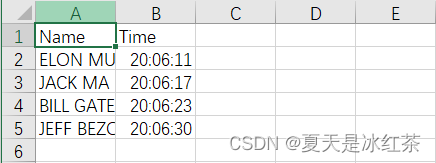
1.エフェクト表示
顔認識:
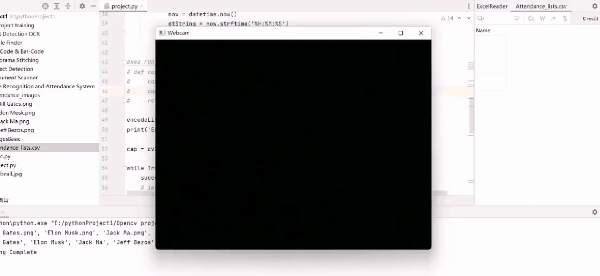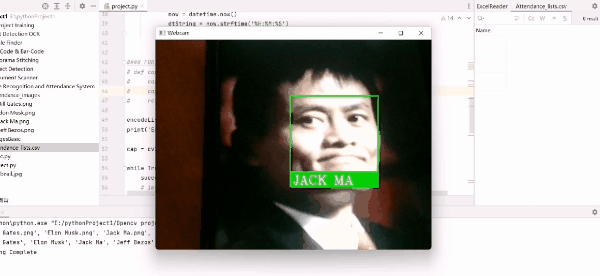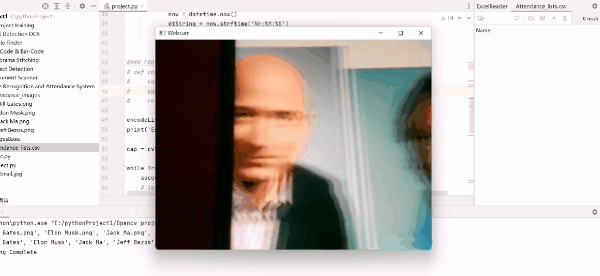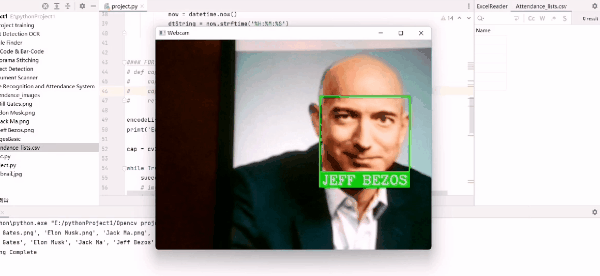
出席効果:
2. プロジェクト紹介
次に、理論の簡単な紹介と基本的な実装の学習から始めて、高精度で顔認識を実行する方法を学びます。次に、ウェブカメラを使用して顔を検出し、リアルタイムで出席を Excel シートに記録する出席プロジェクトを作成します。
3. プロジェクトの基本理論
(1) プロジェクトパッケージの構築
その前に、この記事を読んでプロジェクト パッケージの構築を完了しておく必要があります(37 メッセージ)
さらに、パッケージをインストールする必要もあります。手順に従ってください。
pip install face_recognition_models(2) ファイル構成
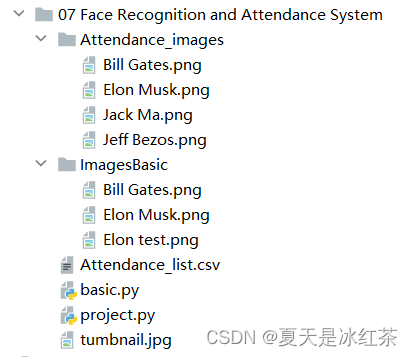
図の構成では、Attendance.csv ファイルの内容は (Name, Time) だけですが、Attendance_images ファイルには、追加したい写真、できれば個々のキャラクターの写真を追加し、写真に名前を付けることができます。彼らの英語名。
(3) basic.pyのコード表示と説明
import cv2
import face_recognition
imgElon = face_recognition.load_image_file('ImagesBasic/Elon Musk.png')
imgElon = cv2.cvtColor(imgElon, cv2.COLOR_BGR2RGB)
imgTest = face_recognition.load_image_file('ImagesBasic/Elon test.png')
imgTest = cv2.cvtColor(imgTest, cv2.COLOR_BGR2RGB)
faceLoc = face_recognition.face_locations(imgElon)[0]
encodeElon = face_recognition.face_encodings(imgElon)[0]
cv2.rectangle(imgElon, (faceLoc[3], faceLoc[0]), (faceLoc[1], faceLoc[2]), (255, 0, 255), 2)
faceLocTest = face_recognition.face_locations(imgTest)[0]
encodeTest = face_recognition.face_encodings(imgTest)[0]
cv2.rectangle(imgTest, (faceLocTest[3], faceLocTest[0]), (faceLocTest[1], faceLocTest[2]), (255, 0, 255), 2)
results = face_recognition.compare_faces([encodeElon], encodeTest)
faceDis = face_recognition.face_distance([encodeElon], encodeTest)
print(results, faceDis)
cv2.putText(imgTest, f'{results} {round(faceDis[0], 2)}', (50, 50), cv2.FONT_HERSHEY_COMPLEX, 1, (0, 0, 255), 2)
cv2.imshow('Elon Musk', imgElon)
cv2.imshow('Elon Test', imgTest)
cv2.waitKey(0)
マスク氏の写真「Elon Musk.png」を標準テストとして使用します。他の2枚の写真はビル・ゲイツ氏とマスク氏のもの。
今日の説明は 2 つの部分に分かれますが、これが説明の基本的な部分です。
- 最初に、これら 2 つのコードで写真をインポートします. face_recognition で load_image_file 関数を使用します.これは、画像ファイル (.jpg、.png など) を numpy 配列にロードし、デフォルトのモード = 'RGB' 形式なので、ここに変換があります。
- 次に、faceLoc は、face_locations() 関数によって返された画像内の顔のバウンディング ボックス配列を受け入れます。注 1 を参照してください。最初の数字を取得します。タプルまで待機します。css (上、右、下) を押す必要があります。 、左 ) 順番に見つかった顔の位置のタプルのリスト。encodeElon() 関数は 128 次元の顔エンコーディング リスト (画像内の各顔に 1 つ) を返しますが、なぜ 128 次元なのですか? 注 2 を参照してください。この後はまたフレーム操作ですが、以前の記事を読んでくださった方はおなじみだと思いますので、注3に従って座標を入力してください。
- その後、compare_faces() は、顔エンコーディングのリストを候補エンコーディングと比較して、それらが一致するかどうかを確認します。覚えておいてください。最初のものだけがリストであり、true/false 値のリストを返します; face_distance() には、指定された顔エンコーディングが必要です。リストし、それを既知の顔エンコーディングと比較し、比較した各顔のユークリッド距離を取得します。距離は、顔がどれだけ似ているかを教えてくれます。繰り返しますが、最初のものだけがリストです。上記の注 4 を参照してください。
- 最後に、フレーム内の情報を適切な場所に配置して、画像を表示します。
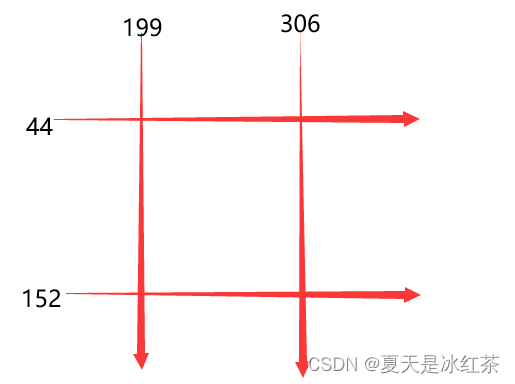
注 1: [(44, 306, 152, 199)]
注2:機械学習は楽しい!パート 4: 最新の顔認識とディープ ラーニング - Fintech Ranking (fintechranking.com) by Adam Geitgey .
注3:座標図
注 4: [True] [0.4559636]
(5) エフェクト表示
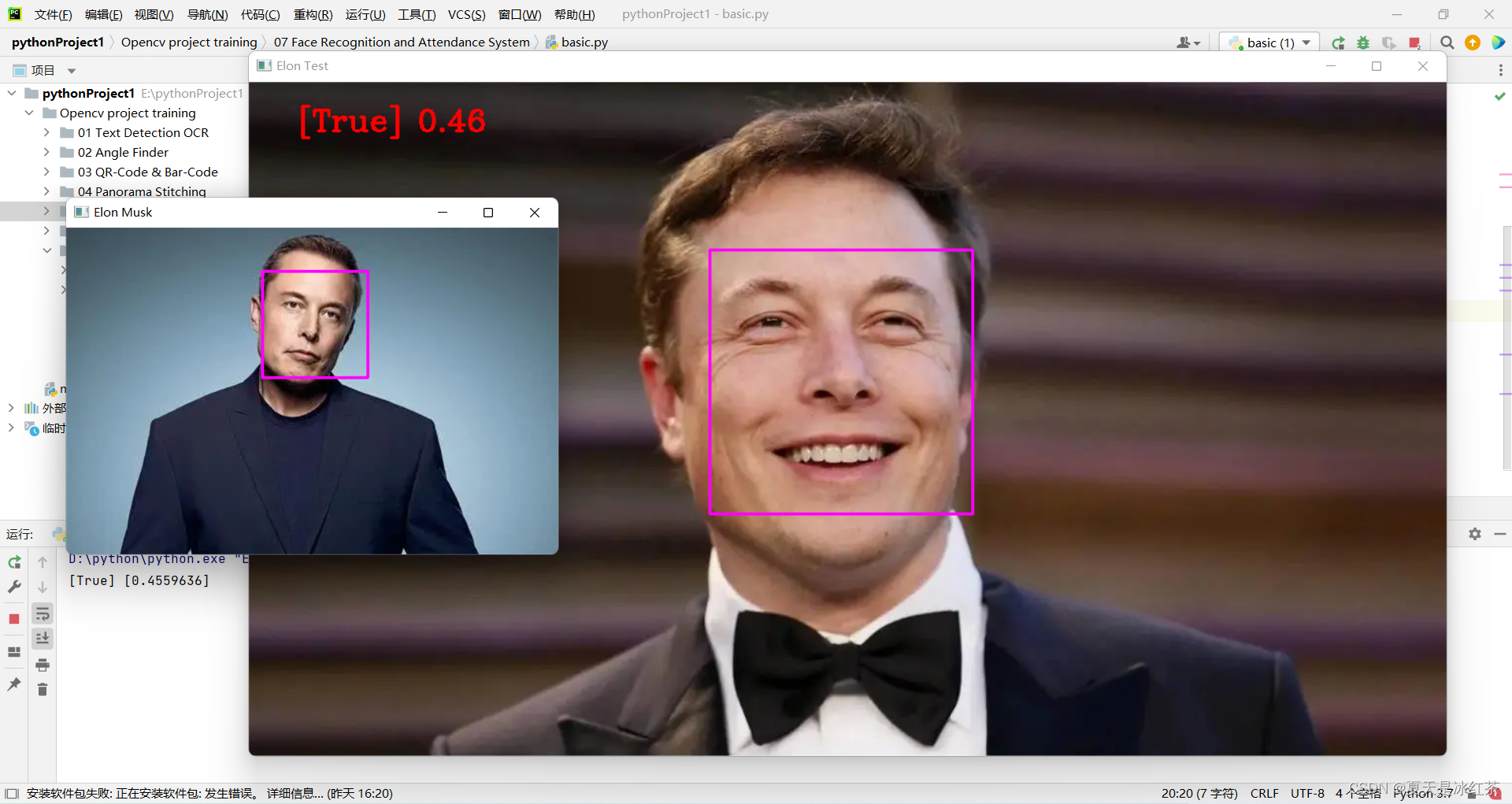
ここでコードを変更することにより、最初に顔認識を実装しました。
imgTest = face_recognition.load_image_file('ImagesBasic/Bill Gates.png')
imgTest = cv2.cvtColor(imgTest, cv2.COLOR_BGR2RGB)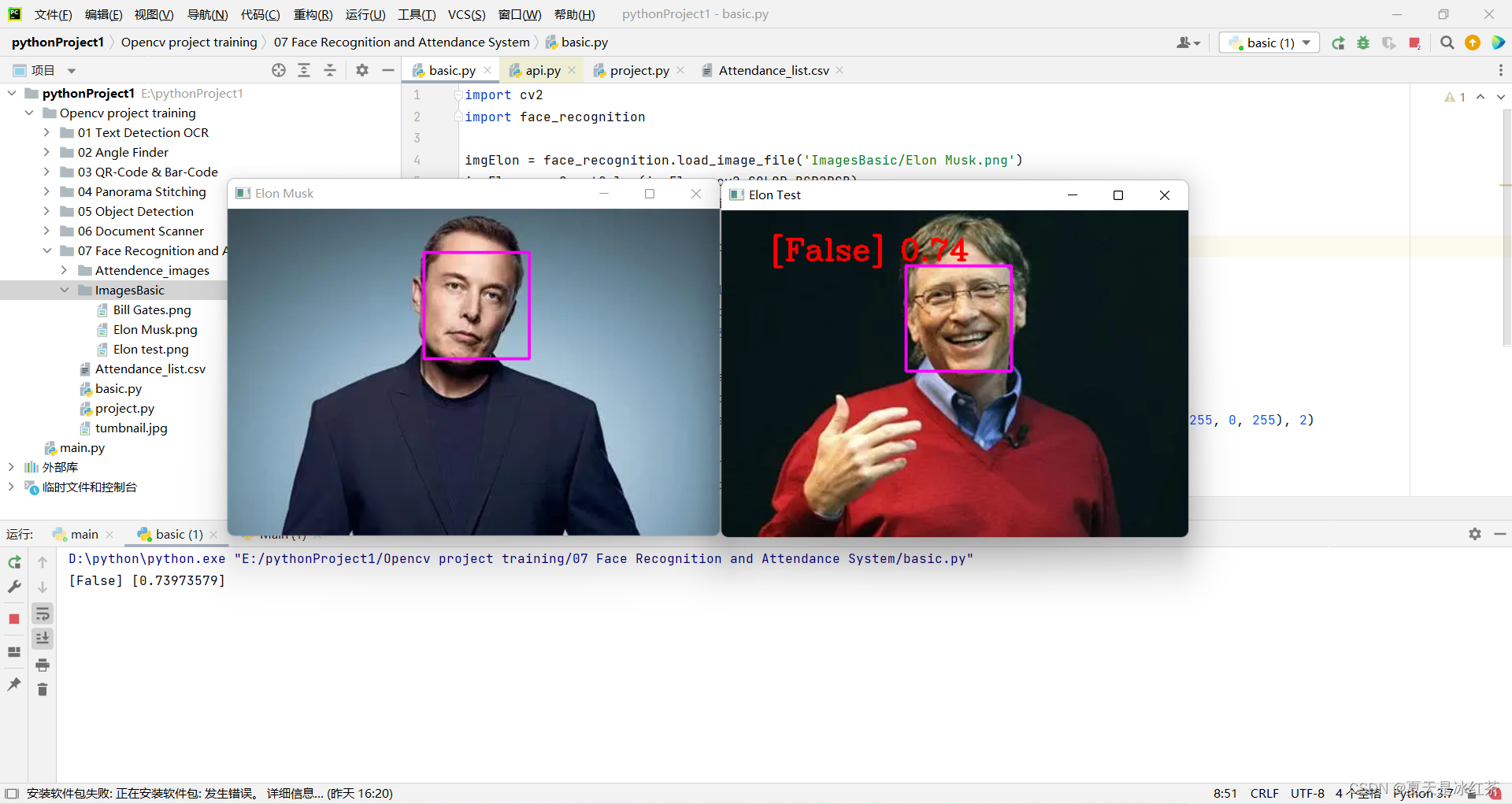
4. プロジェクトコードの表示と説明
import cv2
import numpy as np
import face_recognition
import os
from datetime import datetime
# from PIL import ImageGrab
path = 'Attendance_images'
images = []
classNames = []
myList = os.listdir(path)
print(myList)
for cl in myList:
curImg = cv2.imread(f'{path}/{cl}')
images.append(curImg)
classNames.append(os.path.splitext(cl)[0])
print(classNames)
def findEncodings(images):
encodeList = []
for img in images:
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
encode = face_recognition.face_encodings(img)[0]
encodeList.append(encode)
return encodeList
def markAttendance(name):
with open('Attendance_lists.csv', 'r+') as f:
myDataList = f.readlines()
nameList = []
for line in myDataList:
entry = line.split(',')
nameList.append(entry[0])
if name not in nameList:
now = datetime.now()
dtString = now.strftime('%H:%M:%S')
f.writelines(f'\n{name},{dtString}')
#### FOR CAPTURING SCREEN RATHER THAN WEBCAM
# def captureScreen(bbox=(300,300,690+300,530+300)):
# capScr = np.array(ImageGrab.grab(bbox))
# capScr = cv2.cvtColor(capScr, cv2.COLOR_RGB2BGR)
# return capScr
encodeListKnown = findEncodings(images)
print('Encoding Complete')
cap = cv2.VideoCapture(1)
while True:
success, img = cap.read()
# img = captureScreen()
imgS = cv2.resize(img, (0, 0), None, 0.25, 0.25)
imgS = cv2.cvtColor(imgS, cv2.COLOR_BGR2RGB)
facesCurFrame = face_recognition.face_locations(imgS)
encodesCurFrame = face_recognition.face_encodings(imgS, facesCurFrame)
for encodeFace, faceLoc in zip(encodesCurFrame, facesCurFrame):
matches = face_recognition.compare_faces(encodeListKnown, encodeFace)
faceDis = face_recognition.face_distance(encodeListKnown, encodeFace)
# print(faceDis)
matchIndex = np.argmin(faceDis)
if matches[matchIndex]:
name = classNames[matchIndex].upper()
# print(name)
y1, x2, y2, x1 = faceLoc
y1, x2, y2, x1 = y1 * 4, x2 * 4, y2 * 4, x1 * 4
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.rectangle(img, (x1, y2 - 35), (x2, y2), (0, 255, 0), cv2.FILLED)
cv2.putText(img, name, (x1 + 6, y2 - 6), cv2.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255), 2)
markAttendance(name)
cv2.imshow('Webcam', img)
cv2.waitKey(1)ここでの操作のいくつかは、以前のブログで言及されており、非常に明確に説明されているので、簡単に説明します。
- 最初に、Attendance_images ファイル内の画像の名前を読み取ります。これには .png が含まれていることに注意してください。この名前付けにはそれが必要ないため、[0] を使用します。
- 次に、findEncodings() を記述して、標準画像のエンコーディングをリスト形式で格納します。markAttendance() 関数を使用して、Attendance_lists.csv のファイル情報を読み取り、Excel に書き込みます。Excel には時刻も書き込むことができます。
- あとは、上記の説明で問題ないと思います。y1、x2、y2、x1 = y1 * 4、x2 * 4、y2 * 4、x1 * 4について話しましょう。なぜ4を掛けるか、上記のサイズ変更を覚えておいてください。ピクセルの変更は必要ありませんが、縮小します比率は正確です0.25。
5. プロジェクト資料
6. プロジェクトの概要
今日のプロジェクトは、以前のオブジェクト検出よりもまだ難しいです. 私にとって、現在の効率はあまり高くありません. 昨日の dlib と face_recognition パッケージのダウンロードは本当に完了していません. 一時的にプロジェクトを変更しました. .
それでは、このプロジェクトを楽しんでいただければ幸いです。!
