要旨: この記事では主にカーネル内で処理を中断させない特殊な処理を行う方法について説明する. 理論的には, ユーザーが実行するSQLが使用するメモリ (dynamic_used_memory) は, max_dynamic_memory のメモリを大きく超えることはない.
この記事は、Huawei クラウド コミュニティ「Gaussdb (DWS) メモリ エラーのトラブルシューティング方法」、著者:fightingman から共有されています。
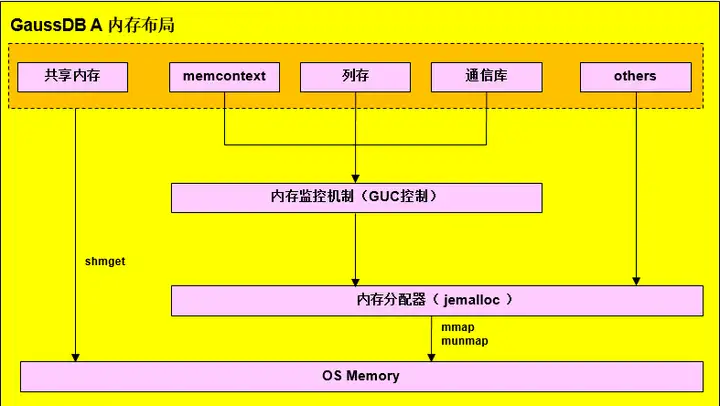
Gaussdb メモリ レイアウト
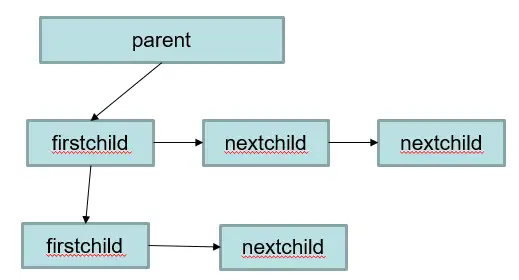
メモリ コンテキスト memoryContext メモリ構造
1.メモリ問題の特定方法
分析シナリオ 1: エラー: メモリが一時的に利用できませんが、データベース ログに表示されます
エラー メッセージから、メモリが不足しているノードを特定できます。
1. ログ解析より
dn に対応するログを観察します。「データベース メモリの制限に達している」かどうか。これは、データベースの論理メモリ管理メカニズムの保護が原因であり、データベースのビューをさらに分析する必要があることを意味します。 「OS のメモリ制限に達している」場合は、オペレーティング システムのメモリ割り当てが失敗したことを意味します。失敗した場合は、オペレーティング システムのパラメータ設定とメモリ ハードウェアの状態を確認する必要があります。
1) データベースのメモリ制限に達した例
----debug_query_id=76279718689098154, memory allocation failed due to reaching the database memory limitation. Current thread is consuming about 10 MB, allocating 240064 bytes.
----debug_query_id=76279718689098154, Memory information of whole process in MB:max_dynamic_memory: 18770, dynamic_used_memory: 18770, dynamic_peak_memory: 18770, dynamic_used_shrctx: 1804, dynamic_peak_shrctx: 1826, max_sctpcomm_memory: 4000, sctpcomm_used_memory: 1786, sctpcomm_peak_memory: 1786, comm_global_memctx: 0, gpu_max_dynamic_memory: 0, gpu_dynamic_used_memory: 0, gpu_dynamic_peak_memory: 0, large_storage_memory: 0, process_used_memory: 22105, cstore_used_memory: 1022, shared_used_memory: 2605, other_used_memory: 0, os_totalmem: 257906, os_freemem: 16762.この時点で、ジョブ 76279718689098154 が 240064 バイトのメモリに適用されようとしており、dynamic_used_memory メモリ値は 18770MB です。2 つの合計は max_dynamic_memory (18770MB) を超えており、データベースの制限を超えているため、メモリの適用は失敗します。
811 以降のバージョンでは、top3 の memoryContext メモリ使用量も出力されます。例は次のとおりです。
----debug_query_id=72339069014641088, sessId: 1670914731.140604465997568.coordinator1, sessType: postgres, contextName: ExprContext, level: 5, parent: FunctionScan_140604465997568, totalSize: 950010640, freeSize: 0, usedSize: 950010640
----debug_query_id=72339069014641053, pid=140604465997568, application_name=gsql, query=select * from pv_total_memory_detail, state=retrying, query_start=2022-12-13 14:59:22.059805+08, enqueue=no waiting queue, connection_info={"driver_name":"gsql","driver_version":"(GaussDB 8.2.0 build bc4cec20) compiled at 2022-12-13 14:45:14 commit 3629 last mr 5138 debug","driver_path":"/data3/x00574567/self/gaussdb/mppdb_temp_install/bin/gsql","os_user":"x00574567"}
----debug_query_id=72339069014641088, sessId: 1670914731.140604738627328.coordinator1, sessType: postgres, contextName: ExprContext, level: 5, parent: FunctionScan_140604738627328, totalSize: 900010080, freeSize: 0, usedSize: 900010080
----debug_query_id=72339069014641057, pid=140604738627328, application_name=gsql, query=select * from pv_total_memory_detail, state=retrying, query_start=2022-12-13 14:59:22.098775+08, enqueue=no waiting queue, connection_info={"driver_name":"gsql","driver_version":"(GaussDB 8.2.0 build bc4cec20) compiled at 2022-12-13 14:45:14 commit 3629 last mr 5138 debug","driver_path":"/data3/x00574567/self/gaussdb/mppdb_temp_install/bin/gsql","os_user":"x00574567"}
----debug_query_id=72339069014641088, sessId: 1670914731.140603779163904.coordinator1, sessType: postgres, contextName: ExprContext, level: 5, parent: FunctionScan_140603779163904, totalSize: 890009968, freeSize: 0, usedSize: 890009968
----debug_query_id=72339069014641058, pid=140603779163904, application_name=gsql, query=select * from pv_total_memory_detail, state=retrying, query_start=2022-12-13 14:59:22.117463+08, enqueue=no waiting queue, connection_info={"driver_name":"gsql","driver_version":"(GaussDB 8.2.0 build bc4cec20) compiled at 2022-12-13 14:45:14 commit 3629 last mr 5138 debug","driver_path":"/data3/x00574567/self/gaussdb/mppdb_temp_install/bin/gsql","os_user":"x00574567"}
----allBackendSize=34, idleSize=7, runningSize=7, retryingSize=20重要なフィールドの説明:
sessId: スレッド開始時刻 + スレッドID (文字列情報はtimestamp.threadid)
sessType: スレッド名
contextName: メモリコンテキスト名
totalSize: メモリ使用量、単位 Byte
freeSize: 現在の memoryContext によって解放されたメモリの総量 (バイト単位)
usedSize: 現在の memoryContext によって使用されているメモリの総量 (バイト単位)
application_name: このバックエンドに接続されているアプリケーションの名前
クエリ: クエリ ステートメント
enqueue: キューイング状態
allBackendSize: スレッドの総数、idleSize: アイドル スレッドの数、runningSize: アクティブなスレッドの数、retryingSize: 再試行されたスレッドの数
また、データベースは複合ジョブをチェックインして、複合ジョブの推定メモリが実際に使用されているメモリを超えているかどうかを確認し、超えている場合は、分析のために次の情報を出力します。
----debug_query_id=76279718689098154, Total estimated Memory is 15196 MB, total current cost Memory is 16454 MB, the difference is 1258 MB.The count of complicated queries is 17 and the count of uncontrolled queries is 1.上記の情報は、すべての複雑なジョブが 15196 MB のメモリを使用すると予想されることを示していますが、実際の使用量は 16454 MB であり、1258 MB を超えています。
17 の複雑なジョブがあり、そのうちの 1 つは実際には予想よりも多くのメモリを使用しています。
----debug_query_id=76279718689098154, The abnormal query thread id 140664667547392.It current used memory is 13618 MB and estimated memory is 1102 MB.It also is the query which costs the maximum memory.上記の情報は、異常なスレッド ID が 140664667547392 であり、このスレッドの推定メモリ消費量が 1102MB であることを示していますが、実際のメモリ消費量は 13618MB です。
----debug_query_id=76279718689098154, It is not the current session and beentry info : datid<16389>, app_name<cn_5001>, query_id<76279718688746485>, tid<140664667547392>, lwtid<173496>, parent_tid<0>, thread_level<0>, query_string<explainperformance with ws as (select d_year AS ws_sold_year, ws_item_sk, ws_bill_customer_sk ws_customer_sk, sum(ws_quantity) ws_qty, sum(ws_wholesale_cost) ws_wc, sum(ws_sales_price) ws_sp from web_sales left join web_returns on wr_order_number=ws_order_number and ws_item_sk=wr_item_sk join date_dim on ws_sold_date_sk = d_date_sk where wr_order_number is null group by d_year, ws_item_sk, ws_bill_customer_sk ), cs as (select d_year AS cs_sold_year, cs_item_sk, cs_bill_customer_sk cs_customer_sk, sum(cs_quantity) cs_qty, sum(cs_wholesale_cost) cs_wc, sum(cs_sales_price) cs_sp from catalog_sales left join catalog_returns on cr_order_number=cs_order_number and cs_item_sk=cr_item_sk join date_dim on cs_sold_date_sk =d_date_sk where cr_order_number is null group by d_year, cs_item_sk, cs_bill_customer_sk ), ss as (select d_year AS ss_sold_year, ss_item_sk, ss_customer_sk, sum(ss_quantity) ss_qty, sum(ss_wholesale_cost) ss_wc, sum(ss_sales_price) ss_spfrom store_sales left join store_returns on sr_ticket_numbe>.上記の情報はさらに、メモリ使用量が推定メモリを超えたジョブ情報の sql 情報を表示します。datid はデータベースの OID、app_name はアプリケーション名、query_string はクエリ sql を示します。
----debug_query_id=76279718689098154, WARNING: the common memory context 'HashContext' is using 1059 MB size larger than 989 MB.----debug_query_id=76279718689098154, WARNING: the common memory context 'VecHashJoin_76279718688746485_6' is using 12359 MB size larger than 10 MB.上記の情報は memcontext が制限を超えていることを示しています. クエリ番号 76279718689098154 では、メモリコンテキストのプリセット値の最大値が 989MB であり、実際に 1059MB が使用されています.
2)OSのメモリ制限に達している
GaussDB のメモリ使用量が GUC の関連パラメータ制限に準拠しているが、オペレーティング システムの使用可能なメモリが不足している場合、1.1 と同様のログ メッセージが表示され、形式は次のとおりです。
----debug_query_id=%lu, FATAL: memory allocation failed due to reaching the OS memory limitation. Current thread is consuming about %d MB, allocating %ld bytes.
----debug_query_id=%lu, Please check the sysctl configuration and GUC variable max_process_memory.
----debug_query_id=%lu, Memory information of whole process in MB:"
"max_dynamic_memory: %d, dynamic_used_memory: %d,
dynamic_peak_memory: %d, dynamic_used_shrctx: %d,
dynamic_peak_shrctx: %d, max_sctpcomm_memory: %d,
sctpcomm_used_memory: %d, sctpcomm_peak_memory: %d,
comm_global_memctx: %d, gpu_max_dynamic_memory: %d,
gpu_dynamic_used_memory: %d,
gpu_dynamic_peak_memory: %d, large_storage_memory: %d,
process_used_memory: %d, cstore_used_memory: %d,
shared_used_memory: %d, other_used_memory: %d,
os_totalmem: %d, os_freemem: %dこのうち、os_totalmem は現在の OS の合計メモリ、つまり「free」コマンドでの合計情報です。os_freemem は、現在の OS で使用可能なメモリ、つまり「free」コマンドの空き情報です。
最初のログの「allocating %ld bytes」で要求されるメモリが、3 番目のログの「os_freemem」項目よりも大きく、データベースがその他の異常なく実行できる場合は、期待どおりであり、OS メモリが不足していることを示しています。不十分。
2. 各インスタンスのメモリ使用量については、pgxc_total_memory_detail をクエリします。
メモリ エラーが報告された後、ステートメントで使用されていたメモリが解放されますが、このとき、多くのメモリを占有していたステートメントがエラー レポートによって失われ、クエリ メモリ ビューをクエリできなくなります。
with a as (select *from pgxc_total_memory_detail where memorytype='dynamic_used_memory'), b as(select * from pgxc_total_memory_detail wherememorytype='dynamic_peak_memory'), c as (select * from pgxc_total_memory_detailwhere memorytype='max_dynamic_memory'), d as (select * frompgxc_total_memory_detail where memorytype='process_used_memory'), e as (select* from pgxc_total_memory_detail where memorytype='other_used_memory'), f as(select * from pgxc_total_memory_detail where memorytype='max_process_memory')select a.nodename,a.memorymbytes as dynamic_used_memory,b.memorymbytes asdynamic_peak_memory,c.memorymbytes as max_dynamic_memory,d.memorymbytes asprocess_used_memory,e.memorymbytes as other_used_memory,f.memorymbytes asmax_process_memory from a,b,c,d,e,f where a.nodename=b.nodename andb.nodename=c.nodename and c.nodename=d.nodename and d.nodename=e.nodename ande.nodename=f.nodename order by a.nodename;
このビューをクエリすると、メモリ不足が原因でメモリが一時的に利用できないことが報告され、ビューが利用できなくなる場合があります。この場合、disable_memory_protect を off に設定する必要があります。
set disable_memory_protect=off; その後、ビューをクエリしてもエラーは報告されません。
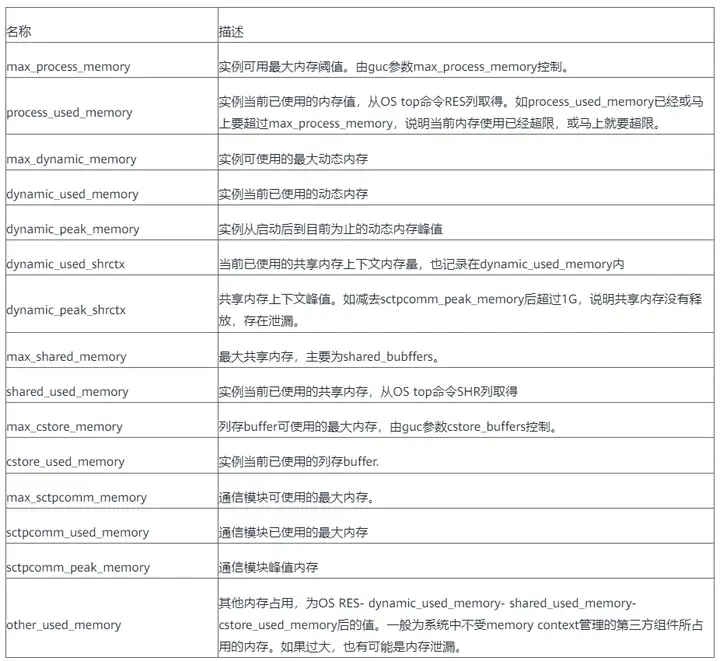
上記のビューを使用して、クラスター内のどのノードが異常なメモリ使用量を持っているかを見つけ、そのノードに接続して、pv_session_memory_detail ビューを使用して問題のあるメモリ コンテキストを見つけることができます。
SELECT * FROM pv_session_memory_detail ORDER BY totalsize desc LIMIT 100;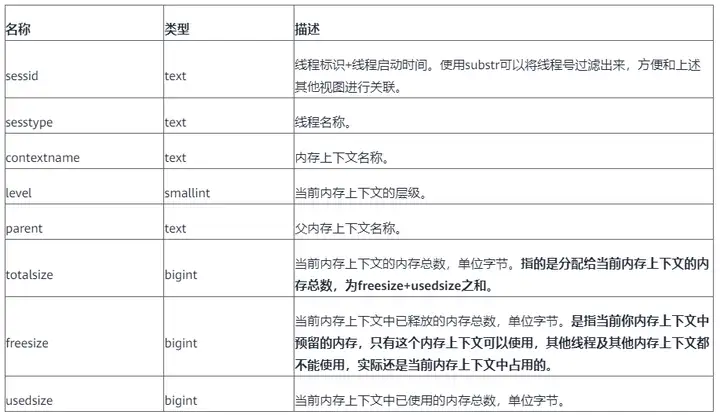
pg_stat_activity ビューと組み合わせると、どのステートメントが最も memcontext を使用しているかがわかります。
select sessid, contextname, level,parent, pg_size_pretty(totalsize) as total ,pg_size_pretty(freesize) as freesize, pg_size_pretty(usedsize) as usedsize, datname,query_id, query from pv_session_memory_detail a , pg_stat_activity b where split_part(a.sessid,'.',2) = b.pid order by totalsize desc limit 100;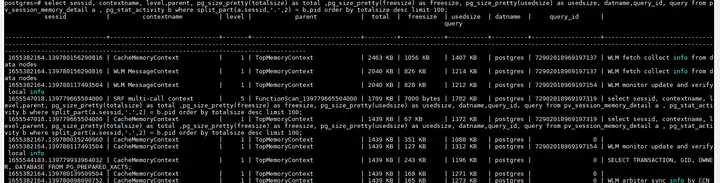
緊急復旧
EXECUTE DIRECT ON(cn_5001) 'SELECT pg_terminate_backend(139780156290816)';2. メモリ使用量が多いシナリオの分析
1.アイドル状態の接続が多すぎると、メモリ使用量が増加します
まずどのインスタンスのメモリ使用量が多いかを確認する.確認方法は上記のようにpgxc_total_memory_detailをクエリしてから, cnまたはdnに接続して以下のsqlをクエリする.
select b.state, sum(totalsize) as totalsize, sum(freesize) as freesize, sum(usedsize) as usedsize from pv_session_memory_detail a , pg_stat_activity b where split_part(a.sessid,'.',2) = b.pid group by b.state order by totalsize desc limit 100;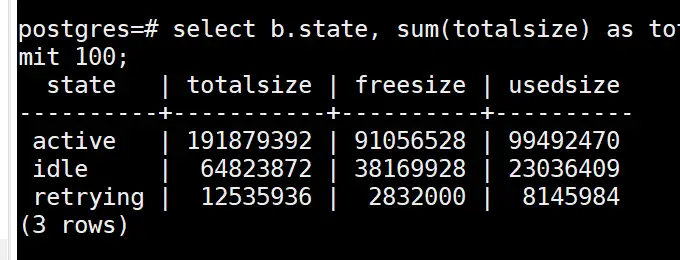
上記の図のアイドル状態の合計サイズが多くのメモリを占有する場合は、アイドル状態のアイドル接続をクリーンアップしてメモリを解放することを試みることができます
解決策: アイドル状態のアイドル状態の接続をクリーンアップする
CLEAN CONNECTION TO ALL FORCE FOR DATABASE xxxx;clean connection は、pg_pooler_status で in_used 状態が f であるアイドル接続のみをクリーンアップできますが、in_used 状態が t である接続はクリーンアップできません. In_used は t. 通常、pbe ステートメントが実行され、cn と dn のアイドル接続はクリーンアップできません。リリースされました。
上記の方法でクリーンアップできない場合は、cn とクライアントの間の接続をクリーンアップしてから、クリーン接続を実行して cn と dn の間の接続をクリーンアップすることしかできません。cn でアイドル状態の接続を見つけることを試みることができます。この操作は cn を壊します クライアントと接続するには、実行できるかクライアントに確認する必要があります
select 'execute direct on ('||coorname||') ''select pg_terminate_backend('||pid||')'';' from pgxc_stat_activity where usename not in ('Ruby', 'omm') and state='idle';select の結果を順番に実行します。
2. ステートメントがメモリを占有しすぎている 最初のステップの最初のステートメントがアクティブ状態のステートメントをクエリし、大量のメモリを占有している場合、実行中のステートメントがメモリを占有している原因は、メモリが多すぎることです。
以下のステートメントをクエリして、多くのメモリを消費するステートメントを見つけます
select b.state as state, a.sessid as sessid, b.query_id as query_id, substr(b.query,1,100) as query, sum(totalsize) as totalsize, sum(freesize) as freesize, sum(usedsize) as usedsize from pv_session_memory_detail a , pg_stat_activity b where split_part(a.sessid,'.',2) = b.pid and usename not in ('Ruby', 'omm') group by state,sessid,query_id,query order by totalsize desc limit 100;ステートメントを見つけたら、query_id に従って、対応する cn で異常な SQL を検索して強制終了します。
3. dynamic_used_shrctx はより多くのメモリを使用します
dynamic_used_shrctx は共有メモリ コンテキストが使用するメモリで、これも MemoryContext で分割され、スレッド間で共有されます。pg_shared_memory_detail ビューを介して表示
select * from pg_shared_memory_detail order by totalsize desc limit 10;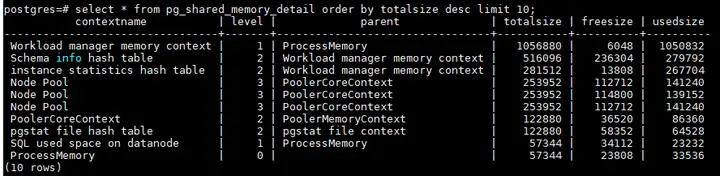
通常、共有メモリ コンテキストの割り当てはステートメントに関連付けられます. コンテキスト名にはスレッド番号または query_id が付けられ、異常な sql は query_id またはスレッド番号に従ってチェックされ、killされます. また、共有メモリ コンテキストは通常、 topsql など、カーネル内の各モジュールが使用するメモリ メモリ使用量が妥当かどうか、および解放メカニズムを確認する必要があります。
4. メモリ ビュー pv_total_memory_detail で、dynamic_used_memory > max_dynamic_memory
1) GUC パラメータ disable_memory_protect がオンの場合
2) メモリを割り当てるとき、debug_query_id は 0 です
3) カーネルがキーコードセグメントを実行するとき
4) カーネル Postmaster スレッド内のメモリ割り当て
5) トランザクションのロールバック段階で
上記の状況はすべて、操作が中断されないようにするためにカーネルによって行われる特別な処理です. 理論的には、ユーザーが実行する SQL によって使用されるメモリ (dynamic_used_memory) は、大規模に max_dynamic_memory のメモリを超えることはありません.
クリックしてフォローし、Huawei Cloudの新しいテクノロジーについて初めて学びましょう〜