1.スターロックスとは
- StarRocks を使用してさまざまなデータ分析シナリオの超高速分析をサポートできる、新世代の超高速フルシーン MPP データベース。
- 包括的なベクトル化エンジンを使用し、新しく設計された CBO オプティマイザー、クエリ速度 (特に複数テーブルの関連付けクエリ) を備えたシンプルなアーキテクチャ。
- リアルタイムのデータ分析を十分にサポートし、リアルタイムの更新データの効率的なクエリを実現できます。また、最新の具体化されたビューをサポートして、クエリをさらに高速化します。
- ユーザーは、大型ワイドテーブル、スターモデル、スノーフレークモデルなど、さまざまなモデルを柔軟に構築できます。
- MySQL プロトコルと互換性があり、標準の SQL 構文をサポートし、使いやすく、システム全体で外部依存関係がなく、高可用性、簡単な操作と保守管理が可能です。
2. システム構成
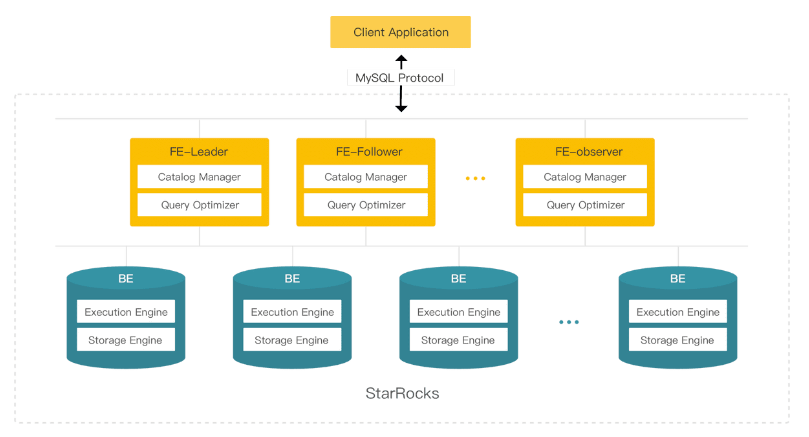
コア プロセス: FE (フロントエンド)、BE (バックエンド)。
注: すべてのノードはステートフルです。
- FE (フロントエンド) は、メタデータの管理、クライアント接続の管理、およびクエリ プランニングとクエリ スケジューリングの実行を担当します。
- フォロワー
- リーダー: フォロワーは Paxos のような BDBJE プロトコルを介してリーダーを選択し、すべてのトランザクションの送信はリーダーによって開始および完了されます。
- フォロワー: クエリの同時実行性を改善し、投票に参加し、主要な選挙操作に参加します。
- オブザーバー: 主な選択操作には参加せず、ログを非同期的に同期して再生するだけで、主にクラスターのクエリ同時実行機能を拡張するために使用されます。
- BE (バックエンド) は、データの保存と SQL の実行を担当します。
3. ストレージ アーキテクチャ
StarRocks では、次の図に示すように、テーブルのデータは複数のタブレットに分割され、各タブレットは複数のコピーの形で BE ノードに格納されます。
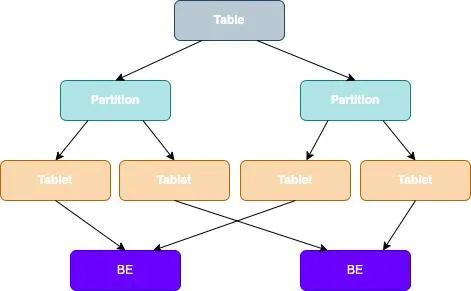
テーブルデータ分割+タブレット3部分のデータ配布:
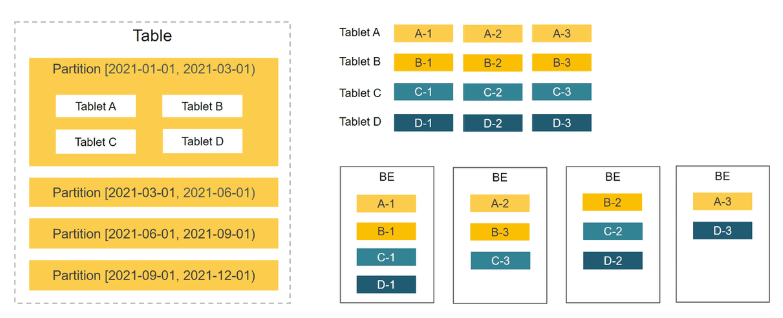
StarRocks は、ハッシュ分散とレンジハッシュを組み合わせたデータ分散 (推奨) をサポートしています。
より高いパフォーマンスを待つために、Range-Hash の結合されたデータ分散、つまり、パーティション化してからバケット化する方法を使用することを強くお勧めします。
- 範囲パーティションは動的に追加および削除できます。
- ハッシュ バケットが決定されると、それらを調整することはできません。未作成のパーティションのみが新しいバケット数を設定できます。
パーティショニングとバケット化の選択は重要です。テーブルを作成するときに適切なパーティションとバケット列を選択すると、クラスターの全体的なパフォーマンスを効果的に向上させることができます。
以下は、特別なアプリケーション シナリオでのパーティションとバケットの選択に関するいくつかの提案です。
- データの偏り: ビジネス側で、データが大幅に偏っていると判断された場合は、データのバケット化に大きな偏りのある列のみを使用するのではなく、複数の列を組み合わせて使用することをお勧めします。
- 高い同時実行性: パーティショニングとバケット化は、クエリ ステートメントの条件を可能な限りカバーする必要があります。これにより、スキャン データを効果的に削減し、同時実行性を向上させることができます。
- 高スループット: データの分割を試み、クラスターがより高い同時実行性でデータをスキャンし、対応する計算を完了できるようにします。
3.1 テーブルの格納
テーブルを格納する場合、テーブルは 2 つのレイヤーに分割されてバケット化され、テーブルのデータは格納および管理のために複数のマシンに分散されます。
- パーティショニング メカニズム: クエリのパフォーマンスを向上させるための効率的なフィルタリング。
パーティショニングは、パーティション キーに従ってテーブルを分割するテーブル パーティショニングに似ており、時間で分割したり、データ量に応じて日/月/年で分割したりできます。アクセス数が少ない場合はパーティションプルーニングを使用したり、データのコールド度に応じてデータを別のメディアに分割したりできます。
- バケット共有メカニズム: クラスターのパフォーマンスを最大限に活用し、ホットスポットの問題を回避します。
バケット キー ハッシュを使用した後、データはすべての BE に均等に分散され、バケット データは偏ってはなりません. バケット キーの選択原理は、カーディナリティの高い列または複数の列を組み合わせてカーディナリティの高い列にすることです. 分散データを十分に。
注: バケットの数は適度である必要があります. パフォーマンスをフルに発揮させたい場合は、次のように設定できます: BE 数 * CPU コア/2. タブレットを約 1GB で制御するのが最適です. ある場合タブレットが少なすぎると、並列処理が不十分になる可能性があります. データが多すぎると、遠すぎる可能性があります. スキャンの同時実行数が多すぎると、パフォーマンスが低下します.
- タブレット: 並列計算リソースを柔軟に設定できる最小のデータ論理ユニット。
テーブルは複数のタブレットに分割され、StarRocks が SQL ステートメントを実行すると、すべてのタブレットに対して並行処理を実装できるため、マルチコンピューターおよびマルチコアが提供する計算能力を最大限に活用できます。
テーブルの作成時にレプリカの数を指定でき、複数のレプリカによってデータ ストレージの高信頼性とサービスの高可用性を確保できます。
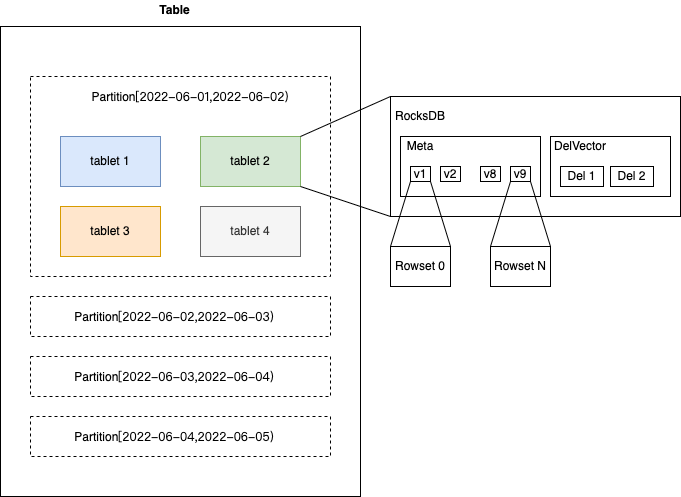
- Rowset: データ変更ごとに Rowset が生成されます。
グループと列のストレージに編成されたいくつかのファイルです. 各コミットは新しいバージョンを生成し、どの行セットが各バージョンに含まれています.
書き込まれるたびにバージョンが追加されます (単一のファイルであるか、ストリーム負荷が数ギガバイトのファイルであるかに関係なく)。
- セグメント: Rowset 内のデータ量が比較的多い場合、複数のセグメント データに分割され、ディスクが切り離されます。
4. 要件の背景
ケース番号1:
- ビジネスの背景
指標工場サービスは主に事業者向けで、事業指標の収集と処理を通じて、製品の状態をリアルタイムで反映し、運用のためのデータサポートを提供し、製品の脆弱性またはサービスの異常を検出し、指標の異常警報機能を提供します。
- ビジネスシナリオ分析
ビジネス指標の埋め込みにはさまざまな方法があり、特定の方法に限定されるものではありません.埋め込みポイントが明確に識別され、ビジネスパラメータが豊富であり、データが解析の基本要件を満たしている限り、それらは次のように使用できます.それらは、SDK、MySQL BinLog、ビジネス ログ、Alibaba Cloud ODPS データ分析に大別できます。
既存の課題、さまざまなビジネス シナリオは調整が難しく、要約されたデータの特徴は次のとおりです。
- 完全なログの詳細が必要です。
- データは常に最新である必要があります。つまり、リアルタイムの更新シナリオを満たす必要があります。
- データは、月、週、日、時間などのレベルで集計する必要があります。
- より大きな書き込みボリュームを運ぶことができる必要があります。
- 各ビジネス データは、データの保存時間を柔軟に構成する必要があります。
- データ ソースには多くのソースがあり、レポートのカスタマイズは比較的多く、複数のデータ ソースが大きな幅の広いテーブルにマージされるシナリオがあり、複数テーブル接続の要件もあります。
- さまざまな監視グラフ、レポート プレゼンテーション、リアルタイムのビジネス クエリなど、つまり上位のものはクエリではありません。
- スターロックスの紹介
幸いなことに、StarRocks には、上記のすべてのビジネス シナリオのニーズをカバーする比較的豊富なデータ モデルがあります。つまり、詳細モデル、更新モデル、集約モデル、主キー モデル、および大規模で幅の広いテーブルではなく、より柔軟なスター モデルの選択です。つまり、複数テーブルの関連付けを使用して直接クエリを実行します。
- 詳細なモデル:
- 埋もれたポイント データは、詳細に従って構造化され、完全に保存されます。
- このシナリオでは、1 億のデータ ボリュームでの DB のクエリ パフォーマンスに対する要件が高くなります。
- データは、動的パーティションを構成することで有効期限ポリシーを構成できます。
- シナリオを使用する場合、オンライン集計クエリの構造化データから個々のフィールド ディメンションを選択します。
- 集約モデル:
- 埋もれたポイントデータの量は膨大で、詳細なデータはトレーサビリティを必要とせず、PV や UV シナリオなどの集計計算は直接実行されます。
- 動的パーティションを構成することにより、有効期限ポリシーを使用してデータを構成できます。
- モデルを更新します。
- 埋もれたポイント データのステータスが変化し、データをリアルタイムで更新する必要がある. 更新されたデータの範囲は、注文、クーポンのステータスなど、複数のパーティションにまたがることはありません。
- 動的パーティションを構成することにより、有効期限ポリシーを使用してデータを構成できます。
上記のビジネス シナリオの分析に基づいて、これら 3 つのモデルはデータの問題を完全に解決できます。
リアルタイムのデータ書き込みが必要な場合は、業界で一般的なソリューションに従います。つまり、データが Kafka に収集された後、Flink を使用して StarRocks にリアルタイムで書き込みます。StarRocks は、非常に便利な Flink コネクタ プラグインを提供しています。
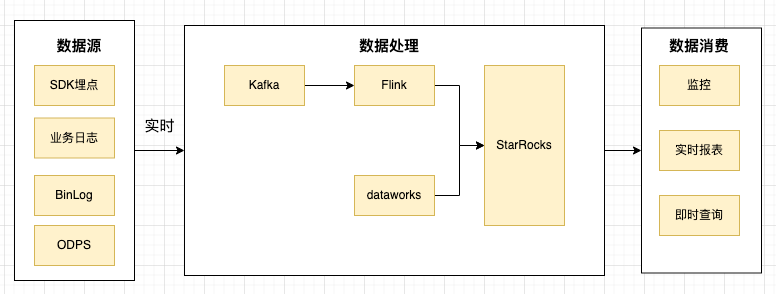
小さなヒント:
1. StarRocks は書き込みパフォーマンスを非常によく最適化していますが、書き込み圧力が高い場合、書き込み拒否が依然として発生します.一度にインポートされるデータの量を増やして頻度を減らすことをお勧めしますが、それも原因となりますデータ ストレージの遅延。増加します。したがって、利益を最大化するには、特定のトレードオフを行う必要があります。
2. Flink のシンク側を大きすぎるように構成することはお勧めできません, これにより、同時トランザクションが多すぎてエラーが報告されます. 各 flink タスク ソースをより多く構成できること、およびシンク接続の数が大きすぎないようにすることをお勧めします.
- まとめ
クラスタ サイズ: 5 FE (8c32GB)、5 BE (32c128GB)
現在、このソリューションは数百のビジネス インジケーターへのアクセスをサポートしており、数十の大規模なインジケーターの表示とアラーム、テラバイト単位のデータ ストレージ、数百ギガバイトの毎日の純増、全体的な安定した運用が含まれます。
ケース 2:
- ビジネスの背景
内部システム ビジネスかんばんは、主に会社全体の従業員にサービスを提供し、プロジェクトやタスクの追跡などの機能を提供します。
- ビジネスシナリオ分析
ビジネスの特徴を分析します。
- データが頻繁に変更(更新)され、変更期間が長い
- クエリ期間
- レポートはリアルタイムで更新する必要があります
- 関連するディメンション テーブル クエリ、部門/事業部門/リソース ドメインなどは多数あります。
- ホット データとコールド データ、最近のデータ クエリが頻繁に行われる
- 歴史的建造物と問題点
データベースの初期選択では、ビジネス特性と合わせて、ユーザーが動的かつ柔軟にタスクを追加および削除する必要があるため、アプリケーション コードとストレージ層の間のインピーダンスを減らすために JOSN モデルが選択され、そのモデルとして MongoDB が選択されます。データストレージ。
会社の迅速な納品に伴い、レポート表示が必要な場合、特に時間スパンが比較的長く、多部門、多次元、詳細なレポート表示が含まれる場合、MongoDB でクエリ時間を実行する必要があります。 10秒またはそれ以上。
- スターロックスの紹介
優れた分析データベースである StarRocks と ClickHouse を調査しました.モデルを選択する際には、主に単一テーブルの集計クエリ、複数テーブルの関連付けクエリ、およびリアルタイム更新の読み書きクエリに焦点を当てて、ビジネス アプリケーションのシナリオを分析しました。ディメンションテーブルは頻繁に更新される、つまりMySQLに保存されます.StarRocksは外観関連のクエリをよりよくサポートし、開発の難しさを大幅に軽減します.最終的に、ストレージエンジンとしてStarRocksを使用することにしました.
変換段階では、元の MongoDB のコレクションが 3 つのテーブルに分割されます。詳細モデルを使用して、該当する担当者のタスク情報を毎日記録し、以前の記録である 1 人 1 日 1 レコードからイベント単位まで、日ごとに分割し、1 人が 1 日に複数のレコードを持つことができます。
頻繁に更新されるディメンション テーブルを実装するには、外部テーブルの使用を選択して、ディメンション データを StarRocks に同期する複雑さを軽減します。\
- まとめ
変換前の MongoDB クエリは複雑で、何度もクエリを実行していました。
db.time_note_new.aggregate(
[
{'$unwind': '$depart'},
{'$match': {
'depart': {'$in': ['部门id']},
'workday': {'$gte': 1609430400, '$lt': 1646064000},
'content.id': {'$in': ['事项id']},
'vacate_state': {'$in': [0, 1]}}
},
{'$group': {
'_id': '$depart',
'write_hour': {'$sum': '$write_hour'},
'code_count': {'$sum': '$code_count'},
'all_hour': {'$sum': '$all_hour'},
'count_day_user': {'$sum': {'$cond': [{'$eq': ['$vacate_state', 0]}, 1, 0]}},
'vacate_hour': {'$sum': {'$cond': [{'$eq': ['$vacate_state', 0]}, '$all_hour', 0]}},
'vacate_write_hour': {'$sum': {'$cond': [{'$eq': ['$vacate_state', 0]}, '$write_hour', 0]}}}
-- ... more field
},
{'$project': {
'_id': 1,
'write_hour': {'$cond': [{'$eq': ['$count_day_user', 0]}, 0, {'$divide': ['$vacate_write_hour', '$count_day_user']}]},
'count_day_user': 1,
'vacate_hour': 1,
'vacate_write_hour': 1,
'code_count': {'$cond': [{'$eq': ['$count_day_user', 0]}, 0, {'$divide': ['$code_count', '$count_day_user']}]},
'all_hour': {'$cond': [{'$eq': ['$count_day_user', 0]}, 0, {'$divide': ['$vacate_hour', '$count_day_user']}]}}
-- ... more field
}
]
)変換後、SQL と直接互換性があり、一度に集約できます。
WITH cont_time as (
SELECT b.depart_id, a.user_id, a.workday, a.content_id, a.vacate_state
min(a.content_second)/3600 AS content_hour,
min(a.write_second)/3600 AS write_hour,
min(a.all_second)/3600 AS all_hour
FROM time_note_report AS a
JOIN user_department AS b ON a.user_id = b.user_id
-- 更多维表关联
WHERE b.depart_id IN (?) AND a.content_id IN (?)
AND a.workday >= '2021-01-01' AND a.workday < '2022-03-31'
AND a.vacate_state IN (0, 1)
GROUP BY b.depart_id, a.user_id, a.workday, a.content_id,a.vacate_state
)
SELECT M.*, N.*
FROM (
SELECT t.depart_id,
SUM(IF(t.content_id = 14, t.content_hour, 0)) AS content_hour_14,
SUM(IF(t.content_id = 46, t.content_hour, 0)) AS content_hour_46,
-- ...more
FROM cont_time t
GROUP BY t.depart_id
) M
JOIN (
SELECT depart_id AS join_depart_id,
SUM(write_hour) AS write_hour,
SUM(all_hour) AS all_hour
-- 更多指标
FROM cont_time
GROUP BY depart_id
) N ON M.depart_id = N.join_depart_id
ORDER BY depart_id ASCクエリ レポートで 2021/01/01 ~ 2022/03/01 のデータを比較するには:
- StarRocks: 1 つのクエリ集計。複雑な SQL 集計関数を使用して完全に計算でき、295 ミリ秒かかります。
- Mongodb: 2つのクエリ+計算に分割する必要があり、合計で3秒+9秒=12秒かかります
5. 経験の共有
StarRocks の使用中に発生したエラーと解決策 (オンライン情報が少ないエラー情報):
a.データ インポート ストリーム ロード エラー: 「データベース 13003 で現在実行中の txns は 100 で、制限 100 を超えています」
原因:データベースごとに実行中のインポート ジョブの最大数を超えました。デフォルト値は 100 です。インポートごとのジョブの数は、max_running_txn_num_per_db パラメーターを調整することで増やすことができます。できれば、ジョブの送信バッチを調整することで可能です。これは、バッチを節約し、同時実行性を減らすためです。
b. FE が次のエラーを報告する: 「java.io.FileNotFoundException: /proc/net/snmp (Too many open files)」
理由:ファイル ハンドルが不十分です. ここで、スーパーバイザがプロセスを管理する場合、fe の起動スクリプトにファイル ハンドルの設定を追加する必要があることに注意してください。
if [[ $(ulimit -n) -lt 60000 ]]; then
ulimit -n 65535
fi
c. StarRocks は、Java 言語を使用してユーザー定義関数 UDF を記述することをサポートしており、実行関数でエラーが報告されます: "rpc failed, host: xxxx"、およびエラーが be.out ログで報告されます:
start time: Tue Aug 9 19:05:14 CST 2022
Error occurred during initialization of VM
java/lang/NoClassDefFoundError: java/lang/Object理由:スーパーバイザーを使用してプロセスを管理する場合は、JAVA_HOME 環境変数の増加に注意する必要があります.BE ノードでさえ Java のいくつかの関数を呼び出す必要があり、JAVA_HOME 環境変数の構成を BE 起動スクリプトに直接追加できます。 .
d. 削除操作を実行すると、次のエラーが報告されます。
SQL > delete from tableName partition (p20220809,p20220810) where `c_time` > '2022-08-09 15:20:00' and `c_time` < '2022-08-10 15:20:00';
ERROR 1064 (HY000): Where clause only supports compound predicate, binary predicate, is_null predicate and in predicate理由:現在、削除後の where 条件は between and 操作をサポートしていません。現在、サポートされているのは =、>、>=、<、<=、!=、IN、NOT IN のみです。
e. Routine Load を使用して kakfa データを消費すると、多数のランダムな group_id が生成される
提案:ルーチン ロードを作成するときにグループ名を指定します。
f. StarRocks 接続がタイムアウトし、クエリ ステートメントがエラーを報告しました: "ERROR 1064(HY000): there is no scanNode Backend". BE ノードを再起動した後、一時的に回復しました。ログエラーは次のとおりです。
kafka log-4-FAIL, event: [thrd:x.x.x.x:9092/bootstrap]: x.x.x.x:9092/1: ApiVersionRequest failed: Local: Timed out: probably due to broker version < 0.10 (see api.version.request configuration) (after 10009ms in state APIVERSION_QUERY)理由: kafka への Routine Load 接続に問題があると、BrpcWorker スレッドが使い果たされ、StarRocks への通常のアクセスに影響します。一時的な解決策は、問題のあるタスクを見つけて、タスクを一時停止し、再開することです。
6. 今後の計画
次に、より多くのサービスを StarRocks に接続して元の OLAP クエリ エンジンを置き換え、より多くのビジネス シナリオを使用して経験を蓄積し、クラスターの安定性を向上させます。将来的には、StarRocks が主キー モデルのメモリ使用量を最適化して増加させ、一部の列をより柔軟に更新する方法をサポートし、ビットマップ クエリのパフォーマンスを引き続き最適化および改善し、マルチテナント リソースの分離を最適化することを願っています。今後も、StarRocks のコミュニティ ディスカッションに積極的に参加し、ビジネス シナリオに関するフィードバックを提供していきます。
*テキスト/Shen Rui
Dewu テクノロジーに注目し、毎週月、水、金の夜 18:30 にテクニカル ドライ グッズを更新します
記事が役に立ったと思われる場合は、コメント、転送、いいねをお願いします〜