記事ディレクトリ
1. データの断片化
-
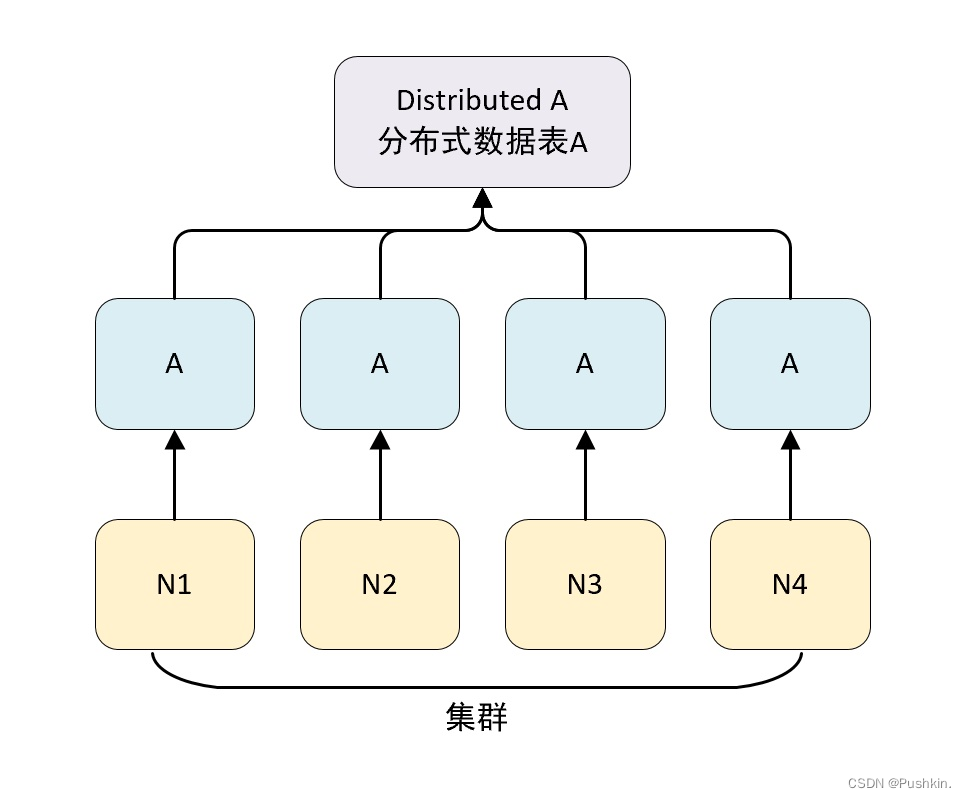
クリックハウスの各サーバー ノードは、シャード (シャード) と呼ぶことができます。N 台のサーバーがあり、各サーバーにデータ テーブル A があり、各サーバーのデータ テーブル A のデータが繰り返されないと仮定すると、データ テーブル A には N 個のシャードがあると言えます。
-
完全なソリューションを実現するには、データが書き込まれるときに各シャードにデータが均等に書き込まれる方法と、クエリが実行されて結果セットに結合されるときにデータが各シャードにルーティングされる方法についても考慮する必要があります。
-
クリックハウスのデータ シャーディングは、分散テーブル エンジンと組み合わせて使用する必要があります。分散テーブル エンジン自体はデータを保存しませんが、分散テーブルの第 1 層プロキシとして使用して、クラスター内でデータの書き込み、分散、クエリ、およびルーティングを自動的に実行できます。
1.1 クラスタの構成方法
クリックハウスのクラスター構成では、シャードを使用してディストリビューションを表し、レプリカを使用してレプリカを表します。
- 1 シャード、0 レプリカ構成
<shard> <!--分片-->
<replica> <!--副本-->
</replica>
</shard>
- 1 シャード、1 レプリカ構成
<shard> <!--分片-->
<replica> <!--副本-->
</replica>
<replica> <!--副本-->
</replica>
</shard>
- クリックハウス クラスタを構成するには 2 つの方法があります
1.1.1 レプリカのないシャード
ノード ラベルを使用して配布ノードを直接定義する場合、ノードの保証書の配布にはコピーが含まれず、構成は次のようになります。
<yandex>
<!-- 自定义配置名称,与 conf.xml 配置的 include 属性相同即可-->
<clickhouse_remote_servers>
<shard_1> <!--自定义集群名称-->
<node> <!--自定义 clickhouse 节点-->
<!--必填参数-->
<host>node3</host>
<port>9977</port>
<!--选填参数-->
<weight>1</weight>
<user>default</user>
<password></password>
<secure></secure>
<compression></compression>
</node>
<node>
<host>node2</host>
<port>9977</port>
</node>
</shard_1>
</clickhouse_remote_servers>
</yandex>
<!-- 配置定义了一个名为 shard_1 的集群,包含了两个节点 node3、node2 -->
| 構成、設定 | 例証する |
|---|---|
| shard_1 | グローバルに一意のカスタム クラスタ名は、クラスタ構成を後で参照するための一意の識別子です。 |
| ノード | レプリカを含まないノードの定義に使用 |
| ホスト | クリックハウス ノード サーバー アドレス |
| ポート | クリックハウス サービスの TCP ポート |
| 重さ | シャードの重み、デフォルトは 1 |
| ユーザー | クリックハウス ユーザー、デフォルトはデフォルト |
| パスワード | クリックハウスのユーザーパスワード、デフォルトは空文字 |
| 安全 | SSL 接続ポート、デフォルト 9440 |
| 圧迫 | データ圧縮機能を有効にするかどうか、デフォルトは true |
1.1.2 カスタム レプリカとシャード
- The cluster configuration supports custom allocation and the number of replicas. このフォームでは、前の構成で構成されたノード ラベルではなく、シャード ラベルを使用する必要があります。それ以外は、構成はまったく同じです。
- カスタム レプリカとシャードを構成する場合、レプリカとシャードの数は完全に構成次第です。
- その中で、シャードは論理的なデータのシャーディングを表し、物理的なシャーディングはレプリカで表されます
- レプリカの N グループがシャード ラベルの下に定義されている場合、そのシャードのセマンティクスは 1 つのシャードと N-1 個のレプリカを表します。
- レプリカのないシャード
<!-- 2 分片,0 副本-->
<sharding_simple> <!-- 集群自定义名称 -->
<shard> <!-- 分片 -->
<replica> <!-- 副本 -->
<host>node3</host>
<port>9977</port>
</replica>
</shard>
<shard>
<replica>
<host>node2</host>
<port>9977</port>
</replica>
</shard>
</sharding_simple>
- N 個のシャードと N 個のレプリカ
必要に応じて、レプリカとシャードの組み合わせを構成できます
<!-- 1 分片,1 副本-->
<sharding_simple> <!-- 集群自定义名称 -->
<shard> <!-- 分片 -->
<replica> <!-- 副本 -->
<host>node3</host>
<port>9977</port>
</replica>
<replica>
<host>node2</host>
<port>9977</port>
</replica>
</shard>
</sharding_simple>
<!-- 2 分片,1 副本-->
<sharding_simple> <!-- 集群自定义名称 -->
<shard> <!-- 分片 -->
<replica> <!-- 副本 -->
<host>node3</host>
<port>9977</port>
</replica>
<replica>
<host>node2</host>
<port>9977</port>
</replica>
</shard>
<shard> <!-- 分片 -->
<replica> <!-- 副本 -->
<host>node4</host>
<port>9977</port>
</replica>
<replica>
<host>node5</host>
<port>9977</port>
</replica>
</shard>
</sharding_simple>
<!-- 集群部署中,副本数量的上线是 clickhouse 节点的数量决定的 -->
クリックハウスでいくつかの例が構成されています。構成ファイルを開いて見てください。
<remote_servers>
<!-- Test only shard config for testing distributed storage -->
<test_shard_localhost>
<!-- Inter-server per-cluster secret for Distributed queries
default: no secret (no authentication will be performed)
If set, then Distributed queries will be validated on shards, so at least:
- such cluster should exist on the shard,
- such cluster should have the same secret.
And also (and which is more important), the initial_user will
be used as current user for the query.
Right now the protocol is pretty simple and it only takes into account:
- cluster name
- query
Also it will be nice if the following will be implemented:
- source hostname (see interserver_http_host), but then it will depends from DNS,
it can use IP address instead, but then the you need to get correct on the initiator node.
- target hostname / ip address (same notes as for source hostname)
- time-based security tokens
-->
<!-- <secret></secret> -->
<shard>
<!-- Optional. Whether to write data to just one of the replicas. Default: false (write data to all replicas). -->
<!-- <internal_replication>false</internal_replication> -->
<!-- Optional. Shard weight when writing data. Default: 1. -->
<!-- <weight>1</weight> -->
<replica>
<host>localhost</host>
<port>9000</port>
<!-- Optional. Priority of the replica for load_balancing. Default: 1 (less value has more priority). -->
<!-- <priority>1</priority> -->
</replica>
</shard>
</test_shard_localhost>
<test_cluster_two_shards_localhost>
<shard>
<replica>
<host>localhost</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>localhost</host>
<port>9000</port>
</replica>
</shard>
</test_cluster_two_shards_localhost>
<!-- 配置 2 个分配,0 副本 -->
<test_cluster_two_shards>
<shard>
<replica>
<host>127.0.0.1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>127.0.0.2</host>
<port>9000</port>
</replica>
</shard>
</test_cluster_two_shards>
<!--2 分片,0 副本-->
<test_cluster_two_shards_internal_replication>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>127.0.0.1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>127.0.0.2</host>
<port>9000</port>
</replica>
</shard>
</test_cluster_two_shards_internal_replication>
<!--1分片 0 副本,权重设为 1-->
<test_shard_localhost_secure>
<shard>
<replica>
<host>localhost</host>
<port>9440</port>
<secure>1</secure>
</replica>
</shard>
</test_shard_localhost_secure>
<test_unavailable_shard>
<shard>
<replica>
<host>localhost</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>localhost</host>
<port>1</port>
</replica>
</shard>
</test_unavailable_shard>
<!-- 手动添加新的集群 -->
<two_shard>
<shard>
<replica>
<host>node3</host>
<port>9977</port>
</replica>
</shard>
<shard>
<replica>
<host>node2</host>
<port>9977</port>
</replica>
</shard>
</two_shard>
</remote_servers>
-- 在 system.clusters 中查看配置情况
select cluster,host_name from system.clusters;
┌─cluster──────────────────────────────────────┬─host_name─┐
│ test_cluster_two_shards │ 127.0.0.1 │
│ test_cluster_two_shards │ 127.0.0.2 │
│ test_cluster_two_shards_internal_replication │ 127.0.0.1 │
│ test_cluster_two_shards_internal_replication │ 127.0.0.2 │
│ test_cluster_two_shards_localhost │ localhost │
│ test_cluster_two_shards_localhost │ localhost │
│ test_shard_localhost │ localhost │
│ test_shard_localhost_secure │ localhost │
│ test_unavailable_shard │ localhost │
│ test_unavailable_shard │ localhost │
└──────────────────────────────────────────────┴───────────┘
- 動的変数を定義する
各ノードの構成構成ファイルに変数構成を追加します
# node3
vim /etc/clickhouse-server/config.xml
# 增加如下内容
<macros>
<shard>01</shard>
<replica>node3</replica>
</macros>
# node2
vim /etc/clickhouse-server/config.xml
# 增加如下内容
<macros>
<shard>02</shard>
<replica>node2</replica>
</macros>
-- 进入 clickhouse 命令行查看变量是否配置成功
select * from system.macros;
-- 查看远端节点的数据
select * from remote('node2:9977','system','macros','default')
1.2 クラスターベースの分散 DDL の実装
デフォルトでは、create、drop、rename、alter などの ddl ステートメントは分散実行をサポートしていないため、複数のレプリカ テーブルを作成するには、異なるサーバー上に作成する必要があります。また、クラスターが構成されている場合は、新しい構文を使用できます。実装された分散 DDL実行。
create / drop / rename / alter table on cluster cluster_name
-- cluster_name 对应为配置文件中的汲取名称,clickhouse 会根据集群的配置,去各个节点执行 DDL 语句
-- 在 two_shard 集群 创建测试表
CREATE TABLE t_shard ON CLUSTER two_shard
(
`id` UInt8,
`name` String,
`date` DateTime
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/t_shard', '{replica}')
PARTITION BY toYYYYMM(date)
ORDER BY id
┌─host──┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ node2 │ 9977 │ 0 │ │ 1 │ 1 │
└───────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
┌─host──┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ node3 │ 9977 │ 0 │ │ 0 │ 0 │
└───────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
-- 表引擎可以使用其他任意引擎
-- {shard} 和 {replica} 两个动态变量代替了前面的硬编码方式
-- clickhouse 会根据 shard_2 的配置在 node3 和 node2 中创建 t_shard 数据表
-- 删除 t_shard 表
drop table t_shard on cluster shard_2;
1.2.1 データ構造
- Zookeeper のノード構造
<!-- 在默认情况下,分布式 DDL 在 zookeeper 内使用的根路径由config.xml distributed_ddl 标签配置 -->
<distributed_ddl>
<path>/clickhouse/task_queue/ddl</path>
</distributed_ddl>
<!-- 默认为 /clickhouse/task_queue/ddl-->
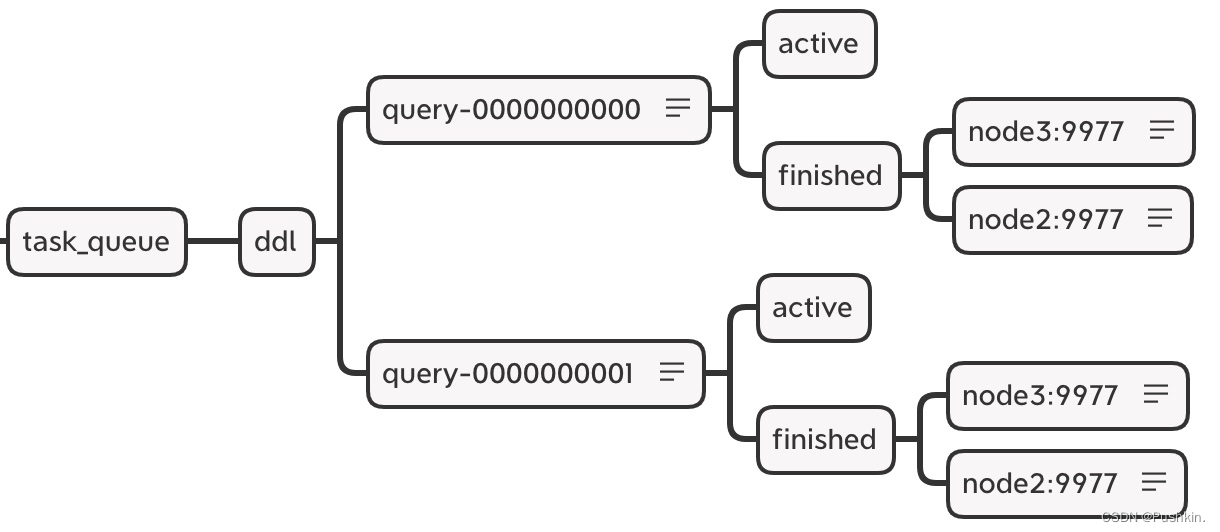
このパスの下には、/query-[seq] を含む他のリスニング ノードがいくつかあります。これは DDL 操作ログです。分散 DDL クエリが実行されるたびに、ノードの下に操作ログが追加され、応答操作が記録されます。各ノードが新しいログをリッスンすると、応答して実行されます。
The DDL operation log useszookeeper to persist sequence nodes. The name of each instruction is prefixed with query-[seq], and the sequence number after that is incremented. query-[seq] 操作ログの下に 2 つのステータス ノードがあります。
- query-[seq]/active: ステータスの監視に使用されます.タスクの実行中、現在のクラスタでステータスがアクティブであるノードは、このノードの下に一時的に保存されます.
- query-[seq]/finished: タスクの完了を確認するために使用されます.タスクの実行中、クラスター内のホストノードが実行されるたびに、ノードの下にレコードが書き込まれます.
/query-000001/finished
node3 : 0
node2 : 0
# 表示 node3,node2 两个节点已经执行完成
2. DDLLogEntry ログ オブジェクトのデータ構造
# 在 /query-[seq]下记录的信息由 DDLLogEntry 承载,它的核心属性有以下几个:
version: 1
query: CREATE TABLE default.t_shard UUID \'d1679b02-9eae-4766-8032-8201a2746692\' ON CLUSTER two_shard (`id` UInt8, `name` String, `date` DateTime) ENGINE = ReplicatedMergeTree(\'/clickhouse/tables/{
shard}/t_shard\', \'{
replica}\') PARTITION BY toYYYYMM(date) ORDER BY id
hosts: ['node3:9977','node2:9977']
initiator: node3%2Exy%2Ecom:9977
# query:记录了 DDL 查询的执行语句
# host:记录了指定集群的 hosts 主机列表,集群由分布式 DDL 语句中的 on cluster 指定,在分布式 DDL 执行过程中,会根据 hosts 列表逐个判断它们的执行状态。
# initiator:记录初始 host 主机的名称,hosts 主机列表的取值来自于初始化 host 节点上的去集群
ホスト ホスト リストの値のソースは、次のクエリと同等です。
SELECT host_name
FROM system.clusters
WHERE cluster = 'two_shard'
┌─host_name─┐
│ node3 │
│ node2 │
└───────────┘
1.2.2 分散DDLの実行手順
分散テーブルの作成を例として、分散 DDL の実行フローを説明します。
分散 DDL の全プロセスは上から下に時系列で実行され、大きく 3 つのステップに分けられます。
- DDL ログのプッシュ: 最初に node3 ノードのクラスターで create table を実行すると、node3 も DDLLogEntry ログを作成し、ログを ZooKeeper にプッシュし、タスク実行の進行状況を監視します
- ログをプルして実行: node3 と node2 はそれぞれ ddl/query-[seq] ログのプッシュを監視し、ログをそれぞれローカルにプルします. まず、それぞれのホストがホスト リストに含まれているかどうかを判断します。 DDLLogEntry. 実行プロセスに含め、実行後に終了ノードに書き込み、含まれていない場合は無視する
- 実行の進行状況を確認する: 最初のステップで DDL ステートメントを実行した後、クライアントは 180 秒間ブロックして、すべてのホストが実行を完了することを期待します. 待機時間が 180 秒を超える場合は、バックグラウンド スレッドに転送して続行します待機時間は、distributed_ddl_task_timeout パラメータによって設定されます。デフォルトは 180 です。
2. 分散原理の分析
分散テーブル エンジンは、分散テーブルと同義です. データ自体は保存しませんが、データ シャーディングのプロキシとして機能し、クラスタ内の各ノードにデータを自動的にルーティングできます. したがって、分散テーブル エンジンは他のテーブルと連携する必要がありますテーブルエンジン。
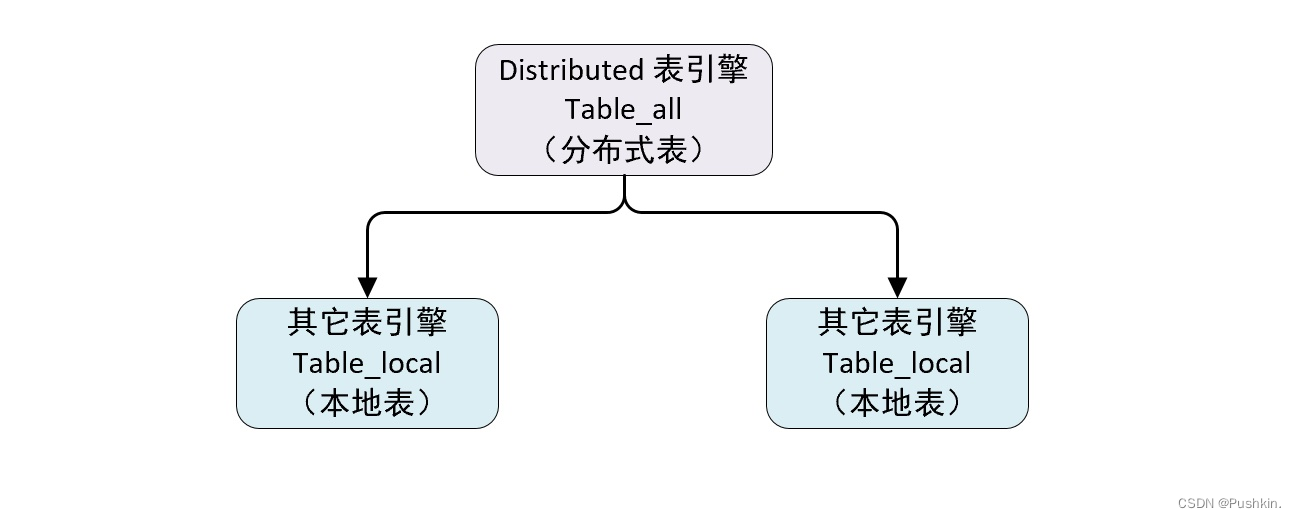
上の図からわかるように、テーブルは 2 つの部分に分かれています。
-
ローカル テーブル: 通常、_local サフィックスを付けて名前を付けます。ローカル テーブルはデータのキャリアです。任意の非分散テーブル エンジン、yi'zhang'ben を使用できます。
-
分散テーブル: 通常、接尾辞 _all で名前が付けられます。分散テーブルは、分散テーブル エンジンのみを使用できます。ローカル テーブルと 1 対多のマッピング関係を形成し、後で分散テーブル プロキシを介して複数のローカル テーブルを操作します。
分散テーブルとローカル テーブル間のテーブル構造の一貫性チェックのために、分散テーブル エンジンは読み取り時チェックのメカニズムを採用しています。つまり、それらのテーブル構造に互換性がない場合、クエリ中に例外がスローされます。 There is no check when creating a table engine. 異なるクリックハウス ノードのローカル テーブル間で異なるテーブル エンジンを使用することもできますが、通常は行われません. 構造の一貫性を保つことは、後のメンテナンスに役立ち、予期しない結果を回避します. .
2.1 定義形式
分散テーブル エンジンの定義
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name on cluster cluster_name(
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
...
) ENGINE = Distributed(cluster,database,table,[sharding_key])
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
- cluster: クラスター構成のカスタム名に対応するクラスター名. 分散テーブルへの書き込みとクエリのプロセスでは、クラスターの構成情報を使用して対応するノードを見つけます.
- データベース: 対応するデータベース名
- table: データ テーブルの名前に対応します。
- sharding_key: sharding key, optional parameter. データを書き込む過程で、分散テーブルは、シャーディング キーの規則に従って、各ローカル テーブルが配置されているノードにデータを分散します。
-- 创建分布式表 t_shard_2_all 代理 two_shard 集群的 drfault.t_shard_2_local 表
CREATE TABLE t_shard_2_all ON CLUSTER two_shard
(
`id` UInt8,
`name` String,
`date` DateTime
)
ENGINE = Distributed(two_shard, default, t_shard_2_local, rand())
Query id: 83e4f090-0f7d-4892-bbf3-a094f97a6eea
┌─host──┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ node2 │ 9977 │ 0 │ │ 1 │ 1 │
└───────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
┌─host──┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ node3 │ 9977 │ 0 │ │ 0 │ 0 │
└───────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
-- 这里用的是 on cluster 分布式 DDL, 所以在 two_shard 集群中每个节点都会创建一张分布式表
-- 写入数据时会根据 rand() 随机函数的取值决定写入那个分片,
-- 当这时还没有创建 本地表,可以看出Distributed 是读数据时才会进行检查。
-- 尝试 查询 t_shard_2_all 分布式表
SELECT *
FROM t_shard_2_all;
Received exception from server (version 21.4.3):
Code: 60. DB::Exception: Received from localhost:9977. DB::Exception: Table default.t_shard_2_local doesn t exist.
-- 使用分布式 DDL 创建本地表
CREATE TABLE t_shard_2_local ON CLUSTER two_shard
(
`id` UInt8,
`name` String,
`date` DateTime
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/t_shard_2_local', '{replica}')
PARTITION BY toYYYYMM(date)
ORDER BY id
┌─host──┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ node3 │ 9977 │ 0 │ │ 1 │ 0 │
│ node2 │ 9977 │ 0 │ │ 0 │ 0 │
└───────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
-- 尝试 查询 t_shard_2_all 分布式表
SELECT *
FROM t_shard_2_all;
Query id: 5ae82696-0f07-469b-bff5-bd17dc513da7
Ok.
0 rows in set. Elapsed: 0.009 sec.
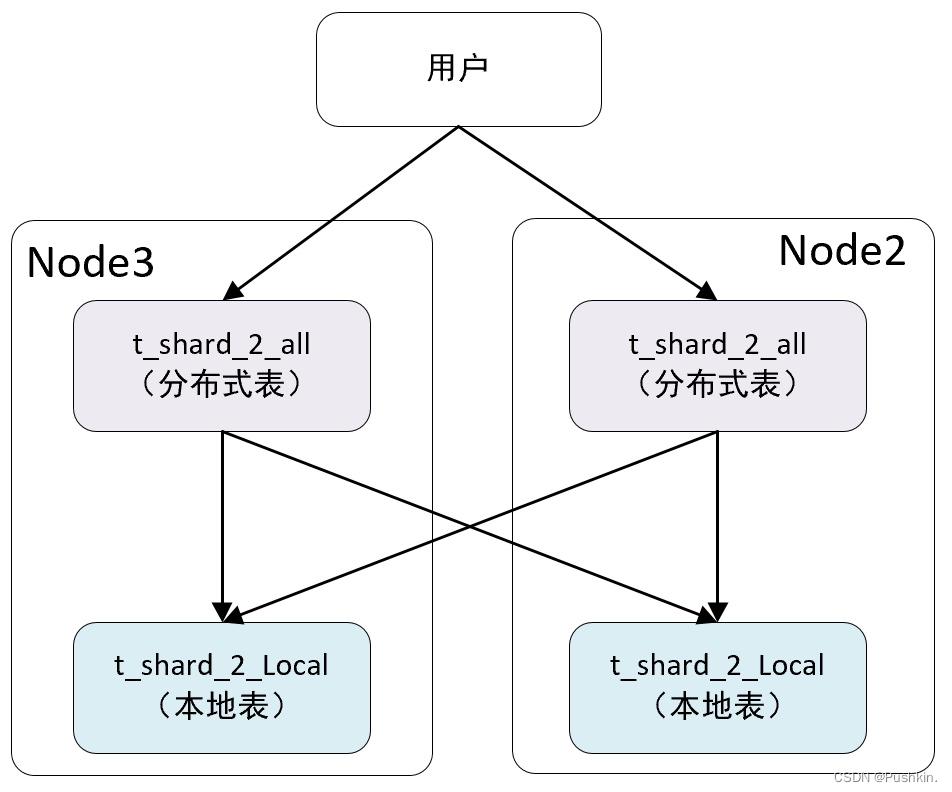
-- 到现在为止,拥有两个数据分配的分布式表 t_shard_2_all 就创建好了
2.2 クエリの分類
分散テーブルに対するクエリ操作は、次のカテゴリに分類できます。
- ローカル テーブルに作用するクエリ: 対応する select および insert 分散テーブルは、分散方式でローカル ローカル テーブルに作用します。
- 分散テーブル自体にのみ影響し、ローカル テーブルのクエリには影響しません. 分散テーブルは、作成、削除、名前の変更、変更など、一部のメタデータ操作をサポートしています. 変更には、パーティション操作 (パーティションのアタッチとパーティションの置換) は含まれませんなど)。これらの操作は、ローカル ローカル テーブルではなく、分散テーブル自体のみを変更します。
- 分散テーブルを完全に削除したい場合は、分散テーブルとローカルテーブルを別々に削除する必要があります
-- 删除分布式表
drop table t_shard_2_all on cluster two_shard;
-- 删除本地表
drop table t_shard_2_local on cluster two_shard;
- サポートされていない操作です。分散テーブルは、alter delete や alter update を含むミューテーション タイプの操作をサポートしていません。
2.3 シャーディングのルール
The rules for sharding are Further Explained here. シャーディング キーは、一連の Int 型と UInt 型を含む整数型の値を返す必要があります。
-- 分片键可以是一个具体的整型字段
-- 按照用户 ID 划分
Distributed(cluster,database,table,userid)
-- 分片键也可以是返回整型的表达式
-- 按照随机数划分
Distributed(cluster,database,table,rand())
-- 按照用户 ID 的散列值划分
Distributed(cluster,database,table,intHash64(userid))
シャード キーを宣言しない場合、分散テーブルにはシャードを 1 つしか含めることができません。つまり、マップできるテーブルは 1 つだけです。そうしないと、データの書き込み時に例外がスローされます。分散テーブルに含まれるシャードが 1 つだけの場合、分散の意味が失われるため、通常、シャード キーはビジネス ニーズに応じて設定されます。
2.3.1 シャードの重量(重量)
クラスターを構成する場合、重み設定 1 があります。
重みのデフォルトは 1 で、割り切れる任意の値に設定できますが、比較的小さい値に設定することをお勧めします。The shard weight will impact the data of the data in the shard. シャードの重みが大きいほど、より多くのデータが書き込まれます。
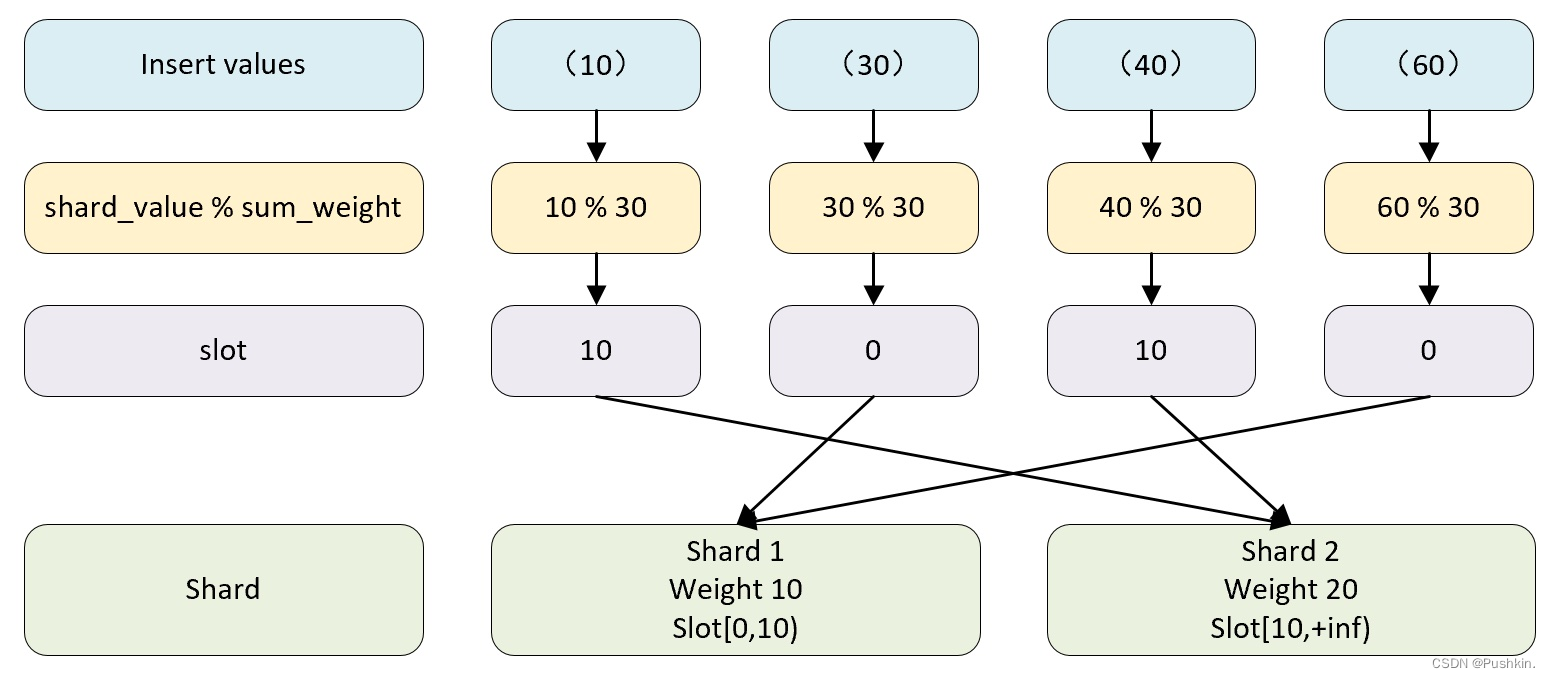
2.3.2 スロット
スロットの数は、すべてのシャードの重みの合計に等しくなります。クラスターに 2 つのシャードがあり、最初のシャードの重みが 10 で、2 番目のシャードの重みが 20 であるとすると、スロットの数は 30 (10 +20)、スロットは重みに応じて重み付けされます。要素の値の範囲は、対応するシャードとのマッピング関係を形成します。
- スロット値の範囲が [0-10) の範囲にある場合、最初のシャードに対応します。
- スロット値の範囲が [10-20) の範囲にある場合、2 番目のシャードに対応します。
2.3.3 選択機能
選択関数は、書き込まれるデータ行を書き込む必要があるシャードを決定するために使用されます。決定プロセスは、大まかに 2 つのステップに分けられます。
- スロットの値を見つけます。計算式は次のとおりです。
スロット = shard_value % sum_weight
- shard_value はシャード キーの値です。
- sum_weight はすべてのシャードの重みの合計です
データの行が shard_value = 10、sum_weight = 30 の場合、30%10 = 10、つまりスロット = 10
- スロット値に基づいて、対応するデータ シャードを見つけます。スロットが 10 の場合、[10,20) 間隔に属するため、このデータ行は 2 番目のシャードに対応します。
2.4 分散書き込みのコアプロセス
クラスター内のシャードにデータを書き込む場合、通常は 2 つの考え方があります。
- 外部コンピューティング システムの助けを借りて, データは最初に均等に分割されます, その後、データはコンピューティング システムによってクリックハウス クラスターの各ローカル テーブルに直接書き込まれます. このソリューションは通常、書き込みパフォーマンスが向上します。ピアツーピアで書かれていますが、このソリューションは主に外部システムに依存しており、クリックハウス自体には依存していません。
- 分散テーブル エンジンを介してシャードされたデータをプロキシします。この方法の書き込みプロセスを以下に詳細に説明する。
理解を容易にするために、シャードの書き込みとレプリカのレプリケーションを 2 つの部分に分けて説明します。シャードの書き込みプロセスを説明するために、シャードが 2 つ、レプリカが 0 のクラスターを使用し、シャードが 1 つ、レプリカが 1 つのクラスターを使用して、シャードを説明します。複製プロセスをコピーします。
2.4.1 シャードにデータを書き込むプロセス
分散テーブルに対して挿入操作を行うと、データ書き込みの実行ロジックが入ります。全体の流れは大きく分けて5段階。
- 最初のシャード ノードにローカル シャード データ
を書き込む まず、node3 ノードの分散テーブル t_shard_2_all で挿入操作を実行し、10、30、40、60 行のデータを書き込みます。実行後、分散テーブルは次の 2 つのことを行います。
- データは割り当てルールに従って分割されます。この例では、30、60 が最初のシャードに分割され、10、40 が 2 番目のシャードに分割されます。
- データ 現在割り当てられているデータは、ローカル テーブル t_shard_2_local に直接書き込まれます
- 最初のシャードがリモート接続を確立し、リモート シャード データを送信する準備が整う
リモート シャードに配置する必要があるデータは、パーティション単位で t_shard_2_all ストレージ ディレクトリの一時的な bin ファイルに書き込まれます. データ ファイルの命名規則は次のとおりです。
/database@host:port/[increase_num].bin
# 10,40 的两条数据会写入到这个临时文件中
一時データが書き込まれた後、2 番目のシャードのサーバーに接続しようとします。
- 最初のシャードはデータをリモートに送信します
この時点で、リスナーの別のグループが t_shard_2_all ディレクトリ内のファイルの変更を監視する役割を担います. これらのタスクはディレクトリ データをリモート シャードに送信する役割を担います. 各データは独立したプロセスによって送信され、データは圧縮されます.送信前です。
-
2 番目のシャードはデータを受信し、それをローカルに書き込みます
2 番目のシャードは、最初のシャードのサーバーとの接続を確立し、最初のシャードからデータを受け取り、それらをローカル テーブルに書き込みます -
最初のシャードは書き込み完了を確認
し、データ送信者はすべてのデータが送信されたことを確認し、データの書き込みプロセスが完了します。
Distributed テーブルがリモート シャードへのデータ送信を担当する場合、非同期と同期の 2 つのモードがあります。
- 非同期: 分散テーブルがローカル シャードに書き込まれた後、挿入操作は書き込み成功メッセージを返します。
- 同期: 挿入操作の実行後、すべてのシャードの書き込みが完了するまで待機します
insert_distributed_sync パラメータは、使用するモードを制御します。デフォルトは false (非同期) です。true に設定されている場合、insert_distributed_timeout パラメータを設定して、同期待機タイムアウトを制御する必要があります。
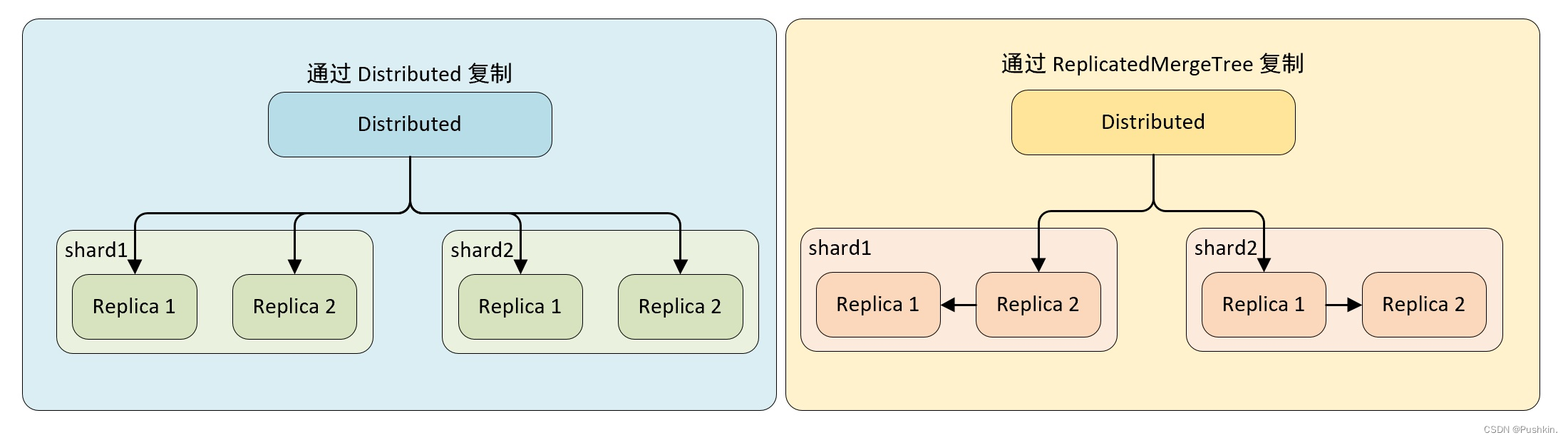
2.4.2 レプリカ複製のプロセス
-
Distributed によるデータのコピー
この実装では、ローカル テーブルが ReplicatedMergeTree テーブル エンジンを使用しなくても、データ コピーの機能を実現できます. Distributed は、コピーとシャードのデータ書き込みを同時に担当します. 書き込みプロセスこの場合、分散ノードの書き込み性能がボトルネックになる可能性があります。 -
ReplicatedMergeTree を使用してデータをレプリケート
する クラスターのシャード構成に internal_replication = true を追加すると、Distributed はシャードごとにデータのコピーを 1 つだけ書き込み、そのコピーの書き込みについては責任を負いません。 ReplicatedMergeTree テーブル エンジンを使用すると、シャード内の複数のコピーが ReplicatedMergeTree 自体によって処理されます。
レプリカの分散選択のアルゴリズムは、大まかに言うと、クリックハウス サーバー ノードにエラー カウントのグローバル カウンターがあります. サーバーが異常な場合、カウンターは 1 増加します. シャードに複数のレプリカがある場合、errors_count カウントが最小のサーバーが選択されて書き込みます.データ。
2.5 分散クエリのコア プロセス
データの書き込みとは異なり、クラスターのデータをクエリするときは、分散テーブル エンジンを介してのみ実装できます. 分散テーブルがクエリ操作を実行すると、各シャードのデータが順番にクエリされ、集計されて返されます.
2.5.1 マルチコピールーティング
When querying data, if a shard in a cluster has multiple replicas, Distributed needs to face the problem of replica selection. Clickhouse は負荷分散アルゴリズムを使用してレプリカの 1 つを選択し、どのアルゴリズムを使用するかは load_balancing パラメータによって決定されます。コントロール。
# clickhouse 提供四种负载均衡算法
load_balancing=random/nearest_hostname/in_order/first_or_random
-
random
random はデフォルトの負荷分散アルゴリズムです. クリックハウスサーバーノードにはグローバルカウンターerrors_countがあります. サーバーに異常が発生するとカウンターが+1され, random はerrors_countが最も少ないノードを選択することです. errors_count が最小のノードが複数ある場合は、ランダムに 1 つ選択します。 -
最も近いホスト名は、ランダムの変形と見なすことができ、errors_count が最小のノードも選択されます. errors_count が最小のノードが複数ある場合は、現在構成されているホスト名に最も類似したホスト名を持つノードが選択されます. -
in_order
は random の変形と見なすことができ、errors_count が最小のノードも選択されます. errors_count が最小のノードが複数ある場合は、レプリカの構成順序に従って 1 つずつ選択します. -
first_or_random
は in_order のバリアントと見なすことができます. また、errors_count が最小のノードを選択します. errors_count が最小のノードが複数ある場合は、最初に構成されたレプリカ ノードが選択されます. 最初のレプリカ ノードが使用できない場合は、1 つがランダムに選択されます.
2.5.2 マルチシャード クエリのコア プロセス
分散クエリは分散書き込みに似ています. クエリを開始する人にも責任があります. 選択クエリを受け取る分散テーブルは、クエリ全体を連結する責任があります.
まず、分散テーブルのクエリ SQL に対して、シャードの数に応じてクエリをいくつかのローカル テーブル クエリのサブクエリに分割し、各テーブルに対してクエリを開始し、最後に各シャードの結果を取得します。集約。
-- 例如在分布式表执行下面查询,查看执行计划
EXPLAIN
SELECT count(1)
FROM t_shard_2_all;
┌─explain─────────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ MergingAggregated │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ Union │
│ Expression (Convert block structure for query from local replica) │
│ ReadFromPreparedSource (Optimized trivial count) │
│ ReadFromPreparedSource (Read from remote replica) │
└─────────────────────────────────────────────────────────────────────────────┘
実行計画全体は、上から下まで 2 つのステップに分けることができます。
-
各シャード
のデータをクエリする ローカル データの読み取りとリモート データの読み取りは並行して行われ、それぞれがローカル シャードとリモート シャードのクエリ アクションの実行を担当します。 -
マージされた結果を返す 返された結果をマージ
する
2.5.3 グローバルを使用して分散サブクエリを最適化する
分散クエリでサブクエリを使用すると、ジレンマに直面する可能性があります。
次の例を見てください。
-- 使用分布式 DDL 创建 分布式表
CREATE TABLE t_distributed_query_all ON CLUSTER two_shard
(
`id` UInt8, -- 用户编号
`repo` UInt8 -- 仓库编号
)
ENGINE = Distributed(two_shard, default, t_distributed_query_local, rand());
-- 使用分布式 DDL 创建本地表
CREATE TABLE t_distributed_query_local ON CLUSTER two_shard
(
`id` UInt8,
`repo` UInt8
)
ENGINE = TinyLog;
-- 在 node2 节点写入数据
insert into t_distributed_query_local values (1,100),(2,100),(3,100);
-- 查询数据
select * from t_distributed_query_local;
┌─id─┬─repo─┐
│ 1 │ 100 │
│ 2 │ 100 │
│ 3 │ 100 │
└────┴──────┘
-- 在 node3 节点写入数据
insert into t_distributed_query_local values (3,200),(4,200);
-- 查询数据
select * from t_distributed_query_local;
┌─id─┬─repo─┐
│ 3 │ 200 │
│ 4 │ 200 │
└────┴──────┘
-- 查询全局表数据
select * from t_distributed_query_all;
┌─id─┬─repo─┐
│ 1 │ 100 │
│ 2 │ 100 │
│ 3 │ 100 │
└────┴──────┘
┌─id─┬─repo─┐
│ 3 │ 200 │
│ 4 │ 200 │
└────┴──────┘
同時に2つの倉庫を持っているユーザーを見つける必要があります.この種のクエリには、inクエリ句を使用できます.同時に、問題はinクエリが分散テーブルを使用するか、ローカルテーブルを使用するか?
- ローカル テーブルの使用に関する問題
in クエリでローカル テーブルを使用する場合:
SELECT uniq(id)
FROM t_distributed_query_all
WHERE (repo = 100) AND (
id IN
(
SELECT id
FROM t_distributed_query_local
WHERE repo = 200
)
);
┌─uniq(id)─┐
│ 0 │
└──────────┘
-- 并没有查询出结果
-- 在分布式表在接收到查询后,将上面 SQL 替换成本地表的形式再发送到每个分片进行执行
SELECT uniq(id)
FROM t_distributed_query_local
WHERE (repo = 100) AND (
id IN
(
SELECT id
FROM t_distributed_query_local
WHERE repo = 200
)
);
-- 单独在分片 1 或分片 2 都无法找到满足 同时等于 100 和 200 的数据
- グローバルを使用してクエリを最適化
する クエリの問題を解決するには、global in または join を使用して最適化します
SELECT uniq(id)
FROM t_distributed_query_all
WHERE (repo = 100) AND (id GLOBAL IN
(
SELECT id
FROM t_distributed_query_all
WHERE repo = 200
))
Query id: 0a55d59d-c87b-4bc8-8985-dad26f0a39b9
┌─uniq(id)─┐
│ 1 │
└──────────┘
グローバル クエリ プロセス:
- 分散クエリを開始するために in 句を個別に提案する
- 分散テーブルをローカル テーブルに変換した後、ローカル シャードとリモート シャードでそれぞれクエリを実行します。
- in サブクエリの結果を要約し、一時メモリ テーブルに格納します。
- memtable をリモート シャード ノードに送信する
- 分散テーブルをローカル テーブルに変換した後、完全な SQL ステートメントの実行を開始し、in 句で一時テーブルのデータを直接使用します。
グローバル修飾子を使用した後、クリックハウスはメモリテーブルを使用してサブクエリで取得したデータを一時的に保存し、それをリモートシャードノードに送信して、データ共有の目的を達成し、クエリの増幅の問題を回避します。 Or the data returned by the join clause should not be too large. メモリ テーブルに重複データがある場合は、句にdistinctを追加して、重複排除を実現できます。