ガイド
この記事は、2023 年 2 月に開催された QCon グローバル ソフトウェア開発会議 (北京ステーション) での AI インフラストラクチャのトピックに関する同名のトピック共有から編集されています。ChatGPT、Bard、あなたと出会う「Wen Xin Yi Yan」などのアプリケーションは、すべて各メーカーが発売した大型モデルをベースにしています。GPT-3 には 1750 億のパラメーターがあり、Wenxin の大きなモデルには 2600 億のパラメーターがあります。NVIDIA GPU A100 を使用して GPT-3 をトレーニングする例を挙げると、理論的には、1 枚のカードで 32 年かかり、キロカロリー規模の分散クラスターは、さまざまな最適化の後でも、トレーニングを完了するのに 34 日かかります。この講演では、コンピューティング パワー ウォール、ストレージ ウォール、単一マシンおよびクラスタの高性能ネットワーク設計、グラフ アクセスとバックエンド アクセラレーション、モデルの分割とマッピングなど、インフラストラクチャに対する大規模なモデル トレーニングの課題を紹介しました。共有 Baidu インテリジェント クラウドの応答方法とエンジニアリング プラクティスは、フレームワークからクラスターまでのフルスタック インフラストラクチャを構築し、ソフトウェアとハードウェアを組み合わせて、大規模なモデルのエンド ツー エンドのトレーニングを加速しました。
過去 2 年間、ビッグ モデルは AI テクノロジ アーキテクチャに最大の影響を与えてきました。大規模なモデルの生成、反復、進化の過程で、基盤となるインフラストラクチャに新たな課題が生じます。
今日の分かち合いは主に 4 つの部分に分かれています. 最初の部分は、ビジネスの観点から大きなモデルによってもたらされた主な変化を紹介することです. 第 2 部では、大規模モデルの時代に大規模モデルのトレーニングがインフラストラクチャにもたらす課題と、Baidu Smart Cloud がどのように対応するかについて説明します。第 3 部では、大規模モデルとプラットフォーム構築のニーズを組み合わせ、Baidu Smart Cloud によって作成されたソフトウェアとハードウェアの共同最適化について説明します。第 4 部は、大規模モデルの今後の開発とインフラストラクチャの新しい要件に関する Baidu Smart Cloud の考えです。

1. GPT-3が大型モデルの時代を開く
大型モデルの時代は、次の特徴を持つGPT-3によって開かれました。
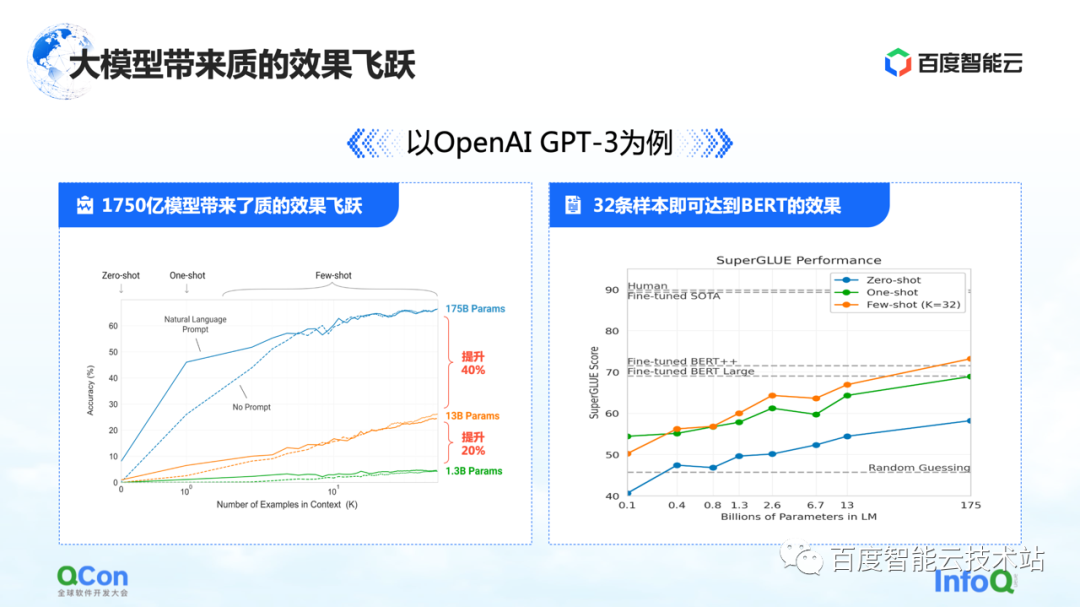
1つ目の特徴は、モデルのパラメータが大幅に改善されたことで、1つのモデルで1,750億パラメータに達し、精度も大幅に向上しました。左の図から、モデル パラメータが増えるにつれて、モデルの精度も向上していることがわかります。
右側の図は、そのさらに衝撃的な機能を示しています。事前にトレーニングされた 1,750 億のパラメーター モデルに基づいており、少数のサンプルでトレーニングするだけで済み、大規模なサンプル トレーニングを使用した後に BERT の効果に近づくことができます。これは、モデルの規模が大きくなることをある程度反映しており、モデルのパフォーマンスとモデルの汎用性の向上をもたらすことができます。
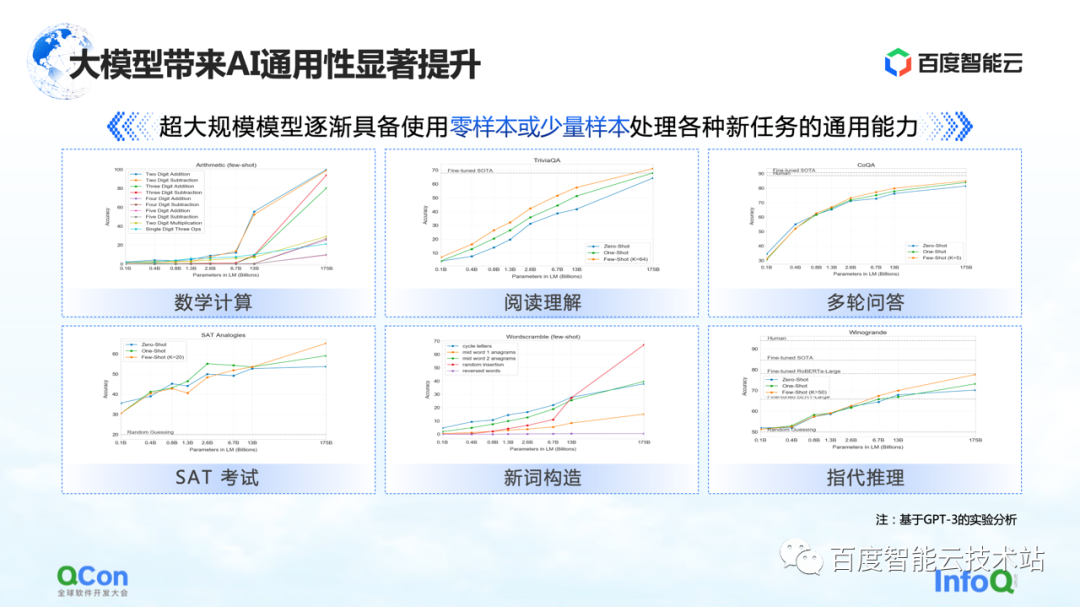
さらに、GPT-3 は、数学的計算、読解、複数回の質疑応答などのタスクにもある程度の汎用性を示しており、サンプル数が少ないだけで、人間の精度に近いモデルをより高い精度で実現できます。 . 使う。
このため、大規模なモデルは、AI の研究開発モデル全体にも新たな変化をもたらしました。将来的には、最初に大規模なモデルを事前トレーニングしてから、特定のタスク用に少数のサンプルで微調整を実行して、優れたトレーニング結果を得ることができます。現在のようにモデルをトレーニングする代わりに、各タスクを完全に反復してゼロからトレーニングする必要があります。
Baidu は非常に早い段階で大規模モデルのトレーニングを開始し、2600 億のパラメーターを持つ Wenxin 大規模モデルが 2021 年にリリースされました。Stable DiffusionやAIGC Vincent graph、最近流行りのチャットロボットChatGPTなど、社会全体の注目を集めている今、大規模モデルの時代が到来したことを誰もが実感しています。
メーカーも大型モデル関連の製品を並べており、Googleは先にBardをリリースしたばかりで、Baiduは3月に「Wen Xin Yi Yan」を発売する予定です。
大規模モデル トレーニングのさまざまな特徴は何ですか?
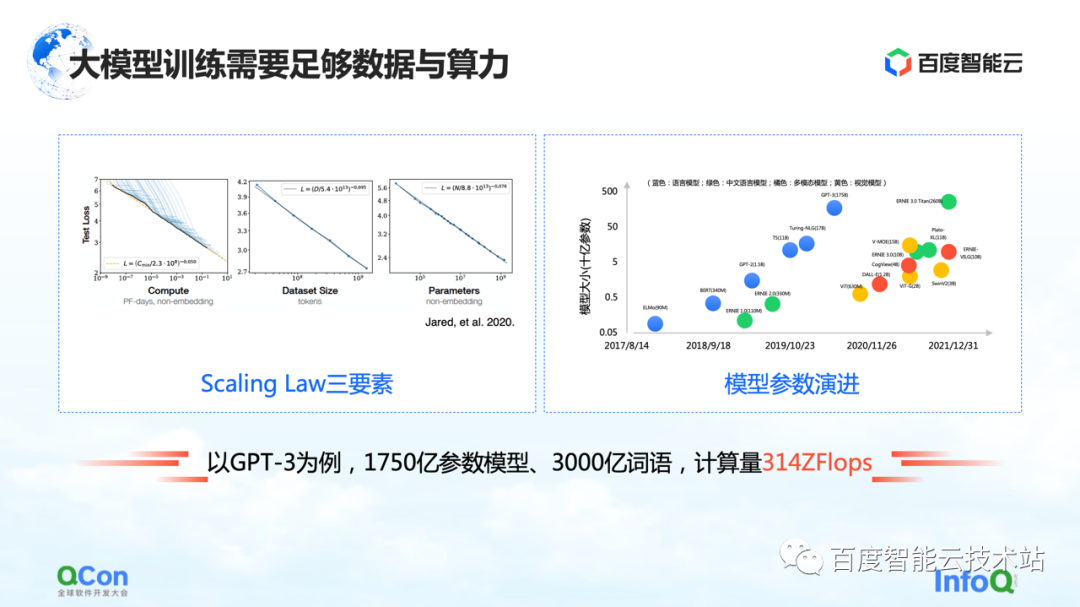
大きなモデルには、左の図のようにスケーリング則があり、モデルのパラメータスケールとトレーニングデータが大きくなるほど、効果はどんどん良くなります。
ただし、ここには前提があります。パラメーターは十分に大きくなければならず、データセットはパラメーター全体のトレーニングをサポートするのに十分です。この結果、計算量が指数関数的に増加します。通常の小型モデルならマシン1台、カード1枚で出来ます。ただし、大規模なモデルの場合、トレーニング ボリュームの要件により、トレーニングをサポートするための大規模なリソースが必要になります。
GPT-3 を例にとると、これは 1,750 億のパラメーターを持つモデルであり、適切な効果を得るためにそれをサポートするために 3,000 億語のトレーニングが必要です。その計算は、論文では 314 ZFLOP と見積もられています。NVIDIA GPU A100 と比較すると、カードはまだ 312 TFLOPS の AI 計算能力にすぎず、中間の絶対値は 9 桁違います。
したがって、大規模なモデルの計算、トレーニング、および進化をより適切にサポートするために、インフラストラクチャをどのように設計および開発するかが非常に重要な問題になっています。
2. 大規模モデル インフラストラクチャ パノラマ
これは、大規模モデル向けの Baidu Smart Cloud インフラストラクチャのパノラマです。ハードウェアとソフトウェアを組み合わせ、フレームワークからクラスタまでをカバーするフルスタックのインフラです。
大規模モデルでは、インフラストラクチャは、基盤となるハードウェアやネットワークなどの従来のインフラストラクチャだけをカバーするものではなくなりました。また、関連するすべてのリソースをインフラストラクチャのカテゴリに含める必要があります。
具体的には、大まかにいくつかのレベルに分けられます。
-
最上位レイヤーはモデル レイヤーであり、内部および外部のパブリッシュされたモデルといくつかのサポート コンポーネントを含みます。たとえば、Baidu のフライング パドル PaddlePaddleと Fleet、Fleet はフライング パドルでの分散戦略です。同時に、PyTorch などのオープン ソース コミュニティには、DeepSpeed/Megatron など、PyTorch フレームワークに基づく大規模なモデル トレーニング フレームワークと高速化機能がいくつかあります。
-
このフレームワークの下で、AI オペレーター アクセラレーション、通信アクセラレーションなど、アクセラレーション ライブラリの関連機能も開発します。
-
以下は、部分的なリソース管理または部分的なクラスター管理に関連する機能の一部です。
-
一番下には、スタンドアロンのシングル カード、異種チップ、ネットワーク関連機能などのハードウェア リソースがあります。
上記はインフラ全体のパノラマです。今日は、AI フレームワークから始めて、アクセラレーション レイヤーとハードウェア レイヤーに拡張して、Baidu Smart Cloud の特定の作業を共有することに焦点を当てます。
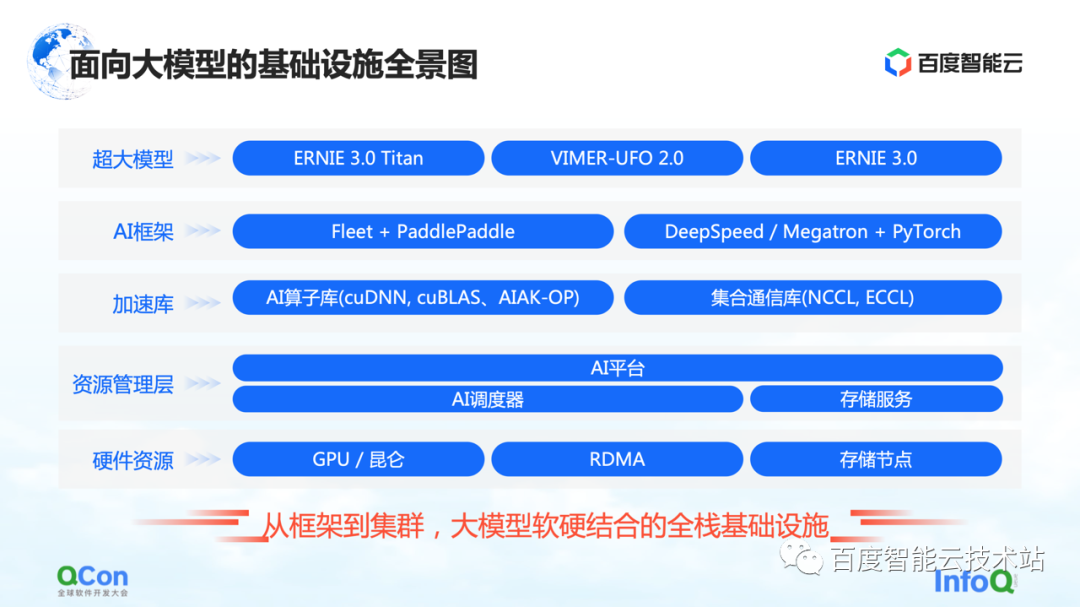
最初に最上位の AI フレームワークから始めます。
1 枚のカードでの従来の小さなモデル トレーニングでは、トレーニング データを使用して順方向勾配と逆方向勾配を継続的に更新することで、トレーニング全体を完了することができます。大規模なモデルのトレーニングには、コンピューティング パワー ウォールとストレージ ウォールという 2 つの主な課題があります。
コンピューティング パワー ウォールとは、314 ZFLOP のコンピューティング パワーを必要とする GPT-3 のモデル トレーニングを完了したい場合に、単一のコンピューティング パワーでは時間がかかりすぎるという問題を解決するために分散方式を使用する方法を指しますが、シングル カードには 314 ZFLOP のコンピューティング パワーしかありません312 TFLOPS の演算能力。結局のところ、1 枚のカードでモデルをトレーニングするには 32 年かかりますが、これは明らかに実現不可能です。
次は収納壁です。これは、大規模なモデルにとってより大きな課題です。1 枚のカードでモデルを保持できない場合、モデルには何らかのセグメンテーション方法が必要です。
たとえば、1000 億レベルの大規模モデル (パラメーター、トレーニング中間値などを含む) のストレージには、2 TB のストレージ スペースが必要ですが、1 枚のカードの最大ビデオ メモリは現在 80 GB しかありません。したがって、大規模なモデルのトレーニングには、1 枚のカードでは収まらないという問題を解決するために、いくつかのセグメンテーション戦略が必要です。
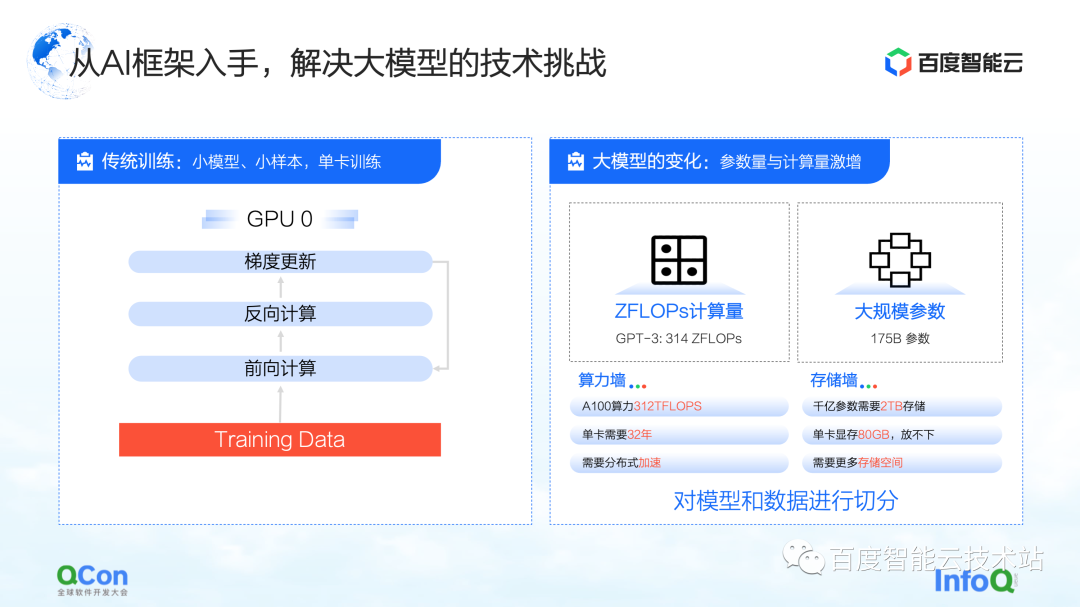
1 つ目はコンピューティング パワー ウォールで、1 枚のカードでは不十分なコンピューティング パワーの問題を解決します。
非常に単純で最もよく知られているアイデアは、トレーニング サンプルを異なるカードに分割するデータ並列処理です。全体として、私たちが観察している大規模なモデルのトレーニング プロセスでは、主に同期データ更新戦略が採用されています。

焦点は、ストレージ ウォールの問題の解決策にあります。鍵となるのは、モデルのセグメンテーションの戦略と方法です。
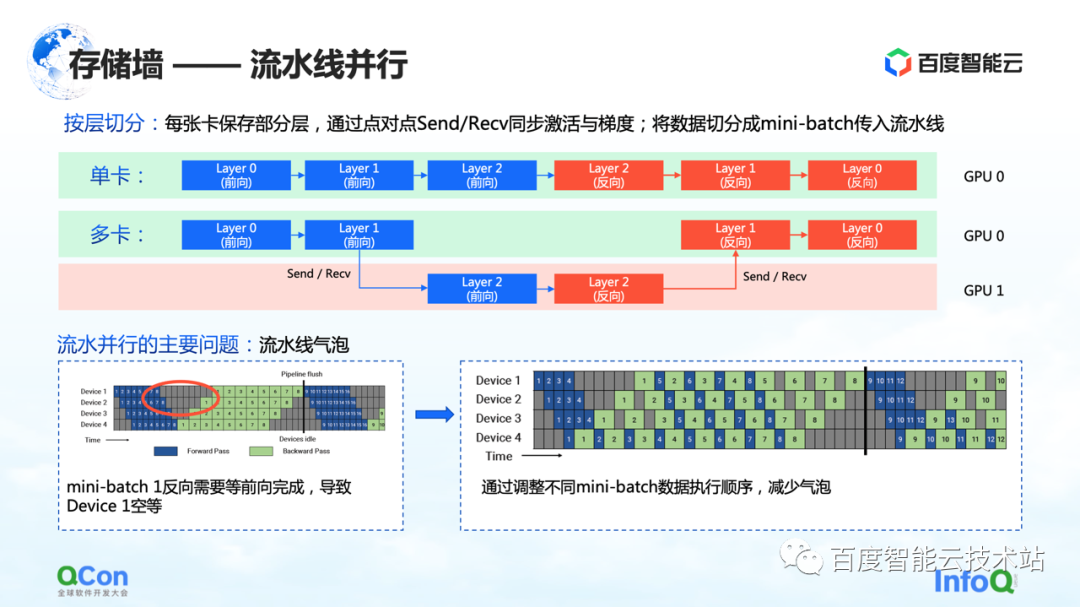
最初のスライス方法は、パイプライン化された並列処理です。
以下の図の例を使用して説明します。モデルの場合、多くのレイヤーで構成されています. トレーニングするときは、最初に順方向に、次に逆方向にトレーニングします。たとえば、図の 0、1、2 の 3 つのレイヤーは 1 枚のカードに収まらないため、レイヤーごとに分割した後、このモデルのいくつかのレイヤーを 1 枚目のカードに配置します。たとえば、下の図では、緑色の領域は GPU 0 を表し、赤色の領域は GPU 1 を表します。最初のいくつかのレイヤーを GPU 0 に配置し、残りのいくつかのレイヤーを GPU 1 に配置できます。データが流れているときは、最初に GPU 0 で 2 回の転送を行い、次に GPU 1 で 1 回の転送と 1 回の逆回しを行い、GPU 0 に戻って 2 回の逆回しを行います。このプロセスは特にパイプラインに似ているため、パイプライン並列処理と呼びます。
しかし、パイプラインの並列処理には大きな問題、つまりパイプライン バブルがあります。データ間に依存関係があり、グラデーションは前のレイヤーの計算に依存するため、データフローの過程で気泡が生成され、空になります。このような問題に対応して、さまざまなミニバッチの実行戦略を調整することで、バブルのエンプティ時間を短縮します。
上記は、この問題を見るアルゴリズムエンジニアまたはフレームワークエンジニアの視点です。インフラストラクチャ エンジニアの観点からは、それがインフラストラクチャにもたらすさまざまな変化についてより懸念しています。
ここでは、その通信セマンティクスに焦点を当てます。これは順方向と逆方向の間にあり、独自のアクティベーション値とグラデーション値を渡す必要があります。これにより、追加の送受信操作が行われます。また、送受信はポイント ツー ポイントです。ソリューションについては、記事の後半で説明します。
上記は、ストレージの壁を破る最初の並列モデル セグメンテーション戦略であるパイプラインの並列処理です。
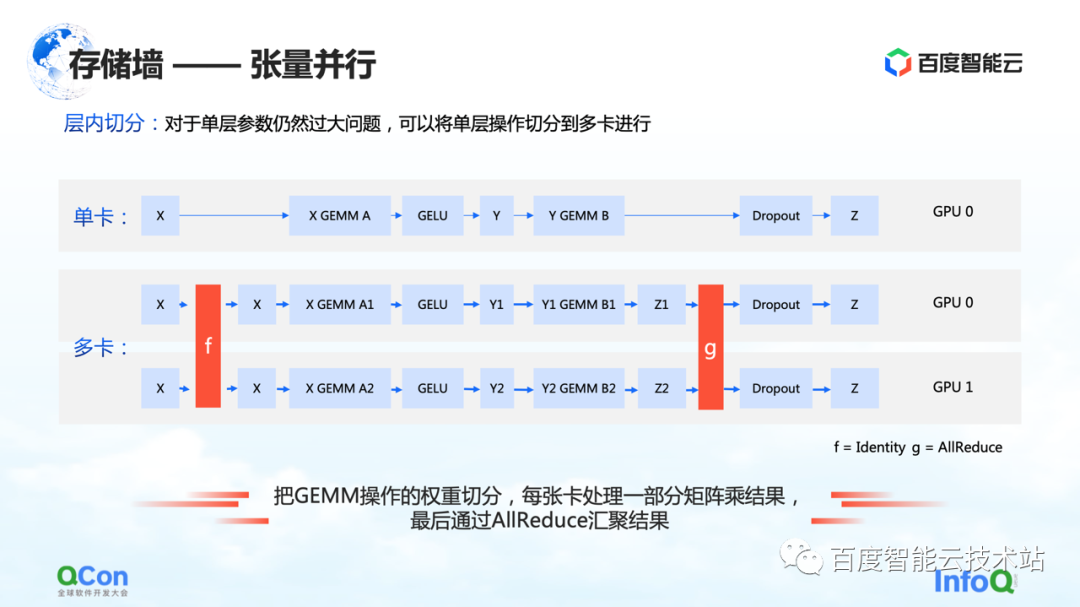
2 番目のセグメンテーション方法は tensor parallelism です。これは、単層パラメーターが大きすぎるという問題を解決します。
モデルには多くの層がありますが、層の 1 つは計算集約的です。現時点では、このレイヤーの計算量は、マシン間またはカード間で共同計算されることを期待しています。アルゴリズム エンジニアの観点から見ると、解決策は、さまざまな入力をいくつかの部分に分割し、異なる部分を使用して部分的な計算を実行し、最後に集計を実行することです。
しかし、インフラエンジニアの観点からは、このプロセスでどのような追加操作が導入されるかにまだ注意を払っています。前述のシナリオでは、追加の操作はグラフの f と g です。f と g は何の略ですか? フォワードを行う場合、f は不変演算であり、x は f を介して透過的に送信され、一部の計算は後で実行できます。ただし、最後に結果を集計する場合は、値全体を渡す必要があります。この場合、g の操作を導入する必要があります。g は AllReduce の操作であり、2 つの異なる値を意味的に集約して、出力 z が両方のカードで同じデータを取得できるようにします。
したがって、インフラストラクチャ エンジニアの観点からは、追加の AllReduce 通信操作が導入されていることがわかります。この操作の通信トラフィックは、その中のパラメータが比較的大きいため、依然として比較的大きいです。記事後半で対処法も紹介します
これは、ストレージの壁を破ることができる 2 番目の最適化方法です。
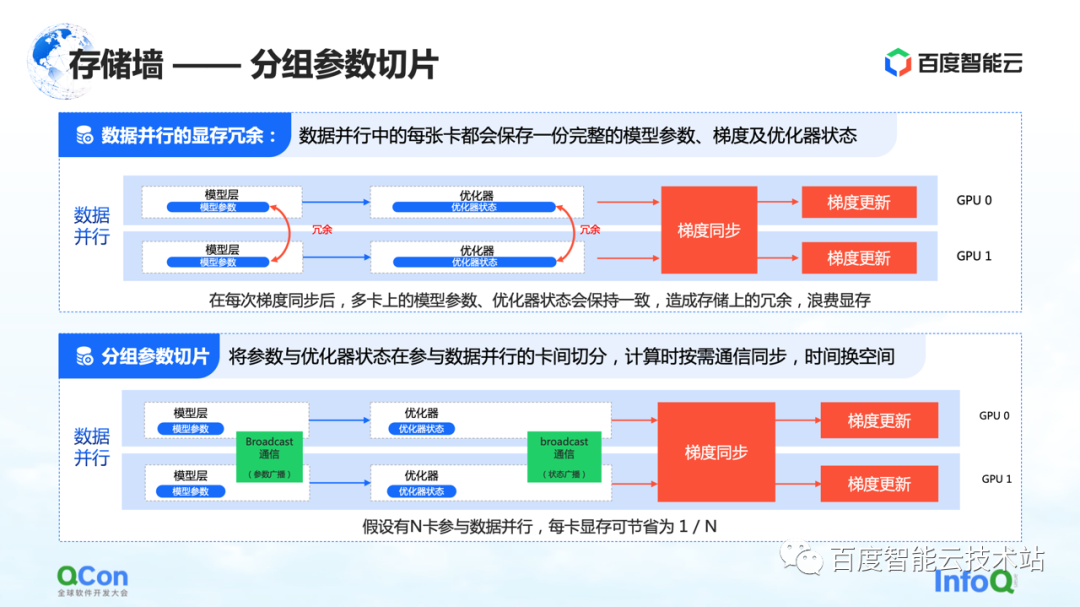
スライスの 3 番目の方法は、グループ化されたパラメーターのスライスです。この方法により、データの並列処理におけるメモリの冗長性がある程度低下します。従来のデータ実行では、各カードには独自のモデル パラメーターとオプティマイザーの状態があります。これらはそれぞれのトレーニング プロセス中に同期および更新する必要があるため、これらの状態は別のカードに完全にバックアップされます。
上記のプロセスでは、実際には、同じデータとパラメーターが異なるカードに重複して保存されます。大規模なモデルには非常に高いストレージ容量が必要なため、このような冗長ストレージは受け入れられません。この問題を解決するために、モデル パラメーターを分割し、各カードのパラメーターの一部のみを保持します。
計算が本当に必要な場合は、時間とスペースを交換します。最初にパラメーターを同期し、計算が完了したら冗長データを破棄します。このようにして、ビデオ メモリの需要をさらに圧縮することができ、既存のマシンでトレーニングをより適切に実行できます。
同様に、インフラエンジニアの観点からは、ブロードキャストなどの通信操作を導入する必要があり、通信内容はこれらのオプティマイザーの状態とモデルのパラメーターです。
上記は、ストレージの壁を破る 3 つ目の最適化方法です。
上記のメモリ最適化方法と戦略に加えて、モデルの計算量を削減する別の方法があります。
データ量が十分に大きい場合、モデルのパラメーターが多いほど、モデルの精度が向上します。ただし、パラメータが増えると計算量も増え、より多くのリソースが必要になると同時に、計算時間も長くなります。
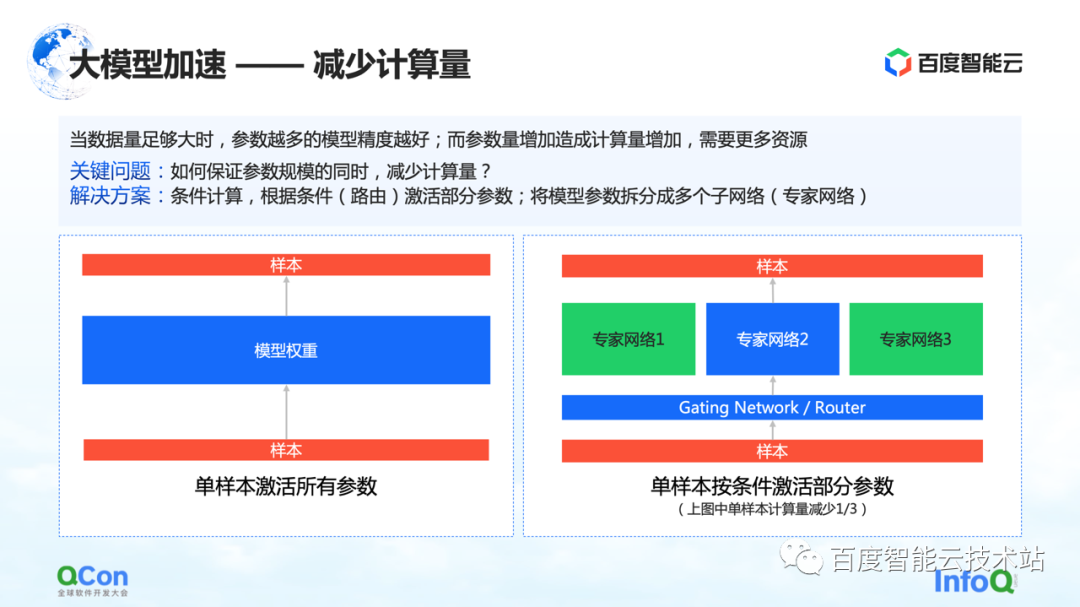
では、パラメータ スケールを変更せずに計算量を削減するにはどうすればよいでしょうか。解決策の 1 つが条件付きコンピューティングです。特定の条件 (つまり、右図のゲーティング層、またはルーティング層と呼ばれます) に従って、いくつかのパラメーターを選択してアクティブにします。
たとえば、右の図では、パラメーターを 3 つの部分に分割し、モデルの条件に応じて、一部のパラメーターのみをエキスパート ネットワーク 2 での計算のためにアクティブにします。エキスパート 1 とエキスパート 3 の一部のパラメータは計算されません。これにより、パラメータ規模を確保しつつ計算量を削減することができる。
以上が条件付き計算による計算量削減の方法です。
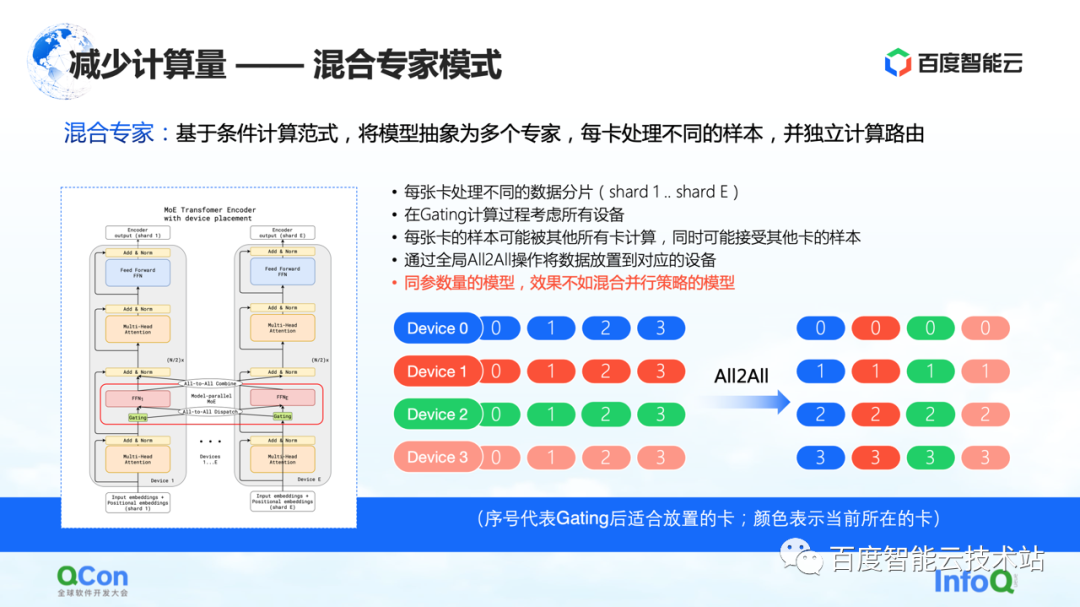
上記の方法に基づいて、業界はモデルを複数の専門家に抽象化する混合専門家モデルを提案し、各カードは異なるサンプルを処理します。具体的には、いくつかのルーティングの選択肢がモデル レイヤーに挿入され、この選択に従って一部のパラメーターのみがアクティブになります。同時に、さまざまなエキスパートのパラメーターがさまざまなカードに保持されます。このように、サンプル配布の過程で、それらは計算のために異なるカードに割り当てられます。
しかし、インフラエンジニアの視点から見ると、このプロセスで All2All 操作が導入されていることがわかりました。下の右図のように、0、1、2、3 などのサンプルが複数の Device に格納されます。デバイスの値は、どのカードが計算に適しているか、またはどのエキスパートが計算に適しているかを示します。たとえば、0 は 0 番の専門家、つまり 0 番のカードで計算するのに適していることを意味します。それぞれのカードは、格納されたデータを計算するのに適しているかどうかを判断し、たとえば、カード No.1 は、一部のパラメータは No.0 カードで計算するのに適していると判断し、他のパラメータは No.1 カードで計算するのに適していると判断します。次に、サンプルを別のカードに配布します。
上記の操作の後、No.0 カードのサンプルはすべて 0 であり、No.1 カードのサンプルはすべて 1 です。以上の処理を通信では All2All と呼びます。インフラストラクチャ エンジニアの観点から見ると、この操作は比較的重い操作であり、これに基づいて関連する最適化を行う必要があります。また、次のテキストでさらに紹介します。
このモードで観察された現象の 1 つは、混合エキスパート モードを使用すると、そのトレーニング精度が、同じパラメーターのモデルの下で今説明したさまざまな並列戦略やハイブリッド重ね合わせ戦略ほど良くないということです。実際の状況に。
いくつかの並行戦略を紹介したので、Baidu Smart Cloud の内部プラクティスを共有します。
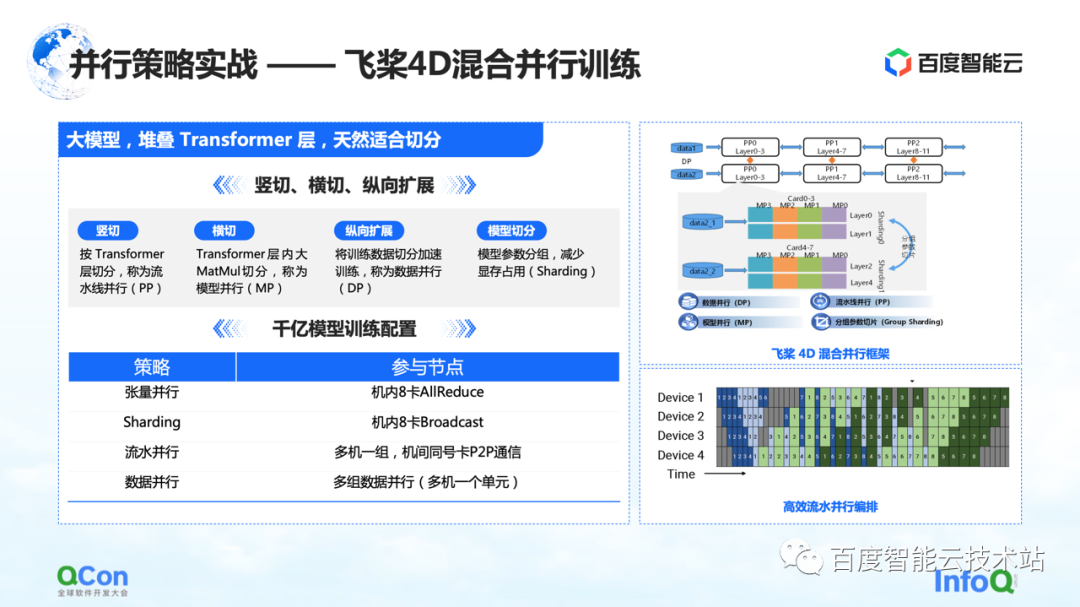
Paddleを使用して 2600 億のパラメーターを持つ大規模なモデルをトレーニングし、最適化された Transformer クラスのいくつかのレイヤーを積み重ねました。水平方向と垂直方向にスライスできます. たとえば、パイプライン並列戦略を使用して、Transformer レイヤーに従ってモデルを垂直方向にスライスします。分野横断とは、モデル並列戦略/テンソル並列戦略を使用して、Transformer 内の MetaMul などの大規模な行列乗算の計算を分割することです。同時に、データ並列処理の垂直方向の最適化と、データ並列処理におけるグループ化モデルのパラメーター分割のビデオ メモリの最適化を追加しました。上記の4つの方法を通じて、フライングパドルの4Dハイブリッド並列トレーニングのフレームワークを導入しました。
1000 億のパラメーター モデルのトレーニング構成では、マシンで 8 枚のカードを使用してテンソルの並列処理を行い、同時にデータの並列処理と連携してグループ化パラメーターのセグメンテーション操作を実行します。同時に、複数のマシン グループを使用して並列パイプラインを形成し、2,600 億のモデル パラメータを伝送します。最後に、分散コンピューティングにデータ並列方式を使用して、モデルの月次トレーニングを完了します。
上記は、モデル並列パラメーター モデル並列戦略全体の実際の戦闘です。
次に、インフラストラクチャの観点に戻って、モデル トレーニングにおけるさまざまなセグメンテーション戦略の通信および計算能力の要件を評価します。
表に示すように、1000億個のパラメータの規模に応じて、さまざまなセグメンテーション方法に必要な通信トラフィックと計算時間をリストします。トレーニングプロセス全体の観点からは、計算プロセスと通信プロセスを完全にカバーまたはオーバーラップできることが最大の効果です。
この表から、クラスター、ハードウェア、ネットワーク、および全体的な通信モードの 1000 億パラメーター モデルの要件を推測できます。推定 1,750 億のパラメーターを 1,024 枚の A100 カードで 3,000 億語を使用してトレーニングしたモデルに基づくと、完全なエンドツーエンドのトレーニングを完了するには 34 日かかります。
以上がハード面での当方の評価です。
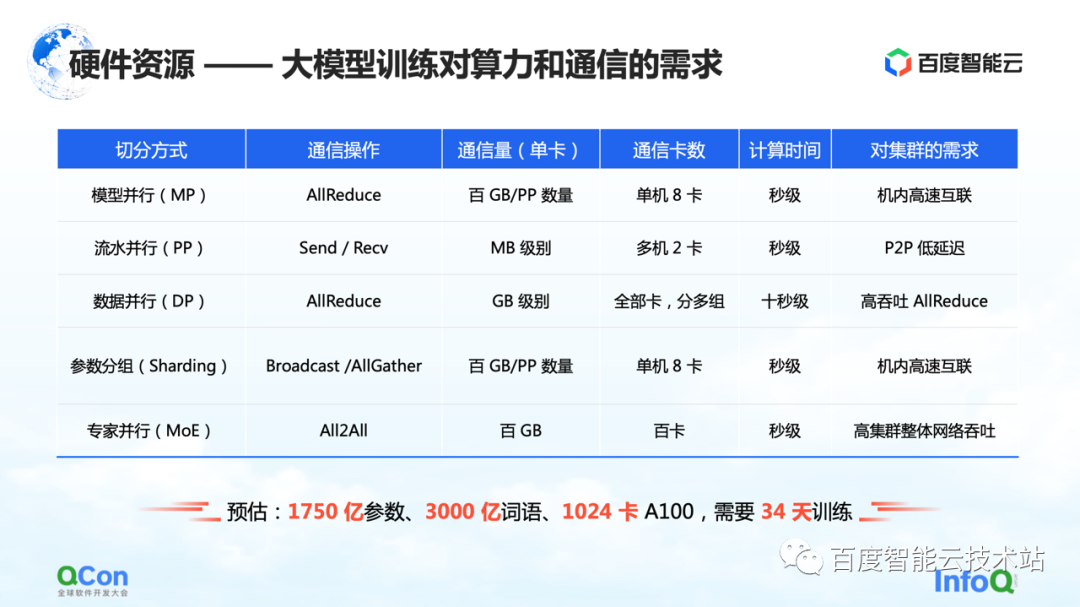
ハードウェア要件に基づいて、次のステップはスタンドアロン レベルとネットワーク レベルの選択です。
スタンドアロン レベルでは、多数の AllReduce およびブロードキャスト操作をマシンで実行する必要があるため、マシンが高性能で高帯域幅の接続をサポートできることを願っています。そこで、当時の機種選定では最新鋭のA100 80Gパッケージを採用し、A100を8台使用して1機を構成しました。
また、外部ネットワークの接続方法で最も重要なのはトポロジ接続方法です。ネットワーク カードと GPU カードが可能な限り同じ PCIe スイッチの下にあり、トレーニング プロセス全体でのカード間の相互作用のスループット ボトルネックが、対称的な方法でより適切に削減されることを願っています。同時に、それらが CPU の PCIe ルート ポートを通過しないようにしてください。
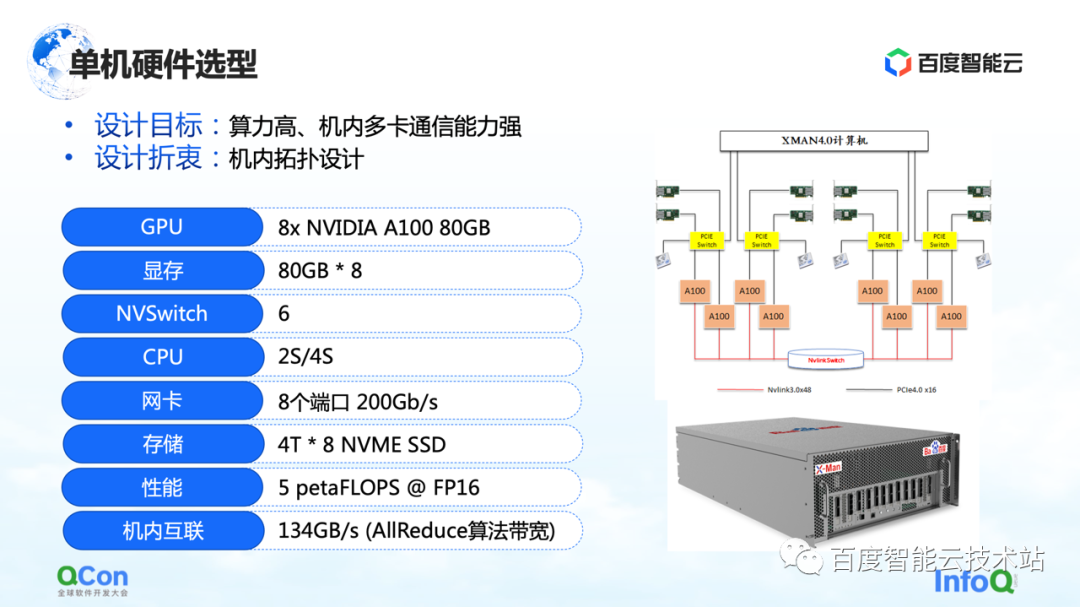
スタンドアロンについて説明した後、クラスタ ネットワークの設計を見てみましょう。
まず、要件を評価してみましょう. ビジネス上の期待がエンド ツー エンドのモデル トレーニングを 1 か月以内に完了することである場合、単一ジョブ トレーニングでキロカロリー レベルに到達し、大型モデルで 10,000 カロリー レベルに到達する必要があります。トレーニング クラスター。したがって、ネットワーク設計のプロセスでは、次の 2 つの点を考慮する必要があります。
まず、パイプラインで送受信のポイント ツー ポイント動作を満たすためには、P2P 遅延を減らす必要があります。
2 つ目は、AI トレーニングのネットワーク側のトラフィックが同じカードの AllReduce 操作に集中するため、通信スループットが高いことも期待できます。
このコミュニケーションの必要性のために。右に示す 3 層 CLOS アーキテクチャのトポロジを設計しました。従来の方法と比較して、このトポロジーで最も重要なことは、8 つのガイド レールを最適化することです。これにより、異なるマシンで同じ番号を持つカードの通信におけるジャンプの数が可能な限り少なくなります。
CLOS アーキテクチャでは、最下層は Unit です。各ユニットには 20 台のマシンがあり、各マシンの同じ番号の GPU カードを、対応する番号の同じグループの TOR に接続します。このように、1 つのユニット内のすべての同じ番号のカードが 1 つのホップのみで通信を完了できるため、同じ番号のカード間の通信が大幅に改善されます。
ただし、1 つのユニットに合計 160 枚のカードを備えた 20 台のマシンしかなく、大規模なモデルのトレーニングの要件を満たすことができません。そこで、2 層目の Leaf 層を設計しました。リーフ層は、異なるユニットの同じ番号のカードを同じリーフ グループのスイッチング デバイスに接続します。これにより、同じ番号のカードを相互接続する問題は解決されます。このレイヤーを介して、20 台のユニットを再び相互接続できます。これまでに、400 台のマシンと合計 3200 枚のカードを接続できました。このような 3200 カード クラスタの場合、同じ番号の任意の 2 つのカード間の通信は、最大 3 ホップまでホッピングすることで実現できます。
異なる番号のカードの通信をサポートしたい場合はどうすればよいでしょうか? 異なる番号を持つカード間の通信の問題を解決するために、上部に Spine レイヤーを追加しました。
この 3 層アーキテクチャにより、AllReduce 操作に最適化された 3200 枚のカードをサポートする全体的なアーキテクチャを実現しました。IBのネットワーク機器上であれば16000枚の規模に対応できるアーキテクチャであり、IBボックス型ネットワークとしては現時点で最大規模です。
CLOS アーキテクチャを、Dragonfly、Torus などの他のネットワーク アーキテクチャと比較しました。それらと比較して、このアーキテクチャのネットワーク帯域幅はより十分であり、ノード間のホップ数はより安定しているため、予測可能なトレーニング パフォーマンスを見積もるのに非常に役立ちます。
以上がスタンドアロンからクラスタネットワークまでの構築案です。

3. ソフトウェアとハードウェアの組み合わせの共同最適化
大規模なモデル トレーニングは、ハードウェアを購入してそこに置いてトレーニングを完了することを意味するものではありません。また、ハードウェアとソフトウェアの共同最適化も必要です。
まず、計算の最適化について話しましょう。大規模なモデルのトレーニングは、依然として全体として計算集約的なプロセスです。コンピューティングの最適化に関しては、現在のアイデアやアイデアの多くは、静的グラフのマルチバックエンド アクセラレーションに基づいています。Paddle、PyTorch、TensorFlow のいずれであっても、ユーザーによって作成されたグラフは、まずグラフ キャプチャによって動的グラフを静的グラフに変換し、次に静的グラフをバックエンドに入れて高速化します。
以下の図は、静的グラフベースのマルチバックエンド アーキテクチャ全体を示しており、次の部分に分割されています**。**
1 つ目は、動的グラフを静的グラフに変換するグラフ アクセスです。
2 つ目はマルチバックエンド アクセス方式で、さまざまなバックエンドを通じてタイミング ベースの最適化機能を提供します。
3 つ目はグラフの最適化で、計算効率をさらに向上させるために、静的グラフの計算の最適化とグラフ変換を行いました。
最後に、いくつかのカスタム オペレーターを使用して、大規模なモデルのトレーニング プロセス全体を高速化します。
以下、分けて紹介しよう。

大規模モデルのトレーニング アーキテクチャでは、最初の部分はグラフ アクセスです。AIフレームワークでグラフを記述する場合、通常、静的グラフと動的グラフに分けられます。
静的グラフとは、ユーザーがグラフを実行する前にグラフを作成し、実際の入力と組み合わせて実行することです。このような特性と組み合わせると、計算プロセス中に事前にコンパイルの最適化またはスケジューリングの最適化を行うことができ、トレーニングのパフォーマンスを向上させることができます。
しかし、それに対応するのは動的グラフの構築プロセスです。ユーザーは何気なくコードを書き、それは書き込みプロセス中に動的に実行されます。たとえば、PyTorch は、ユーザーがステートメントを記述した後、関連する実行と評価を実行します。ユーザーにとって、このアプローチの利点は、開発とデバッグが容易なことです。しかし、エグゼキューターまたは加速プロセスについては、それが見られるたびに操作の小さな部分であるため、あまり最適化されていません。
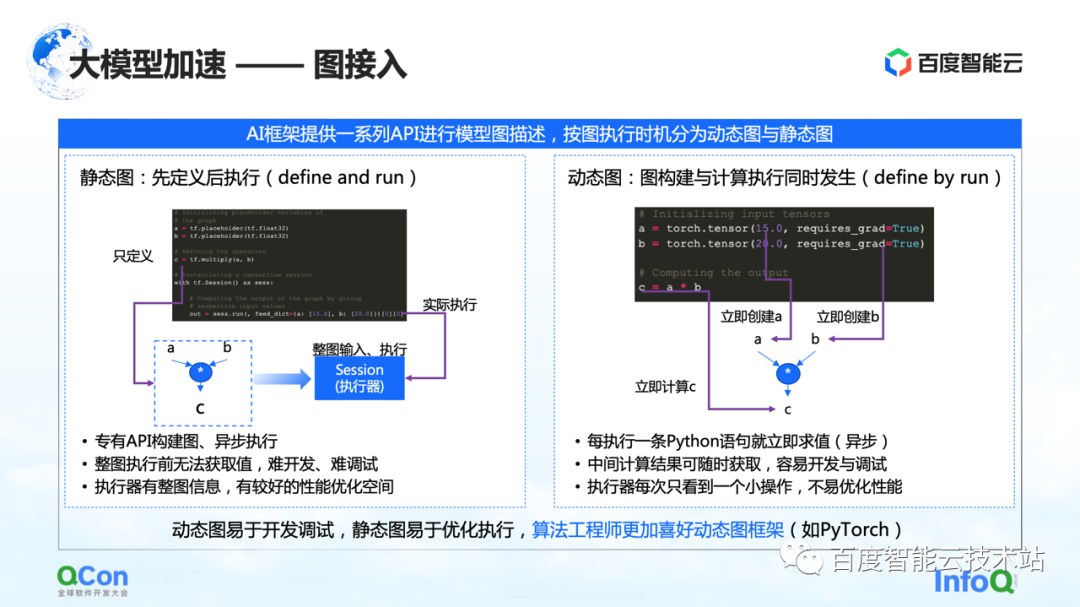
この問題を解決するには、動的グラフと静的グラフを統合し、動的グラフを使用して開発し、静的グラフを介して実行するというのが一般的な考え方です。私たちが現在目にしている実装には、主に 2 つのパスがあります。
1 つ目は、Python AST に基づいて静的変換を行うことです。たとえば、ユーザーが作成した Python ソース コードを取得し、それを Python AST ツリーに変換し、AST ツリーに基づいて CodeGen を実行します。この過程で静的群グラフのメソッドとAPIを利用して、Pythonの動的ソースコードを静的グラフに変換することができます。
しかし、このプロセスでは、Python 言語の柔軟性が最大の問題であり、静的解析ではセマンティクスを十分に理解できず、動的画像から静的画像への変換に失敗します。たとえば、静的解析のプロセスでは、動的な型を推測する方法がなく、たとえば、静的解析では範囲の範囲を推測できないため、実際の変換プロセスで頻繁に失敗します。そのため、静的変換はいくつかの単純なモデル シナリオにのみ適用できます。
2 番目のルートは、トレースまたはシンボリック トレースを使用して簡単な実行とシミュレーションを行うことです。Tracer は、記録プロセス中に遭遇したいくつかの計算ノードを記録します. これらの計算ノードを記録した後、再生または再編成を通じて事後的に静的グラフ全体を構築します. この方法の利点は、いくつかの入力メソッドをシミュレートするか、特別な構造メソッドを構築することによって、全体的な動的グラフをキャプチャして計算し、パスをよりうまくキャプチャできることです。
しかし、実際には、このプロセスにはいくつかの問題があります。入力に依存する分岐またはループ構造の場合、Tracer はシミュレートされた入力を構築することによって静的グラフを構築するため、Tracer は一部の分岐にのみ移動し、セキュリティ上の問題につながります。
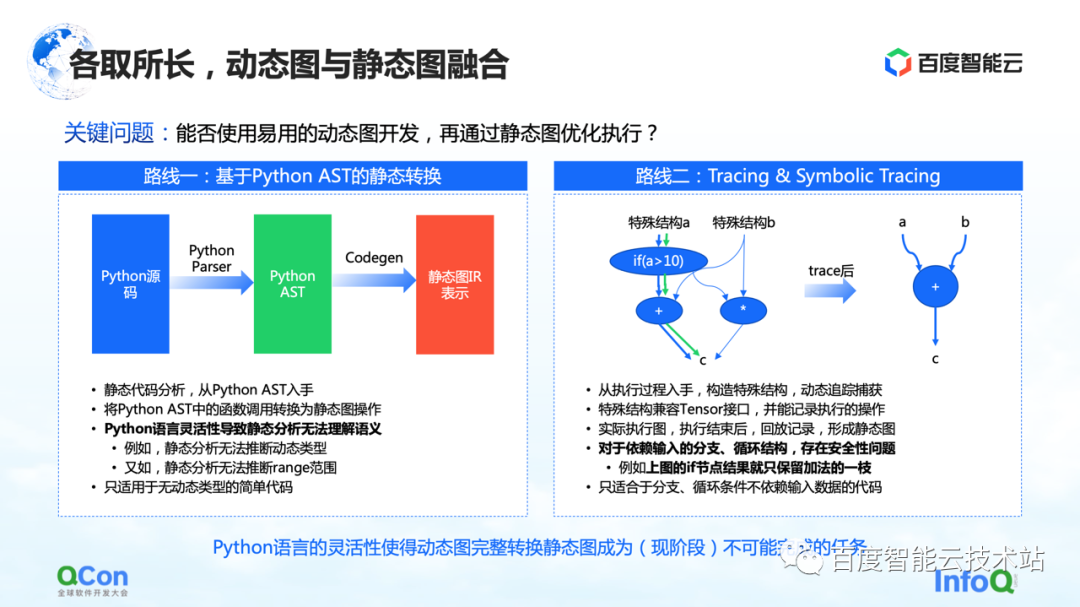
これらの方法を比較した結果、Python の既存の言語の柔軟性の下では、この段階で動的グラフから静的グラフへの変換を完了することは基本的に不可能な作業であることがわかりました。したがって、私たちの焦点は、クラウド上でより安全で使いやすい画像変換機能をユーザーに提供する方法に移っています。この段階では、次のようないくつかのオプションがあります。
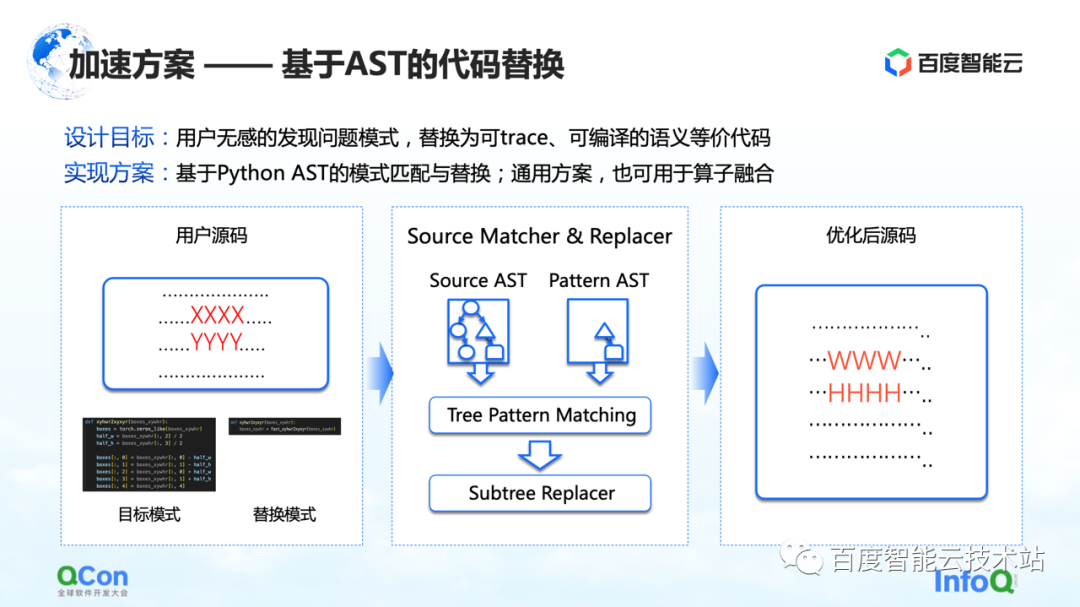
最初の解決策は、AST コード置換に基づく方法を開発することです。この方法では、Baidu Smart Cloud は、対応するモデル変換および最適化機能を提供します。これは、ユーザーには影響されません。たとえば、ユーザーがソース コードの一部を入力しますが、コードの一部 (図の XXXX と YYYY で示されている部分) は、静止画像のキャプチャ、グラフの最適化、およびオペレーターの最適化の過程にあることがわかりました。コードが動的グラフを静的グラフに変換できないか、コードにパフォーマンス最適化の余地があります。次に、中央の図に示すように、置換コードを記述します。左側は置き換え可能と思われる Python コードの一部で、右側は置き換えた別の Python コードです。次に、AST マッチング メソッドを使用して、ユーザーの入力と元のターゲット パターンを AST に変換し、サブツリー ツリー マッチング アルゴリズムを実行します。
このように、元の入力 XXXX、YYYY を WWWW、HHHH に変更し、より実行可能なソリューションに変えることができます。これにより、動的画像を静的画像に変換する成功率がある程度向上し、パフォーマンスが向上します。オペレータと同時に. パフォーマンス, そして、ユーザーが基本的に鈍感であるという効果を達成することができます.
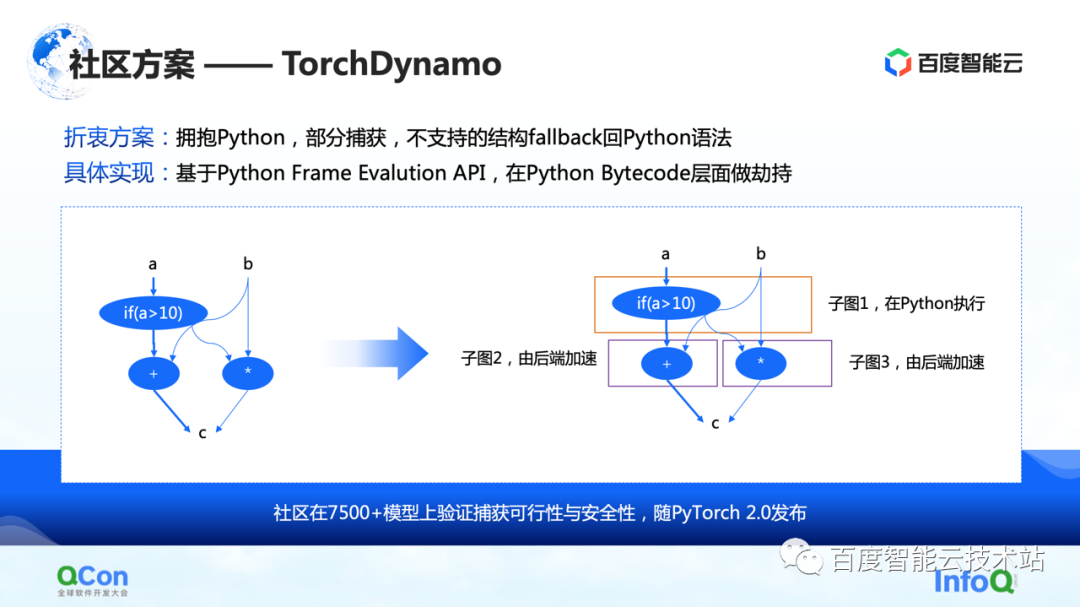
2 つ目は、コミュニティのいくつかのソリューション、特に PyTorch 2.0 によって提案された TorchDynamo ソリューションです。これは、これまで見てきたソリューションであり、計算の最適化により適しています。部分的なグラフ キャプチャを実現でき、サポートされていない構造は Python にフォールバックできます。このようにして、一部のサブグラフをバックエンドにある程度吐き出すことができ、バックエンドはこれらのサブグラフの計算をさらに高速化できます。
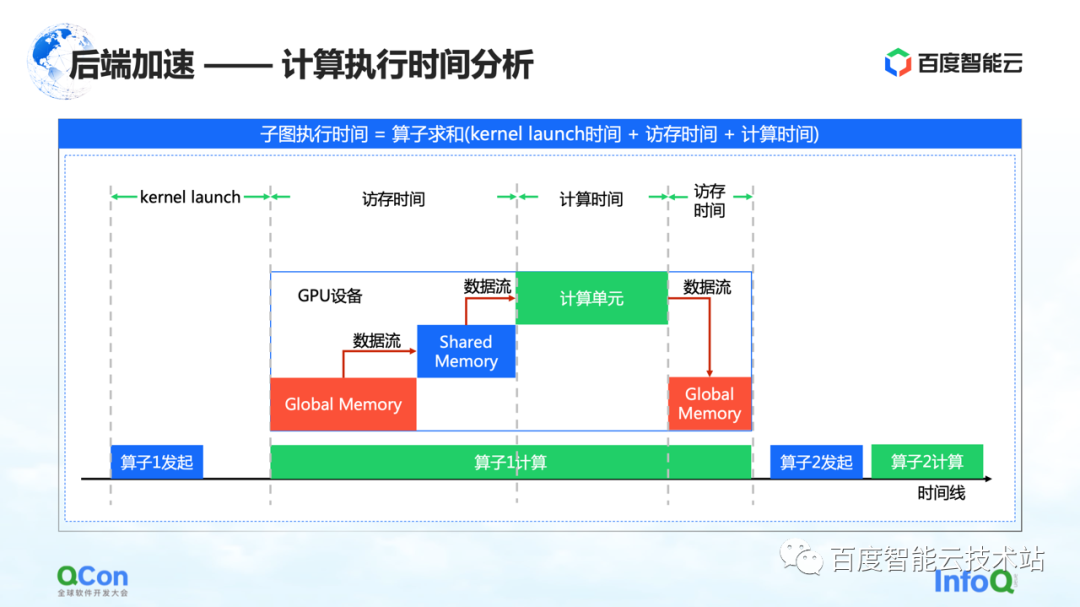
グラフ全体をキャプチャしたら、次のステップは実際に加速、つまりバックエンド加速の計算を開始することです。
GPU コンピューティングのタイミング ダイアグラムのキー ポイントは、メモリ アクセス時間と計算時間であると考えています。今回は以下の角度から加速します。
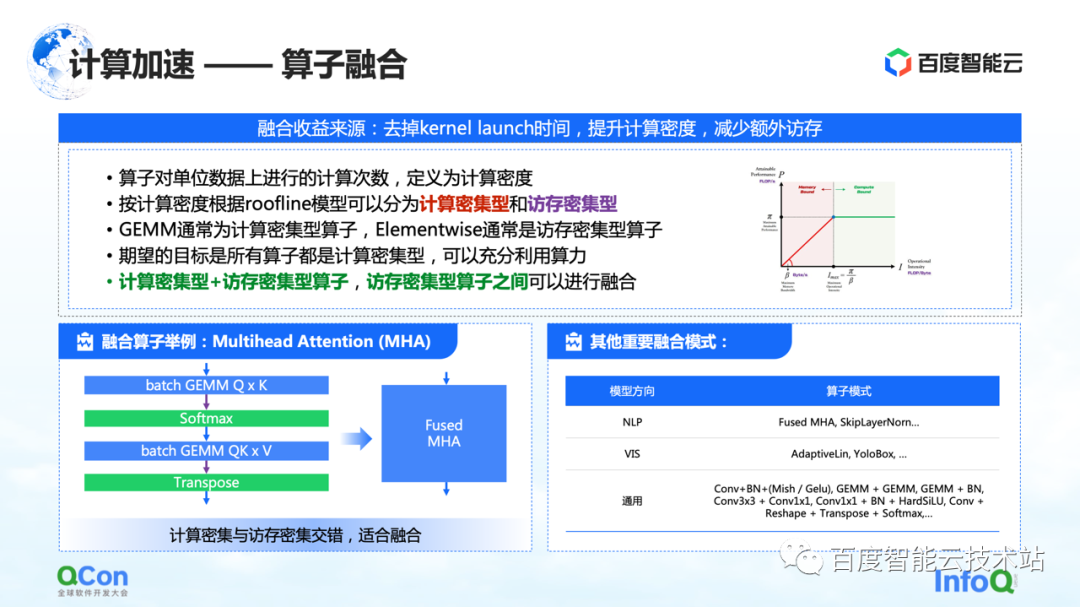
1つ目はオペレーターフュージョンです。オペレーター フュージョンの主な利点は、カーネルの起動にかかる時間を短縮し、計算密度を高め、追加のメモリ アクセスを減らすことです。演算子の単位メモリ アクセスあたりの計算回数を計算密度と定義します。
計算密度の違いに応じて、オペレーターを計算集約型とメモリ集約型の 2 つのタイプに分類します。たとえば、GEMM は典型的な計算集約型の演算子であり、Elementwise は典型的なメモリ集約型の演算子です。「計算集約型オペレータ+メモリ集約型オペレータ」と「メモリ集約型オペレータ+メモリ集約型オペレータ」をうまく融合できることがわかりました。
私たちの目標は、GPU で実行されるすべての演算子を部分的に計算集約型の演算子に変換して、計算能力を最大限に活用できるようにすることです。
左側は私たちの例です.例えば、トランスフォーマー構造では、最も重要なマルチヘッドアテンションがうまく融合することができます. 同時に、右側にいくつかのモデルが見つかりましたが、スペースの制限により、それらを 1 つずつリストすることはできません。
コンピューティングの最適化のもう 1 つのタイプは、演算子の実装の最適化です。
オペレーター実装の本質的な問題は、コンピューティング ロジックとチップ アーキテクチャをどのように組み合わせて、コンピューティング プロセス全体をより適切に実現するかということです。現在、次の 3 種類のシナリオが見られます。
最初のカテゴリは手書きの演算子です。関連するメーカーは、cuBLAS や cuDNN などのオペレーター ライブラリを提供します。提供されるオペレーターのパフォーマンスは最高ですが、サポートされる操作は限定されており、カスタム開発のサポートは比較的貧弱です。
2 番目のカテゴリは、CUTLASS などの半自動テンプレートです。このメソッドは、オープン ソースの抽象化を作成し、開発者が二次開発を行えるようにします。これは、計算集約型とメモリ集約型の演算子の融合を達成するために現在使用している方法でもあります。
3 つ目は、検索ベースの最適化です。コミュニティで、Halide や TVM などのいくつかのコンパイル方法に注意を払いました。現時点では、この方法は一部のオペレーターで有効であることがわかっていますが、他のオペレーターではさらに磨きをかける必要があります。
実際には、これら 3 つの方法には独自の利点があるため、タイミングの選択を通じて最適な実装を提供します。

コンピューティングの最適化について話した後、通信を最適化するいくつかの方法を共有しましょう。
1 つ目は、スイッチ ハッシュの衝突問題の解決です。下の図は私たちが行った実験で、32 カードのタスクを設定し、毎回 30 回の AllReduce 操作を実行しました。下図は通信帯域を計測したもので、速度が遅くなる確率が高いことがわかります。これは、大規模なモデルのトレーニングでは深刻な問題です。
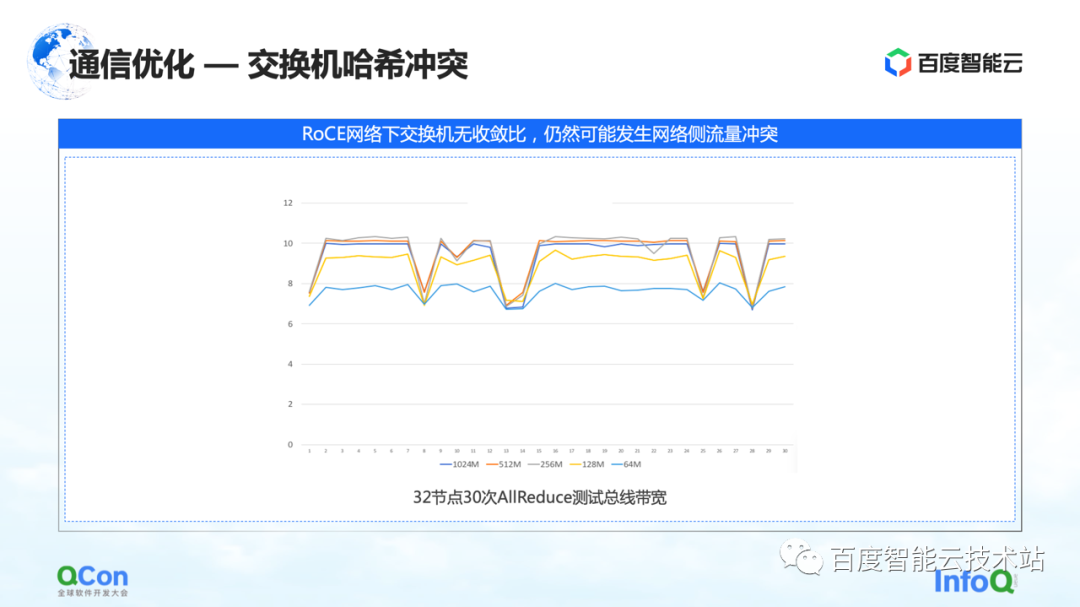
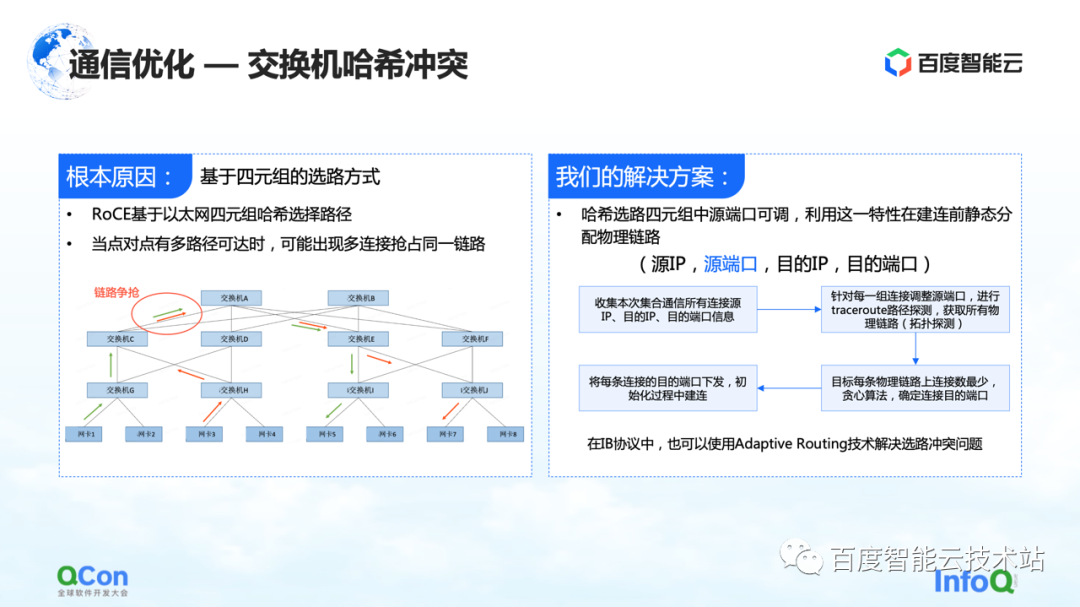
スローダウンの理由は、ハッシュの衝突によるものです。ネットワーク設計では、スイッチには収束率がありません。つまり、ネットワーク設計の帯域幅リソースは十分ですが、イーサネット 4 重ルーティングに基づく方法である RoCE を使用しているため、ネットワーク側でトラフィックの競合が発生する可能性があります。発生します。
例えば、下の図の例では、緑のマシン同士が通信する必要があり、赤のマシン同士も通信する必要がある場合、ルート選択プロセス中に全員の通信が同じ帯域幅を求めて競合します。全体的なネットワーク帯域幅は十分ですが、ローカル ネットワークのホットスポットが形成されるため、通信パフォーマンスが低下します。
私たちのソリューションは、実際には非常に単純です。通信プロセス全体では、送信元 IP、送信元ポート、宛先 IP、および宛先ポートの 4 つのタプルがあります。送信元 IP、宛先 IP、および宛先ポートは固定されていますが、送信元ポートは調整できます。この機能を利用して、送信元ポートを継続的に調整してさまざまなパスを選択し、全体的な貪欲なアルゴリズムを使用してハッシュ衝突の発生を最小限に抑えます。
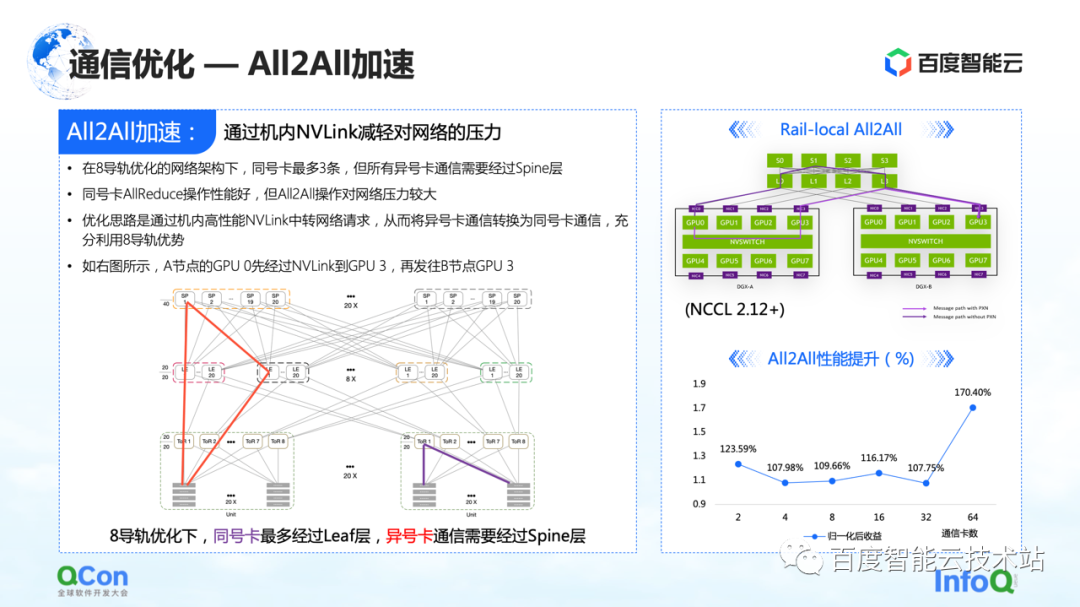
通信の最適化では、前述の AllReduce のいくつかの最適化に加えて、All2All、特に 8 レール用に特別にカスタマイズされたネットワークにも最適化の余地があります。
このネットワークは、All2All 全体の運用において上位層のスパイン スイッチに大きな圧力をかけます。最適化方法は、NCCL の Rail-Local All2All、または PXN の最適化を使用することです。原理は、異なる番号のカード間の通信を、マシン内の高性能な NVLink によって同じ番号のカード間の通信に変換することです。
このように、元々スパイン層まで行っていたマシン間のネットワーク通信をすべてマシン内通信に変換することで、TOR層またはリーフ層の通信だけで異なる番号のカードの通信を実現し、パフォーマンスも改善されます. 大きな改善があります.
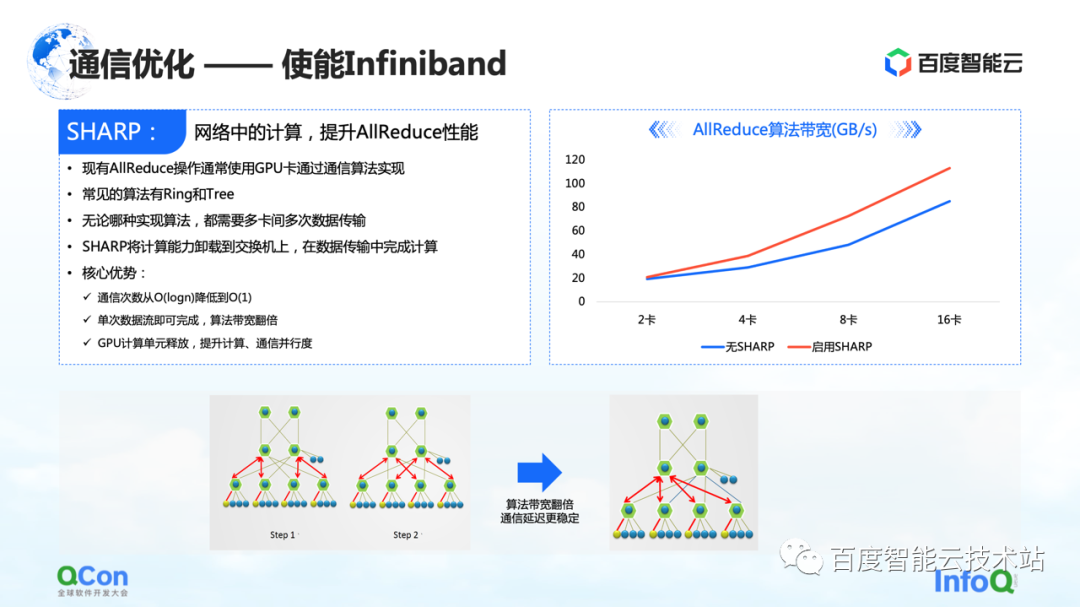
さらに、RoCE で行われるこれらの最適化に加えて、Infiniband を有効にすることで達成できる別の直接的な効果があります。たとえば、前述のスイッチ ハッシュの競合は、独自のアダプティブ ルーティングによって処理できます。AllReduce には、Sharp などの高度な機能もいくつかあります。Sharp は、AllReduce コンピューティング操作の一部をネットワーク デバイスにオフロードして、コンピューティング ユニットを解放し、コンピューティング パフォーマンスを向上させます。この方法により、AllReduce のトレーニング効果を再び向上させることができます。
コンピューティングと通信の最適化についての話が終わったので、この問題を端から端まで見ていきましょう。
大規模なモデル トレーニング全体の観点から見ると、実際には 2 つの部分に分かれています。最初の部分はモデル コードで、2 番目の部分は高性能ネットワークです。これら 2 つの異なるレベルで、早急に解決すべき問題があります。複数のセグメンテーション戦略の後にモデルを配置するのに最も適しているのはどのカードですか?
例を見てみましょう. テンソルの並列処理を行う場合、テンソルの計算を 2 つの部分に分割する必要があります。ブロックの計算結果間で多数の AllReduce 演算が必要になるため、高い帯域幅が必要になります。
異なるマシンの 2 枚のカードに 2 つのテンソル カットを並列に配置すると、ネットワーク通信が発生し、パフォーマンスの問題が発生します。逆に、これら 2 つの部分を同じマシンに配置すると、計算タスクを効率的に完了し、トレーニング効率を向上させることができます。したがって、配置問題の主な魅力は、セグメント化されたモデルと異種ハードウェアの間で最も適切な、または最高のパフォーマンスを発揮するマッピング関係を見つけることです。
初期のモデル トレーニングでは、マッピングは専門的な経験的知識に基づいて手動で行われました。たとえば、下の図は、ビジネス チームと協力して、マシンの帯域幅が良いと判断した場合に、マシンに入れることを推奨することを示しています。機械室に改善の余地があると思われる場合は、機械室に設置することをお勧めします。
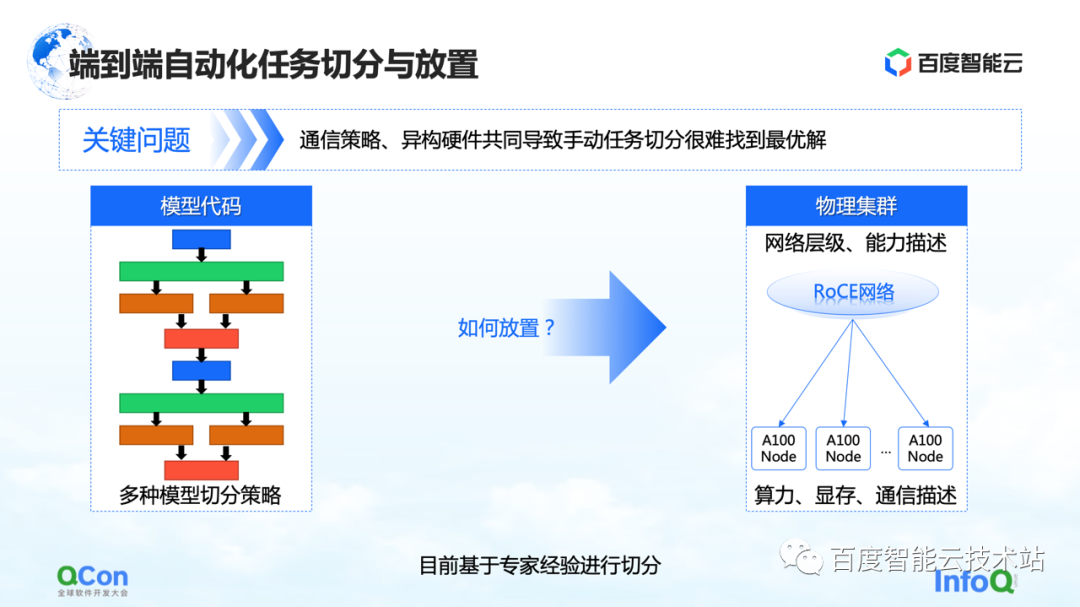
工学的または体系的な解決策はありますか?
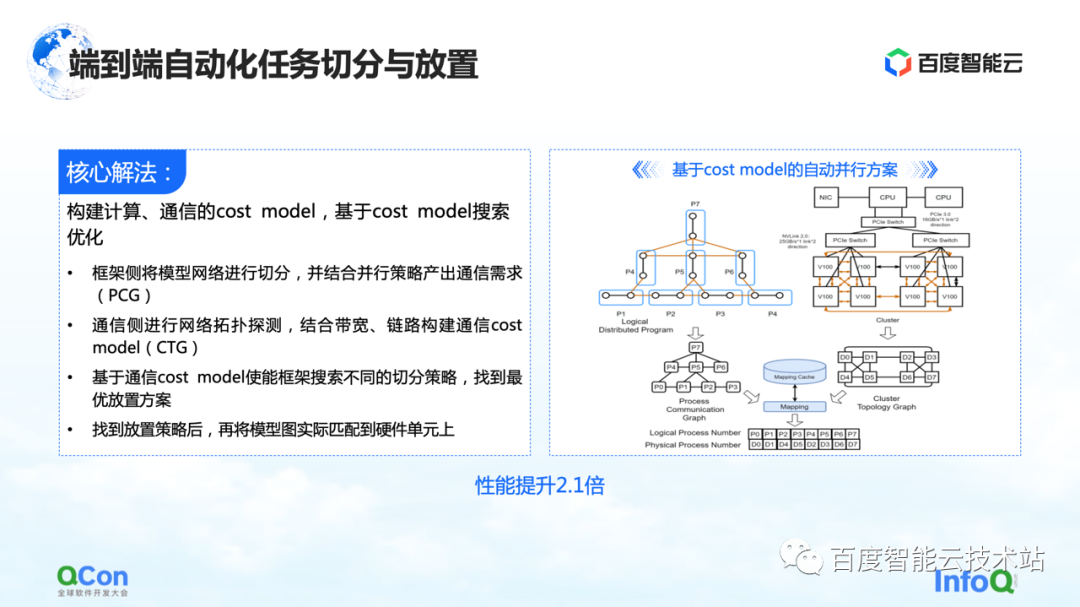
私たちのコア ソリューションは、コンピューティングと通信のコスト モデルを構築し、コスト モデルに基づいて検索の最適化を行うことです。このようにして、最適なマッピングが生成されます。
全体のプロセスでは、フレームワーク側のモデル ネットワークが最初に抽象化およびセグメント化され、コンピューティング フレームワーク ダイアグラムにマッピングされます。同時に、スタンドアロンとクラスターのコンピューティングおよび通信機能がモデル化され、クラスターのトポロジ マップが作成されます。
右側の図の左側のモデルにコンピューティングと通信の要件があり、図の右側にあるハードウェアのコンピューティングと通信の機能がある場合、グラフ アルゴリズムまたはその他の検索によってモデルを分割してマッピングできます。メソッドを実行し、最終的に右図の下部にある最適解を取得します。
実際の大規模なモデルのトレーニング プロセスでは、このようにして最終的なパフォーマンスを 2.1 倍向上させることができます。
4. 大型モデルの開発がインフラの進化を促進
最後に、大規模モデルが将来インフラストラクチャに課す新しい要件について説明します。
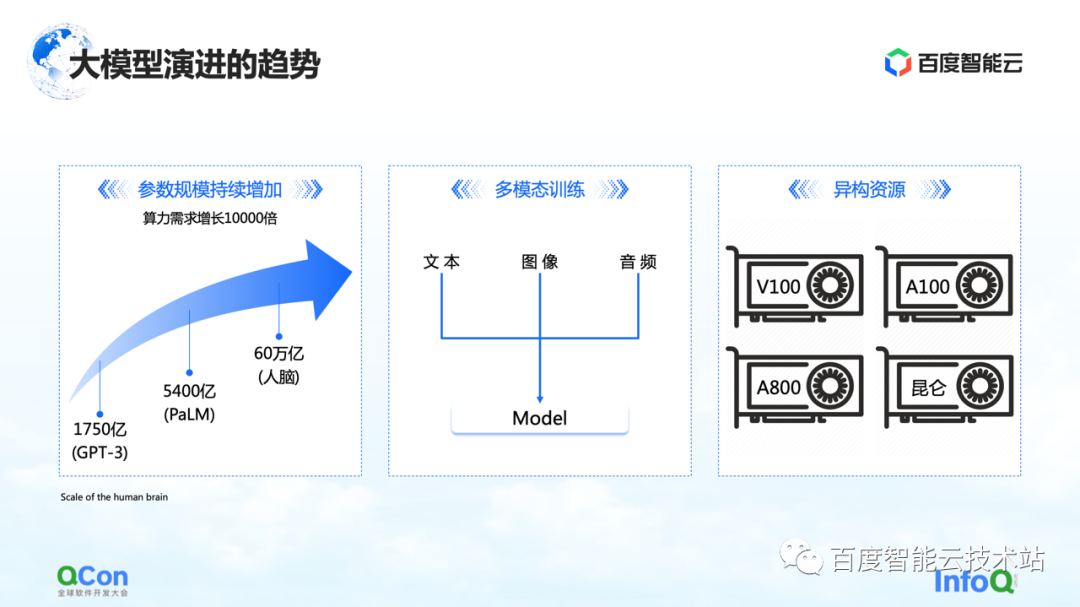
これまでに見た変更点は 3 つあります。1 つ目はモデルのパラメーターです。モデルのパラメーターは、GPT-3 の 1,750 億から PaLM の 5,400 億まで増加し続けます。将来のパラメータの成長の最終的な値については、約 60 兆個のパラメータのスケールを持つ人間の脳を参照できます。
2 つ目は、マルチモーダル トレーニングです。将来的には、より多くのモーダル データを扱う予定です。モーダル データが異なると、ストレージ、計算、およびビデオ メモリにより多くの課題が生じます。
3 つ目は異種リソースです。将来的には、異種リソースがますます増えるでしょう。トレーニングの過程では、さまざまな種類の計算能力をどのように活用するかが喫緊の課題です。
同時に、ビジネスの観点からは、完全なトレーニング プロセスにさまざまな種類のジョブが存在する可能性があり、従来の GPT-3 トレーニング、強化学習トレーニング、およびデータ ラベル付けタスクが同時に存在する可能性があります。これらの異種タスクを異種クラスタに適切に配置する方法は、より大きな問題になります。
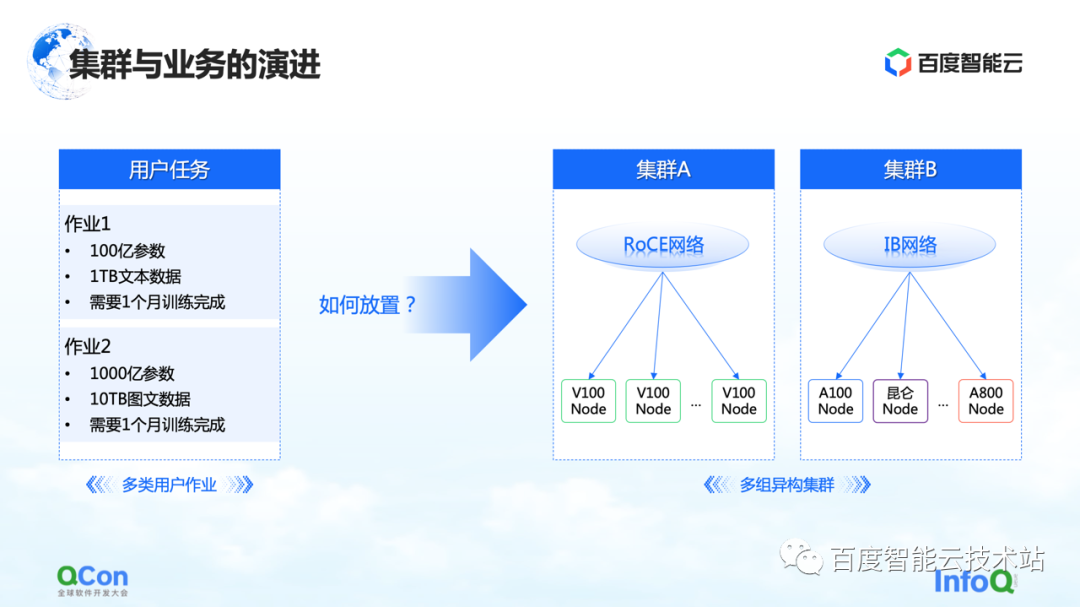
これまでにいくつかの方法を見てきましたが、そのうちの 1 つは統合ビューに基づくエンドツーエンドの最適化です。モデル全体と異種リソースをビューで統合し、統合ビューに基づいてコスト モデルを拡張します。異種リソース クラスター下の配置でのタスクとマルチジョブ。エラスティック スケジューリングの機能と組み合わせることで、クラスター リソースの変化をより適切に感知できます。
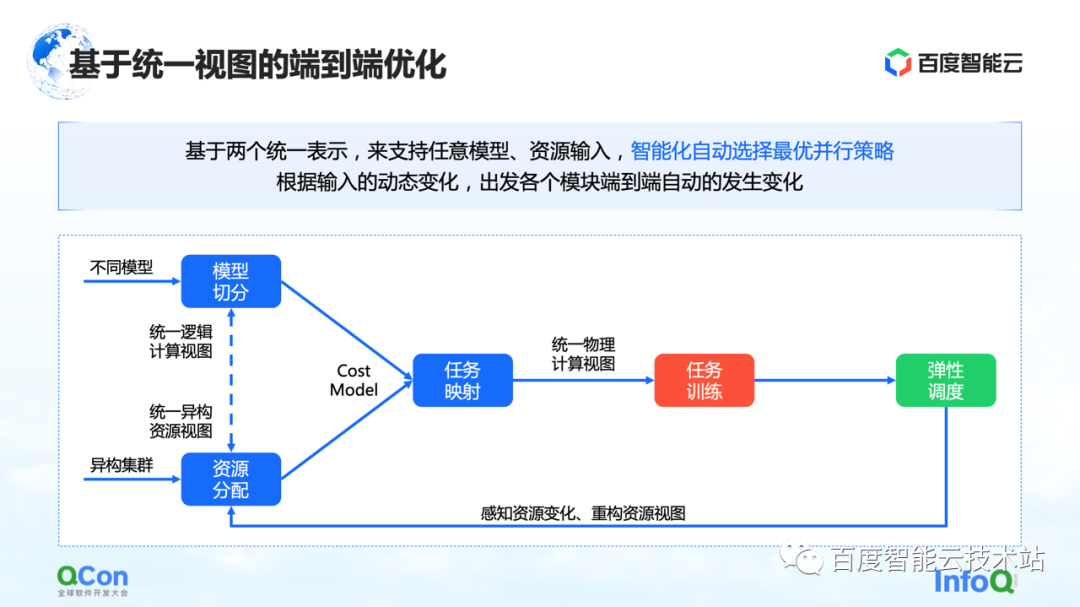
上記のすべての機能は、Baidu Baige の AI ヘテロジニアス コンピューティング プラットフォームに統合されています。
- 終わり -
推奨読書:
アンチチートの活動シーンにおけるグラフアルゴリズムの応用について語る
サーバーレス: パーソナライズされたサービス ポートレートに基づく柔軟なスケーリングの実践
パフォーマンス プラットフォーム データ アクセラレーション ロード