注意点:左右のサブツリーを再帰的にルート化し、状況に応じて対応する共通の祖先ノードを返す
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root == null || p == root || q == root){
return root;
}
//查左子树
TreeNode l = lowestCommonAncestor(root.left,p,q);
// 查右子树
TreeNode r = lowestCommonAncestor(root.right,p,q);
//公共祖先在右子树
if(l == null){
return r;
}
else if(r == null){
// 在左子树
return l;
}else{
// 左右都不为空
return root;
}
}
}
8.2 ルートノードからリーフノードへのパス数の合計
バイナリ ツリーのルート ノード ルートを指定すると、ツリーの各ノードには 0 ~ 9 の数値が格納されます。
ルート ノードからリーフ ノードへの各パスは、番号を表します。
- たとえば、ルート ノードからリーフ ノードへのパス 1 -> 2 -> 3 は、123 という数字を表します。
ルート ノードからリーフ ノードまで生成されたすべての数値の合計を計算します。
リーフ ノードは、子ノードを持たないノードです。
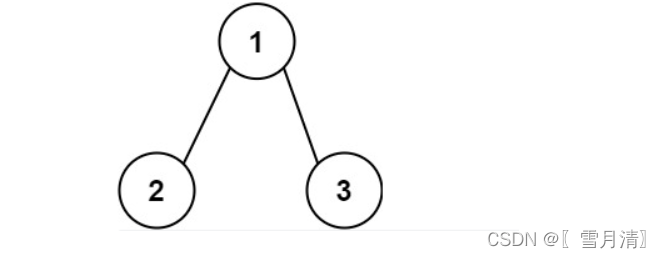
例 1:
入力:ルート = [1,2,3]
出力: 25
説明:
- ルートからリーフ ノード 1->2 へのパスは、数値 12 を表します。
- ルートからリーフ ノード 1->3 へのパスは、13 という数字を表します。
- 数字の合計 = 12 + 13 = 25
アイデア:一次再帰トラバーサル、リーフ ノードに遭遇したかどうかをカウントする
注:リーフ ノードは合計演算のみを実行します
class Solution {
int num = 0;
public int sumNumbers(TreeNode root) {
sum(root,0);
return num;
}
void sum(TreeNode root, int val){
if(root == null){
return;
}
val= val*10 + root.val;
if(root.left == null && root.right == null){
num += val;
}
sum(root.left,val);
sum(root.right,val);
}
}
8.3 二分木の枝刈り
バイナリ ツリーのルート ノード ルートが与えられると、ツリーの各ノードの値は 0 または 1 になります。二分木のすべてのノードで値が 0 であるサブツリーを切り捨ててください。
ノード node のサブツリーは、ノード自体とノードのすべての子孫です。
例 1:
-
入力: [1,null,0,0,1]
-
出力: [1,null,0,null,1]
-
説明:
赤のノードのみが「1 を含まないすべてのサブツリー」という条件を満たします。
右の図は、返された回答を示しています。
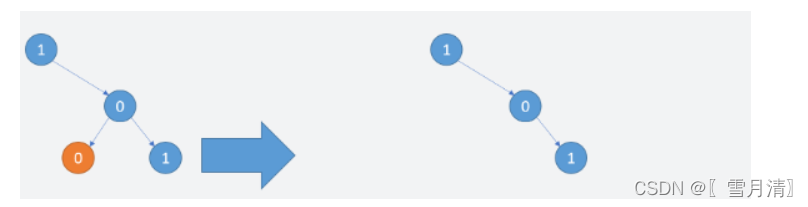
アイデア:各ノードを再帰的にトラバースし、ノードの値が 0 の場合は true を返し、true を返すすべてのノードに NULL を設定します。
注:再帰関数によって返されたステータス値を使用して、プルーニングを実行するかどうかを決定します。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode pruneTree(TreeNode root) {
if(dfs(root)) root = null;
return root;
}
boolean dfs(TreeNode root){
if(root == null) return false;
if(dfs(root.left)){
root.left = null;
}
if(dfs(root.right)){
root.right = null;
}
if(root.left == null && root.right == null && root.val == 0){
return true;
}
return false;
}
}
8.4 二分木のシリアライズとデシリアライズ
シリアライゼーションは、データ構造またはオブジェクトを連続したビットに変換する操作であり、変換されたデータはファイルまたはメモリに保存でき、ネットワークを介して別のコンピューター環境に送信し、逆の方法で再構築することもできます。元データ。
二分木のシリアライズとデシリアライズを実現するアルゴリズムを設計してください。これにより、シリアライゼーション/デシリアライゼーション アルゴリズムの実行ロジックが制限されることはありません。必要なのは、バイナリ ツリーを文字列にシリアライズし、文字列を元のツリー構造にデシリアライズできることだけです。
例 1:
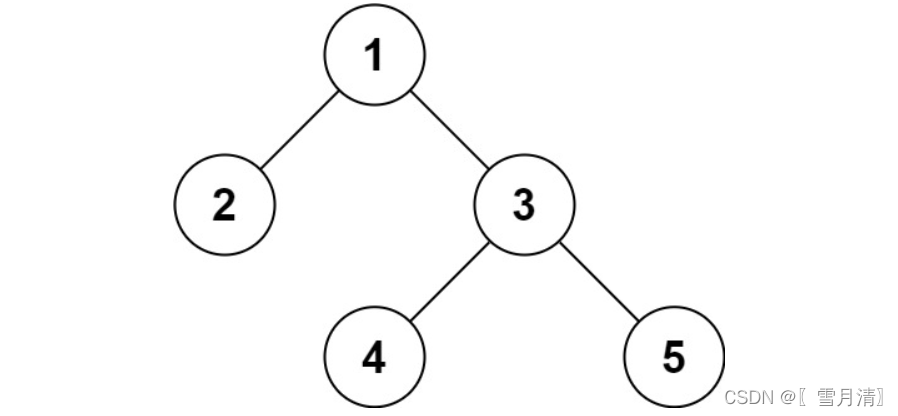
- 入力: ルート = [1,2,3,null,null,4,5]
- 出力: [1,2,3,null,null,4,5]
ヒント:
- ツリーのノード数は範囲
[0, 10^4]内 -1000 <= Node.val <= 1000
アイデア:バイナリ ツリーを前の順序でトラバースし、バイナリ ツリーの各ノードの値を文字列に連結し、# を使用して空のツリーを表す
注:デシリアライズするときは、,文字列を分割して配列に変換します。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Codec {
// Encodes a tree to a single string.
public String serialize(TreeNode root) {
return rserialize(root,"");
}
// 1,2,#,#,3,4,#,#,5,#,#,
public String rserialize(TreeNode root,String str){
// 空子树使用 #代替
if(root == null){
str += "#,";
}else{
str += String.valueOf(root.val) + ",";
str = rserialize(root.left,str);
str = rserialize(root.right,str);
}
return str;
}
// Decodes your encoded data to tree.
public TreeNode deserialize(String data) {
// 以逗号进行分割
String[] split = data.split(",");
List<String> list = new LinkedList<String>( Arrays.asList(split));
return rdeserialize(list);
}
public TreeNode rdeserialize(List<String> list) {
// 空树
if(list.get(0).equals("#")){
list.remove(0);
return null;
}
// 反序列化
TreeNode root = new TreeNode(Integer.valueOf(list.get(0)));
list.remove(0);
root.left = rdeserialize(list);
root.right = rdeserialize(list);
return root;
}
}
8.5 下りパスノード合計
バイナリ ツリーのルート ノードroot と整数 が与えられた場合 targetSum、ノード値の合計が にtargetSum等しい。
パスはルート ノードから開始する必要はなく、リーフ ノードで終了する必要もありませんが、パスの方向は下向きにする必要があります (親ノードから子ノードへのみ)。
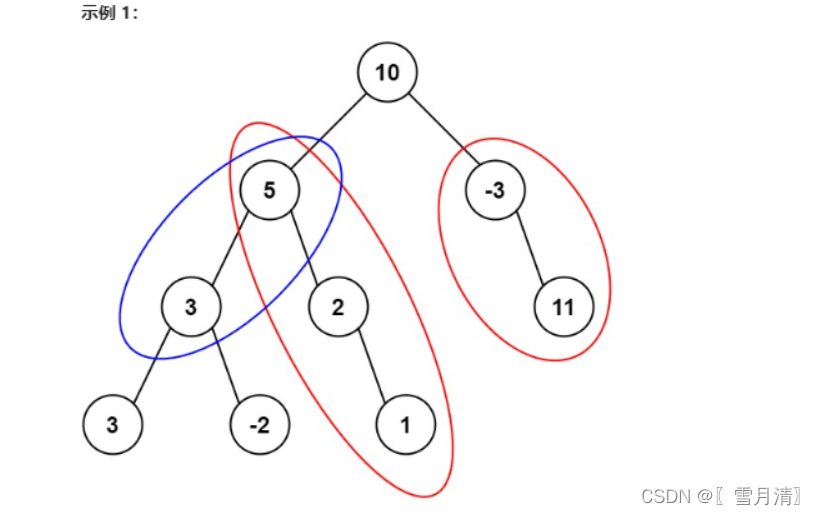
-
キー: ルート = [10,5,-3,3,2,null,11,3,-2,null,1]、targetSum = 8
-
出力: 3
-
説明: 図に示すように、合計が 8 に等しい 3 つのパスがあります。
ヒント:
- 二分木のノード数の範囲は
[0,1000] -10^9 <= Node.val <= 10^9-1000 <= targetSum <= 1000
解決策 1:
アイデア:各ノードを再帰的にトラバースし、targetその都度現在のノード値と比較する. それらが等しい場合は、パスが見つかったことを意味する. そうでない場合は、target現在のノード値を使用して、左右のサブツリーをトラバースし続ける.
注意点:オーバーフローの状況を考慮し、長い統計を使用して、
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
int sum = 0;
public int pathSum(TreeNode root, int targetSum) {
if(root == null) return 0;
dfs(root,targetSum);
pathSum(root.left,targetSum);
pathSum(root.right,targetSum);
return sum;
}
void dfs(TreeNode node, long target){
if(node == null ) return;
if(node.val == target) sum++;
dfs(node.left,target - node.val);
dfs(node.right,target - node.val);
}
}
解決策 2: プレフィックスサム
アイデア:マップを使用して、接頭辞と -> の出現回数を記録し、ノードを横断し、通過したパスと - がマップ内にあるかどうかを確認します。このような値が複数ある場合は、修飾されたパスが複数あることを意味しますtargetSum。
注:他のサブツリーをトラバースする場合、別のパスをトラバースする前にマップに記録された値を削除する必要があります。
class Solution {
public int pathSum(TreeNode root, int targetSum) {
Map<Long,Integer> map = new HashMap<>();
map.put(0l,1);
return dfs(root,map,0l,targetSum);
}
private int dfs(TreeNode root, Map<Long, Integer> map, long cur, int targetSum) {
if(root == null) return 0;
int res = 0;
cur += root.val;
res = map.getOrDefault(cur - targetSum,0);
map.put(cur,map.getOrDefault(cur,0)+1);
res += dfs(root.left,map,cur,targetSum);
res += dfs(root.right,map,cur,targetSum);
// 回溯
map.put(cur,map.getOrDefault(cur,0) -1);
return res;
}
}
8.6 ノードの合計が最大になるパス
パスは、ツリー内の任意のノードから始まり、親ノードと子ノードの接続をたどり、任意のノードに到達するシーケンスとして定義されます。同じノードは、パス シーケンス内で最大。パスには少なくとも1 つのノードが含まれており、必ずしもルート ノードを通過する必要はありません。
パスの合計は、パス内の各ノードの値の合計です。
バイナリ ツリーのルート ノード ルートを指定すると、その最大パス合計、つまりすべてのパスのノード値の合計の最大値を返します。
例 1:
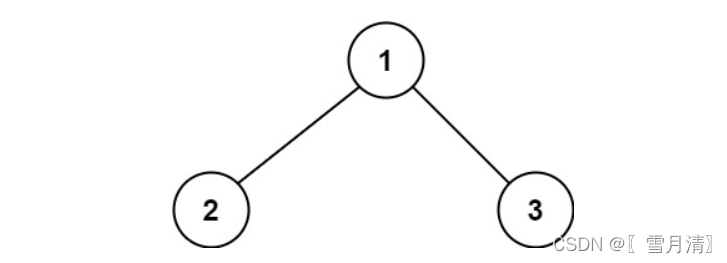
- 入力: ルート = [1,2,3]
- 出力: 6
- 説明: 最適なパスは 2 -> 1 -> 3 であり、パスの合計は 2 + 1 + 3 = 6 です。
ヒント:
- ツリー内のノード数は、
[1, 3 * 10^4] -1000 <= Node.val <= 1000
アイデア: 現在のノードが null の場合は 0 を返し、null でない場合は、現在のノードの左側のサブツリーの最大パス合計 + 右側のサブツリーの最大パス合計 + 現在のノード値を記録し、 とsum比較して ノードごとに、ノードの左右のサブツリーの 2 つのパスの最大値 + ノードの値がノードの貢献値を表します
注: 左サブツリーと右サブツリーの最大値を見つけるときは、それが 0 より大きい場合にのみパスに追加できることに注意してください。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
int sum = Integer.MIN_VALUE;
public int maxPathSum(TreeNode root) {
dfs(root);
return sum;
}
int dfs(TreeNode root){
if(root == null) return 0;
int left = Math.max(dfs(root.left),0);
int right = Math.max(dfs(root.right),0);
sum = Math.max(sum,left + right + root.val);
// 返回当前节点左右两条路径的最大值
return Math.max(left,right) + root.val;
}
}
8.7 二分探索木の平坦化
二分探索木が与えられた場合、ツリーの左端のノードがツリーのルート ノードになり、各ノードには左の子ノードがなく、右の子ノードが 1 つだけあるように、順序通りに走査して昇順の検索ツリーに再配置してください。
例 1:
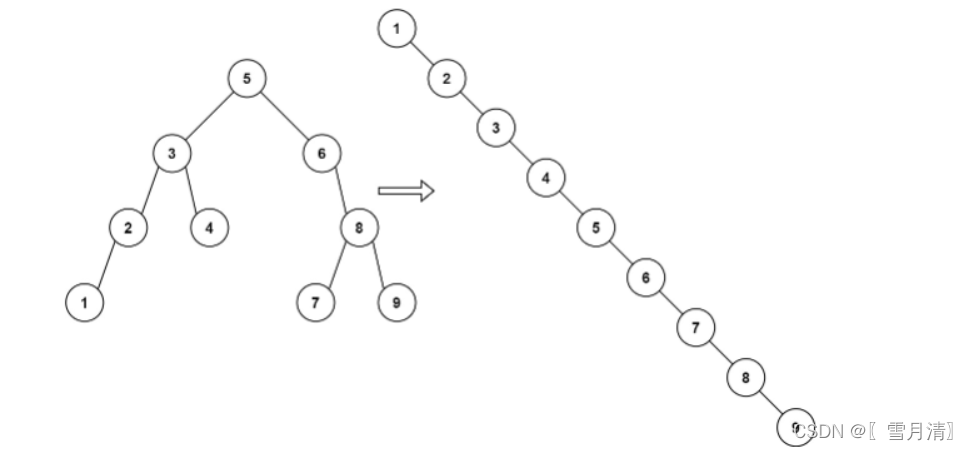
输入:root = [5,3,6,2,4,null,8,1,null,null,null,7,9]
输出:[1,null,2,null,3,null,4,null, 5,ヌル,6,ヌル,7,ヌル,8,ヌル,9]
ヒント:
- ツリーのノード数の値の範囲は次のとおりです。
[1, 100] 0 <= Node.val <= 1000
アイデア:順序通りのトラバーサル、リスト コレクションを使用して順序通りのトラバーサルの結果を記録し、ツリーを再構築する
注:再構築時にノードを再作成する必要があります
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
List<Integer>list = new ArrayList();
public TreeNode increasingBST(TreeNode root) {
if(root == null) return null;
dfs(root);
TreeNode head = new TreeNode(-1);
TreeNode p = head;
for(int val : list){
TreeNode temp = new TreeNode(val);
p.right = temp;
p = temp;
}
return head.right;
}
void dfs(TreeNode node){
if(node == null ) return;
dfs(node.left);
list.add(node.val);
dfs(node.right);
}
}
8.8 二分探索木のインオーダーサクセサ
二分探索木とその中のノード p が与えられた場合、木でノードの順不同の後継者を見つけます。ノードにインオーダー サクセサがない場合は null を返します。
ノード p の後続ノードは、値が p.val よりも大きいノードの中で最小のキー値を持つノード、つまり、順序通りのトラバーサルの順序でノード p の次のノードです。
例 1:
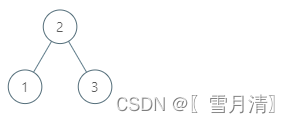
-
入力: ルート = [2,1,3]、p = 1
-
出力: 2
-
説明: ここでの 1 のインオーダー サクセサは 2 です。p と戻り値の両方が TreeNode 型である必要があることに注意してください。
ヒント:
- ツリー内のノード数は範囲
[1, 10^4]内。 -10^5 <= Node.val <= 10^5- ツリー内の各ノードの値は、一意であることが保証されています。
アイデア:二分探索木の特性を利用する
注:現在のノード > p.val は、このノードを記録する必要があります
class Solution {
public TreeNode inorderSuccessor(TreeNode root, TreeNode p) {
if(root == null) return null;
TreeNode node = null;
while( root != null){
if(root.val > p.val){
// 记录后一个
node = root;
root = root.left;
}else{
root = root.right;
}
}
return node;
}
}
8.9 ノード以上のすべての値の合計
二分探索木が与えられた場合、各ノードの値を、ツリー内のノード値以上のすべてのノード値の合計に置き換えます。
念のため、二分探索木は次の制約を満たします。
-
ノードの左サブツリーには、キーがノードのキーより小さいノードのみが含まれます。
-
ノードの右側のサブツリーには、ノードのキーより大きいキーを持つノードのみが含まれます。
-
左右の部分木も二分探索木でなければなりません。
ヒント:
- ツリーのノード数は
0~ です10^4。 - 各ノードには、
-10^4~ の10^4。 - ツリー内のすべての値は互いに異なります。
- 与えられた木は二分探索木です。
例 1:
-
输入:root = [4,1,6,0,2,5,7,null,null,null,3,null,null,null,8]
-
输出:[30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
アイデア:逆順トラバーサル
class Solution {
int sum = 0;
public TreeNode convertBST(TreeNode root) {
if(root == null) return root;
convertBST(root.right);
root.val+=sum;
sum = root.val;
convertBST(root.left);
return root;
}
}
8.10 二分探索木反復子
二分探索木 (BST) を順番にトラバースする反復子を表す二分探索木反復子クラスを実装しますBSTIterator。
-
BSTIterator(TreeNode root)BSTIerator クラスのオブジェクトを初期化します。BST のルート ノードは、コンストラクターの一部として指定されます。ポインタは、BST に存在せず、BST のどの要素よりも小さい数値に初期化されます。 -
boolean hasNext()ポインターの右側に数字がある場合は true を返し、そうでない場合は false を返します。 -
int next()ポインターを右に移動し、ポインターの位置の数値を返します。
ポインタは BST に存在しない数値に初期化されるため、next() の最初の呼び出しは BST の最小要素を返すことに注意してください。
next() 呼び出しは常に有効であると想定できます。つまり、next() が呼び出されると、BST の順序どおりのトラバーサルに少なくとも 1 つの次の番号が存在します。
例:
入力:
- 入力 = [“BSTIterator”, “next”, “next”, “hasNext”, “next”, “hasNext”, “next”, “hasNext”, “next”, “hasNext”]
- 入力 = [[[7, 3, 15, null, null, 9, 20]], [], [], [], [], [], [], [], [], []]
出力:
- [ヌル、3、7、真、9、真、15、真、20、偽]
説明:
BSTIterator bSTIterator = new BSTIterator([7, 3, 15, null, null, 9, 20]);bSTIterator.next();// 3 を返すbSTIterator.next();// 7 を返すbSTIterator.hasNext();// True を返すbSTIterator.next();// 9 を返すbSTIterator.hasNext();// True を返すbSTIterator.next();// 15 を返すbSTIterator.hasNext();// True を返すbSTIterator.next();// 20 を返すbSTIterator.hasNext();// False を返す
ヒント:
- ツリーのノード数は範囲
[1, 105]内 0 <= Node.val <= 106- 最大
105呼び出しhasNextとnext操作
アイデア:単純な順序でのトラバーサル。リスト コレクションを使用して、トラバースされたノードの値を格納します。
class BSTIterator {
List<Integer> list;
int idx ;
public BSTIterator(TreeNode root) {
list = new ArrayList<>();
idx = 0;
dfs(root);
}
private void dfs(TreeNode root) {
if(root == null) return;
dfs(root.left);
list.add(root.val);
dfs(root.right);
}
public int next() {
return list.get(idx++);
}
public boolean hasNext() {
if(idx < list.size()) return true;
return false;
}
}
8.11 二分探索木の 2 つのノードの合計
二分探索木のルート ノード rootと整数 が与えられた場合k、二分探索木の合計が に等しいノードが 2 つ存在するかどうかを判断してくださいk。二分探索木のノードの値はすべて一意であるとします。
例 1:
- 入力: ルート = [8,6,10,5,7,9,11]、k = 12
- 出力: 真
- 説明: ノード 5 とノード 7 の合計は 12 です。
ヒント:
-
二分木のノード数の範囲は [1, 10^4] です。
-
-10^4 <= Node.val <= 10^4 -
ルートは二分探索木です
-
-10^5 <= k <= 10^5
アイデア:セット コレクション + 深さ優先トラバーサル
class Solution {
Set<Integer> set = new HashSet<>();
public boolean findTarget(TreeNode root, int k) {
if(root == null) return false;
if(set.contains(k - root.val)) return true;
set.add(root.val);
return findTarget(root.left,k) || findTarget(root.right,k);
}
}
8.12 値と添字の差が所定の範囲内である
整数配列 nums と 2 つの整数 k と t が与えられます。と を同時に満たす2 つの異なる添え字 i と j があるかどうかを判断してください。abs(nums[i] - nums[j]) <= t abs(i - j) <= k
存在する場合は true、存在しない場合は false を返します。
例 1:
-
入力: 数値 = [1,2,3,1]、k = 3、t = 0
-
出力: 真
-
ヒント:
-
0 <= nums.length <= 2 * 10^4 -
-2^31 <= nums[i] <= 2^31 - 1 -
0 <= k <= 10^4 -
0 <= t <= 2^31 - 1
アイデア:ツリー コレクションを使用しTreeSet、コレクション内でサイズ k のウィンドウを維持し、コレクション内の数値の添え字の差の絶対値が k を超えないようにし、配列をトラバースし、コレクション内で最も近い数値を見つけます。 2 つの数値の差の絶対値が t 以下である
注:オーバーフローを防ぐために、配列内の数値を long に変換します
class Solution {
public boolean containsNearbyAlmostDuplicate(int[] nums, int k, int t) {
int n = nums.length;
TreeSet<Long> ts = new TreeSet<>();
for (int i = 0; i < n; i++) {
Long u = nums[i] * 1L;
// 从 ts 中找到小于等于 u 的最大值(小于等于 u 的最接近 u 的数)
Long l = ts.floor(u);
// 从 ts 中找到大于等于 u 的最小值(大于等于 u 的最接近 u 的数)
Long r = ts.ceiling(u);
if(l != null && u - l <= t) return true;
if(r != null && r - u <= t) return true;
// 将当前数加到 ts 中,并移除下标范围不在 [max(0, i - k), i) 的数(维持滑动窗口大小为 k)
ts.add(u);
if (i >= k) ts.remove(nums[i - k] * 1L);
}
return false;
}
}
8.13 スケジュール
MyCalendarスケジュールを格納するクラスを実装してください。この新しいスケジュールは、追加する期間内に他のスケジュールがない場合に保存できます。
MyCalendarbook(int start, int end)方法があります。これは、開始から終了までの時間にスケジュールを追加することを意味します。ここでの時間は半分開いた間隔であることに注意してください。つまり、[start, end)実数 x の範囲は です start <= x < end。
予約の重複は、2 つのスケジュールの時間が重複している場合に発生します (たとえば、両方のスケジュールが同時に発生した場合)。
MyCalendar.bookメソッドが呼び出されるたびに、二重予約を発生させずにスケジュールをカレンダーに正常に追加できる場合、 は true を返します。それ以外の場合は false を返し、スケジュールをカレンダーに追加しません。
MyCalendarクラスを呼び出すには、次の手順に従います。MyCalendar cal = new MyCalendar(); MyCalendar.book(start, end)
例:
入力:
- [「MyCalendar」、「本」、「本」、「本」]
- [[],[10,20],[15,25],[20,30]]
出力: [null,true,false,true]
説明:
MyCalendar myCalendar = new MyCalendar();MyCalendar.book(10, 20);// true を返すMyCalendar.book(15, 25);// false を返します。時間 15 は最初のスケジュールによってすでに予約されているため、2 番目のスケジュールをカレンダーに追加することはできませんMyCalendar.book(20, 30);// true を返します。最初のスケジュールには時間が含まれていないため、3 番目のスケジュールをカレンダーに追加できます 20
ヒント:
- テスト ケースごとに、
MyCalendar.book関数を21000回まで呼び出します。 0 <= start < end <= 10^9
アイデア: TreeSet コレクションを使用して自動並べ替えと高速挿入を実現し、カスタム並べ替え規則が必要
注:カスタム照合
class MyCalendar {
public static final class MySort implements Comparable<MySort>{
private int start;
private int end;
//自定义排序规则
public MySort(int start,int end){
this.start = start;
this.end = end;
}
@Override
public int compareTo(MySort sort) {
if(end <= sort.start){
return -1;
}
if(sort.end <= start){
return 1;
}
return 0;
}
}
TreeSet<MySort> set = new TreeSet<>();
public MyCalendar() {
}
public boolean book(int start, int end) {
return set.add(new MySort(start,end));
}
}