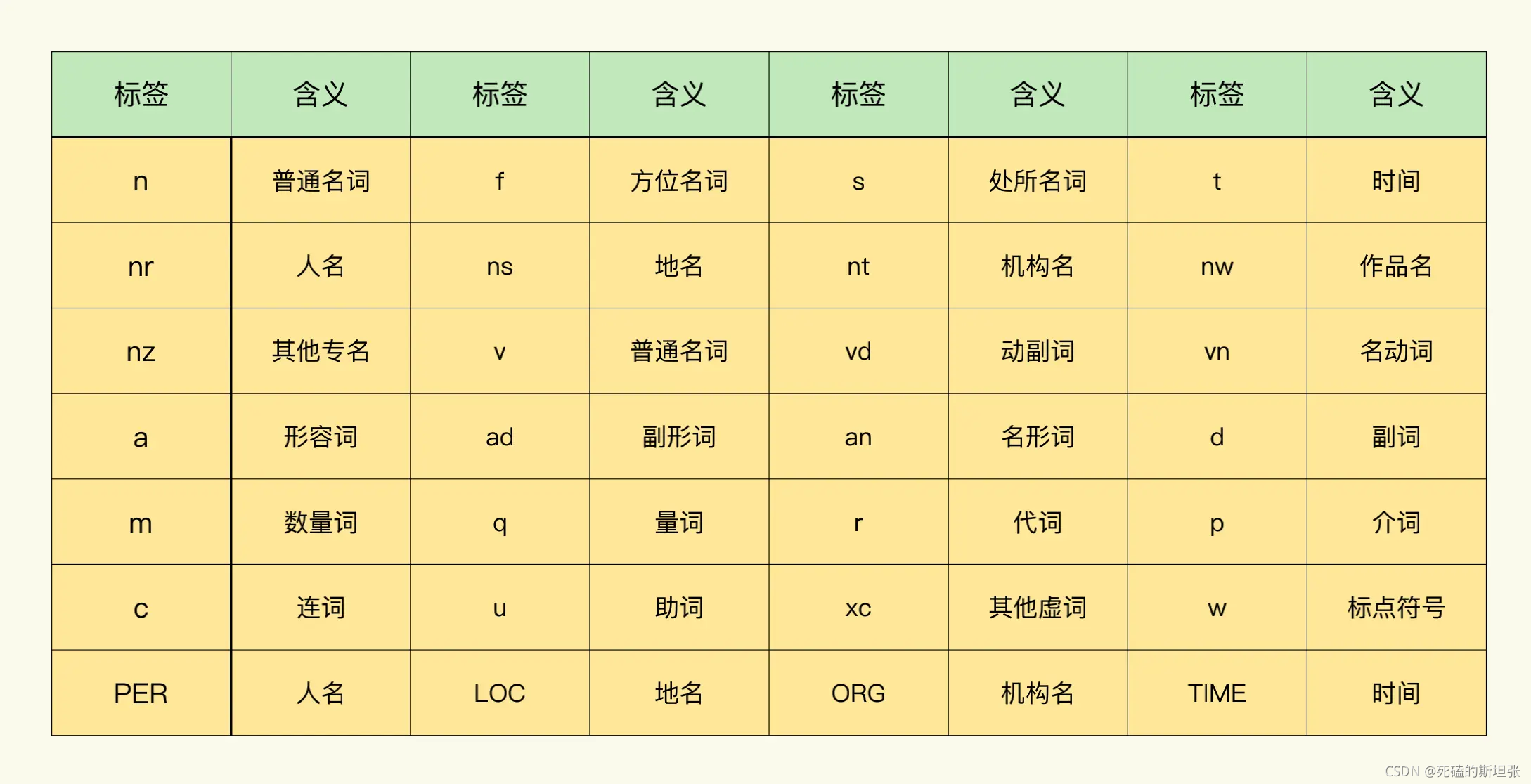
キーワード抽出
句読点を削除するには、一般に2つの方法があります。ストップワードを削除する(ストップワード)、
品詞に従ってキーワードを抽出する。
words2 = jieba.cut(words1)
words3 = list(words2)
print("/".join(words3))
# 速度/快/,/包装/好/,/看着/特别/好/,/喝/着/肯定/不错/!/价廉物美
stop_words = [",", "!"]
words4 =[x for x in words3 if x not in stop_words]
print(words4)
# ['速度', '快', '包装', '好', '看着', '特别', '好', '喝', '着', '肯定', '不错', '价廉物美']
単語のセグメンテーション結果を最適化する別の方法は、品詞に基づいてキーワードを抽出することです。この方法の利点は、jiebaライブラリが、ストップワードのリストを事前に準備しなくても、品詞に従って各単語にタグを付けることができることです。
これがパドル(パドルはBaiduのオープンソース深層学習プラットフォームであり、jiebaはパドルのモデルライブラリを使用します)パターンの品詞テーブルを参照として使用できます。補助語、機能語(句読点)を品詞に従って手動で分析できます。 jiebaシンボルによって自動的に分析された品詞)が削除されました。
# words5 基于词性移除标点符号
import jieba.posseg as psg
words5 = [ (w.word, w.flag) for w in psg.cut(words1) ]
# 保留形容词
saved = ['a',]
words5 =[x for x in words5 if x[1] in saved]
print(words5)
# [('快', 'a'), ('好', 'a'), ('好', 'a'), ('不错', 'a')]
セマンティック感情分析
単語に分割された文については、別のライブラリを使用して、単語のポジティブおよびネガティブな感情的傾向をカウントする必要があります。このライブラリは、snownlpライブラリです。
Snownlpのアルゴリズムの問題により、否定的な単語を不正確に分類する可能性があります。たとえば、「嫌い」の場合、snownlpは単語を「no」と「like」の2つの別々の単語に分割します。次に、セマンティック感情を計算するときに、大きなエラーが発生します。したがって、最初に単語のセグメンテーションにjiebaを使用し、次にsnownlpを使用して単語のセグメンテーション後に意味感情分析を実装します。
from snownlp import SnowNLP
words6 = [ x[0] for x in words5 ]
s1 = SnowNLP(" ".join(words3))
print(s1.sentiments)
# 0.99583439264303
このコードは、snownlpのベイズ(ベイズ)モデルトレーニングメソッドを使用して、モジュールに付属するポジティブサンプルとネガティブサンプルをメモリに読み取り、ベイズモデルのclassify()関数を使用して分類します。これにより、感情属性は次のようになります。感情の値は、感情的な傾向の方向を示します。snownlpの場合:感情の向きが正の場合、感情の結果は1に近くなります。感情的な方向性が負の場合、結果は0に近くなります。
positive = 0
negtive = 0
for word in words6:
s2 = SnowNLP(word)
if s2.sentiments > 0.7:
positive+=1
else:
negtive+=1
print(word,str(s2.sentiments))
print(f"正向评价数量:{
positive}")
print(f"负向评价数量:{
negtive}")
# 快 0.7164835164835165
# 好 0.6558628208940429
# 好 0.6558628208940429
# 不错 0.8612132352941176
# 价廉物美 0.7777777777777779
# 正向评价数量:3
# 负向评价数量:2
snownlpでは、train()関数とsave()関数を使用してモデルをトレーニングおよび保存した後、デフォルトのディクショナリを拡張する関数を実装できます。また、私の作品では、この方法を使って絵文字表現に対応する感情傾向分析機能を高め、snownlpの感情傾向分析の精度をさらに向上させていきます。
sentiment.train(neg2.txt,pos2.txt); # 训练用户自定义正负情感数据集
sentiment.save('sentiment2.marshal'); # 保存训练模型