目次
NLP、CV、さらには CG の分野での Transformer モデルの人気により、アテンション メカニズム (Attention Mechanism) はますます多くの学者によって注目されており、パフォーマンスを向上させるためにさまざまなディープ ラーニング タスクに導入されています。清華大学のフー・シミン教授のチームは最近、CVM に関する Attention レビュー [1] を発表し、この分野の関連研究の進展を詳細に紹介しました。点群アプリケーションの場合、アテンション メカニズムの導入と新しいディープ ラーニング モデルの設計は、当然のことながら研究のホットスポットです。この記事では、注意メカニズムをオブジェクトとして取り上げ、その開発と、点群アプリケーションの分野での成功したアプリケーションの概要を説明し、この研究の方向性にブレークスルーをもたらすことを期待している学生に参考資料を提供します。
1. 注意メカニズムの起源
注意の仕組みについては、Li Mu 氏の深層学習の教科書 [2] を参考に、注意の仕組みを簡単に説明します。注意メカニズムは、人間の視覚をシミュレートし、情報を選択的に選別して受信および処理するメカニズムです。情報をスクリーニングするとき、自律的なプロンプトが提供されない場合、つまり、人が何も考えずにテキストを読んだり、シーンを観察したり、音声を聞いたりする場合、注意メカニズムは白黒シーンなどの異常な情報に偏ります。赤い服の女の子、または段落内の感嘆符など。特定の名詞に関連する文やさまざまなオブジェクトに関連するシーンを読みたい場合など、自律的なプロンプトが導入されると、注意メカニズムがこのプロンプトを導入し、情報が選別されるときにこの情報に対する感度を高めます。上記のプロセスを数学的にモデル化するために、アテンション メカニズムは 3 つの基本要素、つまりクエリ、キー、値を導入します。これら 3 つの要素が一緒になって、アテンション モジュールの基本的な処理ユニットを構成します。キー(Key)と値(Value)は情報の入出力に対応し、クエリ(Query)は自律的なプロンプトに対応します。アテンションモジュールの基本処理単位を下図に示します。
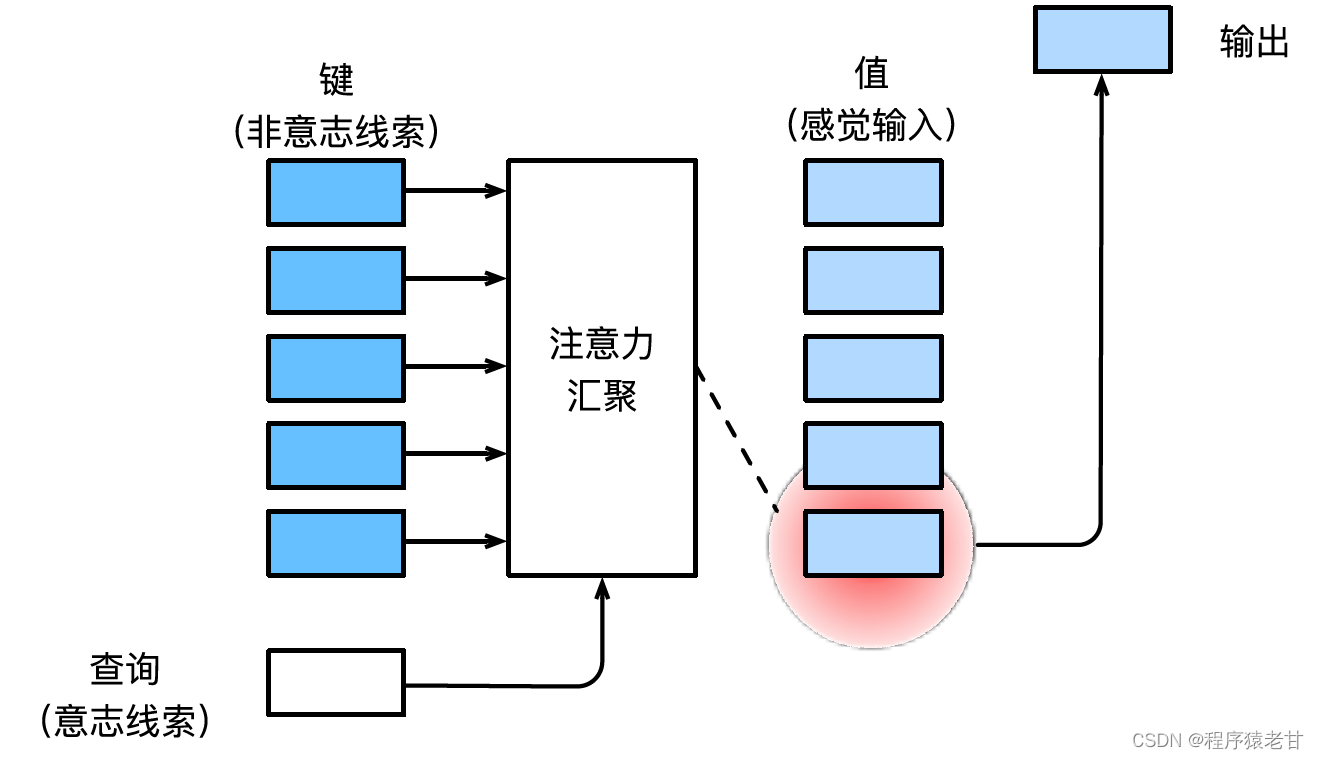
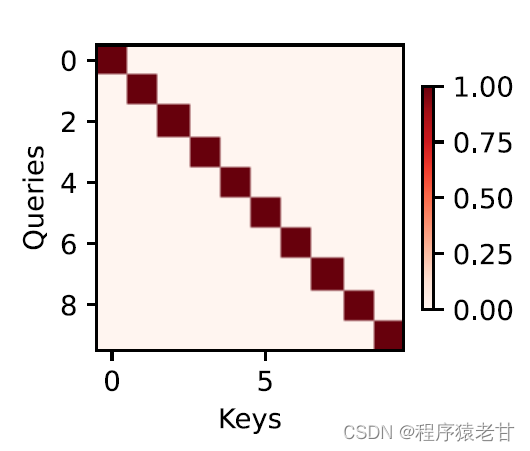
アテンション メカニズムは、アテンション プーリングによってクエリとキーを組み合わせ、値の選択傾向を実現します。キーと値は、トレーニング タスクの入力と出力と同じようにペアになっています。これは、既知のデータ分布またはカテゴリの対応です。アテンション メカニズムはクエリをアテンション プールに入力し、クエリから各キーへの重みコードを確立し、クエリとキーの関係を取得して、対応する値の出力を導きます。つまり、クエリがキーに近いほど、クエリの出力はキーに対応する値に近くなります。このプロセスにより、クエリに近いキーと値の対応に注意が導入され、注意に準拠した出力が導かれます。クエリとキーに対応する2次元の関係行列が成立すると、値が同じ場合は1、異なる場合は0となり、可視化結果は次のように表現できます。 :
2. Nadaraya-Watson カーネル回帰
注意メカニズムの基本的な動作ロジックを理解するために、古典的な注意メカニズム モデル Nadaraya-Watson カーネル回帰 [3] [4] を示します。関数 f によって制御されるキーと値の対応データセット {(x1,y1),(x2,y2),...(xi,yi)} があるとします。学習タスクは f を確立し、新しいx キーの評価。このタスクでは、(xi, yi) はキーと値に対応し、入力 x はクエリを表し、目標は対応する値を取得することです。注意メカニズムによると、x とキー値対応データ セット内の各キー値との類似関係を調べて、その値の予測を確立する必要があります。入力 x が特定の xi キーに近いほど、出力値は yi に近くなります。ここでのキー値の最も単純な推定は、平均化です。
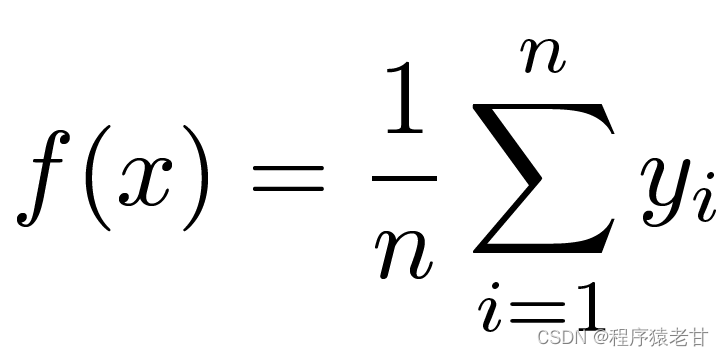
明らかに、これは良い考えではありません。平均プーリングでは、キーと値の分布におけるサンプルの偏差が無視されるためです。評価プロセスにキーと値の違いを導入すると、結果は自然に良くなります。Nadaraya-Watson カーネル回帰は、このようなアイデアを使用して、重み付けされた評価方法を提案します。
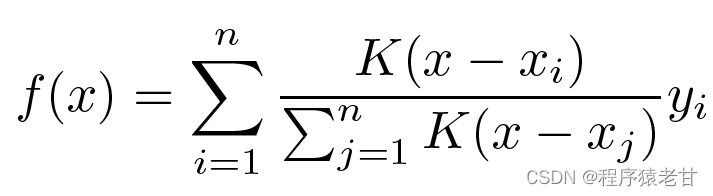
K はカーネルと見なされます。つまり、差からの偏差を測定するための重みとして理解されます。上記の式を、入力とキーの違いの重みに応じて書き直すと、独自の式が得られます。
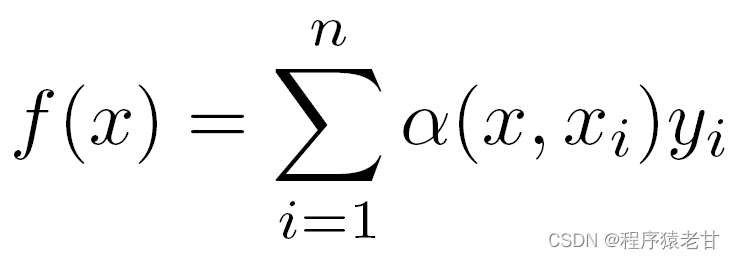
上記の重みをガウス カーネルによって駆動されるガウス重みに置き換えると、関数 f は次のように表すことができます。
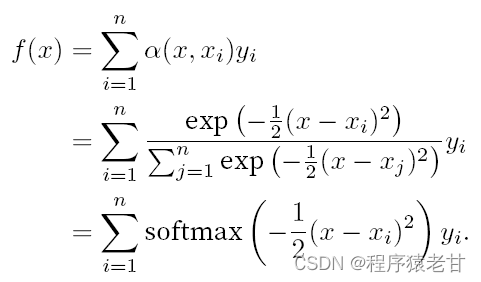
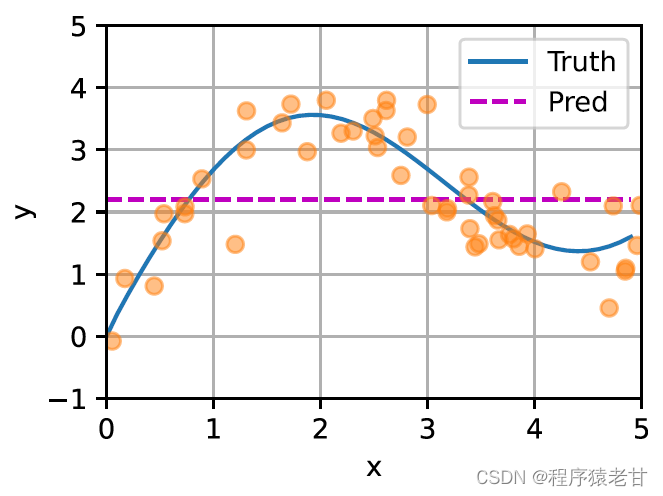
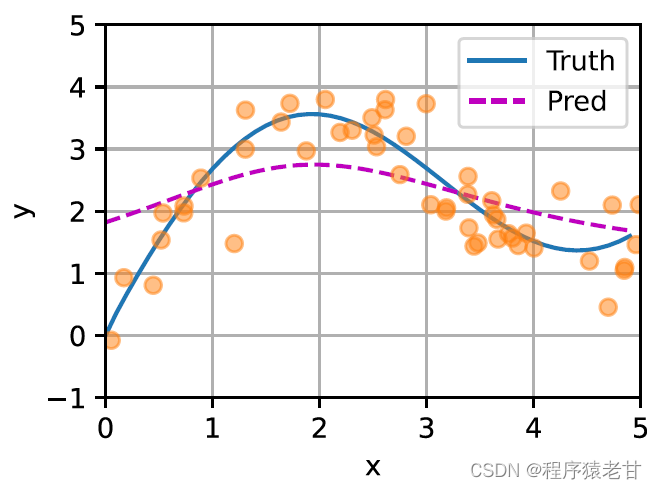
平均プーリング (左側のパネル) とガウス カーネル主導のアテンション プーリング (右側のパネル) から派生したキーと値のペアのサンプルに対するさまざまな f の適合を比較するための概略図がここに示されています。後者のフィッティング性能がはるかに優れていることがわかります。
上記のモデルはノンパラメトリック モデルです. 学習可能なパラメータの場合は、[2] のアテンション メカニズムの章を読むことをお勧めします. ここで使用されるガウス カーネルとそれに対応するガウス重みは、クエリとキーの関係を記述するために使用されます。注意メカニズムでは、この関係を定量的に表したものが注意スコアです。クエリ値の予測を確立する上記のプロセスは、クエリのキーと値のペアに基づいてスコアを確立し、スコアに重みを割り当ててクエリ値を取得することとして表現できます。次のように表現されます。
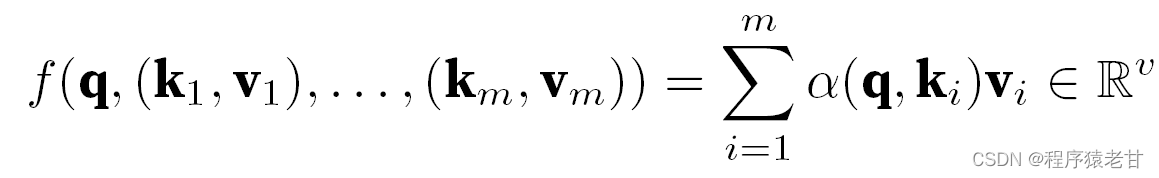
ここで、α は重みを表し、q はクエリを表し、kv はキーと値のペアを表します。教科書 [2] では、クエリとキーの長さの不一致時間の加算的アテンション処理方法と、アテンション スコアの定義に使用されるスケーリング ドット積アテンションの処理方法も紹介されているため、ここでは詳しく説明しません。
3. 多頭注意と自己注意
1) 多頭注意
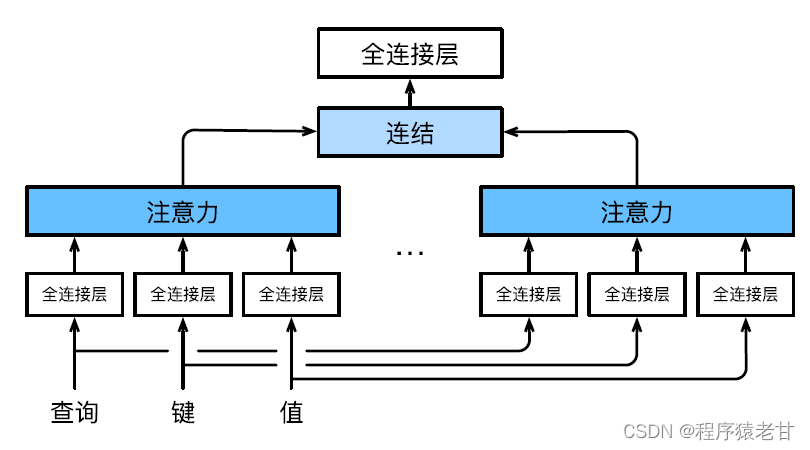
マルチヘッドアテンションを使用して、クエリとサブスペース表現を異なるキー値と組み合わせ、アテンションメカニズムに基づいてさまざまな動作の編成を実現し、構造化された知識とデータの依存関係を学習します。クエリ、キー、および値を変換するために、さまざまな線形射影が個別に学習されます。次に、変換されたクエリとキー値がアテンション プールに並列に送信され、複数のアテンション プールの出力が結合され、学習可能な別の線形射影によって変換され、最終的な出力が生成されます。この設計は、マルチヘッドアテンション [5] と呼ばれます。以下の図は、学習可能な多頭注意モデルを示しています。
各アテンション ヘッドの数学的定義は次のとおりです。クエリ q、キー k、および値 v が与えられると、各アテンション ヘッド h の計算方法は次のようになります。
![]()
ここで、f は、加法的注意とスケーリングされた内積注意になります。マルチヘッドアテンションの出力は、複数のアテンションメカニズムの出力を連結してより複雑な機能を模倣するために、別の線形変換を受けます。
2) 自己注意と位置エンコーディング
Attention メカニズムに基づいて、NLP 問題の字句シーケンスが Attention プールに入力され、字句要素のグループがクエリおよびキー値として同時に使用されます。各クエリは、すべてのキーと値のペアに対応し、アテンション出力を生成します。クエリとキーの値はすべて同じ入力セットから取得されるため、自己注意メカニズムと呼ばれます。ここでは、自己注意メカニズムに基づくコーディング方法を示します。
トークン入力シーケンス x1,x2,...,xn が与えられると、対応する出力は同一のシーケンス y1,y2,...,yn になります。y は次のように表されます。
![]()
最初はこの式がよくわかりませんでした。しかし、テキスト翻訳という具体的な作業と組み合わせると、わかりやすいです。ここでの意味は、トークンの特定の位置にある要素が入力と出力に対応するということです。つまり、キー値は要素そのものです。各単語とトークン内のすべての単語の重みを学習することによって、値の予測を構築する関数を学習する必要があります。
トークンを扱う場合、self-attention の並列計算が必要になるため、順次操作は放棄されます。シーケンス情報を使用するために、位置エンコーディングを入力表現に追加して、絶対または相対位置情報を挿入できます。入力行列に同じ形状の位置埋め込み行列を追加して絶対位置符号化を実現すると、行と列に対応する要素は次のように表されます。
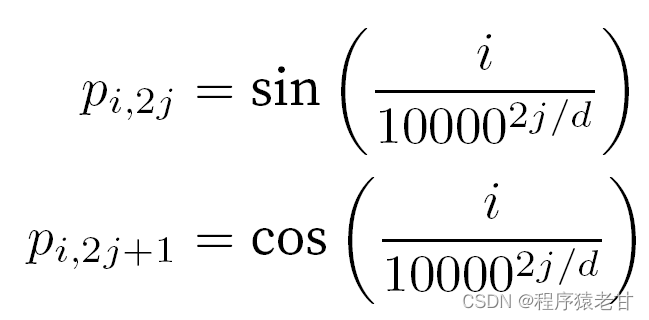
行列要素の位置埋め込みのこの三角法ベースの表現は直感的ではありません。エンコードされた次元と三角関数によって駆動される曲線の頻度との間に関係があることだけがわかっています。つまり、各語彙単位内の異なる次元の情報は、図に示すように、対応する三角関数曲線の異なる頻度を持ちます。
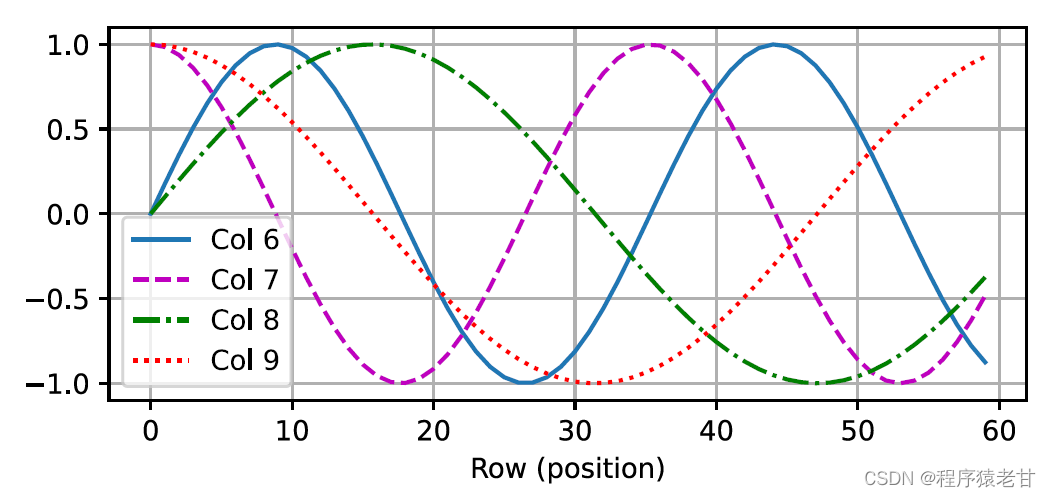
各レンマの次元数が増加するにつれて、その間隔に対応する頻度が減少するようです。この周波数変化と絶対位置の関係を明確にするために、ここでは例を挙げて説明します。これは、0 ~ 7 のバイナリ表現を出力します (周波数ヒートマップは右側にあります)。

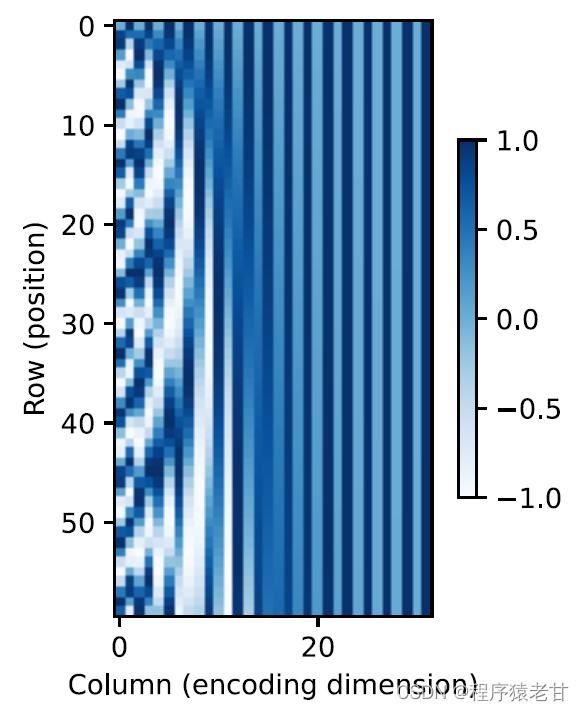
ここで、上位ビットは下位ビットよりも頻繁に交互に入れ替わります。位置エンコーディングを使用することにより、周波数変換に基づく異なる次元の語源のエンコーディングが実現され、次に位置情報の追加が実現されます。相対位置コーディングについては、ここでは詳しく説明しません。
4. 変圧器モデル
いよいよ盛り上がる時が来ました!上記の知識を理解した後、Transformer を学習するための基礎を築きました。入力表現を実現するために依然として循環ニューラル ネットワークに依存している以前の自己注意モデルと比較して、Transformer モデルは、畳み込み層や循環ニューラル ネットワーク層のない自己注意メカニズムに完全に基づいています。
Transformer モデルはコーデック アーキテクチャであり、全体的なアーキテクチャ図は次のとおりです。
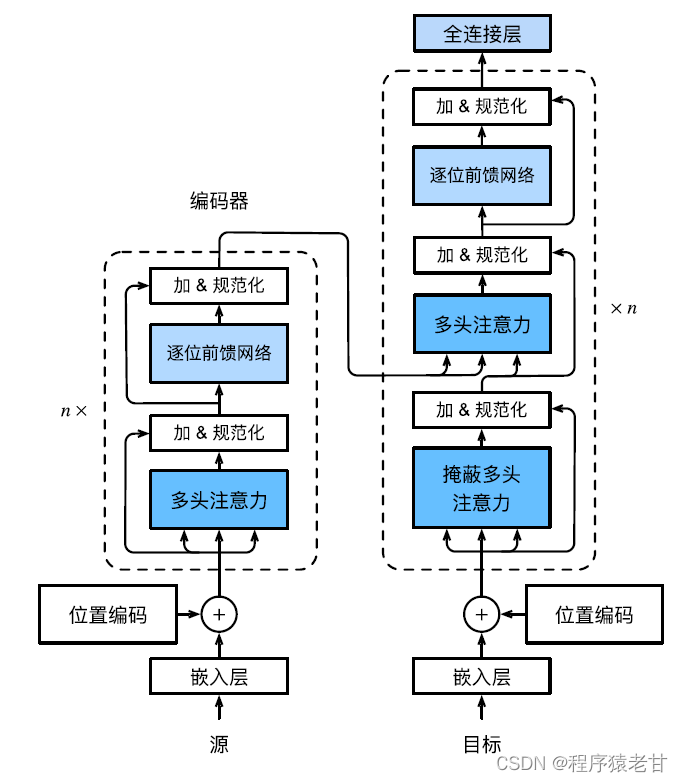
Transformer はエンコーダとデコーダで構成されています. Self-Attention モジュールに基づいて構築されています. ソース (入力) シーケンスとターゲット (出力) シーケンスの埋め込み表現は位置エンコーディングで追加されてから、トランスフォーマに入力されます.それぞれエンコーダーとデコーダー。 エンコーダーは、それぞれが 2 つのサブレイヤーを持つ複数の同じレイヤーを積み重ねることによって構築されます。最初のサブレイヤーはマルチヘッド セルフアテンション プーリングで、2 番目のサブレイヤーは位置ベースのフィードフォワード ネットワークです。エンコーダ層によって計算されたクエリ、キー、および値は、前の層の出力から取得されます。各サブレイヤーは残差接続を使用します。エンコーダーと同様に、デコーダーも複数の同一のレイヤーで構成され、残差接続とレイヤーの正規化を使用します。エンコーダーで記述された 2 つのサブレイヤーに加えて、デコーダーはエンコーダー デコーダー アテンション レイヤーと呼ばれる中間サブレイヤーを追加します。このレイヤーのクエリは前のデコーダーレイヤーの出力から取得され、キーと値はエンコーダー全体の出力から取得されます。デコーダーのセルフアテンションでは、クエリ、キー、および値はすべて、前のデコーダー層の出力から導出されます。デコーダーの各位置は、以前のすべての位置のみを考慮することができます。このマスクされた注意により、自己回帰特性が維持され、予測が生成された出力トークンのみに依存することが保証されます。異なるモジュールの特定の実装については、詳細には説明しません。
注: 上記の用語の説明、原理の紹介、および注意メカニズムに関する公式は、主に Li Mu 先生の教科書 [2] を参照しています。
上記の注意メカニズムの原理に基づいて、点群処理タスクの注意メカニズム深層学習モデルが提案されています。関連作品は次回のブログで詳しく紹介しますので、引き続き当ブログをよろしくお願いいたします。
参照
[1] MH。郭、TX、徐、JJ。劉ら。コンピュータ ビジョンにおける注意メカニズム: 調査[J]。計算ビジュアル メディア、2022 年、8(3): 331-368。
[2] A. Zhang、ZC. Lipton、M. Li、AJ. Smola. Dive into Deep Learning [B]. https://zh-v2.d2l.ai/d2l-zh-pytorch.pdf .
[3] EA。ナダラヤ。回帰の推定について[J]。確率論とその応用、1964、9(1): 141-142。
[4] GS。ワトソン。スムーズな回帰分析。サンキャ: The Indian Journal of Statistics, Series A, pp. 359‒372.
[5] A. Vaswani、N. Shazeer、N. Parmar、他。必要なのは注意だけです。神経情報処理システムの進歩, 2017,5998‒6008.