目次
8. コントロール グループ — cgroups (コントロール グループ)
I.はじめに
Linux オペレーティング システムには、さまざまなサービスを制御する他のプロセスを生成するメイン プロセスがあります。
2. 仮想化の概要
仮想化により、1 台の物理サーバー上で複数の仮想マシンを実行できます。仮想マシンは、物理マシンの CPU、メモリ、および IO ハードウェア リソースを共有しますが、仮想マシンは互いに論理的に分離されています。仮想化により、1 台のコンピュータ上で複数の論理コンピュータが同時に動作し、論理コンピュータごとに異なるオペレーティング システムを実行したり、アプリケーションが相互に影響を与えずに独立した空間で実行したりできるため、コンピュータの作業効率が大幅に向上します。
現在主流の仮想化技術には、オープン ソースの XEN、KVM、VMware の ESXi、および Microsoft の Hyper-V が含まれます。
1. 仮想化の概念
アプリケーションとシステム カーネル リソースを分離し、オペレーティング システム レベルで分離して、リソースの使用率を向上させます。
2. カップリングとデカップリングの概念
2.1. カップリング
結合は、ブロック間結合とも呼ばれます。ソフトウェアシステム構造におけるモジュール間の相互関係の程度の尺度を指します。モジュール同士の接続が密であるほど結合が強く、モジュールが独立しているほど、モジュール間の結合が悪くなります。これは、モジュール間のインターフェイスの複雑さ、呼び出し方、および送信される情報に依存します。
2.2. カップリング
ソフトウェア工学では、オブジェクト間の結合度はオブジェクト間の依存関係です。オブジェクト間の結合が高いほど、メンテナンス コストが高くなるため、クラスとコンポーネント間の結合を最小限に抑えるようにオブジェクトを設計する必要があります。
2.3. デカップリング
デカップリングとは文字通り、デカップリングを意味します。
ソフトウェア エンジニアリングでは、結合度を下げることをデカップリングと理解できます.モジュール間に依存関係がある場合は、結合があるはずです.理論的には絶対ゼロ結合を達成することはできませんが、いくつかの既存の方法を使用して、結合度を最小限に抑えることができます.カップリングです。
3. 仮想化
リソース使用率の問題を軽減および解決します。実際のインスタンスのパフォーマンスは、仮想化よりも比較的安定しており、その機能ははるかに強力です。
4. 仮想化の動作原理
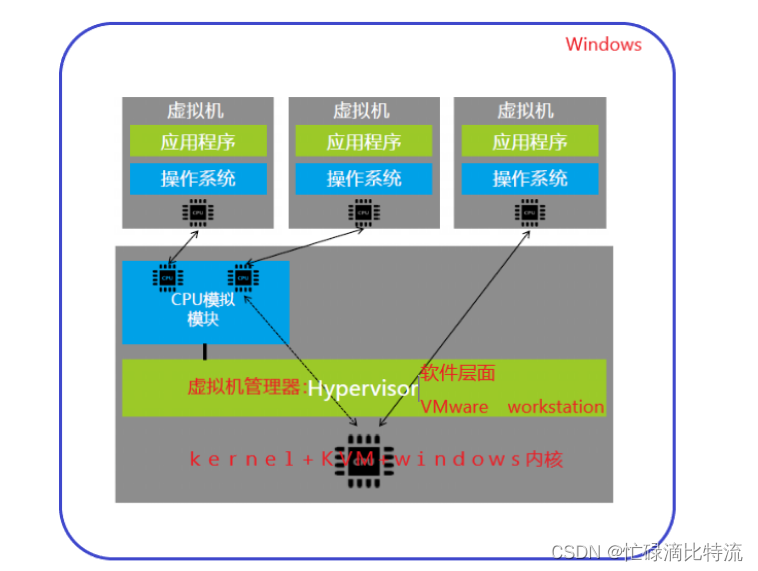
ハイパーバイザー (仮想マシン監視プログラム) と呼ばれるソフトウェアは、物理リソースを効果的に分離し、これらのリソースを異なる仮想環境 (つまり、これらのリソースを必要とするタスク) に割り当てることができます。ハイパーバイザーは、オペレーティング システム (ラップトップなど) の上に配置することも、ハードウェア (サーバーなど) に直接インストールすることもできます。これは、ほとんどの企業が仮想化を使用する方法です。ハイパーバイザーは物理リソースを引き継ぎ、それらを仮想環境で使用できるように分割します。
物理環境のリソースは、必要に応じて分割され、多くの仮想環境に分散されます。仮想環境 (多くの場合、クライアントまたは仮想マシンと呼ばれます) 内で、ユーザーはコンピューティング タスクと対話し、計算を実行できます。仮想マシンは、単一のデータ ファイルとして実行されます。他のデジタル ファイルと同様に、仮想マシンはあるコンピューターから別のコンピューターに移動でき、どちらのコンピューターで開いても同じように機能します。
仮想環境の実行中に、ユーザーまたはプログラムが物理環境からより多くのリソースを要求する命令を発行した場合、ハイパーバイザーはその要求を物理システムに渡し、変更をすべてネイティブに近い速度でキャッシュします (特に、要求がカーネルベースの仮想マシン用の KVM ベースのオープンソース ハイパーバイザーから提供されます)。
5. 2 つのコア コンポーネント
5.1、 QEMU
QEMU はキューとして理解できる I/O 制御モジュールです. コアの目的はリソース カーネル内のリソースを呼び出すことです. KVM ロジックによって分離されたリソースを QEMU に転送し、仮想マシンに転送する必要があります.
QEMU はキューとして理解できる I/O 制御モジュールです. コアの目的はリソース カーネル内のリソースを呼び出すことです. KVM ロジックで分離されたリソースを QEMU に転送し、仮想マシンに転送する必要があります.
5.2、 KVM
物理リソースを論理的に分割し、仮想化されたリソースに抽象化し、VMM で構成に従って論理分割し、アプリケーションの仮想化を実行するために使用されます。
QEMU からのリクエスト コマンドのみを受け入れます。アプリケーション プログラムから直接送信される重要なコマンドは傍受され、インターフェイスを介して QEMU に送信されるため、QEMU はそれを実行する必要があるかどうかを判断できます。
6. 仮想化タイプ
- 完全な仮想化: すべての物理ハードウェア リソースをソフトウェアで抽象化し、最終的に呼び出します。
- 準仮想化: オペレーティング システムの変更が必要
- パススルー: 物理ハードウェア リソースを直接使用 (サポートが必要、まだ完全ではありません)
3. Docker コンテナ

1. ドッカーの誕生
①. Docker は dotcloud 社のオープンソース製品です. dotcloud は 2010 年に設立された、主に PAAS (Platfrom as a Service) プラットフォームに基づいて開発者向けのサービスを提供する会社です。
②. Linux コンテナーは、プロセスとリソースを分離するための軽量な仮想化を提供できるカーネル仮想化テクノロジーです。
③. Docker は、PAAS プロバイダー dotCloud によってオープン ソース化された LXC ベースの高度なコンテナー エンジンです. ソース コードは Github でホストされています. Go 言語に基づいており、Apache2.0 プロトコルに準拠しています.
2.ドッカーとは?
①、軽量な「仮想マシン」です
②. Linux コンテナーでアプリケーションを実行するためのオープンソース ツール
3. 従来のサーバーから仮想化へと移行する理由
アドバンテージ:
①. 従来のサーバーは、利用率を向上させることができます
②. マイクロサービスに適した実行環境を提供する
③高い分離性(仮想マシンがオペレーティングシステムから完全に分離されているため)
④、安全性が高く、雪崩が起こりにくい
⑤. より便利な管理 (物議を醸す)
⑥. リソースを柔軟にスケーリングする方が簡単
⑦. 初期費用が高く、後者は従来のものに比べて「安く」なる
短所:
①初期費用が高い
②メンテナンス難易度が高い
③、ホストのセキュリティ要件が高い
④.リソース要件が非常に高いアプリケーションの実行には適していません (リソースを非常に消費するアプリケーションと呼ばれます)。
⑤、場合によってはランニングコストが高くなる
4.ドッカー機能
- 柔軟性: 最も複雑なアプリケーションでもコンテナー化できます。
- 軽量: コンテナーはホスト カーネルを利用および共有します。
- 交換可能: 更新とアップグレードをその場で展開できます。
- ポータブル: ローカルでビルドし、クラウドにデプロイして、どこでも実行できます。
- スケーラブル: コンテナのレプリカを追加して、自動的に配布できます。
- 積み重ね可能:サービングは垂直に、瞬時に積み重ねることができます。
5. Docker コンテナ VS KVM

5.1、KVM:
Hypervisor を使用して、仮想マシンに実行中のプラットフォームを提供し、各 VM でのオペレーティング システムの実行を管理します。各 VM には、独自のオペレーティング システム、アプリケーション、および必要な依存ファイルが必要です。
5.2. Docker コンテナー:
スケジューリングと分離に Docker エンジンを使用すると、リソースの使用率が向上し、同じハードウェア機能の下でより多くのコンテナー インスタンスを実行できるようになります。各コンテナーには、独自の分離されたユーザー スペースがあります。
5.3 相違点
| 違い | Docker コンテナ | VM |
| 起動速度 | セカンドレベル | 分レベル |
| 運転性能 | ほぼネイティブ (カーネルで直接実行) | 約50%の損失 |
| ディスクの使用状況 | MB | GB |
| 量 | 数十万人 | 通常は数十台 |
| 隔離 | プロセス | システムレベル (より徹底) |
| オペレーティング·システム | Linuxをサポートしている限り | ほとんど全て |
| 梱包度 | プロジェクト コードと依存関係のみをパッケージ化し、ホスト カーネルを共有する | ホストから分離された完全なオペレーティング システム |
6. Docker の 3 つの主要コンポーネント
1. ミラーリング: Docker ミラーリングは特別なファイル システムであり、コンテナーのランタイムに必要なプログラム、ライブラリ、リソース、構成、およびその他のファイルを提供するだけでなく、ランタイム用に準備されたいくつかの構成パラメーターも含まれています。イメージには動的データは含まれず、作成後に内容が変更されることはありません。Docker イメージが実行されると、コンテナーになります (docker run)
2. コンテナー: イメージによって作成された実行中のインスタンス。Docker はコンテナーを使用してアプリケーションを実行します。各コンテナーは、分離された安全なプラットフォームです。コンテナーは、軽量の Linux オペレーティング環境と考えることができます。
3. ミラー ウェアハウス: ミラー ファイルが集中的に格納される場所。ユーザーがイメージを作成した後、パブリック ウェアハウスまたはプライベート ウェアハウスにアップロードし、別のホストでイメージを使用する必要がある場合は、ウェアハウスからダウンロードするだけで済みます。
7. Docker コンテナーの実行ロジック
Docker はクライアント/サーバー (C/S) アーキテクチャ モードを使用し、Docker デーモン (Docker デーモン) はサーバー側として Docker クライアントからの要求を受け取り、Docker コンテナーの作成、実行、および配布を担当します。通常、Docker デーモンは Docker ホストのバックグラウンドで実行され、ユーザーは Docker クライアントを使用して Docker デーモンと直接対話します。
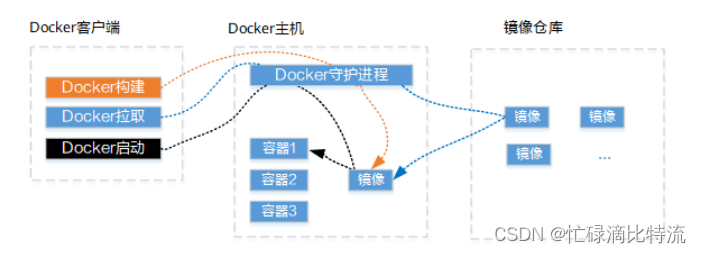
① オレンジ色のプロセスに示すように、Docker build コマンドを実行すると、Docker ファイルに基づいてミラー イメージがビルドされ、ローカルの Docker ホストに格納されます。
②、青色のプロセスに示すように、ローカルに必要なイメージはなく、Docker プル コマンドはクラウド イメージ ウェアハウスからローカルの Docker ホストにイメージをプルします。
③黒いプロセスのようにDocker startコマンドを実行すると、既存のローカルイメージがコンテナにインストールされ、コンテナが起動します。
それぞれの機能
Docker クライアント: Docker デーモン (Docker Daemon) との通信を確立するために使用されるクライアント
Docker ホスト: Docker デーモンとコンテナーの実行に使用される物理マシンまたは仮想マシン
Docker デーモン: Docker クライアントから送信された要求を受信して処理し、Docker API 要求を監視し、イメージ、コンテナー、ネットワーク、データ ボリュームなどの Docker オブジェクトを管理します。
誰もが言葉を要約します:

8. Docker 名前空間
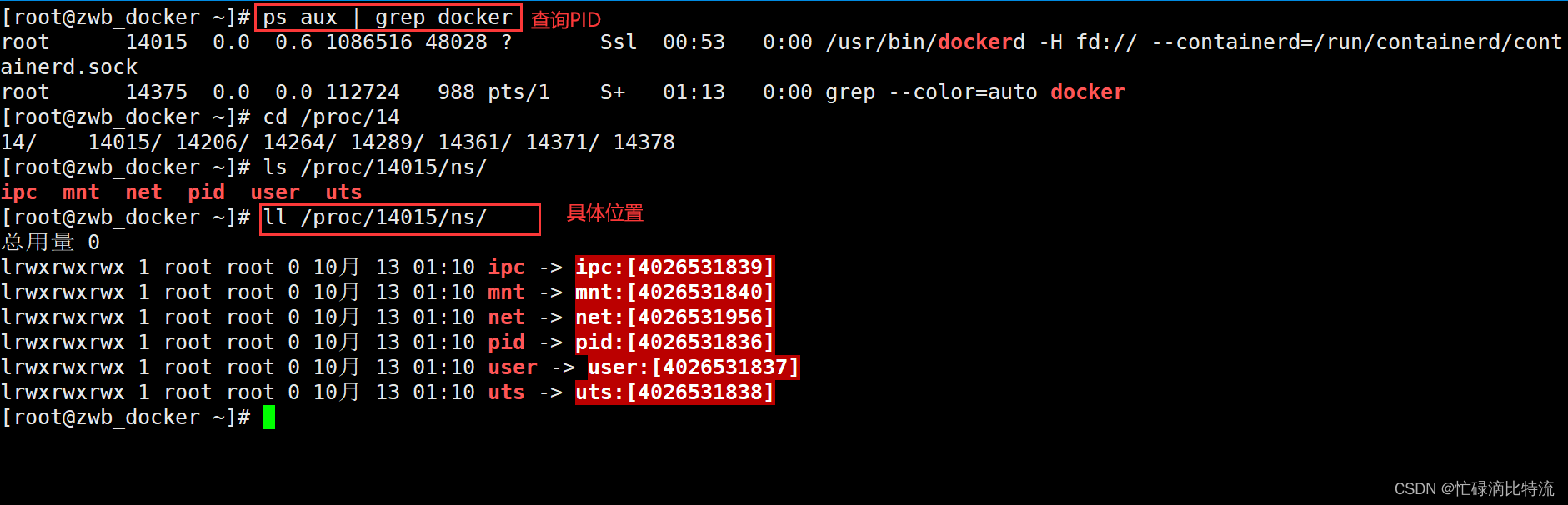
| マウント(mnt) | (マウントポイント) ファイルシステム |
| ユーザー | プロセスを操作するユーザーおよびユーザー グループ |
| ピッド | プロセス番号 |
| uts | ホスト名とドメイン名 |
| ipc | セマフォ、メッセージ キュー、共有メモリ |
| ネット | ネットワーク デバイス、ネットワーク プロトコル スタック、ポートなど |
9. コントロール グループ — cgroups (コントロール グループ)
6 つの名前空間は cgroups によって管理されます.centos cgroups の最後の管理バージョンはバージョン 3.8 であり、3.6 および 3.5 は使用できません
Docker は、cgroupsを介してコンテナによるホスト リソースの使用を制限します
cgroup の4 つの機能:
①.リソースの制限: cgroup は、プロセスグループが使用する総リソースを制限できます
②. 優先順位の割り当て: 割り当てられたCPUタイム スライスの数とハード ディスクの IO 帯域幅のサイズによって、実行中のプロセスの優先レベルを制御することと同じです。
③. リソース統計: cgroup は、CPU 使用時間、メモリ使用量などのシステム リソースの使用量をカウントして、ボリュームごとに請求できます。同時に、サスペンド機能もサポートしており、cgroup によってすべてのリソースが制限され、リソースを使用できません.これは、私たちのプログラムが使用できないという意味ではありませんが、リソースが使用できず、使用できないことに注意してください.待機状態
④、プロセス制御:プロセスグループに対してサスペンドやレジュームなどの操作を行うことができます
10. docker の基本原則
cgroup と名前空間