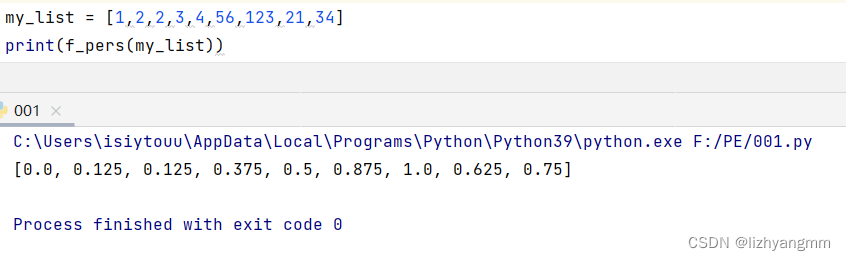
既成の関数がなく、二分法が実現できてしまう・・・が、データ量が多い、これが一般的に遅くない、というかEXCELのほうが早い
np.percentile(series, m*100) は numpy の関数で、パラメータはデータ系列、変位値です
numpy を np としてインポート
def f_pers(series): # 関数を定義、パラメータはデータそのもの
pre_list = [] # 各データの過去の変位値を格納するための空のリスト
シリーズの私のために:
a, b = 0, 1 # 分位点の開始間隔は 0%-100% です
True の間:
m = (a+b)/2 # 最初の分位数は 50%
if np.percentile(series, m*100) >= i: # ターゲット データが分位に対応するデータの 50% 未満の場合、ターゲット データの過去の分位は [0%, 50%] に減少します、次の m が 25% の場合、ターゲット データは 0 ~ 0.25 または 0.25 ~ 0.5 に配置される可能性があります。
b = m
elif np.percentile(series, m*100) < i:
a = m
if np.abs(ab)<=0.0001: # 左右の境界誤差が 4% ポイントになるまでループし、終了します
壊す
pre_list.append(round(m,3)) # 各データの分位点をリストに入れ、小数点以下 3 桁を取る
return pre_list # 変位値リストを返す