Linux カーネルのソース コード プロセスの原理分析
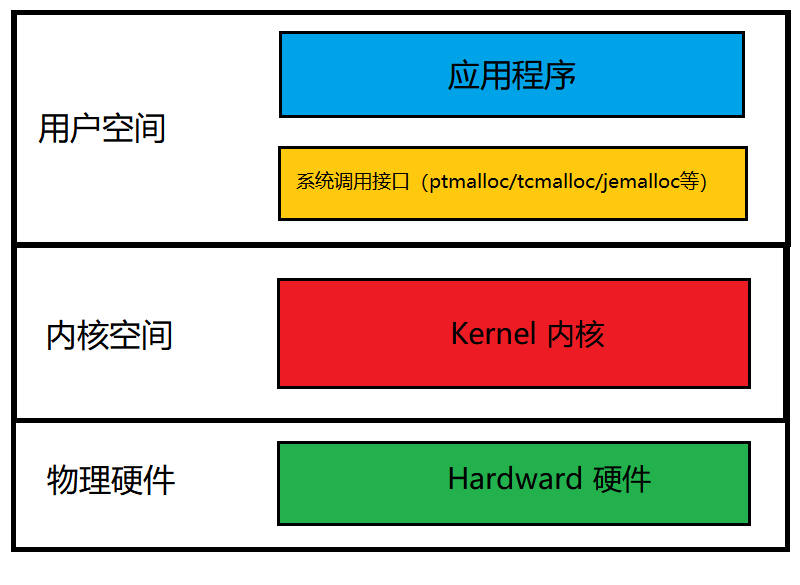
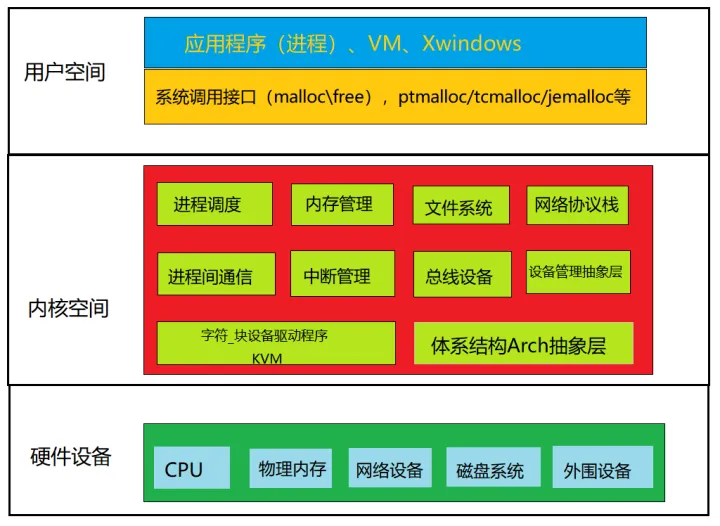
1. Linux カーネル アーキテクチャ図
2. プロセスの基礎知識
Linuxカーネルはプロセスをタスクと呼びます.プロセスの仮想アドレス空間はユーザー仮想アドレス空間とカーネル仮想アドレス空間に分割されます.すべてのプロセスはカーネル仮想アドレス空間を共有し,各プロセスは独立したユーザー仮想アドレス空間を持ちます. .
プロセスには 2 つの特別な形式があります。
ユーザー仮想アドレス空間を持たないプロセスは、カーネル スレッドと呼ばれます。
ユーザーの仮想アドレス空間を共有するプロセスは、ユーザー スレッドと呼ばれます。
一般的に、ユーザー スレッドは、混乱を招くことなく単にスレッドと呼ばれます。同じユーザー仮想アドレス空間を共有するすべてのユーザー スレッドは、スレッド グループを形成します。
C 標準ライブラリの処理用語と Linux カーネルの処理用語の対応関係は次のとおりです。
| C 標準ライブラリ プロセスの用語 | Linux カーネル プロセスの用語 |
|---|---|
| 複数のスレッドで処理する | スレッドグループ |
| 1 つのスレッドだけで処理する | プロセスまたはタスク |
| 糸 | ユーザー仮想アドレス空間を共有するプロセス |
3、Linux プロセスの 4 つの要素
- それを実行するためのプログラムがあります。
- プロセス専用のシステム スタック スペースがあります。
- カーネルには task_struct データ構造があります。
- 独立したストレージ スペースと専用のユーザー スペースがあります。
4 番目に、task_struct データ構造の主要メンバー
(インクルード/linux/sched.h)
struct task_struct {
//进程描述符
#ifdef CONFIG_THREAD_INFO_IN_TASK
/*
* For reasons of header soup (see current_thread_info()), this
* must be the first element of task_struct.
*/
struct thread_info thread_info;
#endif
unsigned int __state;//指向进程状态
#ifdef CONFIG_PREEMPT_RT
/* saved state for "spinlock sleepers" */
unsigned int saved_state;
#endif
/*
* This begins the randomizable portion of task_struct. Only
* scheduling-critical items should be added above here.
*/
randomized_struct_fields_start
void *stack;//指向内核栈
refcount_t usage;
/* Per task flags (PF_*), defined further below: */
unsigned int flags;
unsigned int ptrace;
// ......
};
- task_struct: プロセス記述子。
- __state: プロセスの状態を指します。
- *stack: カーネル スタックを指します。
- pid: グローバル プロセス ID を指します。
- tgid: グローバル スレッド グループの識別子を指します。
- *real_parent: 本当の親プロセスを指す
- *parent: 現在の親プロセスを指します。たとえば、プロセスがシステム コールを使用して別のプロセスによって追跡 (ptrace) されている場合、この時点での親プロセスは追跡プロセスです。
- プロセス スケジューリング ポリシーの優先度: prio、static_prio、normal_prio、rt_priority。
- nr_cpus_allowed: プロセスの実行が許可されているプロセッサ。
- *mm: メモリ記述子を指し、カーネル スレッドの場合、このビットは NULL です。
- *active_mm: カーネル スレッドの実行中にプロセスから借用されるメモリ記述子を指します。
- *fs: ファイルシステム情報。
他にもたくさんのメンバーがいますが、ここにリストするには多すぎます。
5. 新しいプロセス分析を作成する
Linux カーネルでは、既存のプロセスから新しいプロセスがコピーされ、カーネルは静的データ構造を使用してカーネル スレッド 0 を作成し、カーネル スレッド 0 をフォークしてカーネル スレッド 1 とカーネル スレッド 2 を生成します (kthreadd スレッド)。1 番カーネルスレッドの初期化後、ユーザプログラムをロードして 1 番プロセスとなり、1 番プロセスまたはその子孫の fork により他のプロセスが生成され、1 番プロセスの fork により他のカーネルスレッドが生成されます。 kthreadd スレッド。
新しいプロセスを作成するための Linux 3 システム コール:
- fork (フォーク): 子プロセスは、コピー オン ライト テクノロジを使用した親プロセスのコピーです。
- vfork: 子プロセスを作成するために使用され、子プロセスはすぐに execve を呼び出して新しいプログラムをロードします.物理ページのコピーを避けるために、親プロセスはスリープ状態になり、子プロセスが新しいプログラムをロードするのを待ちます. fork が copy-on-write テクノロジーを採用したため、vfork は速度の利点を失い、放棄されました。
- clone (clone): 子プロセスと親プロセスの間でどのリソースを共有するかを正確に制御できます。このシステム コールの主な目的は、スレッドを作成するために pthread ライブラリによって使用されることです。
clone は最も完全な関数であり、多くのパラメーターと複雑な使用法があります。 fork は clone の単純化された関数です。
(カーネル/fork.c)
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
struct kernel_clone_args args = {
.exit_signal = SIGCHLD,
};
return _do_fork(&args);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}
#endif
#ifdef __ARCH_WANT_SYS_VFORK
SYSCALL_DEFINE0(vfork)
{
struct kernel_clone_args args = {
.flags = CLONE_VFORK | CLONE_VM,
.exit_signal = SIGCHLD,
};
return _do_fork(&args);
}
#endif
#ifdef __ARCH_WANT_SYS_CLONE
#ifdef CONFIG_CLONE_BACKWARDS
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
unsigned long, tls,
int __user *, child_tidptr)
#elif defined(CONFIG_CLONE_BACKWARDS2)
SYSCALL_DEFINE5(clone, unsigned long, newsp, unsigned long, clone_flags,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
#elif defined(CONFIG_CLONE_BACKWARDS3)
SYSCALL_DEFINE6(clone, unsigned long, clone_flags, unsigned long, newsp,
int, stack_size,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
#else
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
unsigned long, tls)
#endif
{
struct kernel_clone_args args = {
.flags = (lower_32_bits(clone_flags) & ~CSIGNAL),
.pidfd = parent_tidptr,
.child_tid = child_tidptr,
.parent_tid = parent_tidptr,
.exit_signal = (lower_32_bits(clone_flags) & CSIGNAL),
.stack = newsp,
.tls = tls,
};
if (!legacy_clone_args_valid(&args))
return -EINVAL;
return _do_fork(&args);
}
#endif
Linux カーネルは、システム コールの独自の方法を定義します. 現在、システム コール fork が例として取り上げられています: 新しいプロセスを作成するための 3 つのシステム コールは、ファイル kernel/fork.c にあり、関数に作業を委譲します。 _do_fork (6.0 以降、名前が kernel_clone に変更されました)。具体的なソース コードの分析は次のとおりです。
long _do_fork(struct kernel_clone_args *args)
{
u64 clone_flags = args->flags;
struct completion vfork;
struct pid *pid;
struct task_struct *p;
int trace = 0;
long nr;
// ......
}
Linux カーネル関数 _do_fork() の実行フローを次の図に示します。
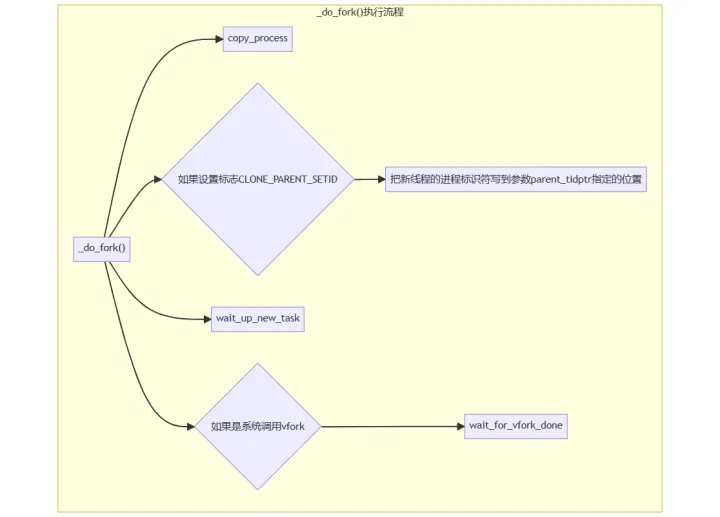
特定のコア処理関数は copy_process() です。 カーネル ソース コードは次のとおりです。
/*
* This creates a new process as a copy of the old one,
* but does not actually start it yet.
*
* It copies the registers, and all the appropriate
* parts of the process environment (as per the clone
* flags). The actual kick-off is left to the caller.
*/
static __latent_entropy struct task_struct *copy_process(
struct pid *pid,
int trace,
int node,
struct kernel_clone_args *args)
{
int pidfd = -1, retval;
struct task_struct *p;
struct multiprocess_signals delayed;
struct file *pidfile = NULL;
u64 clone_flags = args->flags;
struct nsproxy *nsp = current->nsproxy;
// ......
}
関数 copy_process(): 新しいプロセスを作成する主な作業は、この関数によって完了されます. 具体的な処理の流れを下図に示します. 同じ
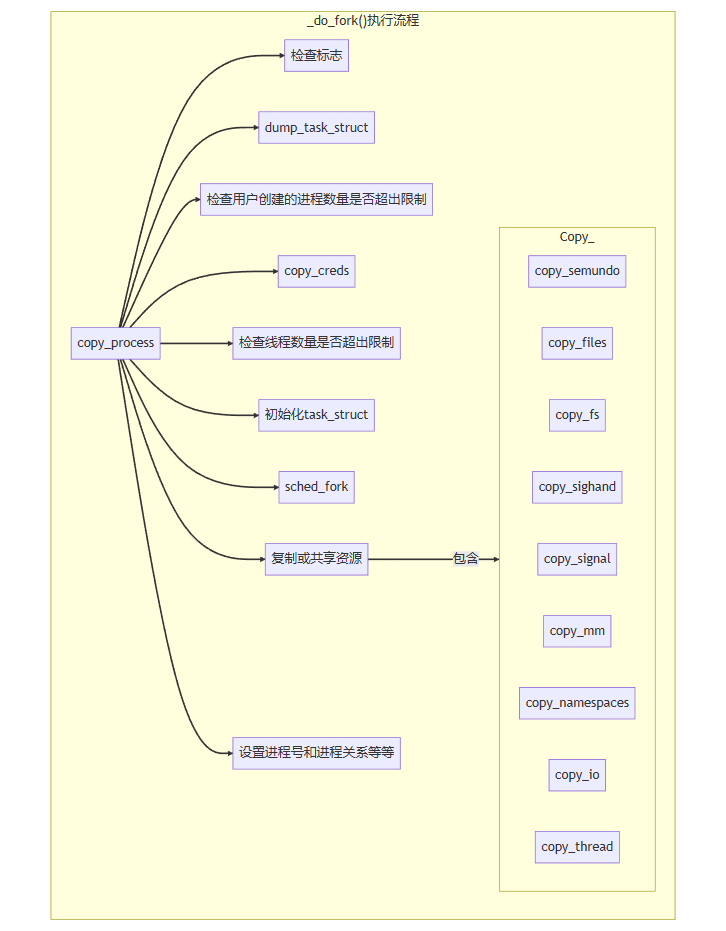
スレッド グループ内のすべてのスレッドは、同じユーザー名前空間とプロセス番号名前空間に属している必要があります.
6. プロセス状態移行の分析
プロセスには 7 つの主な状態があります。
- 準備完了状態、
- 稼働状況、
- 浅い眠り、
- 適度な睡眠、
- 深い眠り、
- ゾンビ状態、
- 死の状態。
それらの間の状態遷移は次のとおりです:
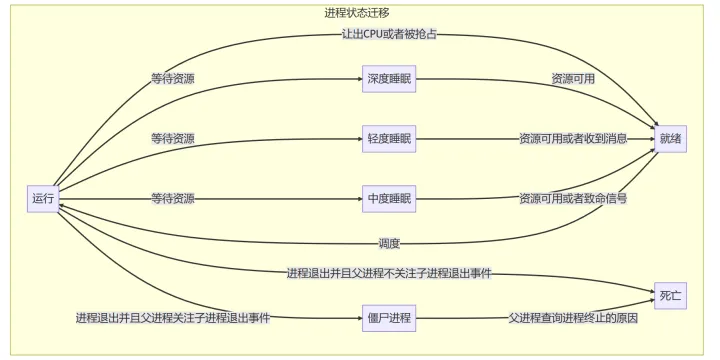
準備完了: 状態は TASK_RUNING (準備完了と実行中に厳密な区別はありません) であり、実行中のキューでスケジューラがスケジュールするのを待っています。
実行中: 状態は TASK_RUNING です。これは、スケジューラが選択され、CPU 上で実行されていることを証明します。
ゾンビ: 状態は TASK_DEAD で、プロセスは終了し、親プロセスは子プロセスの終了イベントに注意を払います。
死: 状態は exit_state です。
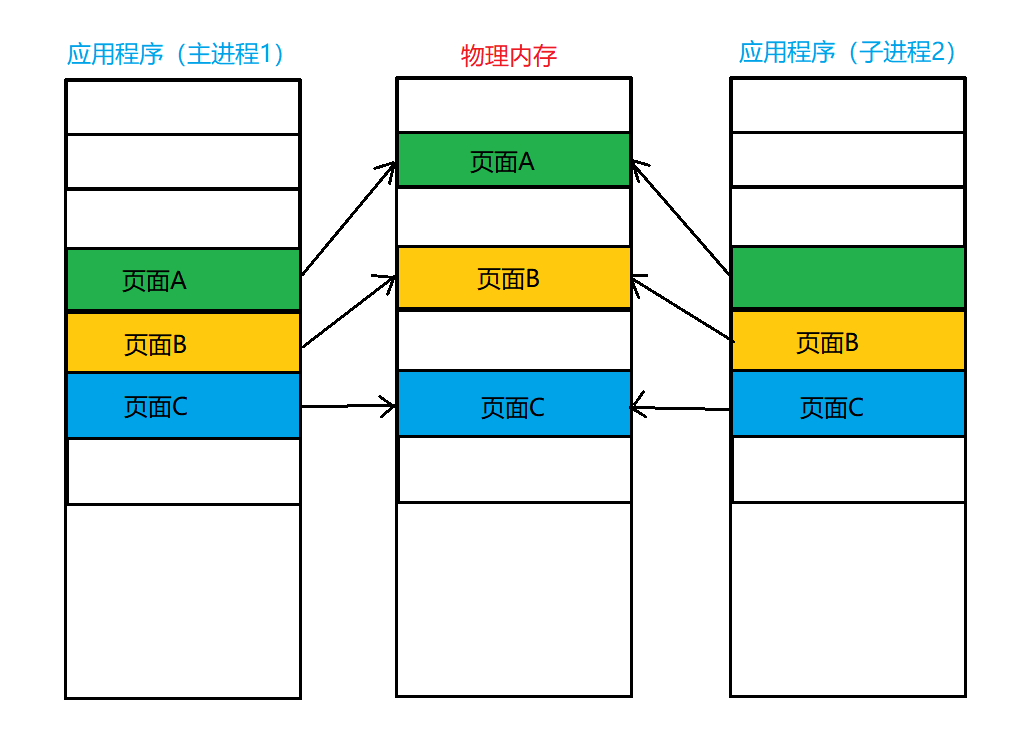
7. コピーオンライト技術
コピー オン ライトの核となる考え方: データ コンテンツをコピーする必要がある場合にのみデータ コンテンツをコピーし、リソースの無駄を減らします。
新しいプロセスを申請する手順:
- 空の PCB (プロセス制御ブロック) を申請します。
- 新しいプロセスにデータ リソースを割り当てます (ここではコピー オン ライト手法を使用します)。
- PCB を初期化します。
- 申請したばかりの新しいプロセスを準備完了キューに挿入します。状態は task_running で、スケジューラによってスケジュールされ、running 状態に入ります。
アプリケーション (プロセス 1) がページ C を変更する前:
アプリケーション (プロセス 1) がページ C を変更した後:
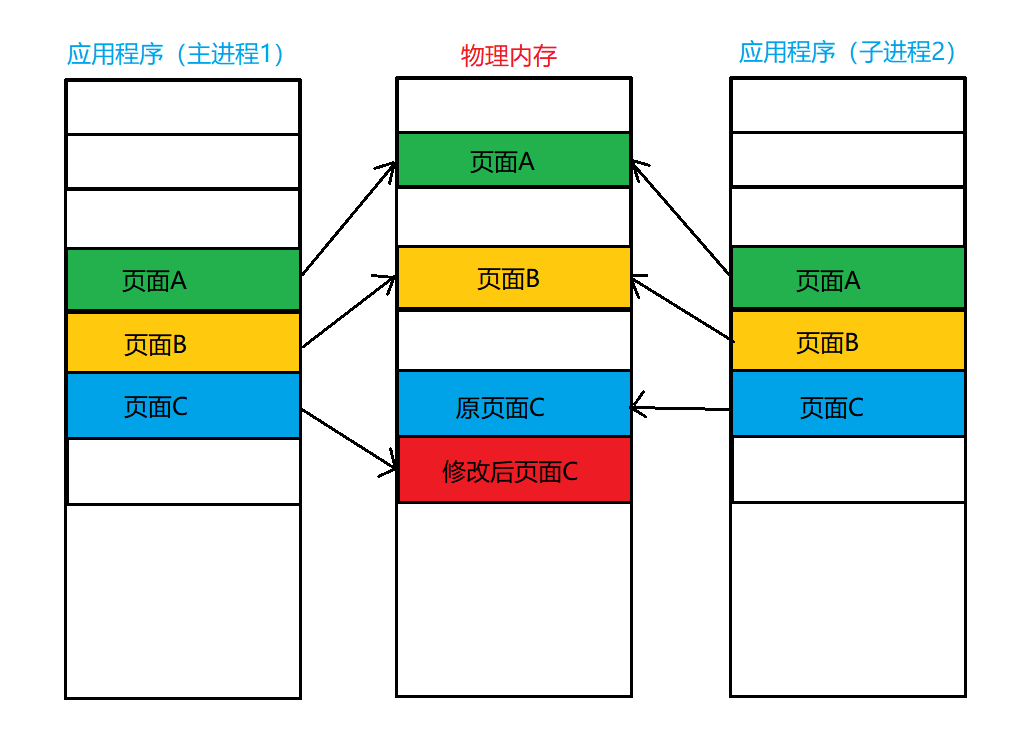
注: 変更可能なページのみをコピー オン ライトとしてマークする必要があり、変更不可能なページは親プロセスと子プロセスで共有できます。 .
